爬虫进阶之-逆向
1 为什么要逆向
自动化程序( selenium)爬取遇到指纹无法爬取,爬取数据量小;为了追求效率和更大的数据量,所以要用逆向。
2 什么是逆向
当返回数据不是明文而是密文时,比如常见的模拟登陆中的密码,有些网站还是采用明文方式传输,但大部分网站都是采用的密文方式传输。这时你对登陆页面发起POST请求,Data字段带上明文的密码时是无法达到模拟登陆的目的的。这时就需要剖析网站的JS加密算法以及对其进行逆向操作。
加密类:请求参数、请求头、请求表达、cookie
解密类:数据逆向
逆向的方向:
exe逆向: c++(汇编、反编译) python
安卓逆向: java python
web逆向: javascript python
ios逆向: ios python
3 requests模块5个步骤
3.1 接口定位
以https://zxts.zjzwfw.gov.cn/zwmhww/#/home/index/public-letter?areacode=33 网站为例
关键词搜索

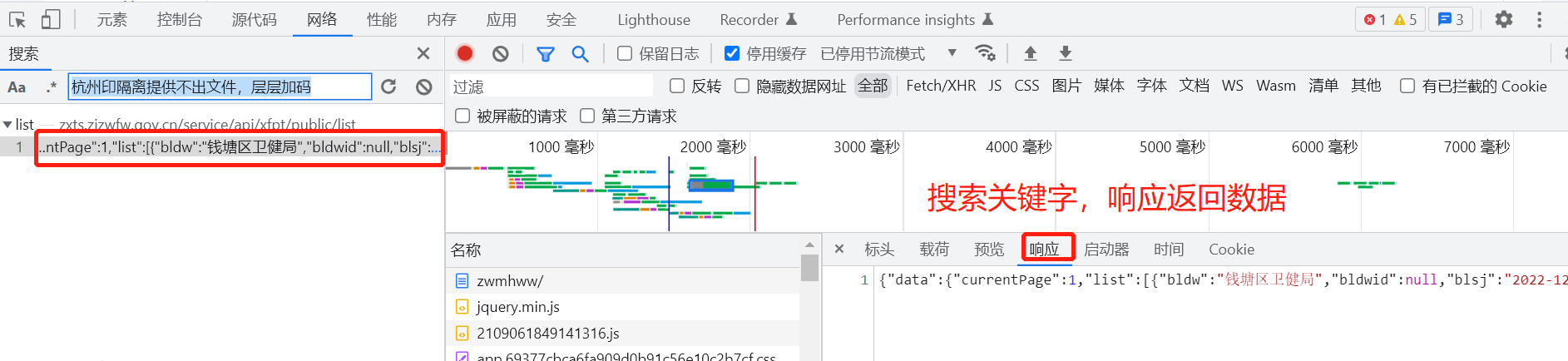
找到接口
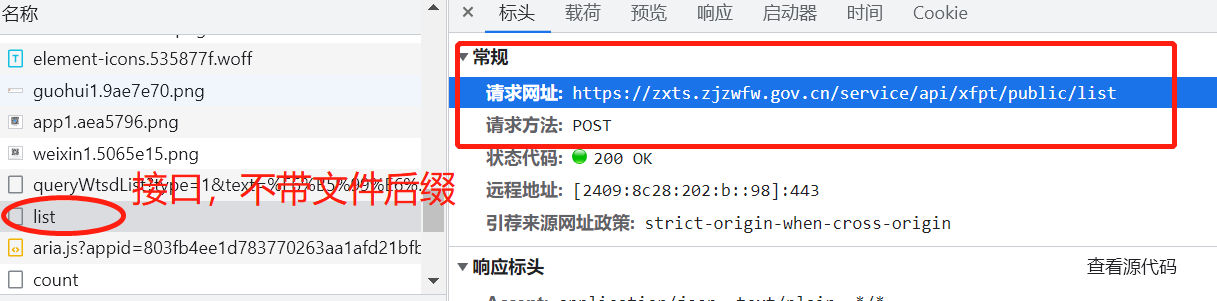
3.2 请求方式区分
请求方式是post,查看表单数据

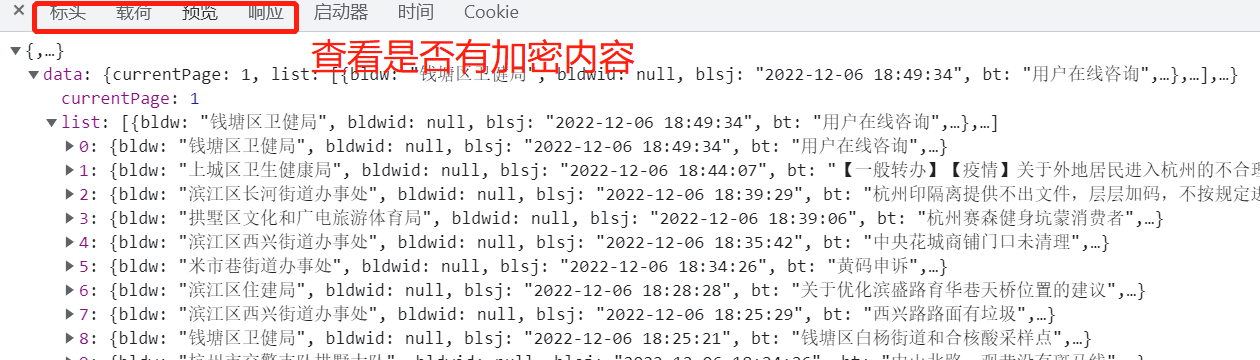
3.3 全局检索是否存在加密内容
3.4 构建爬虫
用requests模块,构建一个简单的爬虫程序
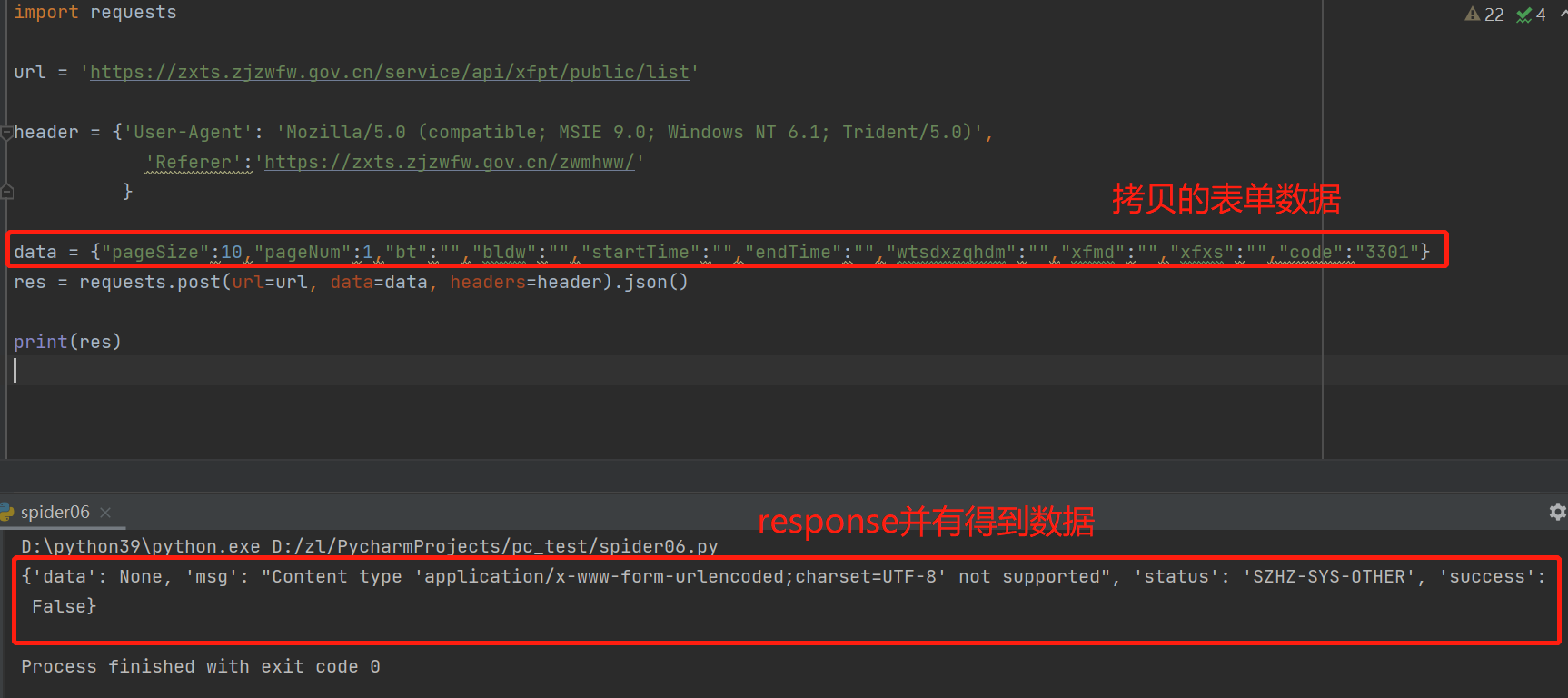
爬虫程序并没有返回数据,说明我们发送的请求参数或者规则有错,不符合该网站javascript的验证规则,如何快速判断接口验证规则?
这里用到XHR断点调试:
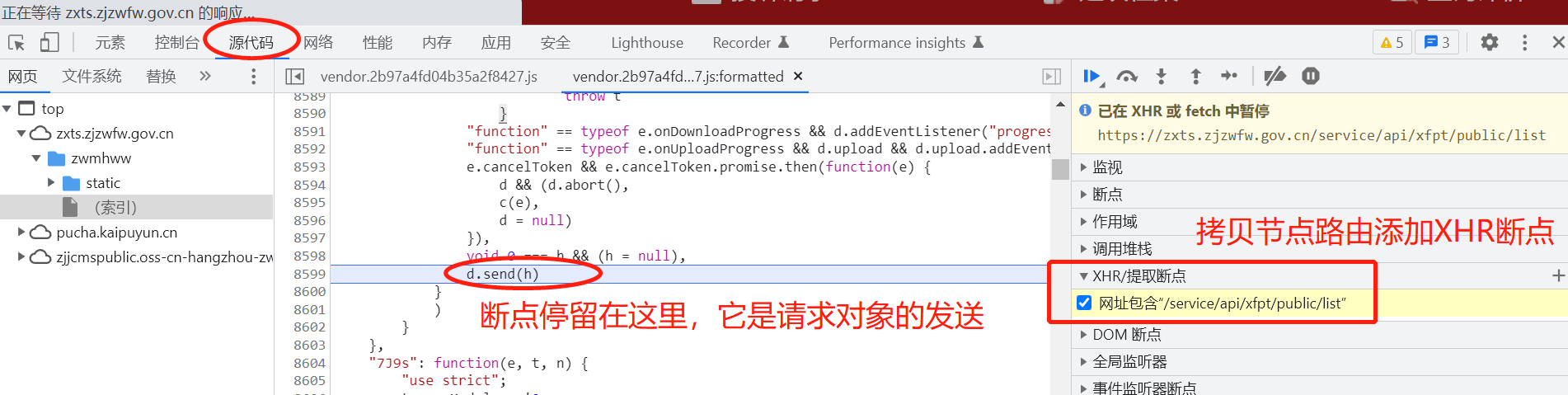
拷贝接口路由,源代码--->添加到XHR断点,刷新网页,发现断点停留位置。
请求对象发送:将由js验证浏览器发送的请求头、请求方法、请求参数、请求表单、接口等是否符合规则,可以通过它来查看需要传入哪些参数,以及格式。
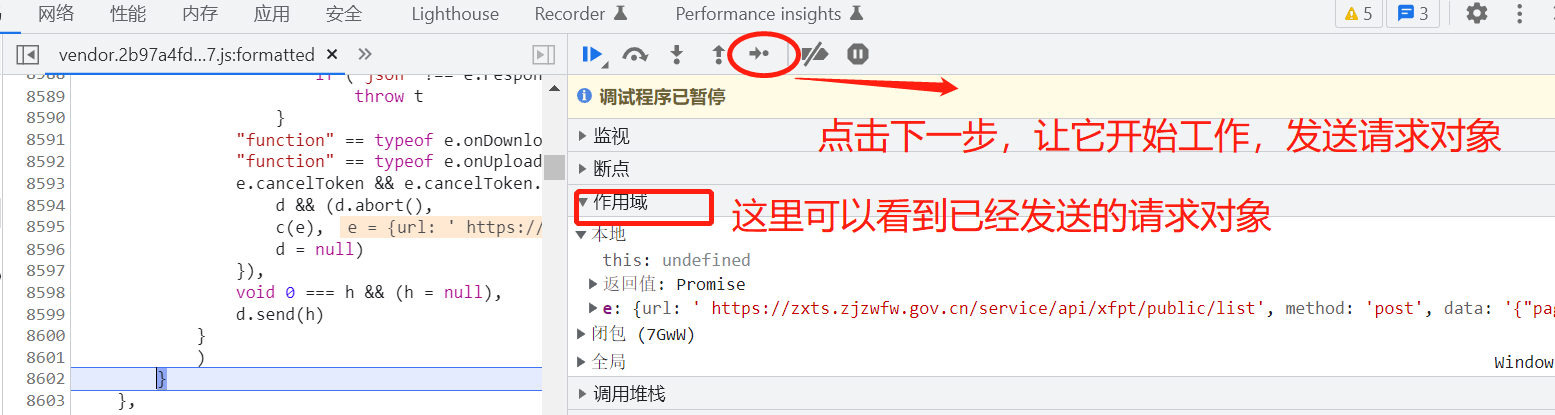
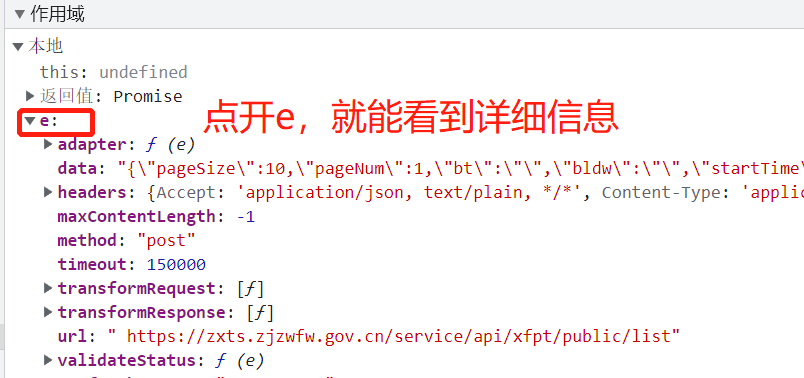
调试的一些相关信息会在作用域进行显示:
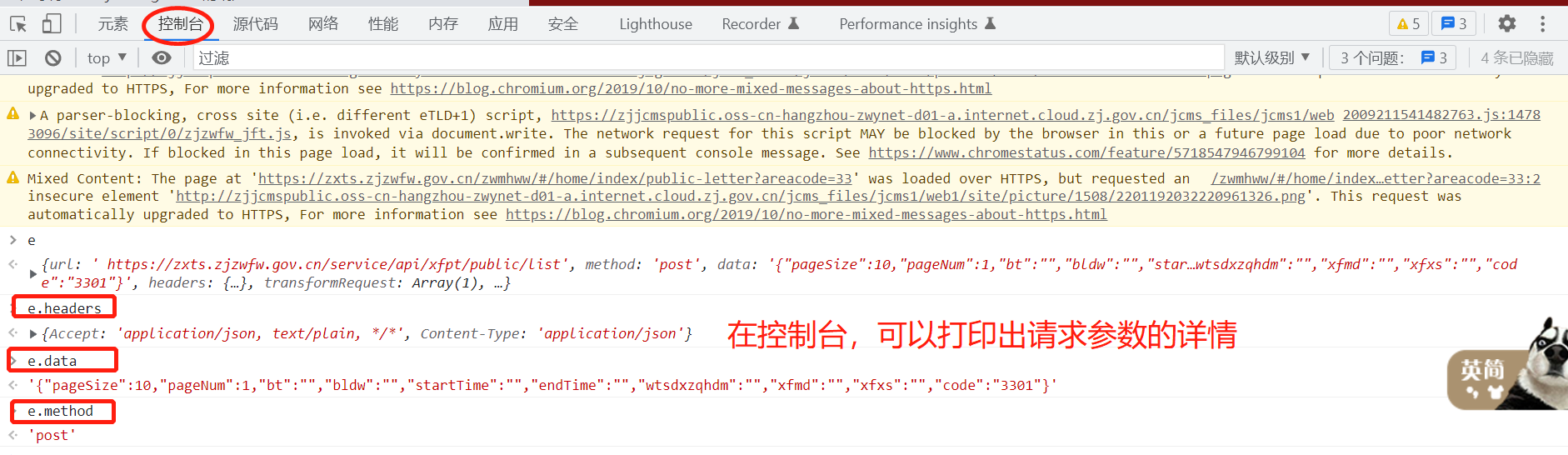
为了方便查看信息,我们可以在控制台打印输出:
我们已经知道了该网站的接口验证规则,重新构建我们的爬虫程序:

请求头添加了两项参数,表单数据的格式更换成json字符串格式,就输出了我们想要返回的数据。
3.5 爬虫请求
4 通过搜索关键字无法定位接口
上例中,我们在定位接口时用到了关键字搜索,但有的网站搜索不到,如下图中的大众点评
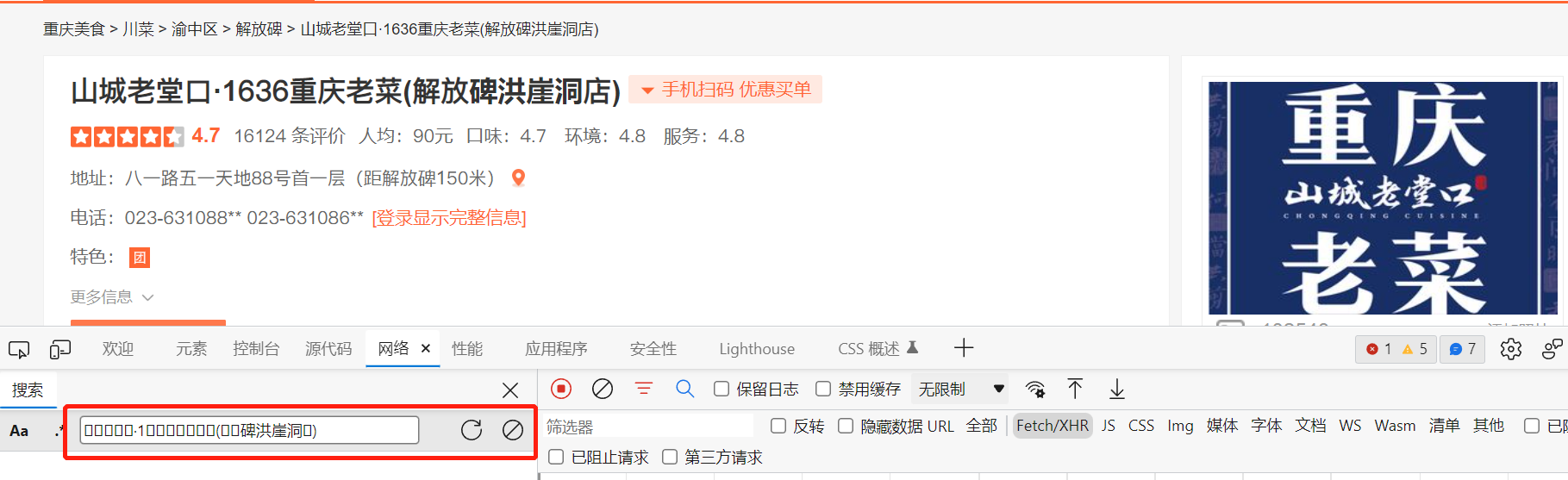
那么,我们需要先判断这个数据是动态数据还是静态数据。在文档过滤器中,所有的数据是静态数据。
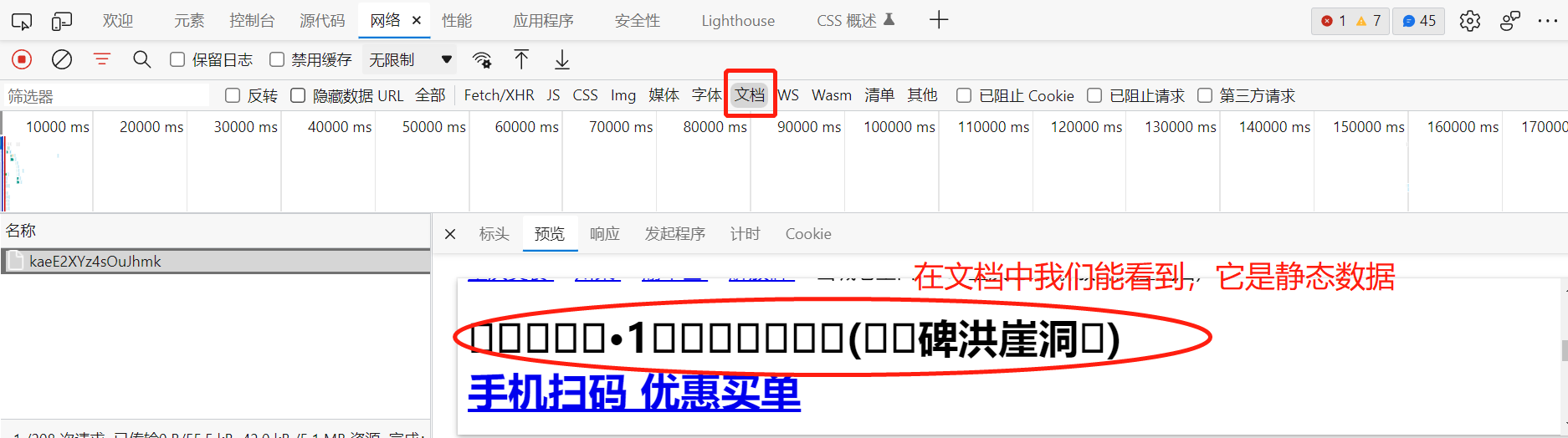
当确定它是静态数据时,我们需要进到它的纯静态HTML页面中,查看它的格式
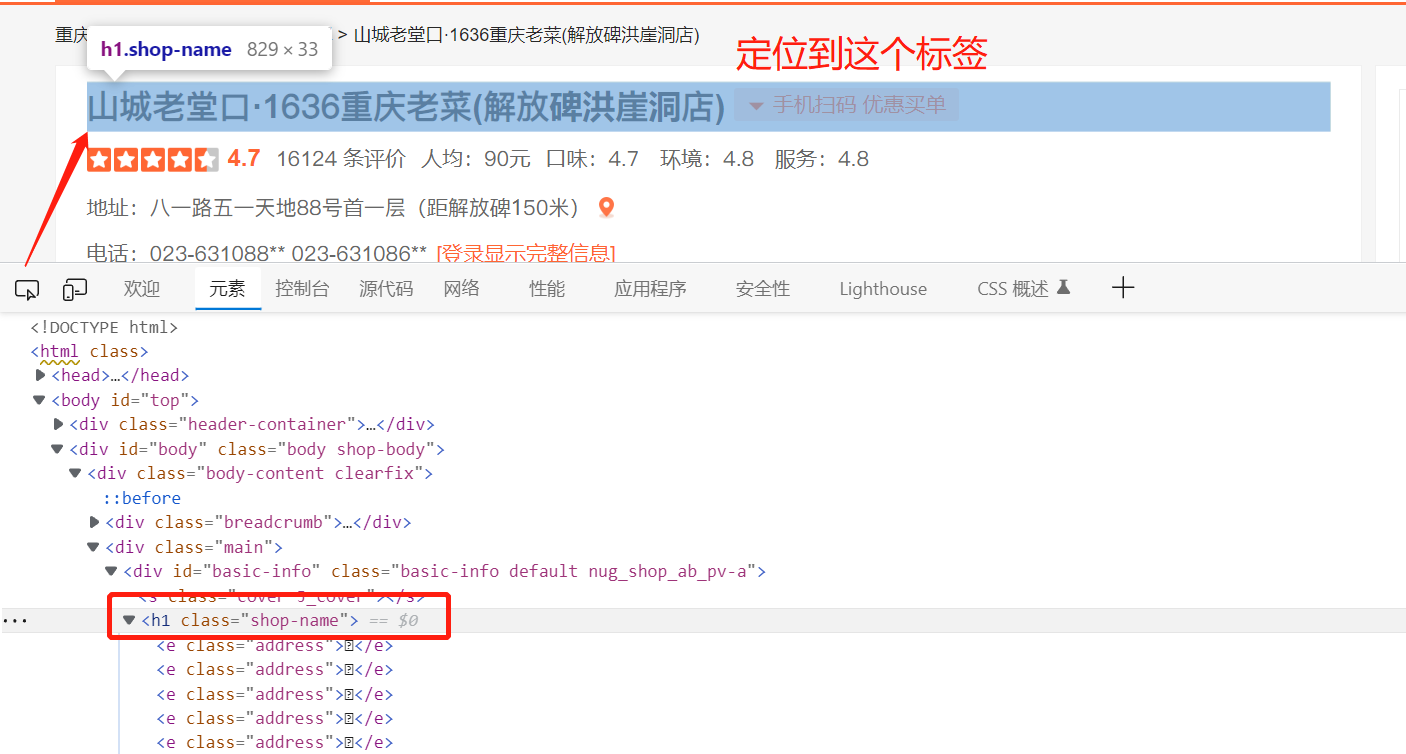
它的内容是?, 我们在纯静态文件中去搜索“shop-name”关键字
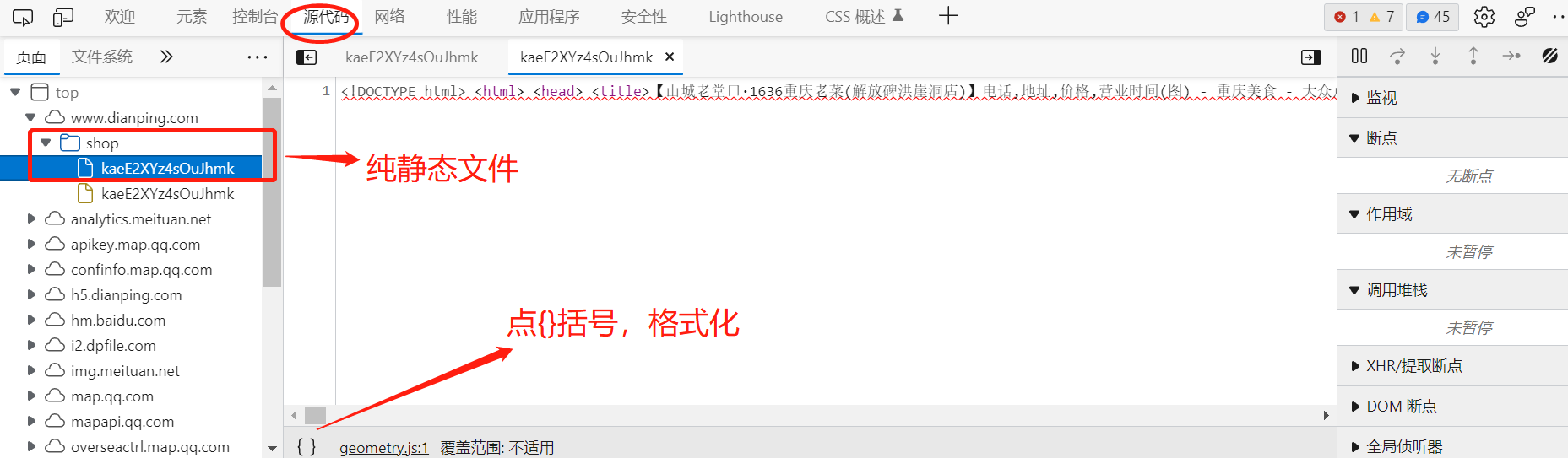

数据格式&#x ,为HTML实体编码,它是字体静态映射。
另外,还有一些网站通过关键字也无法搜索,比如巨量星图 https://www.xingtu.cn/ad/creator/market
我们通过搜索博主的昵称,显示找不到匹配项,接下来我们还是通过文档过滤器来判断数据是静态还是动态。
没有预览,说明数据是动态的。我们通过关键字搜索数字试一下,不带文件名后缀的才是接口,我们能看到响应数据。
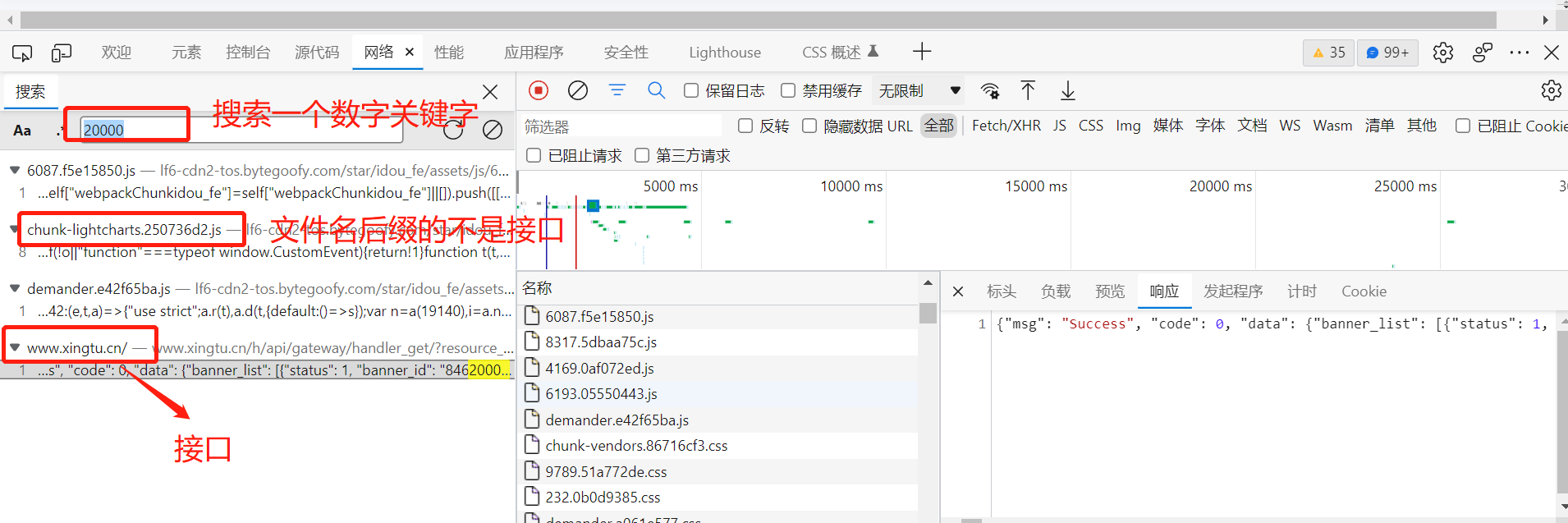
为什么搜索中文关键字搜索不到呢?因为中文是unicode编码,所以只有搜索英文或数字
在搜索不到关键字的时候,可以通过切换页数或切换标签的方法来定位接口。但是需要区分网站是静态加密还是动态加密,还有的网站,首页是静态加密,分页或下滑是动态加密。我们以这个网站为例:https://www.xiniudata.com/industry/newest?from=data
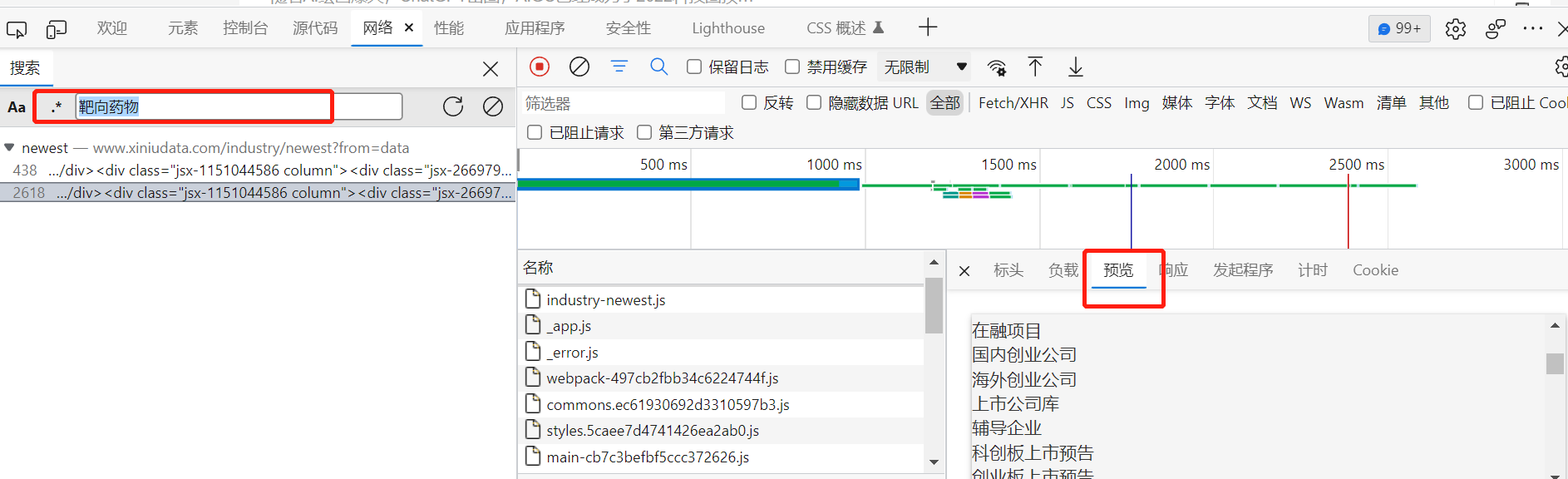
首页通过关键字搜索,预览里有数据,说明首页是静态数据。
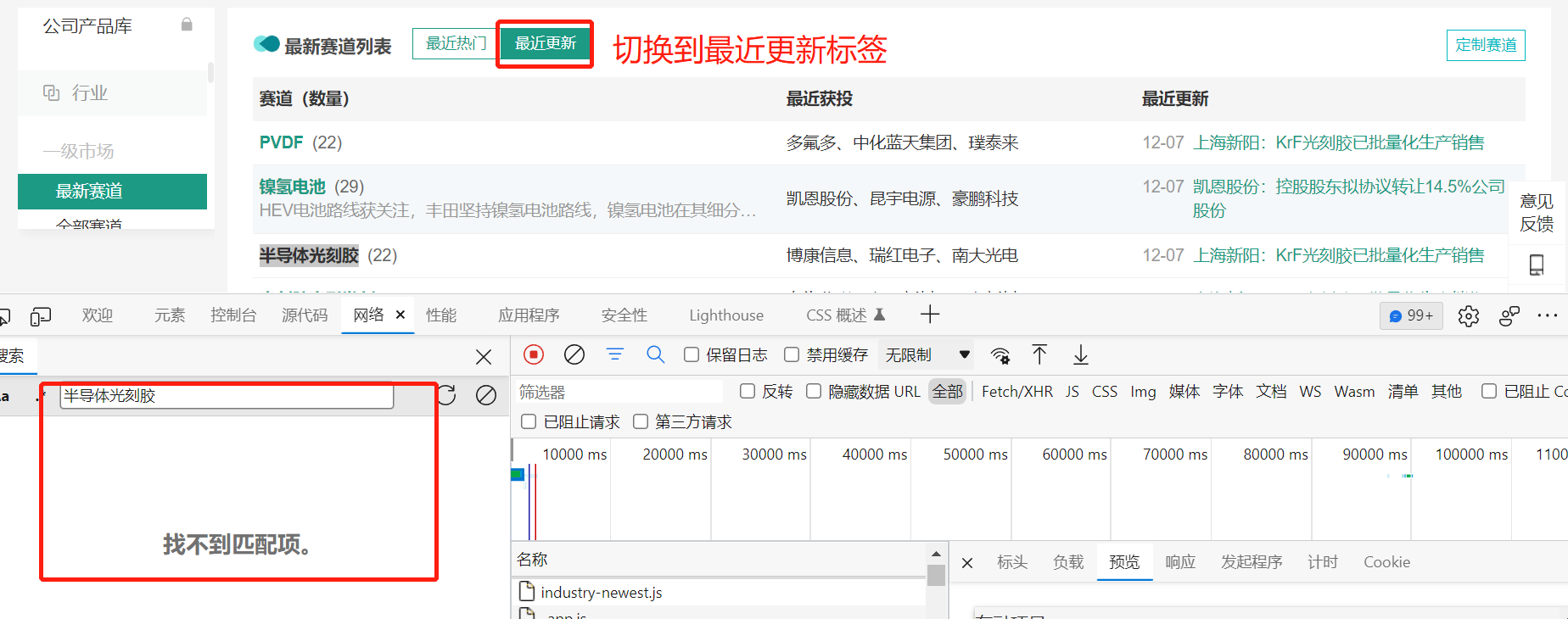
当我们切换标签到最近更新,再搜索关键字就搜索不到了,说明它变成了动态数据。
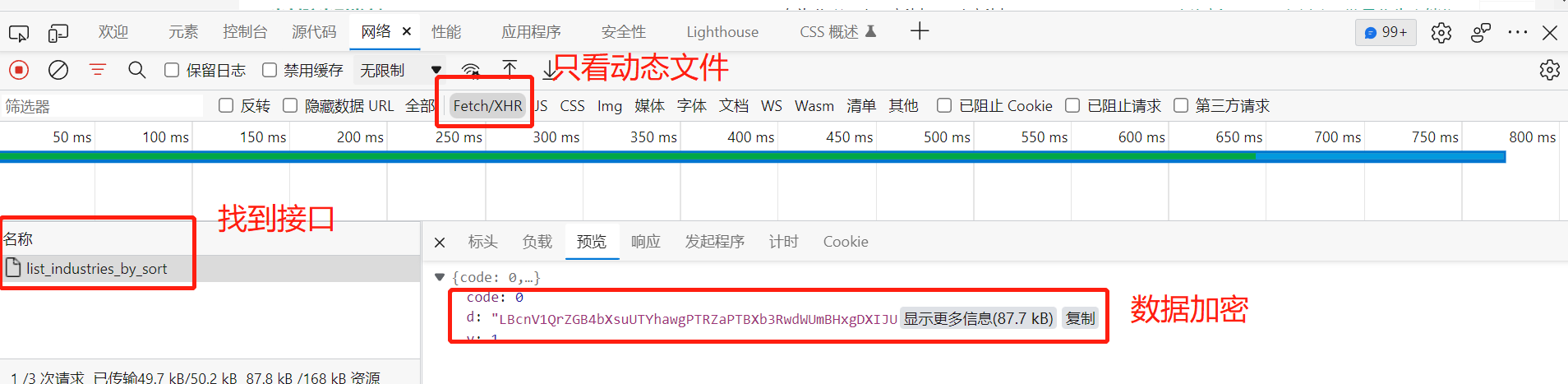
我们在首页,勾选动态文件过滤器,再切换标签,这时候会出现接口,但是数据是加密的。接下来我们要处理数据加密的问题。
5 数据逆向解密
我们在浏览器看到的是明文数据,但是在接口中看到的是密文数据。我们需要在整个网站中去找到关键的js的解密代码,找的是js后缀的文件。
5.1 混淆js
一般利用hook
5.2 无混淆js
主要掌握调试方法、扣js代码的方法、标准算法库。以下几种方法用来在无混淆js中抓取解密方法
1、接口自带关键字
以这个网站为例 : https://www.qimingpian.com/finosda/project/pinvestment
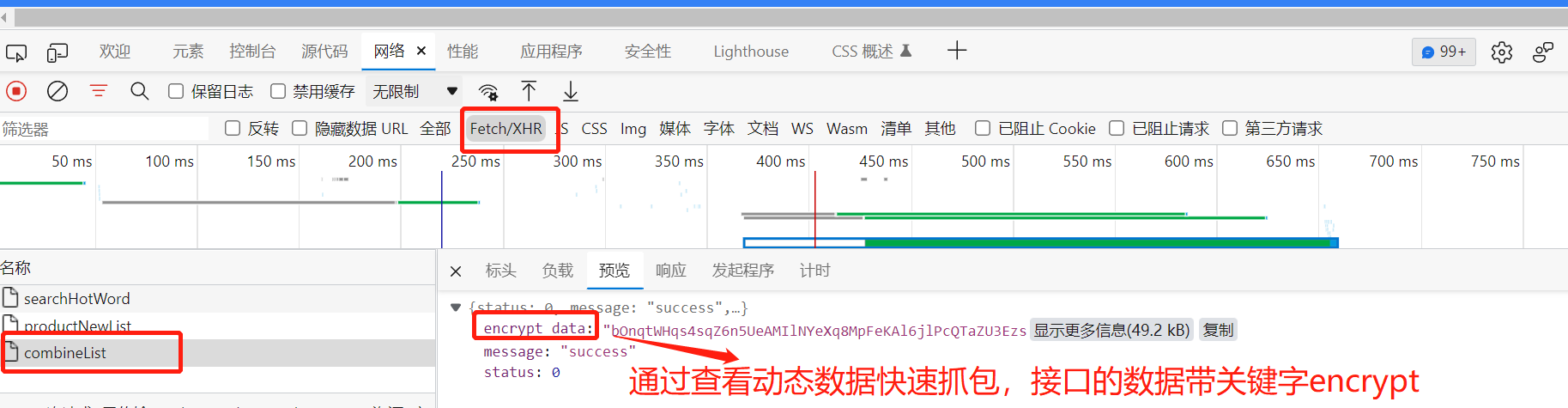
注意:关键字要比较特殊,很泛的关键字不行(比如上例中的d),接下来我们搜索这个关键字。
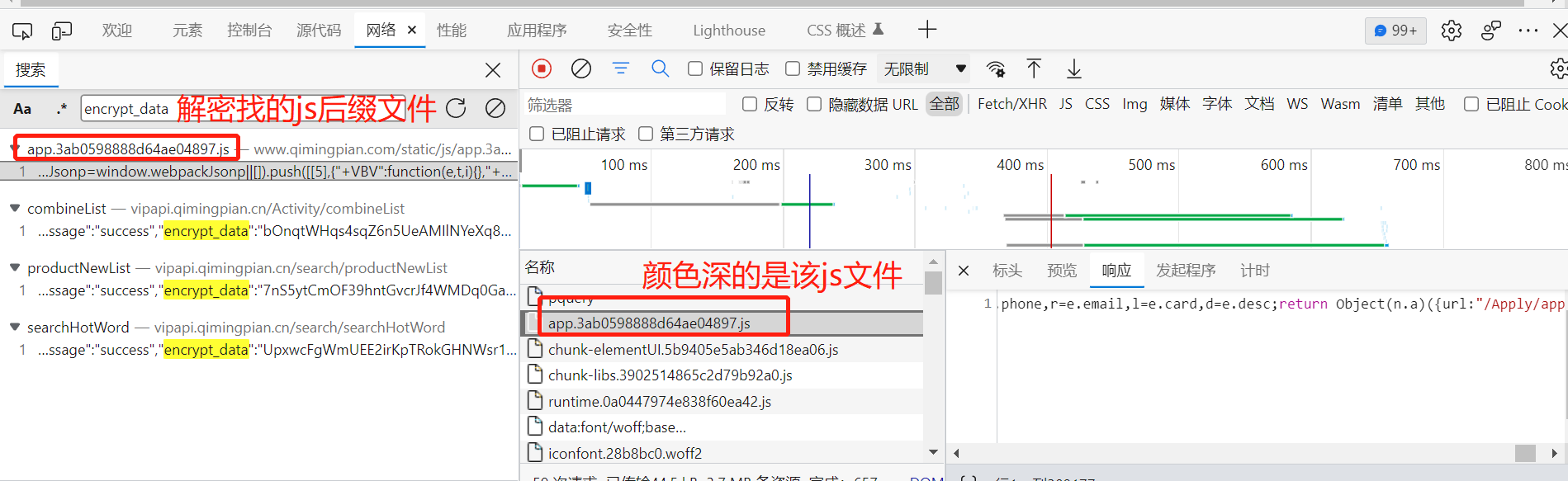
鼠标右键,选择在源面板中打开:
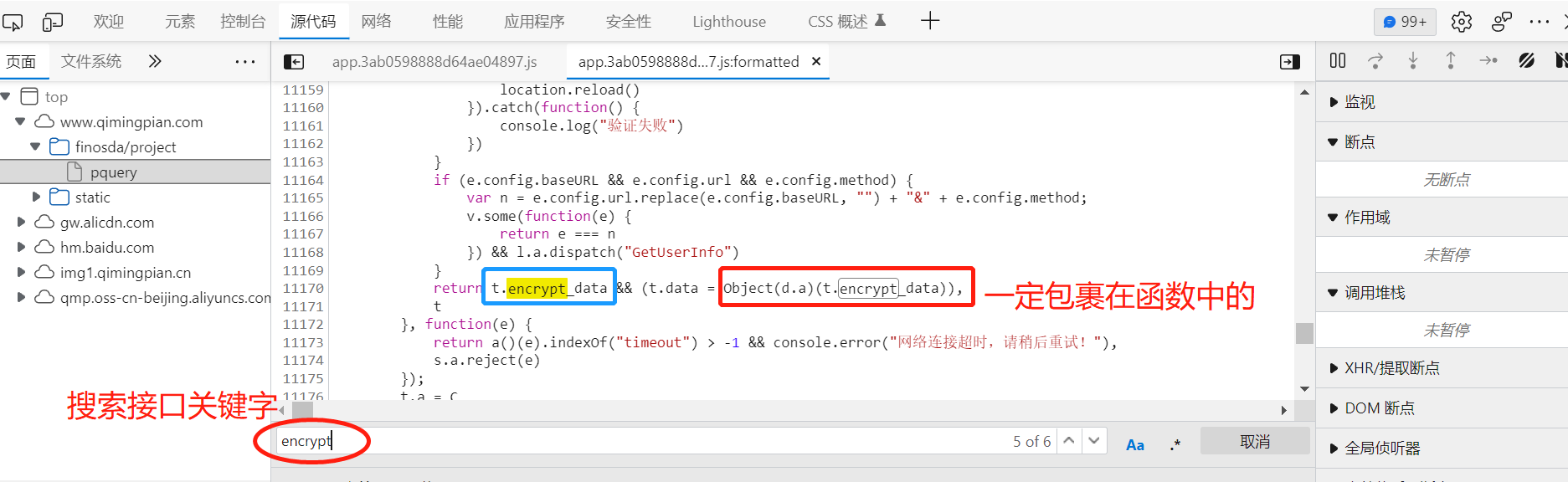
接口关键字是包裹在函数中,如 函数/方法(t.关键字) 或者 函数/方法(关键字),它是通过函数进行解密,注意排除一些图片url。
2、ajax异步渲染
再来分析 https://www.xiniudata.com/industry/newest?from=data ,通过切换标签找到接口,数据是加密的,并且无法通过接口关键字搜索
我们通过查看发起程序:
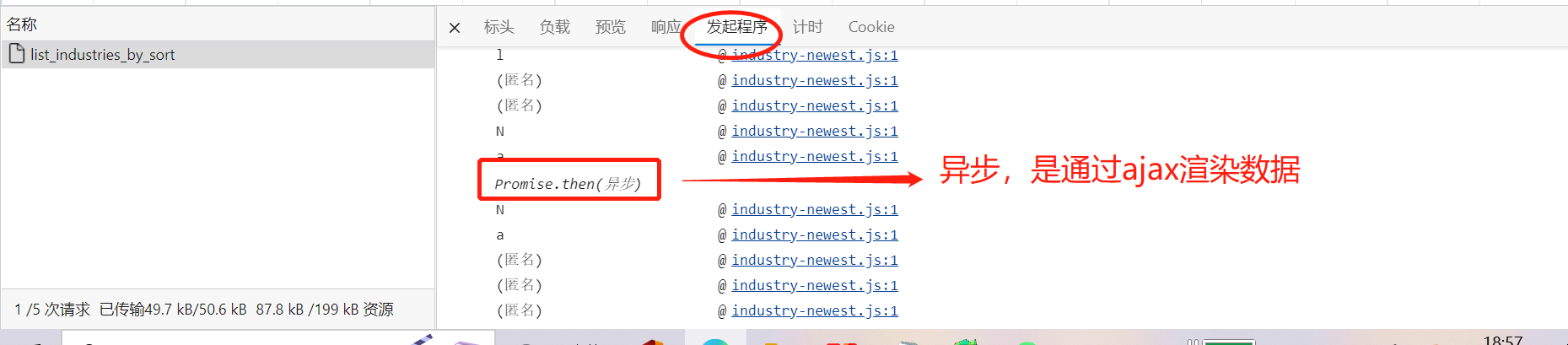
它是异步加载,通过ajax渲染数据,如果前后端分离,数据交互格式用json,因此我们可以用JSON.parse() 来搜索。
搜索条件JSON.parse(函数/方法),但是这个函数/方法不能是内置的,也可以定义一个变量 var a = 函数/方法,JSON.parse(a)

直接搜索JSON.parse( 会有大量的js文件,可以在发起程序找到接口的 js文件引导地址,进入后格式化,然后CTRL+F进行搜索 JSON.parse(
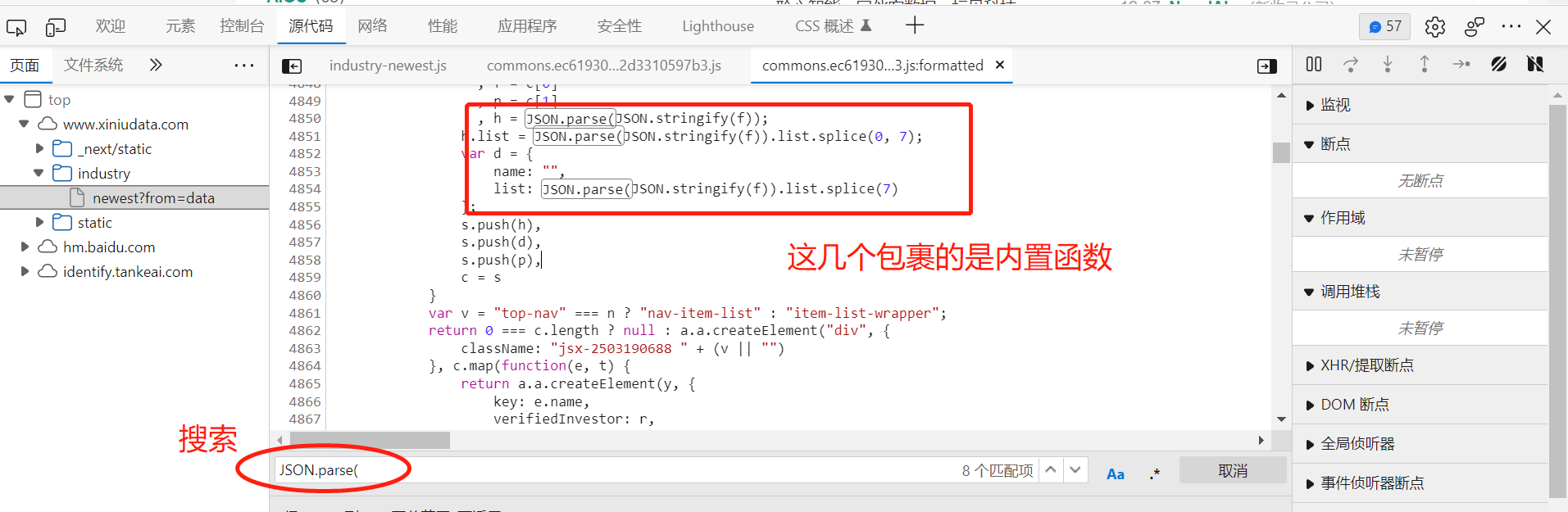
继续往下找

这个比较像,加断点进行调试,断点停止时,拷贝JSON函数,控制台中打印:

打印输出明文数据,这样就找到了关键的js代码
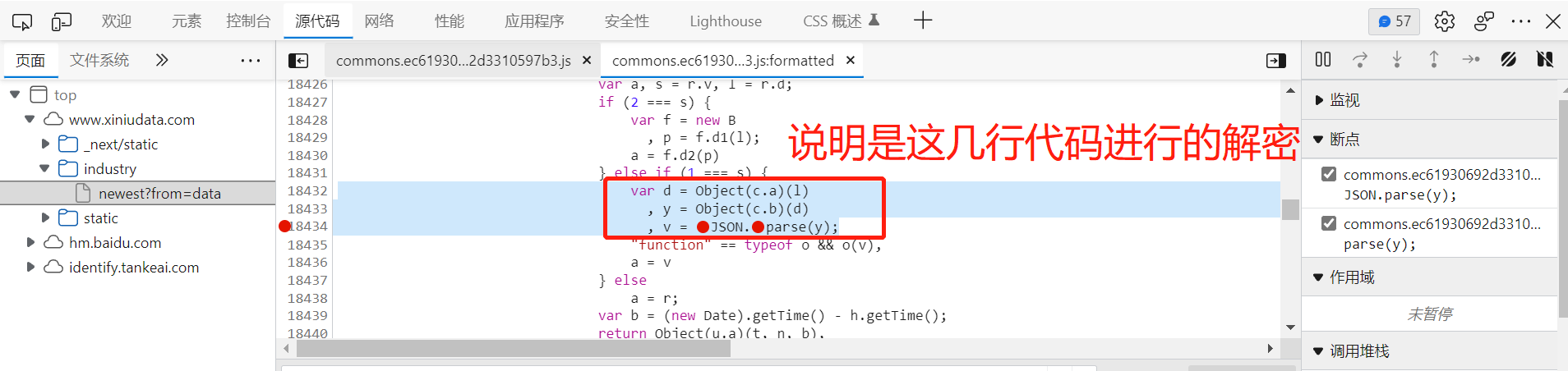
接下来,把这几行js代码拷贝到新建的javascript文件中:

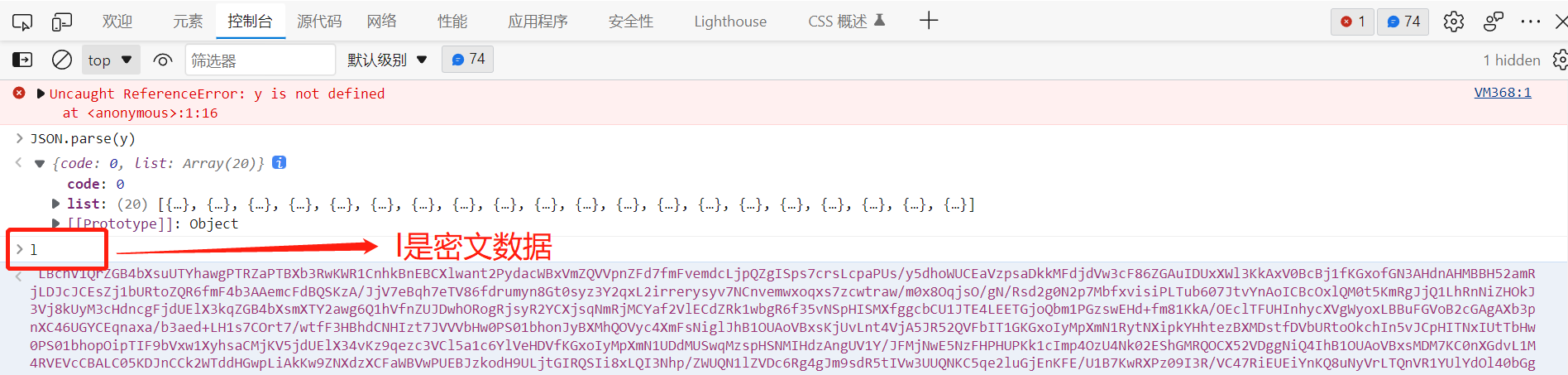
这里的 l 是从控制台拷贝出来的,因为函数中的l就是密文数据,在控制台打印输出:
现在要把l解析成明文,需要先把函数中a, b方法补全:
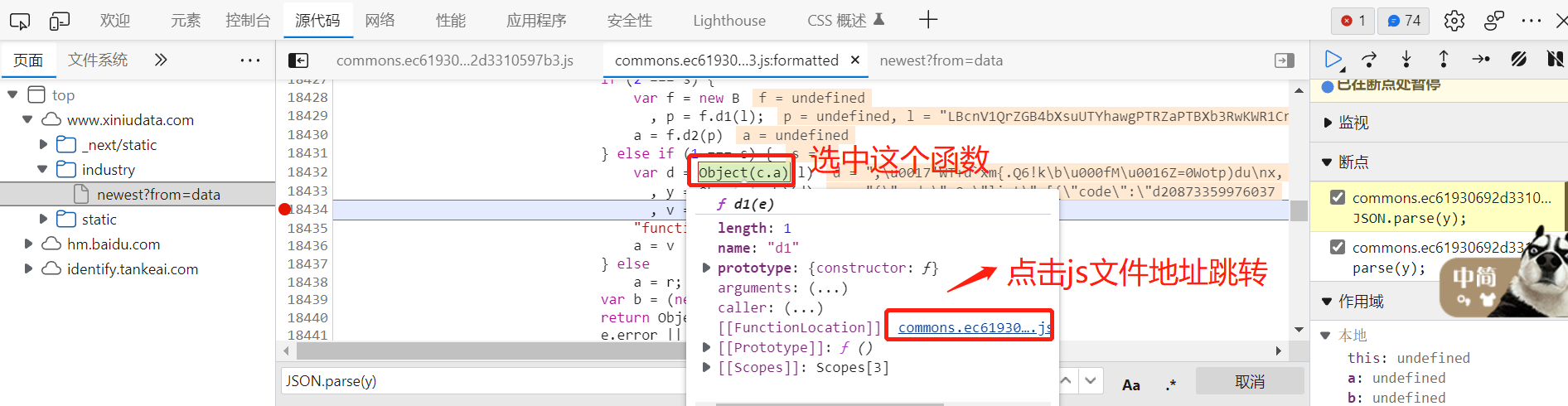
选中函数,点击js文件地址进行跳转,把两个完整的函数拷贝到新建的js文件中:
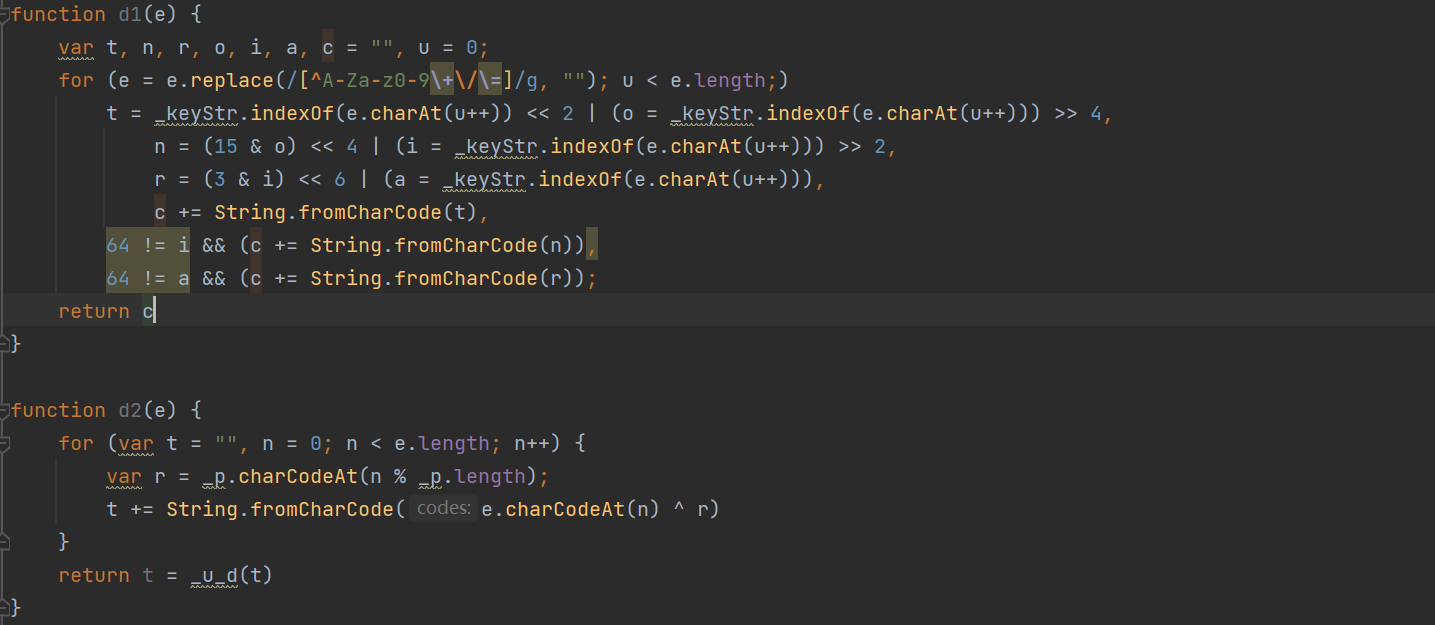
把Object(c.a)、Object(c.b) 分别换成 d1 和 d2:
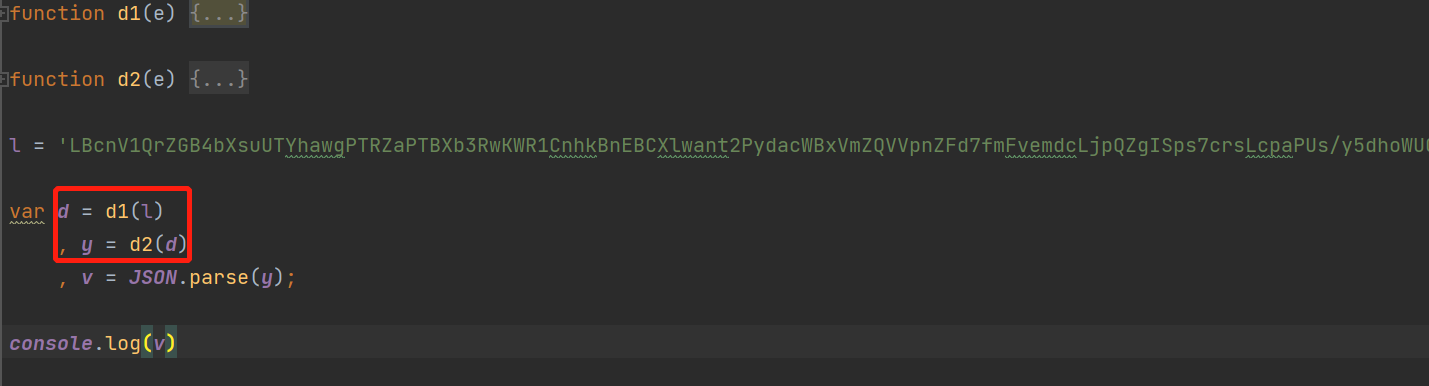
运行js代码,发现报错,因为一些变量或参数需要补全:
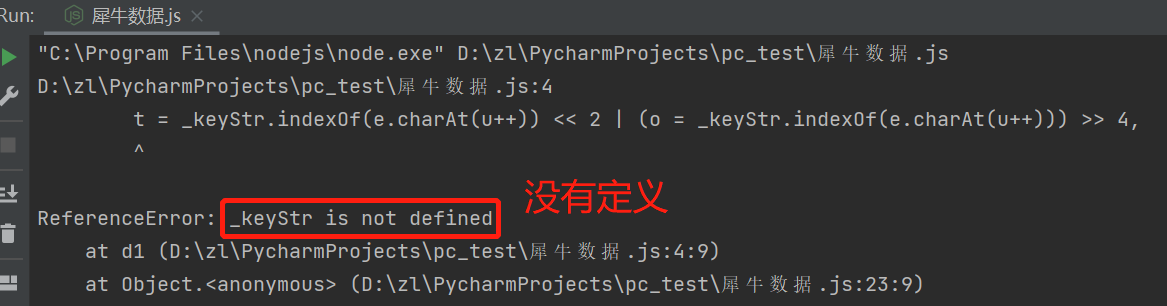
复制 _keyStr 到全局查找:
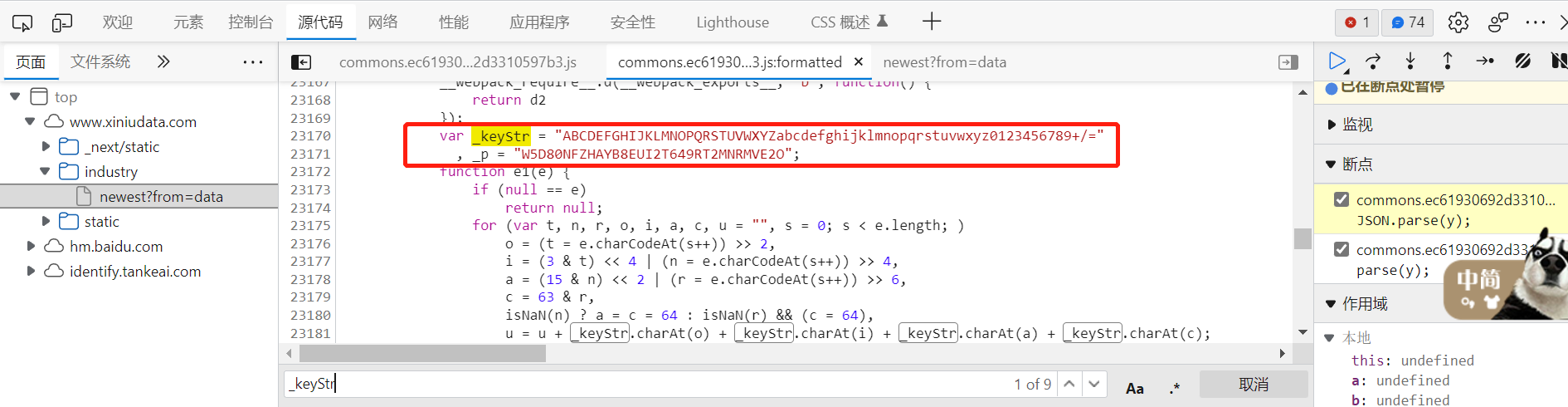
把这段全局声明扣出来,放到建新的js文件中:
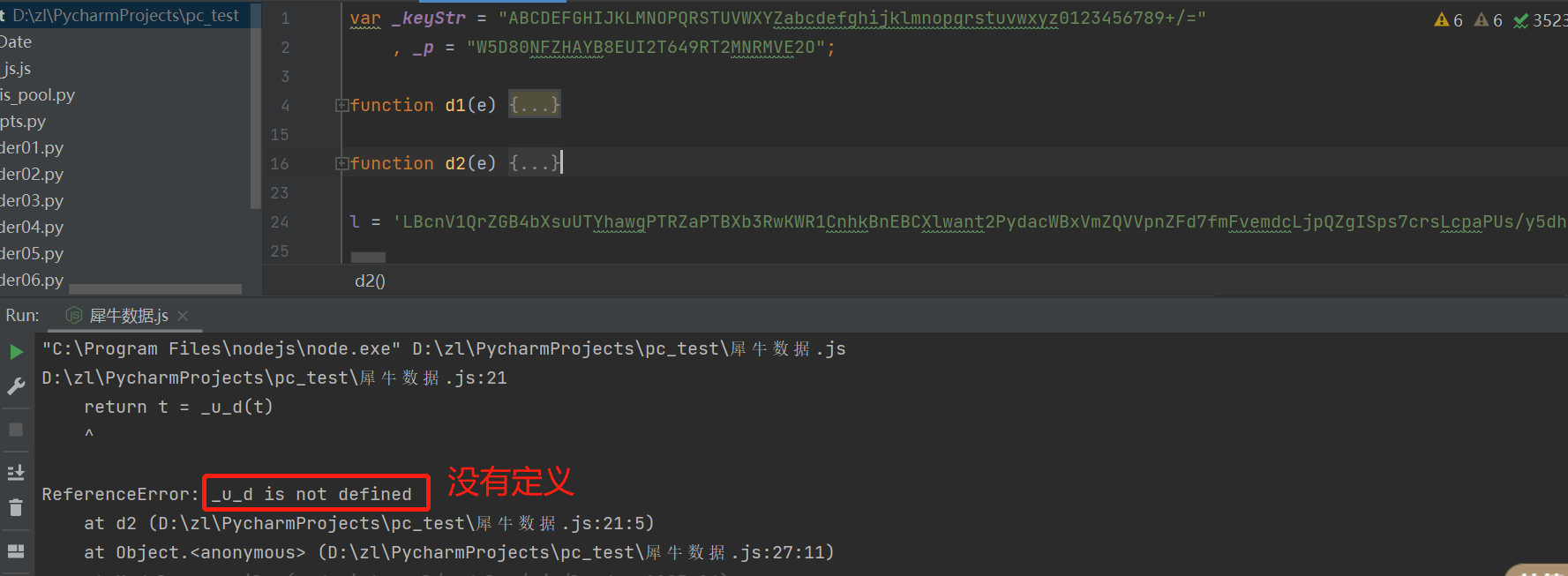
继续运行,仍然报错,_u_d也没有定义,它是d2函数的返回值,我们找到该函数,打上断点,浏览器下滑让断点停留
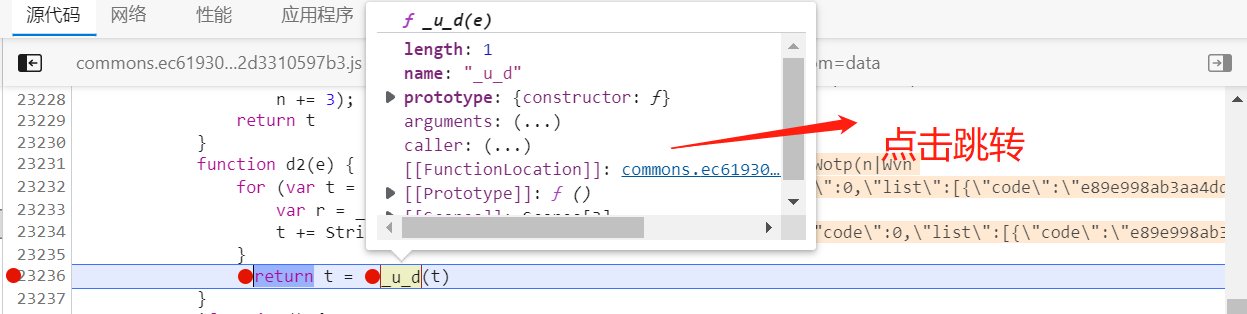
再点击跳转,找到_u_d的函数:
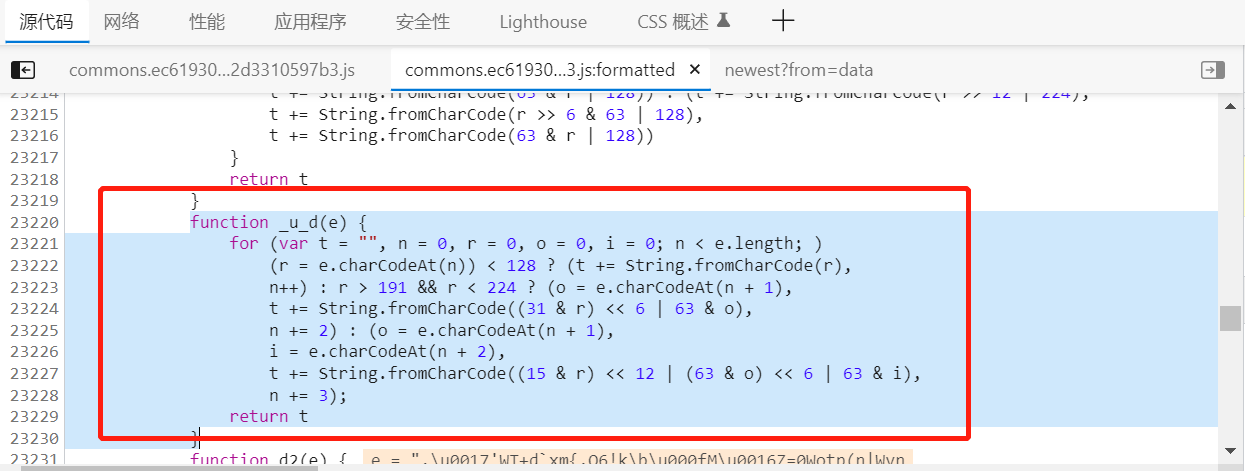
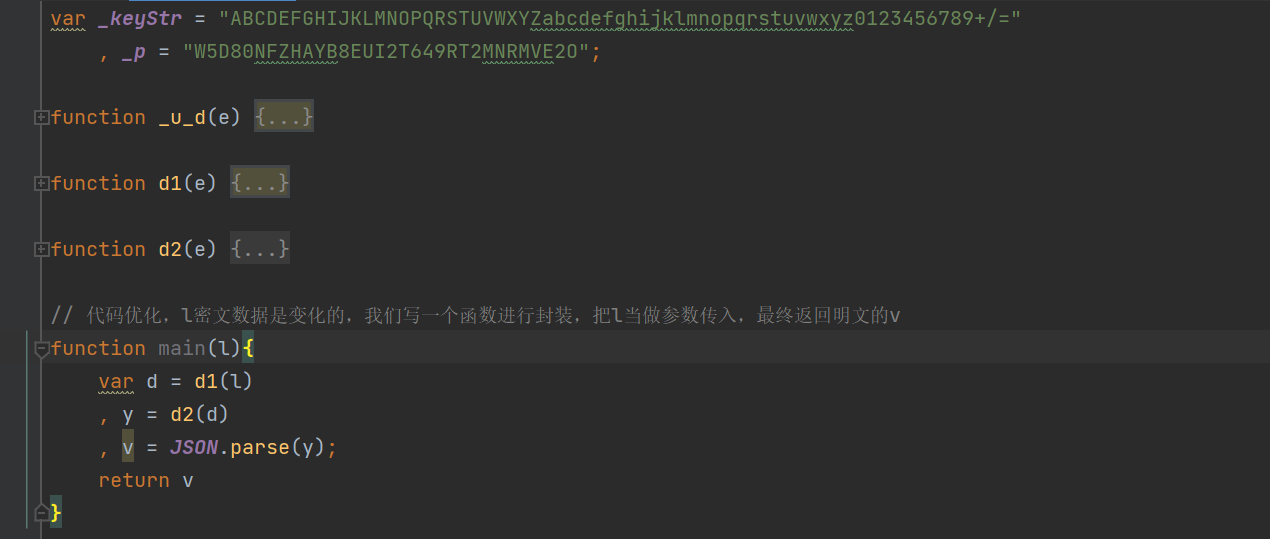
全部拷贝到js文件中,再次运行js代码,就会解析出明文数据,但没有跟python爬虫程序相互结合,接下来需要对代码进行优化和封装。
接下来在python文件中编写爬虫程序,可以用快速生成爬虫代码工具Convert curl commands to code (curlconverter.com)
找到网站接口,点击右键,选择拷贝cURL,放到代码生成工具中,直接生成爬虫程序代码:
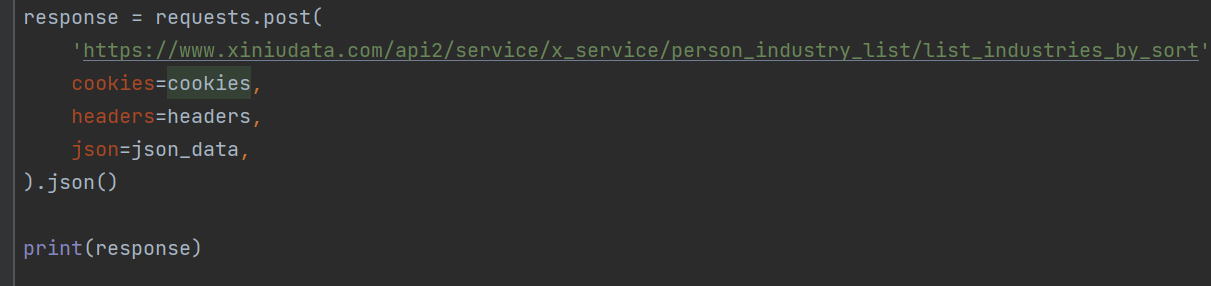
打印输出,能够返回密文数据:

密文数据就是response['d'],现在我们需要把data这个密文数据传给js文件进行解密
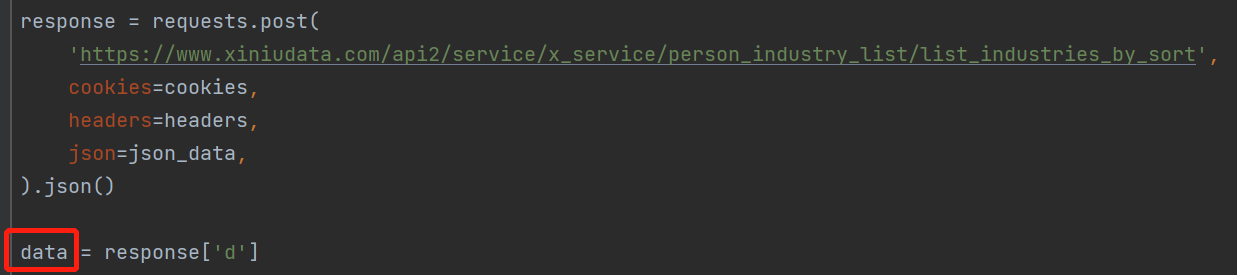
安装 pip3 install pyexecjs2 库,直接调用js代码
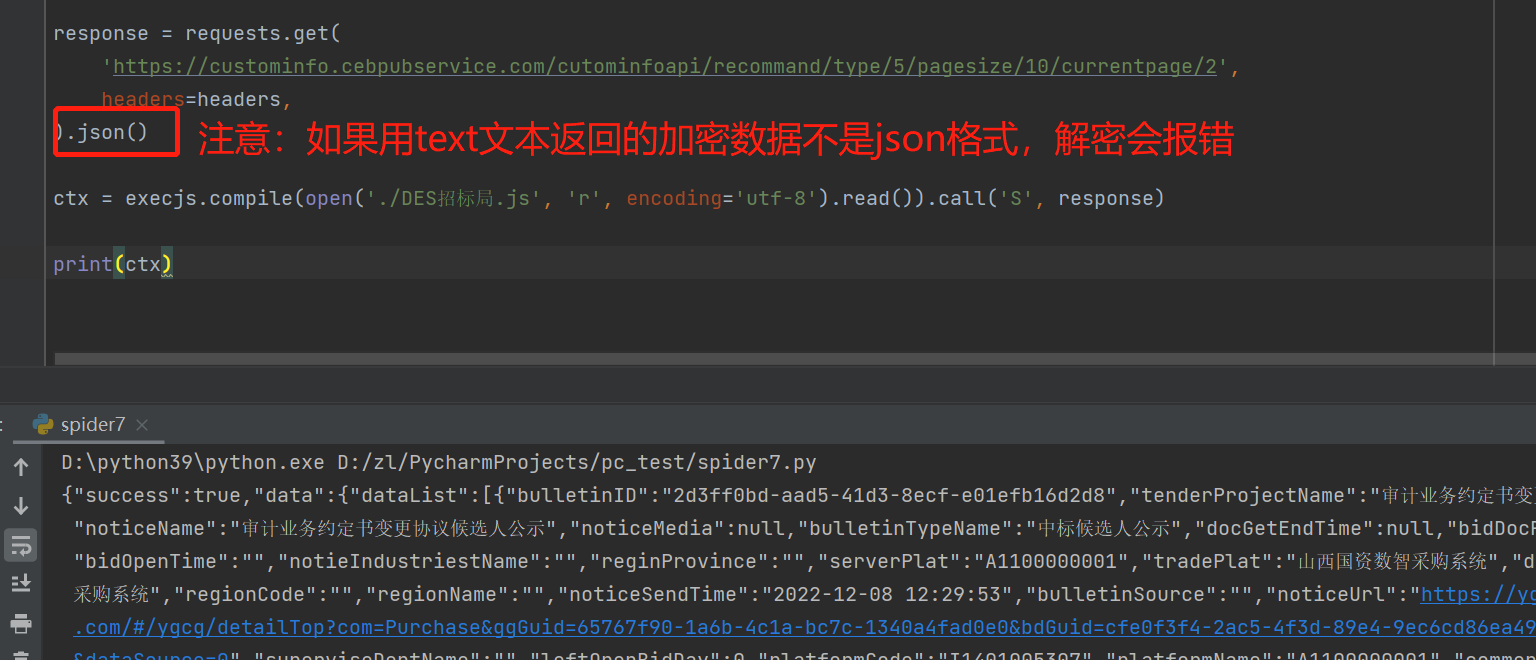
cxt = execjs.compile(open('./犀牛数据.js', 'r', encoding='utf-8').read()).call('main', data)
print(cxt)用execjs打开js文件,调用main函数,并传入data数据,最终返回明文数据。
3、decrypt()方法
安装标准算法库
>npm install crypto-js
安装完成后,在node模块下,找到crypto模块,他是node.js的标准算法库,里面包含了各种标准算法文件。
我们以这个网址为例 http://ctbpsp.com/#/
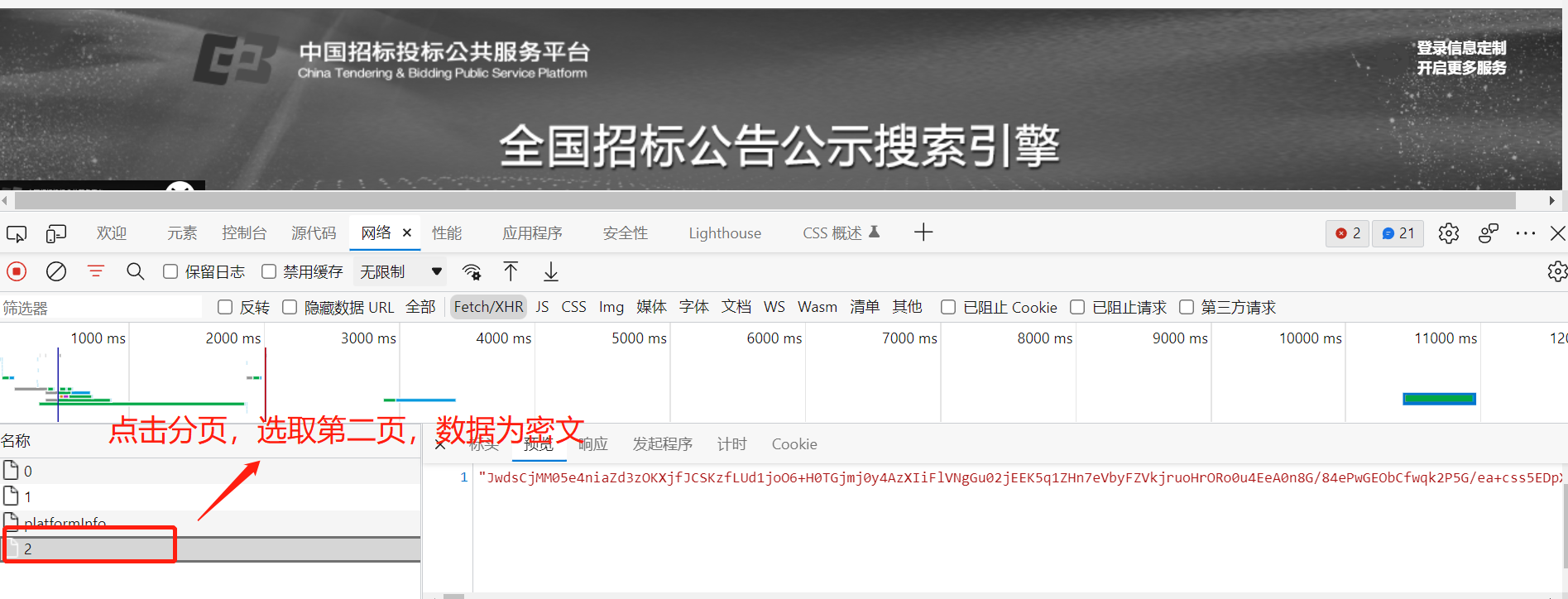
抓包数据,切换页面,定位接口,返回密文数据。找到接口,点击右键复制cURL(bash),到工具网站构建爬虫程序代码:
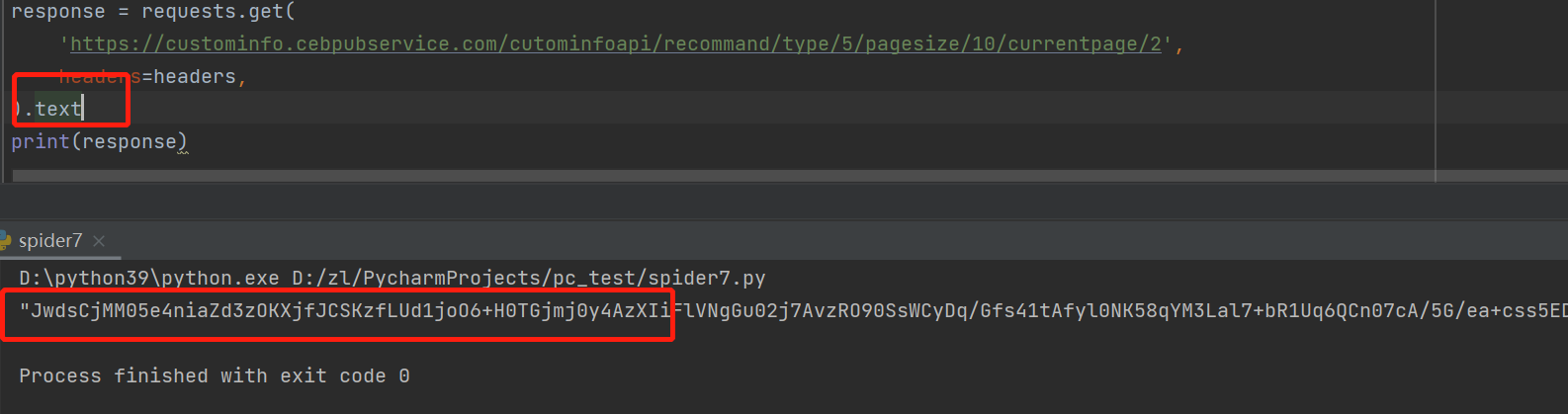
打印输出,得到密文数据。注意,用text返回的字符串带引号,用json(),返回的才是json字符串,它是一个json对象,不带引号:
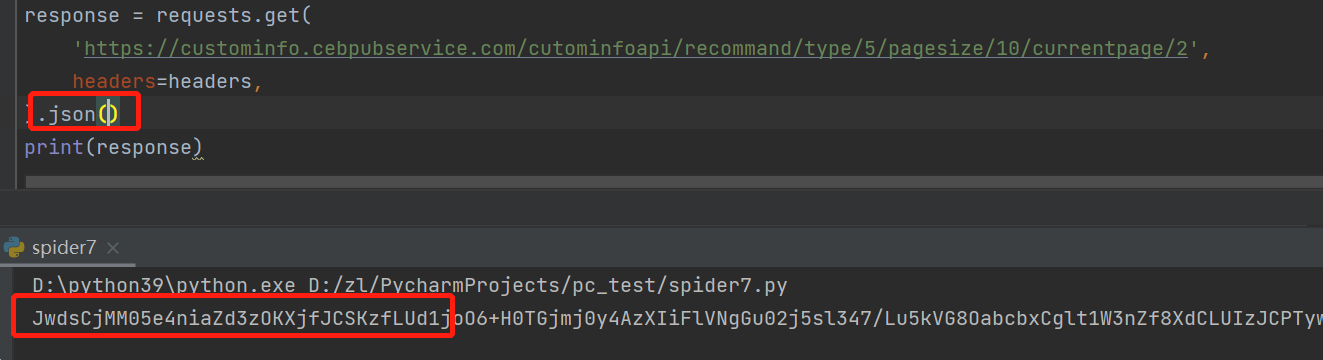
我们在浏览器调试搜索 decrypt( , 查找js文件, 搜索出来有两个:
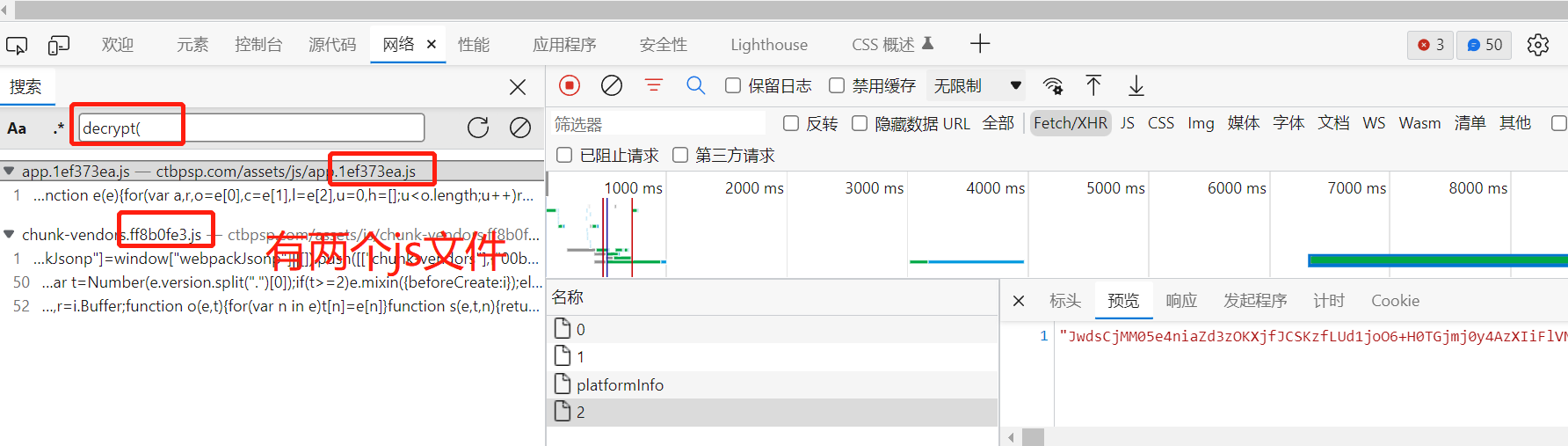
可以通过发起程序去找具体的js文件,也可以通过结合搜索,再搜索路由找到js文件:
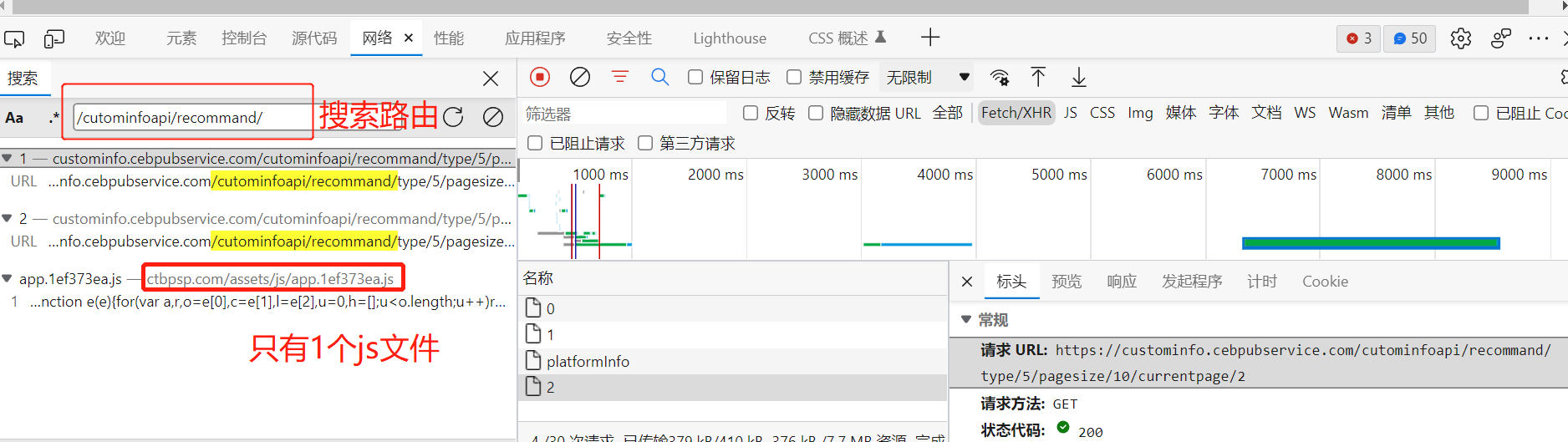

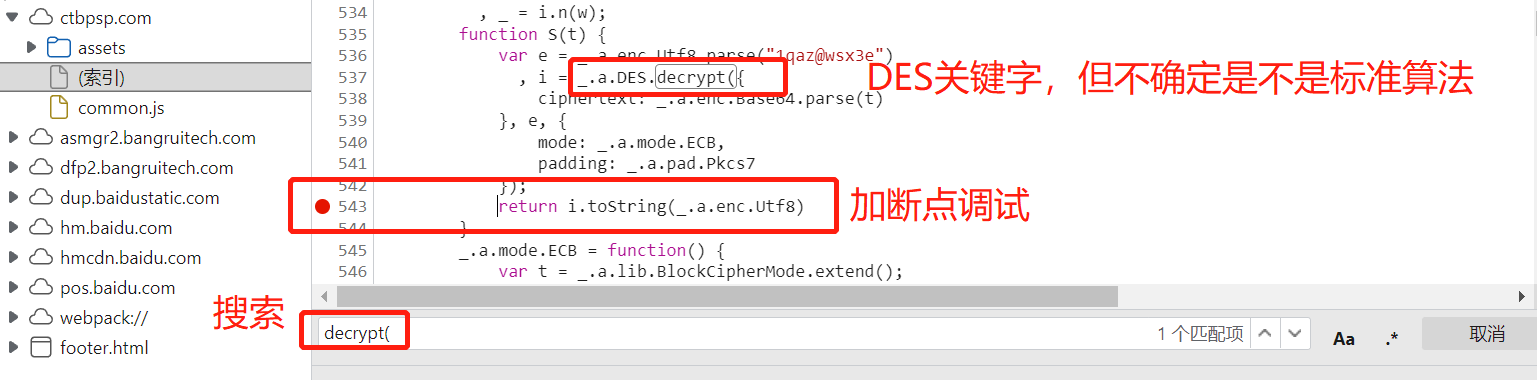
点击分页,断点停止后,拷贝断点到控制台进行打印:
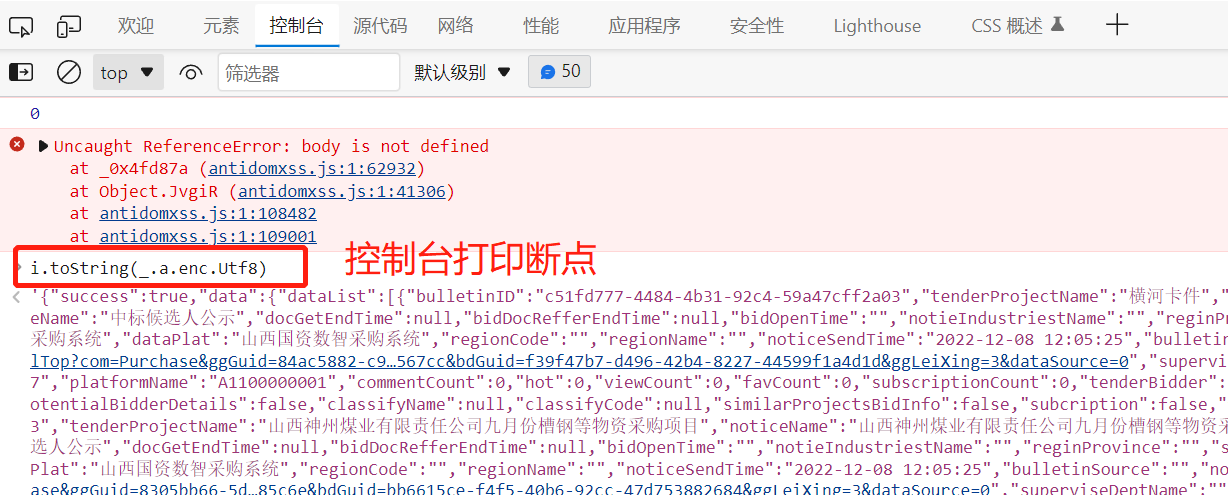
输出明文数据,说明这是它的解密方法,我们把这段代码拷贝到一个新建的js文件中:
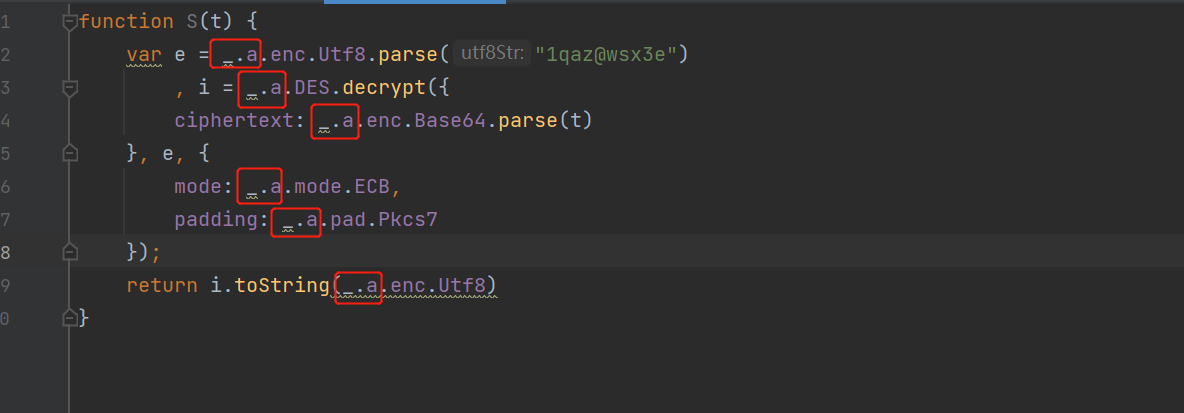
发现这段代码所有的对象都来自与 _.a, 我们在控制台去打印 _.a看看它到底是什么内容:
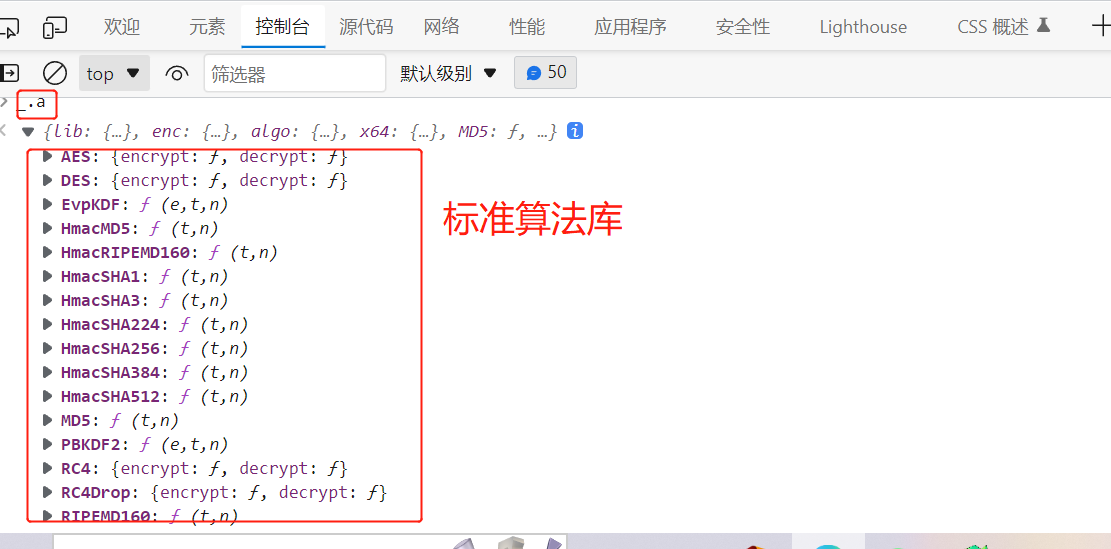
既然 _.a是标准算法库,我们在自己建的js文件中,导入标准算法库进行补全:
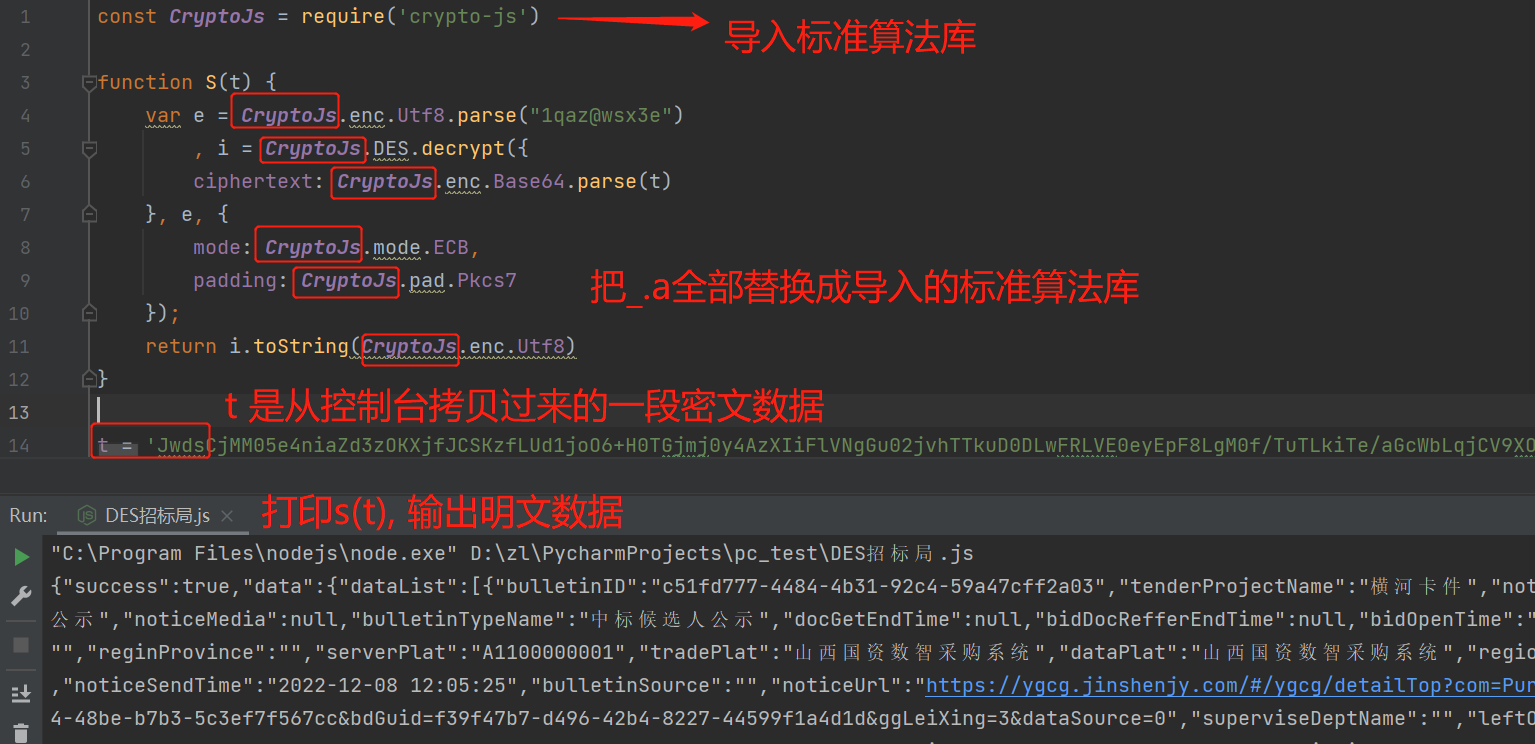
找到解密函数后,同样把它跟我们的py爬虫程序相结合:
爬虫程序负责爬取加密数据,用execjs库打开js文件,调用解密函数'S',并传入加密数据,最终返回明文数据。
6 加密类
加密类的特性: 我们需要找到它的加密规则,它是以什么样的方式进行加密。
服务器在验证加密类参数的时候,它是不知道结果的,因为加密类参数一直处于变化过程。服务器是通过它给浏览器的规则进行验证的,只有规则验证成功,你才能成功获取到数据。
加密类是在request之前做的事情,解密类是在response之后做的事情。
6.1 混淆js
6.2 无混淆js
1、接口自带关键字搜索
请求参数或请求表单是加密内容,但是自带关键字,自带的关键字一般有相对应的拼接,一般有以下两种拼接形式:
key : 函数/方法(需要被加密的内容) 或者 "key" + 函数/方法(需要被加密的内容)
我们以 https://www.theone.art/market?type=copyright 网站为例
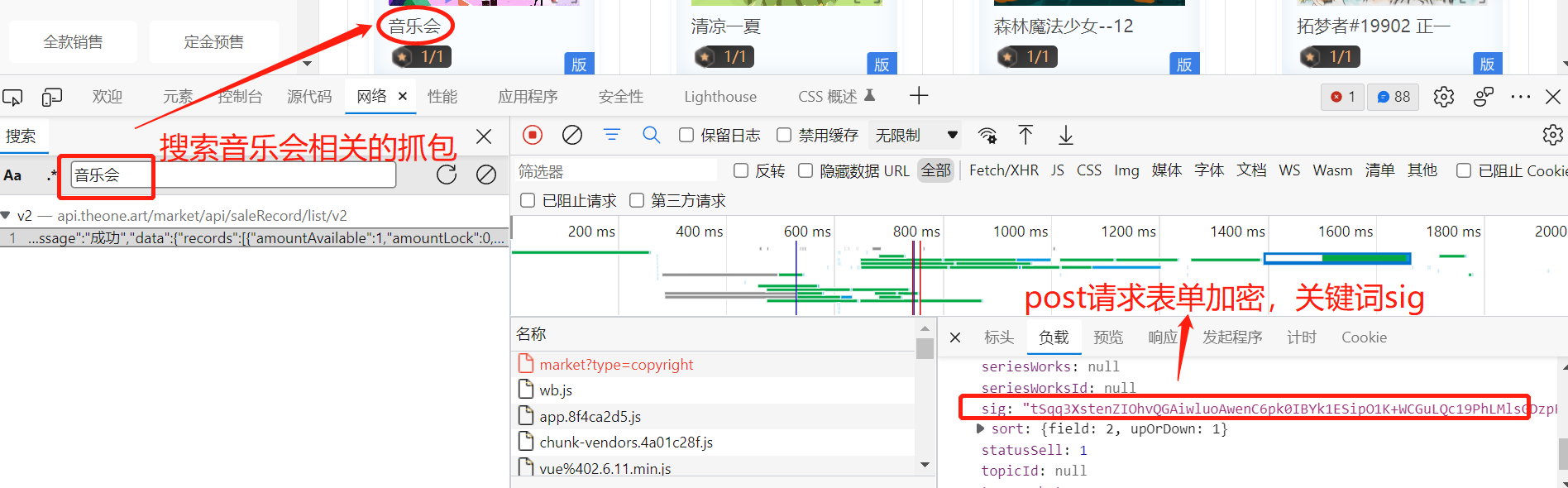
我们想要通过关键字 sig 搜索表单参数,确发现这个词太泛了,搜索出很多内容。 我们用 sig: 搜索,得到的是接口文件,我们现在要找的是请求参数加密类的关键js文件。我们利用一个小技巧,post请求会有data数据,我们尝试 sig.data 搜索,找到js文件,右键源面板打开:
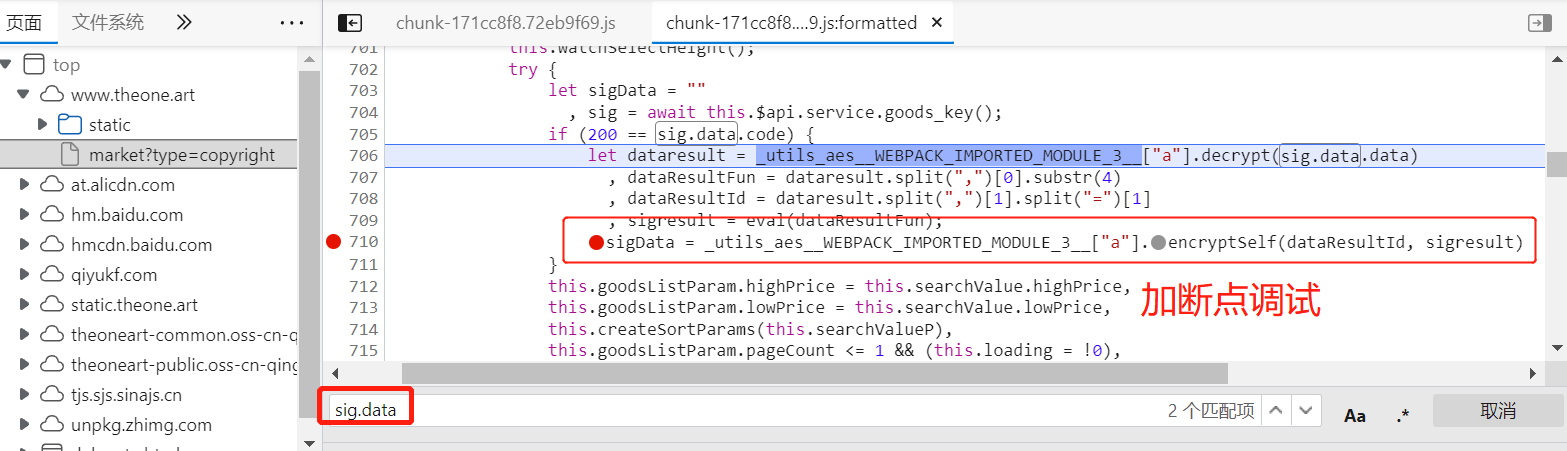
拷贝断点出的函数,放到控制台中打印,输出对应的加密内容,这个就是sig的值:

关键字搜索的技巧就是结合, 关键字+data (表单) 关键字+parse (参数) 关键字+headers (请求头参数) 等。
2、标准算法库进行的加密
搜索 encrypt( 方法
3、跟栈
在请求之前所生成的参数,我们需要向上跟栈。 在响应之后所生成的参数,我们需要向下跟栈。
4、hook注入
通过关键字进行注入, 比如有些接口自带关键字,但通过搜索搜索不到。 我们以 http://www.iwencai.com/unifiedwap/result?w=5g&querytype=stock 为例。
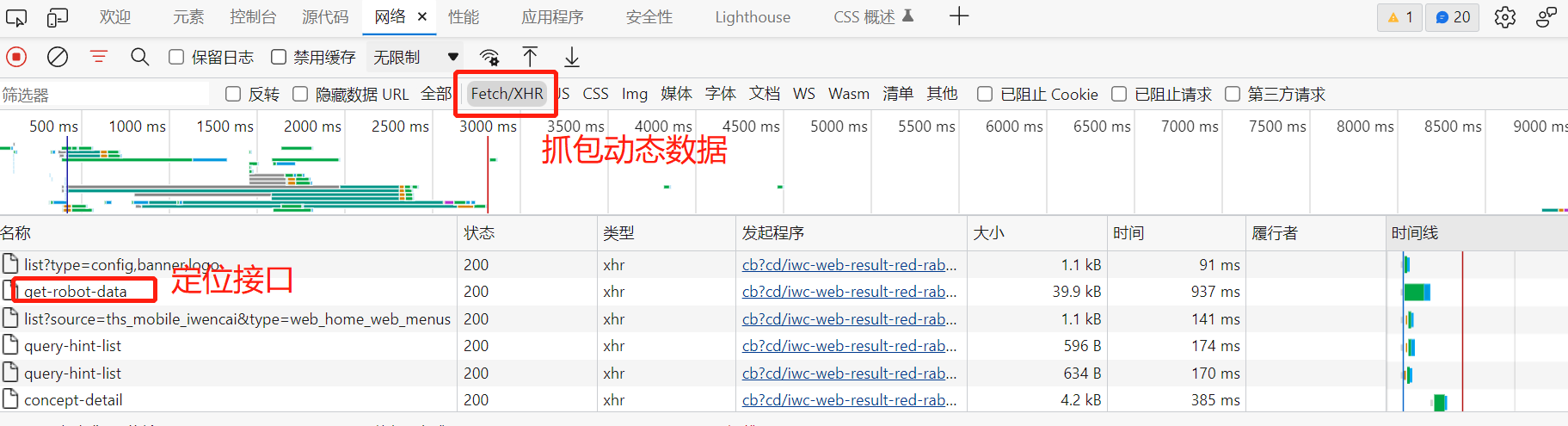
我们全局检索,看是否存在加密内容,在请求表单中没有密文,但是请求头中有一行加密内容。
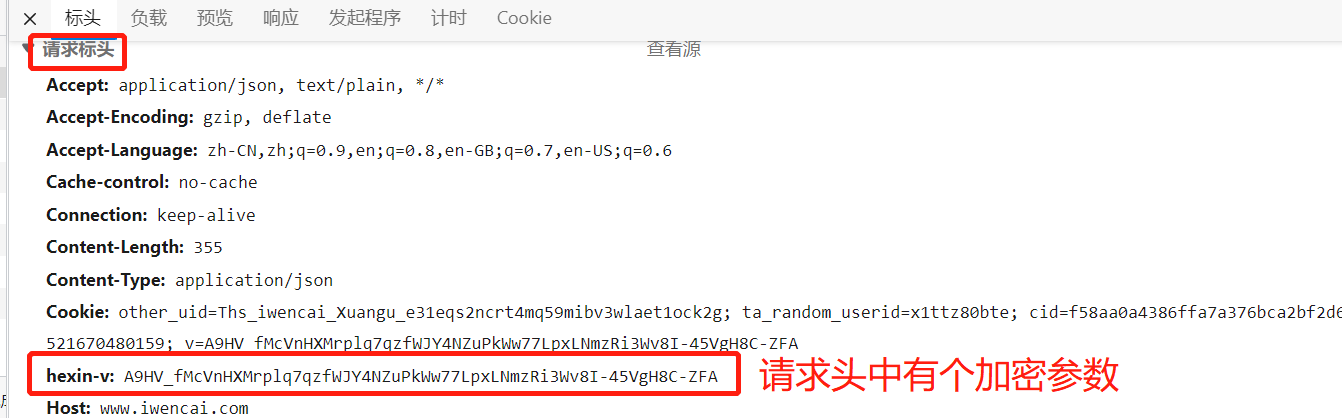
我们通过关键字 hexin-v 以及结合 data\headers等词进行搜索,都无法搜索到js文件。
这里,我们可以利用hook定位关键字,hook注入,一般是固定模板,需要修改的仅是关键字部分,可以直接在控制台进行修改,不需要借助任何工具。需要注意的是,当我们刷新浏览器页面时,它会重新加载。
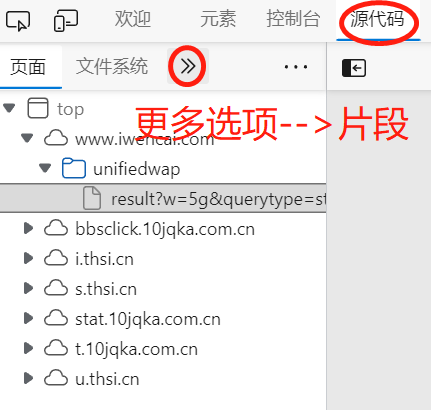
通过源代码,在更多选项中选择片段,新建片段,写入hook代码:
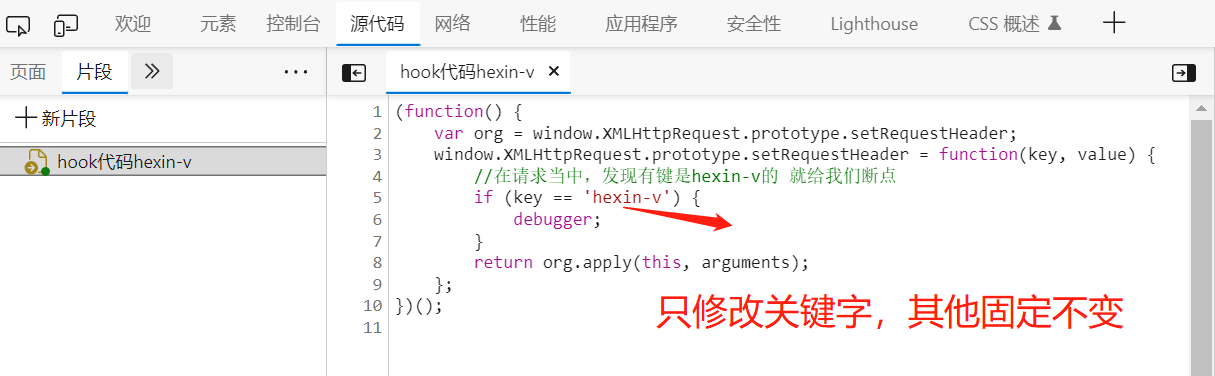
JS逆向常用hook代码: https://blog.csdn.net/qq_29340905/article/details/127727028
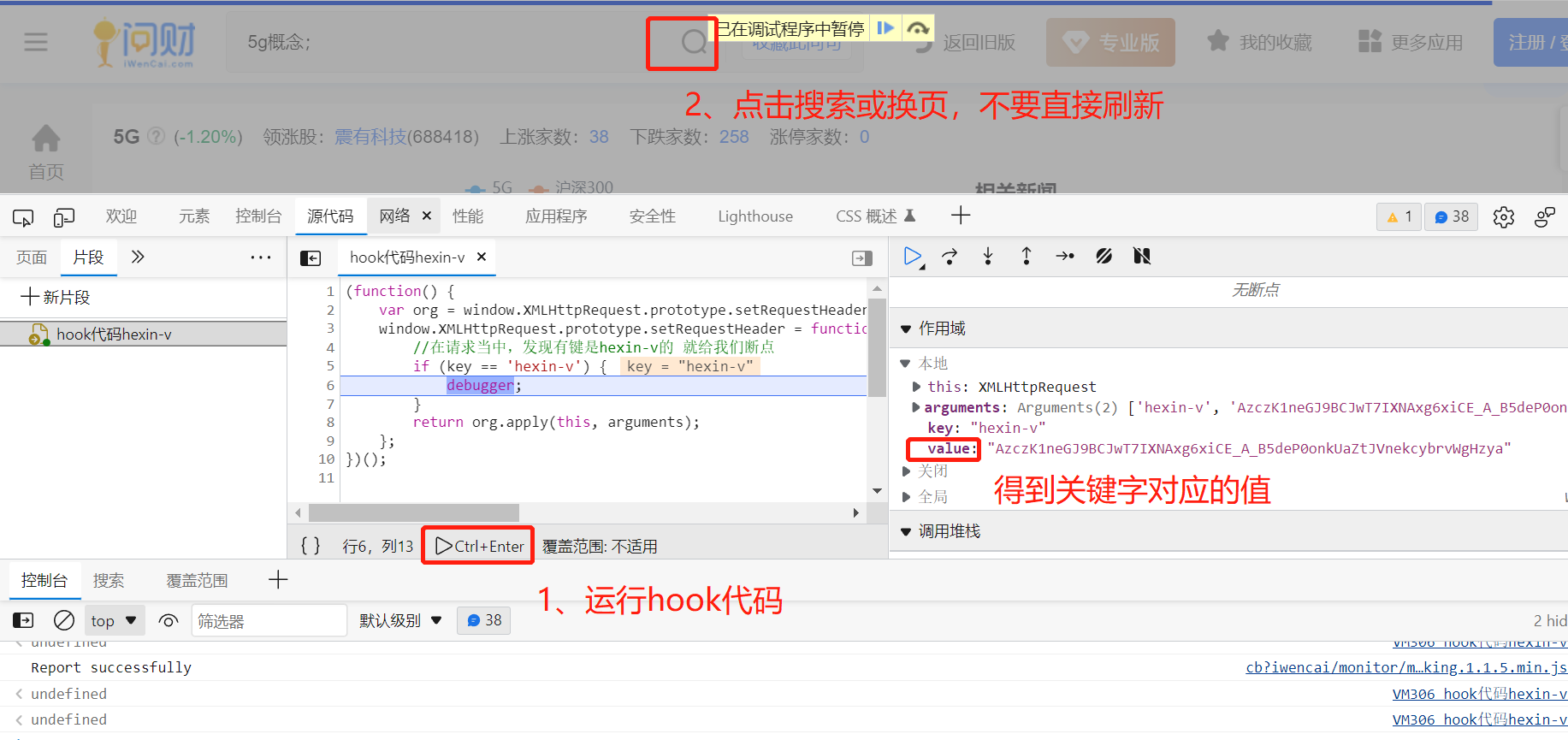
注意点:不要刷新页面,因为会重新加载,不会断点停留。
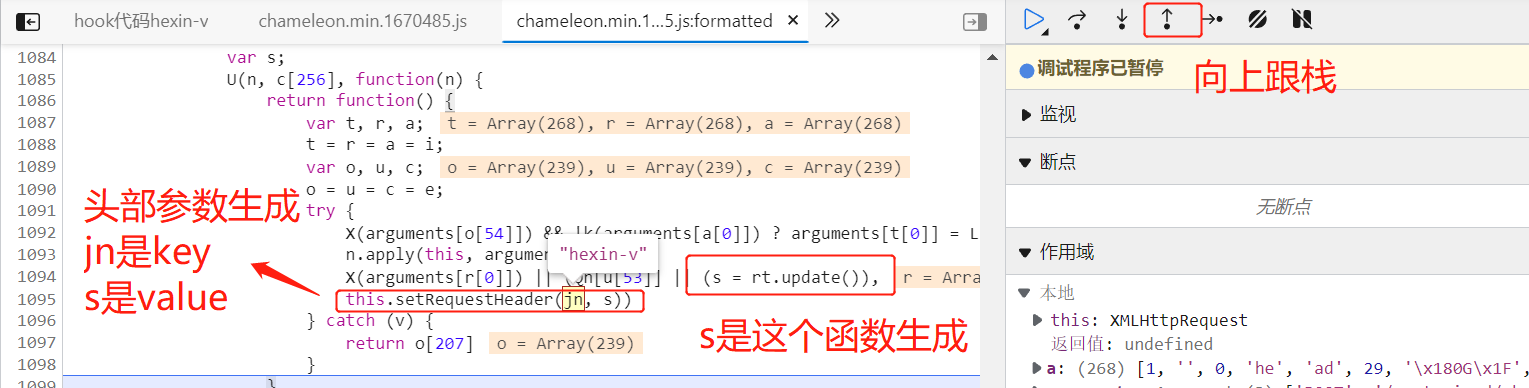
我们现在需要向上跟栈,找出这个值是由什么生成的。
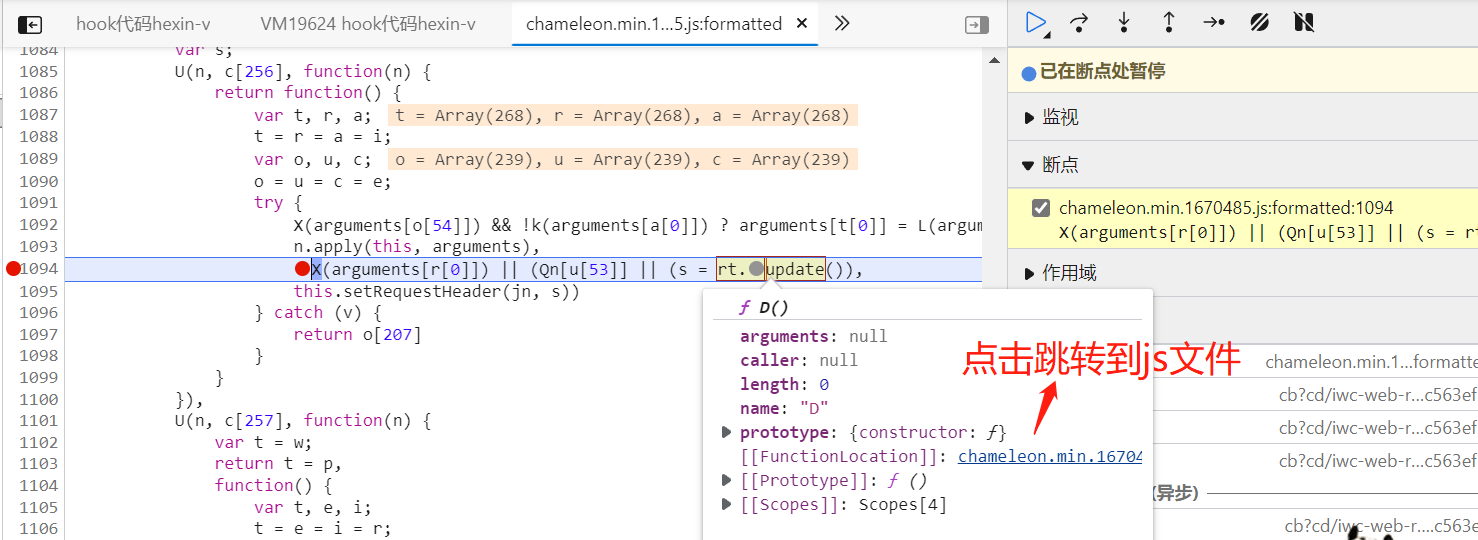
我们在生成 s 的这行代码打上断点,释放掉之前的断点,重新搜索,断点停留在这行,鼠标放上去找到该js文件的具体位置,进入它函数的本地地址。

我们把这段代码拷贝到新建的 js 文件中。 我们再继续找 o 的生成,它是 D 函数的返回值。
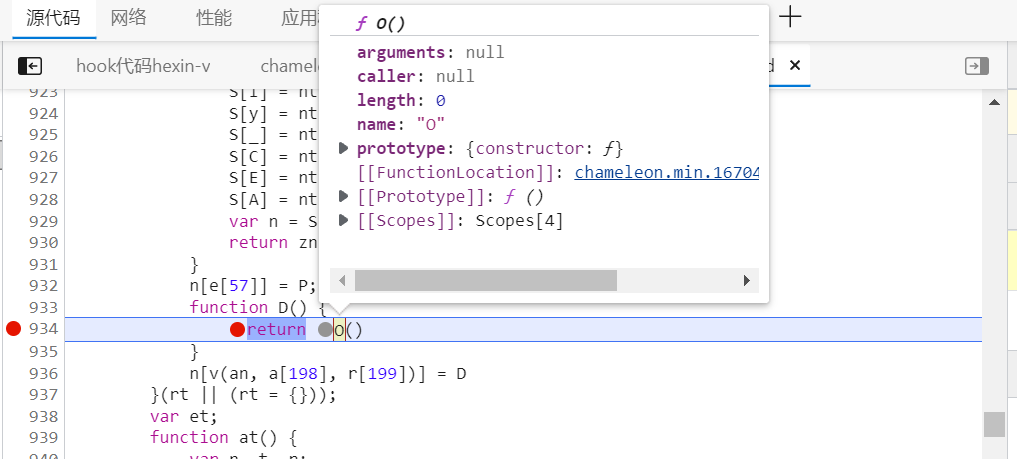
给 o 打上断点,执行脚本运行,走到断点时,查看它的生成的本地函数地址,点击跳转:
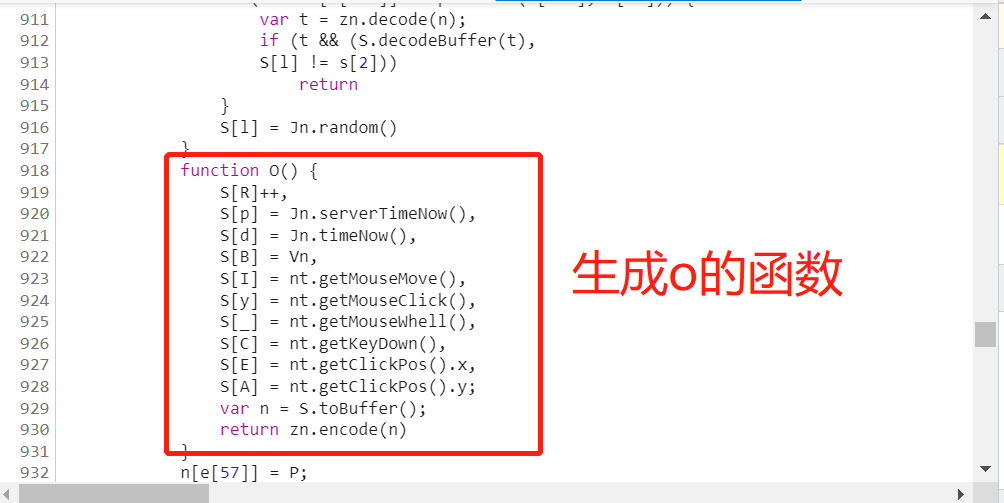
找到生成 o 的函数,把它拷贝到我们新建的js文件中,它是一个特殊的js代码,它调用了很多外置的对象或方法。
我们继续找o 的返回值,zn.encode(n),给它打上断点,点击执行脚本,断点停留在zn 时候,我们可以查看 o 函数调用的外置方法,同样通过本地函数地址查看,发现方法里面又有其他变量,这时再逐个扣取js代码相当复杂。通过查看全局的js代码总共1000多行,我们可以全部拷贝到我们的js文件中。
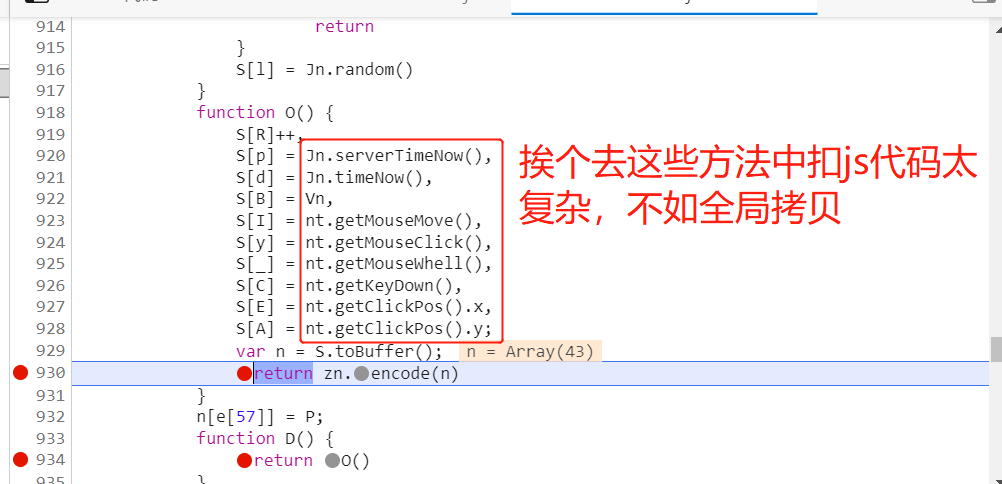
但是,当我们把整个js代码拷贝下来后,我们如何找到主体的加密代码?也就是我们最开始找到的 D 函数。
我们通过 D 函数-->找到 o函数--->找到 zn.encode(n),现在zn.encode(n)是核心的加密代码,它加密了n, n是一个43位的数组。
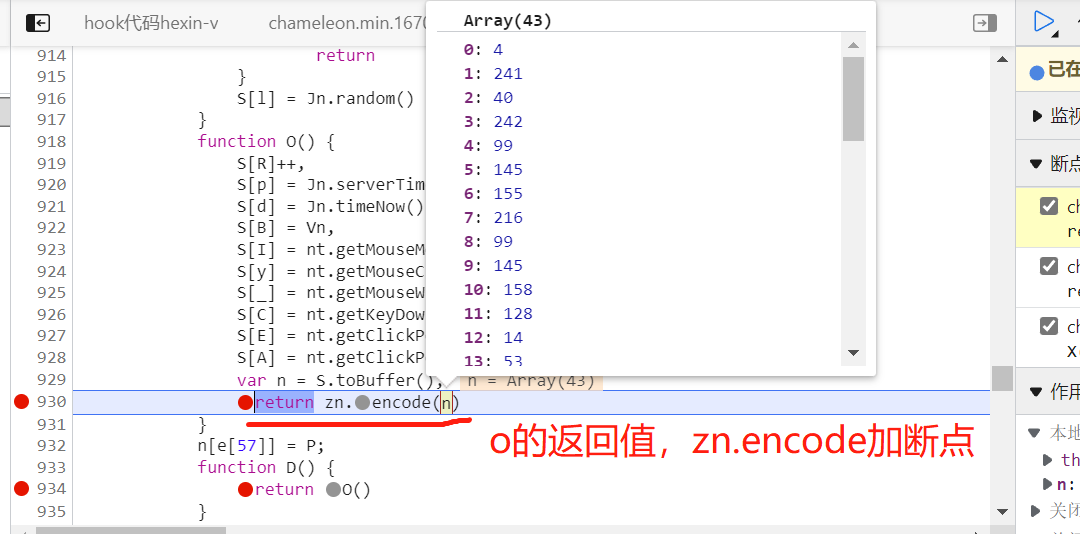
我们最开始找的s = rt.update() 接收的这个函数,我们把代码全部拷贝过来,直接接收可以吗?当然不行,因为缺少环境,我们需要补环境。
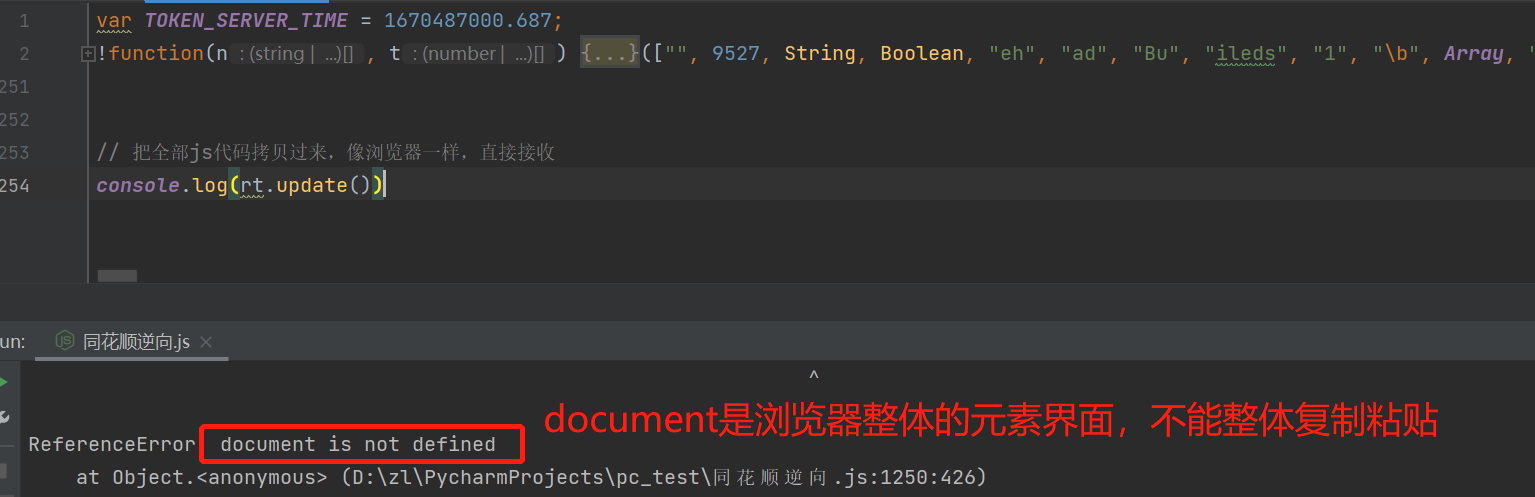
我们在浏览器去搜索document,打上断点,然后执行脚本,所有断点走完之后释放,再次刷新页面,之前所有打上断点的位置全部没有了,这种叫做动态JS。我们去控制台搜索 document.w ,发现没有这个值。于是引出环境问题。
5、补环境问题
上例中的环境属于最基础的环境,比如直接document或者window ,它需要依赖环境进行运行。
高级环境,比如document.某一个值.某一个值 ,它可以使用环境进行运行。上例中,我们搜索了document.w,没有这种值,因此它是基础环境。
为什么要补环境?
我们在用selenium爬取时,即使用了很多设置,还是有可能获取不到源代码,这是因为守方用了环境进行反爬。环境中有个重要的东西,叫浏览器指纹,自动化程序是基于内核,它获取不到浏览器指纹。还有上例中,我们用代码运行,它缺少了浏览器的依赖,即没有浏览器环境,因此我们需要补环境。
如何补环境?
安装node.js的document节点, jsdom
npm install jsdom在我们的js代码中创建浏览器环境
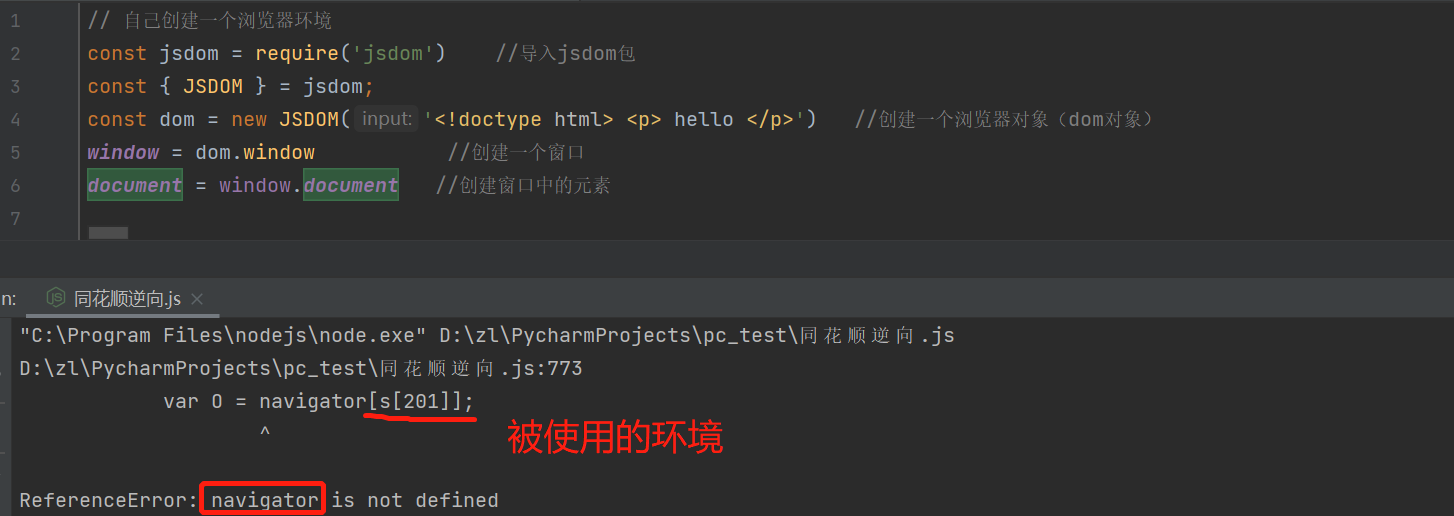
其中<!doctype html>是浏览器的头,在网页源代码中进行拷贝
但是,我们运行仍然报错, navigator是另外一个环境,获取这个环境中的信息时报错,我们需要补全环境。
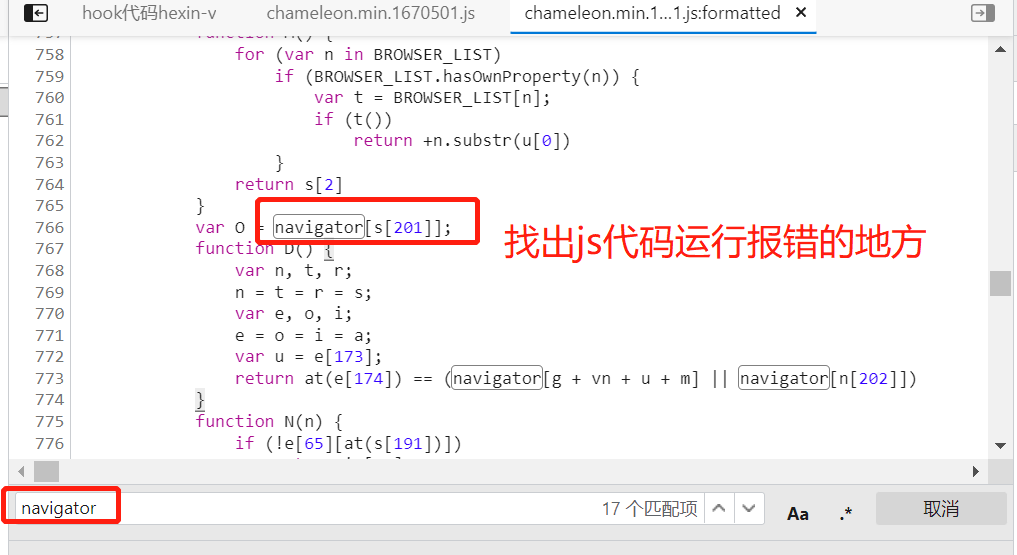
我们仍然通过hook定位代码,断点向上跟栈,找js文件搜索navigator,并找到我们的js代码运行报错的地方
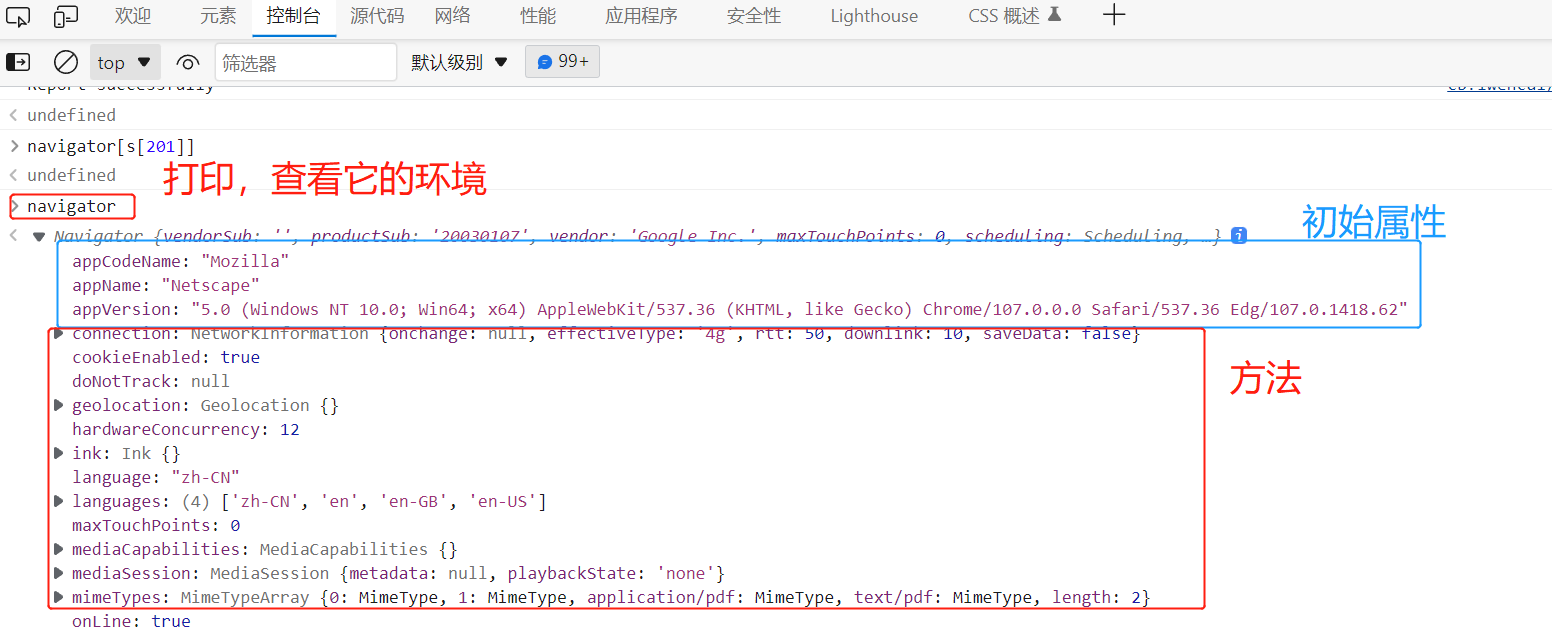
navigator[s[201]] 取值,打印时空值,我们看不到内容,打印navigator可以查看它的环境,先在我们的js文件中配置上基础的初始属性。
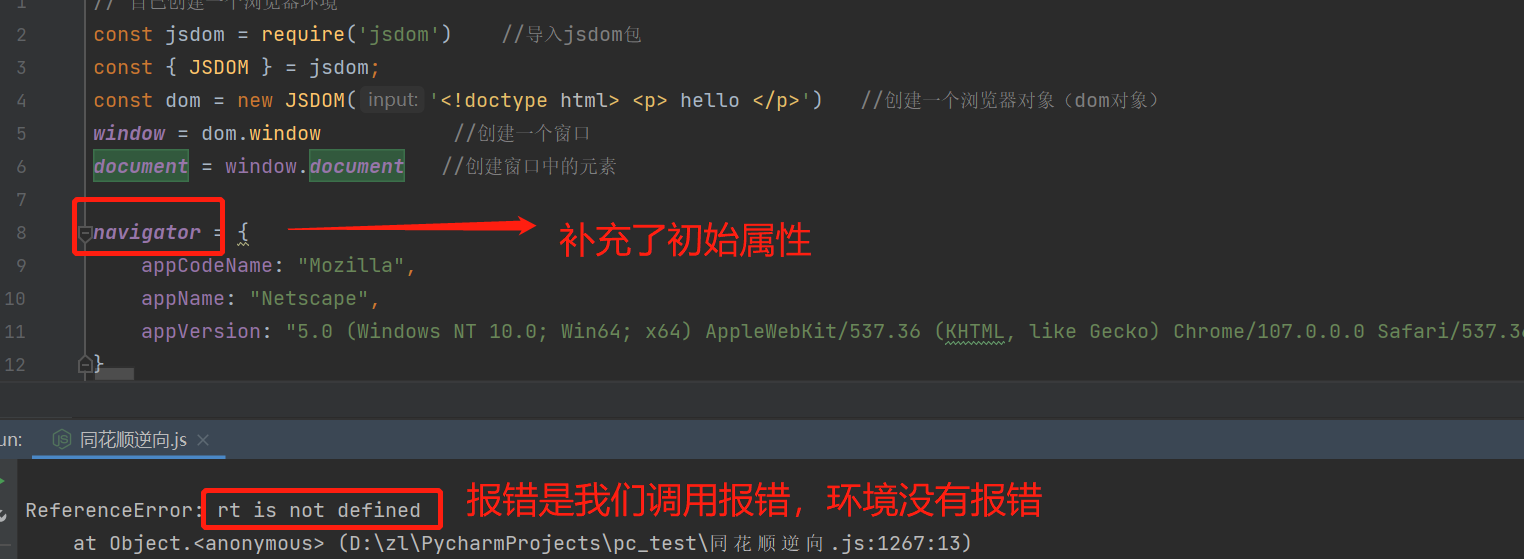
补充了navigator环境的初始属性,运行还是报错,但报错的是我们调用 rt.update()函数而不是环境,说明环境已经补全了。
这样,又回到之前的问题,当我们把整个js代码拷贝下来后,我们如何找到主体的加密代码?我们已经知道在哪里进行的加密,但我们该如何去调用它?
我们还是通过hook,断点调试, D 函数-->找到 o函数--->找到 zn.encode(n),现在zn.encode(n)是核心的加密代码,它加密了n, n是一个43位的数组。我们先找到zn.encode(n)的生成位置:
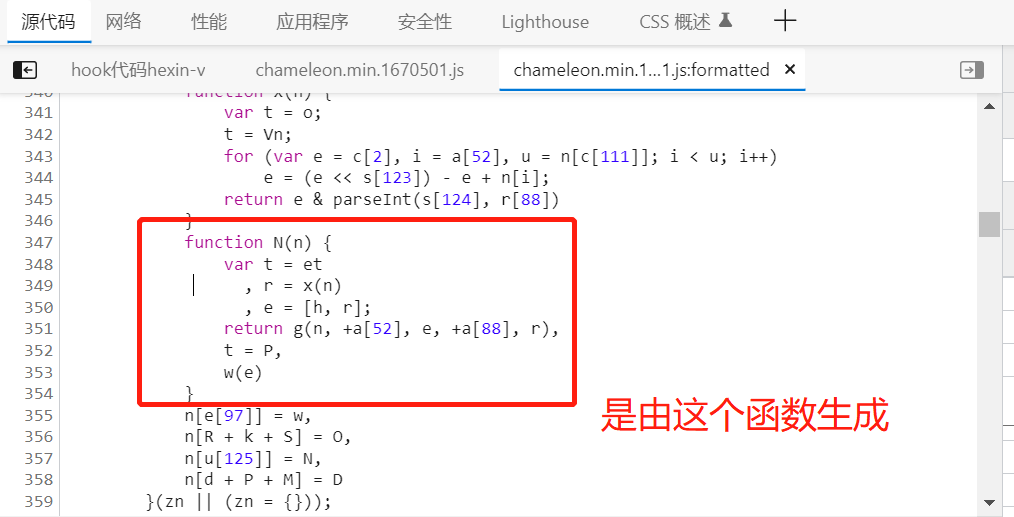
这个N函数里面有明确的方法,因此可以确认核心的加密代码是N函数。
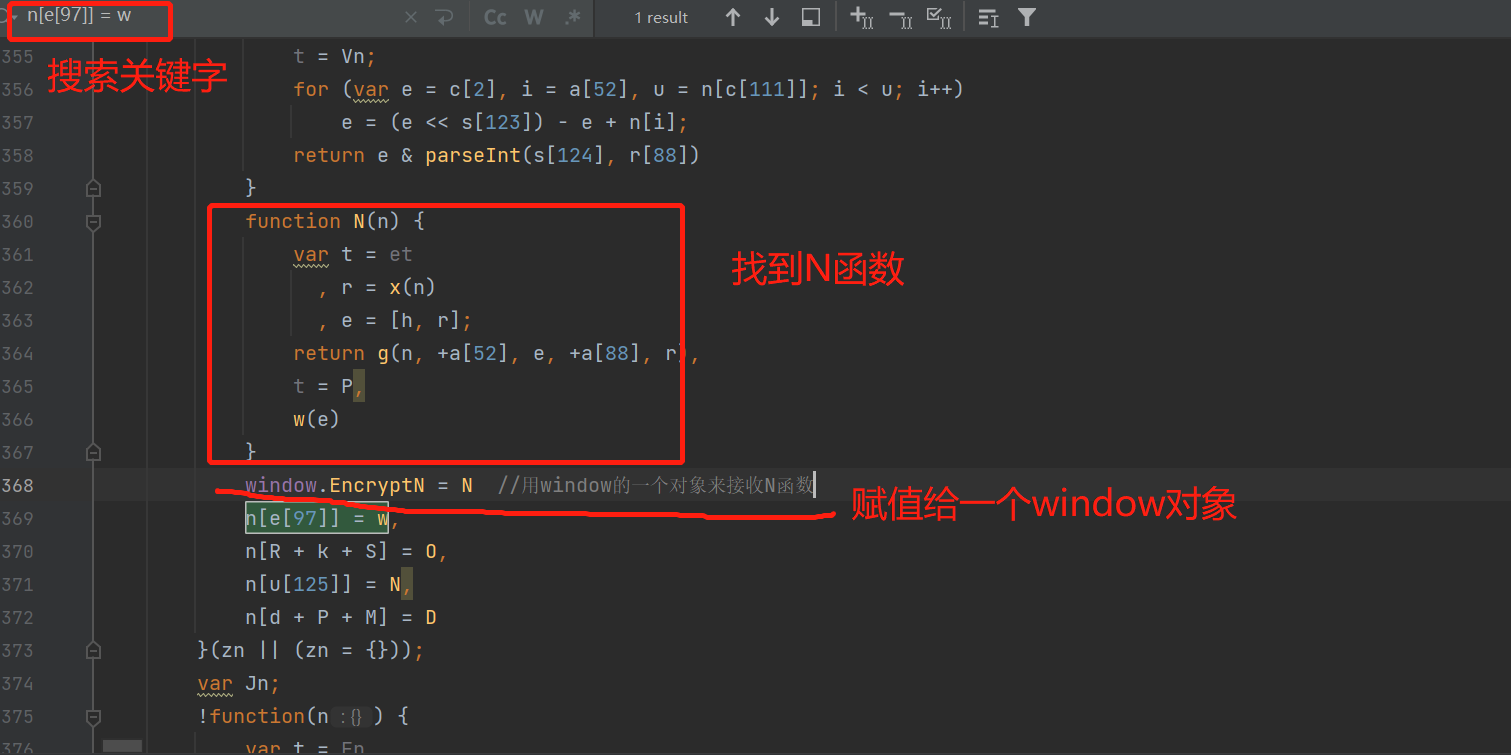
在我们的js文件代码中,通过关键字定位到N函数,并把它赋值给window对象,让后我们调用这个window对象。

这里又个问题,zn.encode(n)函数调用时,传入了一个参数n,我们在源代码中可以看到,n是由s.toBuffer()这个方法生成的,但是这个方法没有生成位置,而是直接传了一个43位的数组赋值给n,那么它传递的这个数组是否是固定的值,我们需要测试一下,拷贝该方法,在控制台中打印。
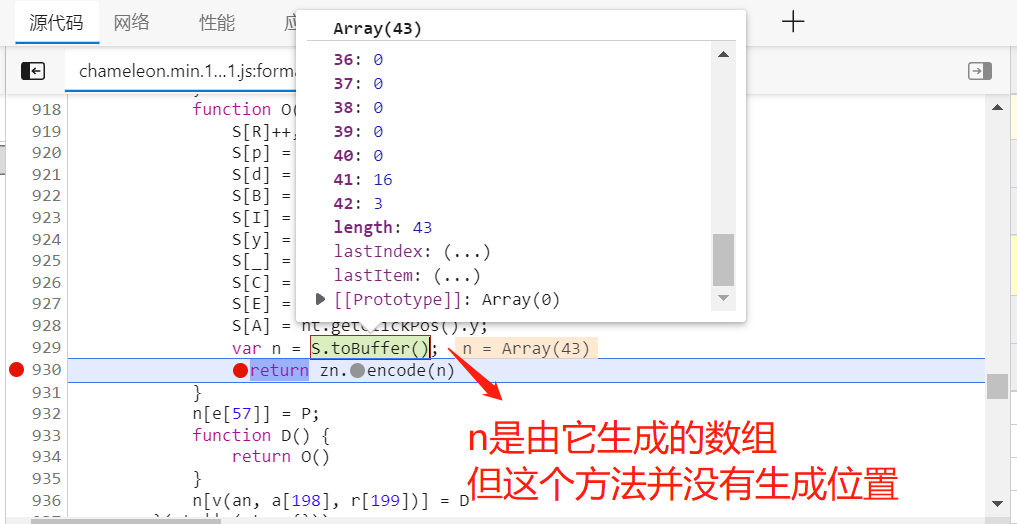
经过测试,我们发现s.toBuffer()方法在控制台输出结果固定不变,因此我们可以这串值拷贝到我们的js文件代码中,把它作为参数传入给window对象
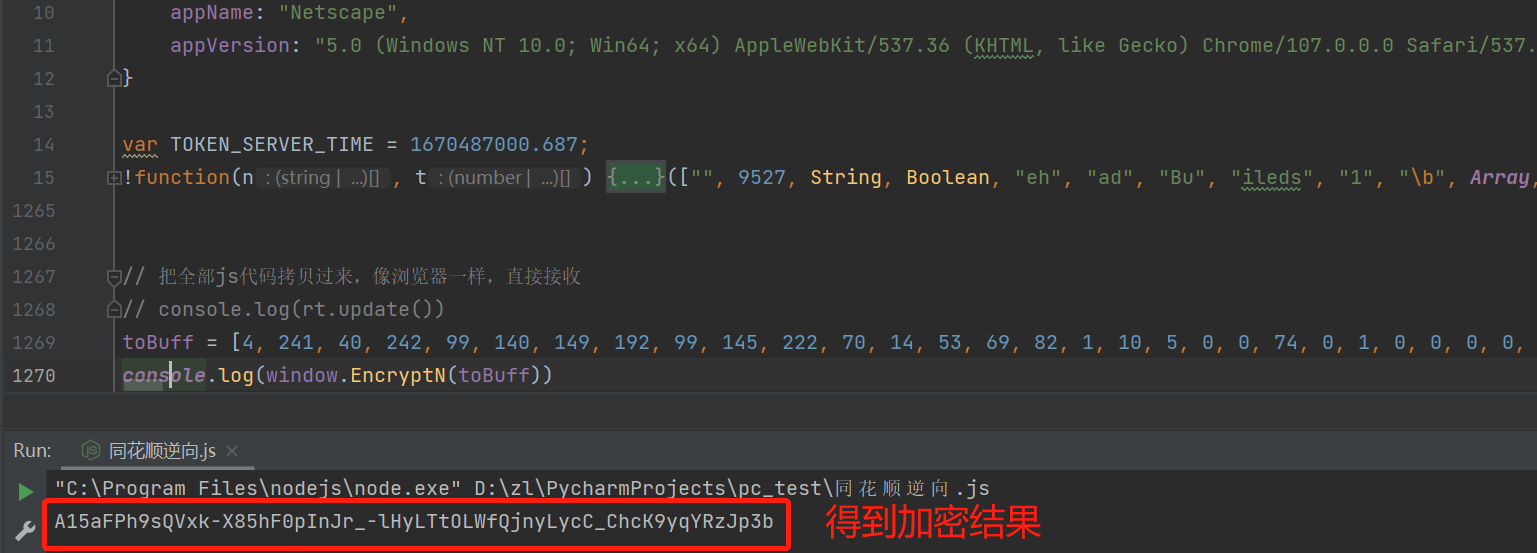
最终,通过请求头加密参数逆向,输出得到加密结果,我们再把加密结果返回给网站执行请求。
7 进制流数据
特殊的加密,返回的不是我们上面看到的密文,而是一种进制数据(二进制、十进制、十六进制......)。数据加密和请求参数加密都会用到这种进制流数据。
7.1 防调试的反爬机制
以 http://www.spolicy.com/ 网站为例,我们一打开开发者调试工具,会出现:
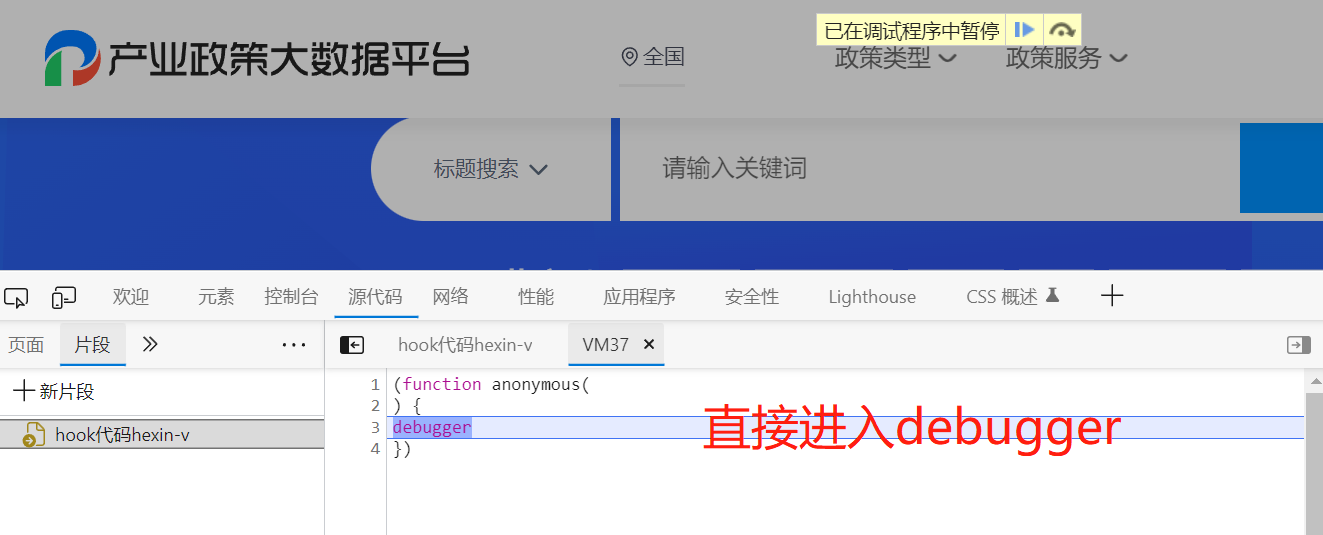
直接进入到debugger,我们不能进行调试。我们可以鼠标右键,选择永不在此暂停,把断点释放,会发现该网站的第二重反爬:整个浏览器卡死。
我们再利用hook注入一段防调试的代码:
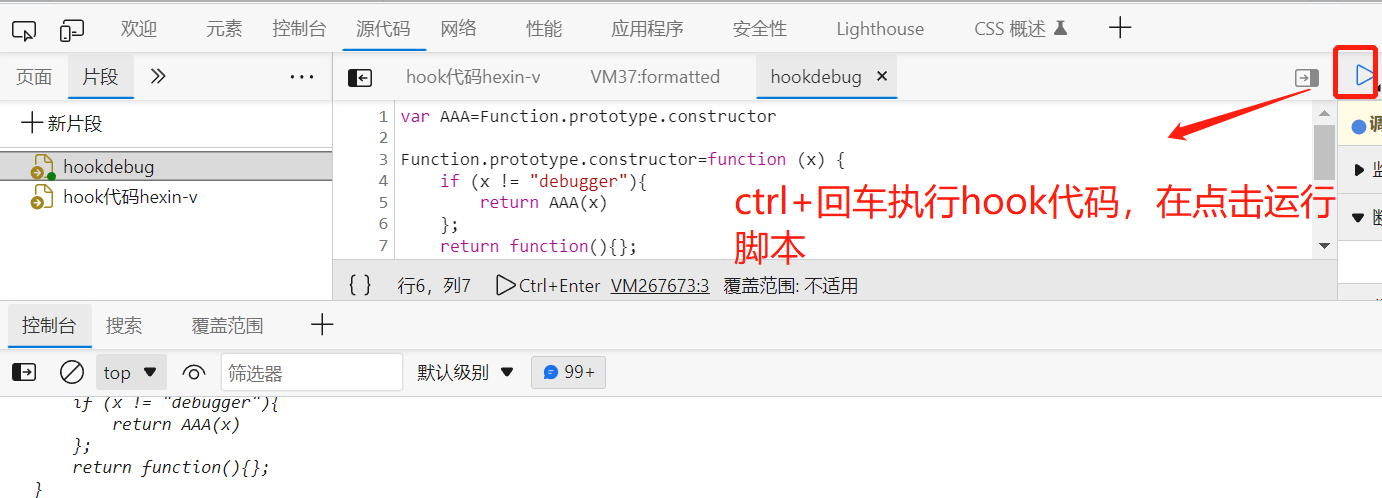
注意:用hook注入的方式,刷新网页后hook注入就没用了,我们只能XHR路径断点,通过切换标签或下滑的方式来定位动态接口。
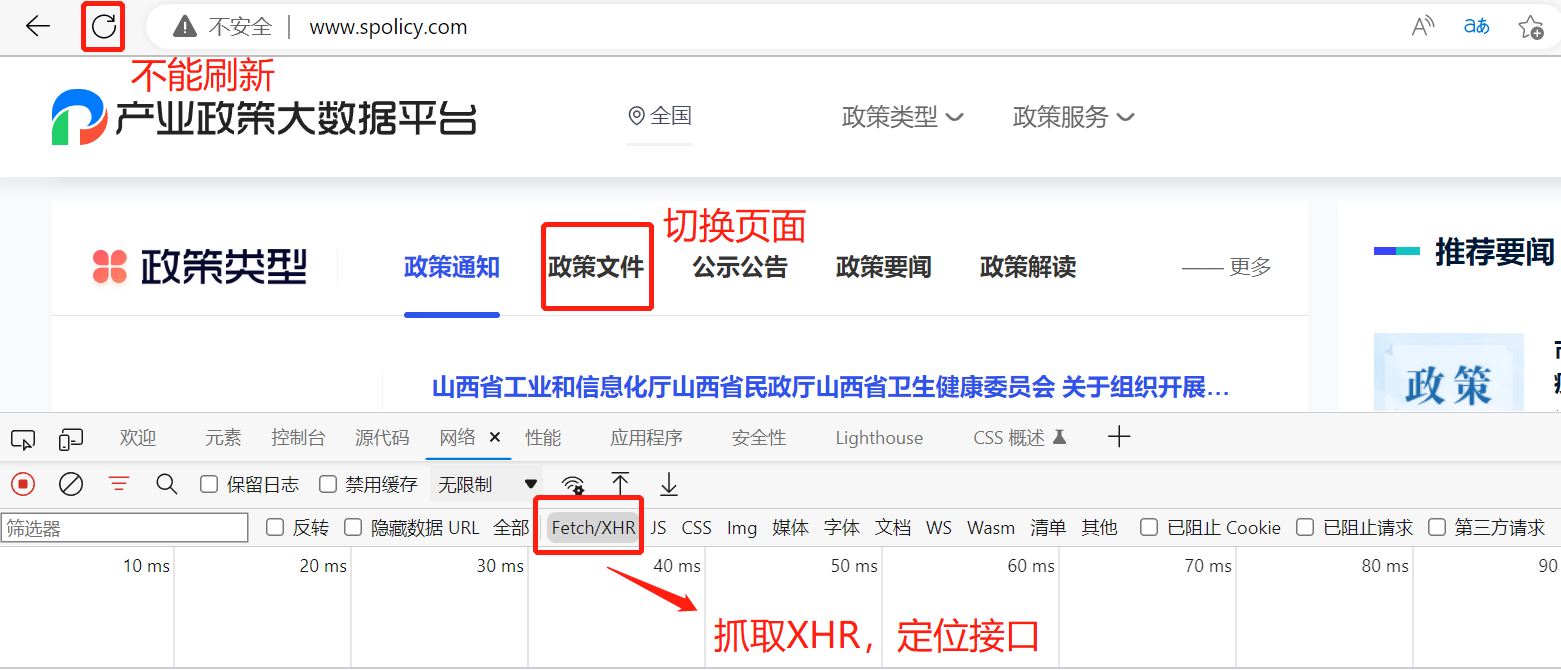
通过切换标签,我们获取到XHR路径断点,接口正常返回数据,但我们发现它的表单数据,不是上面案例中看到的密文数据。
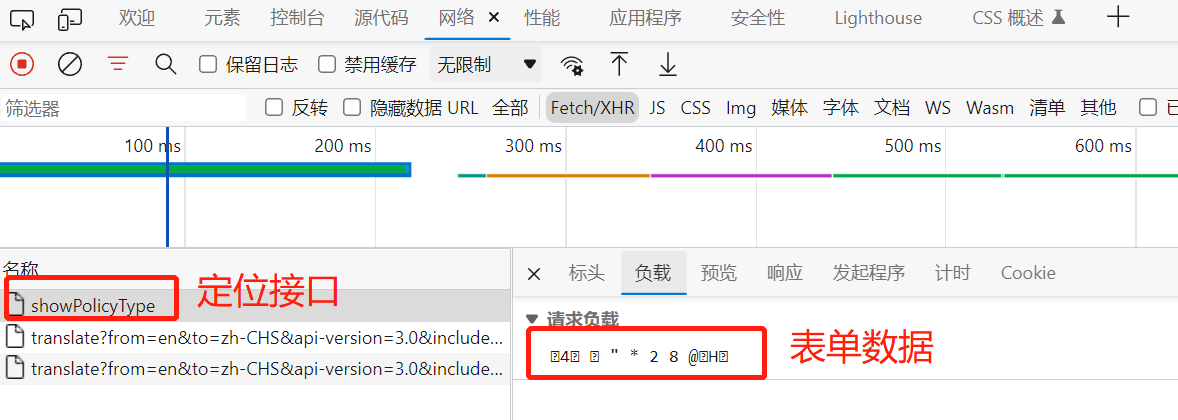
针对这种类似乱码的格式,我们需要找到它的原始数据,需要用到拦截器。
7.2 拦截器
又叫做请求上下文函数,分为request 和 response,这种函数会在我们做某个事情时自动触发。举个例子,比如我们执行“吃饭”这个函数,它会自动触发“吃菜”、“喝酒”等函数,这种就叫做请求上下文函数。
request是请求来之前,我们并不知道它会传什么参数,是捕获不到的,我们能够捕获的只有response。
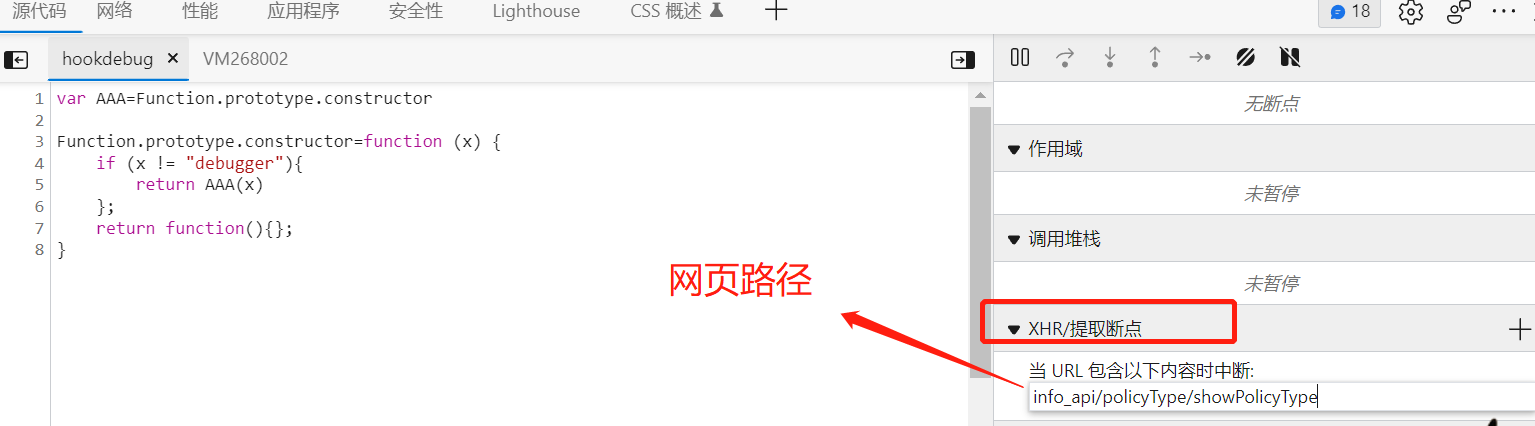
我们先拷贝接口的路由,添加到XHR断点中去,然后我们切换标签,当断点停留时,我们找到发送请求对象:
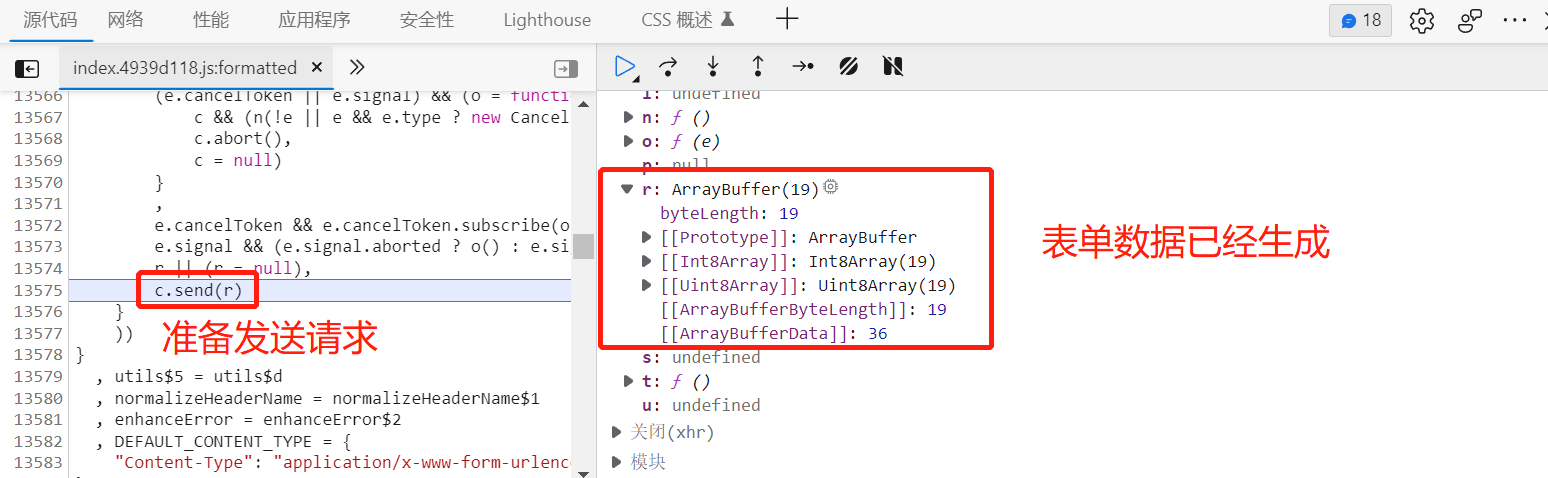
我们看到请求发送前,它的表单数据已经生成。我们点击展开表单数据。
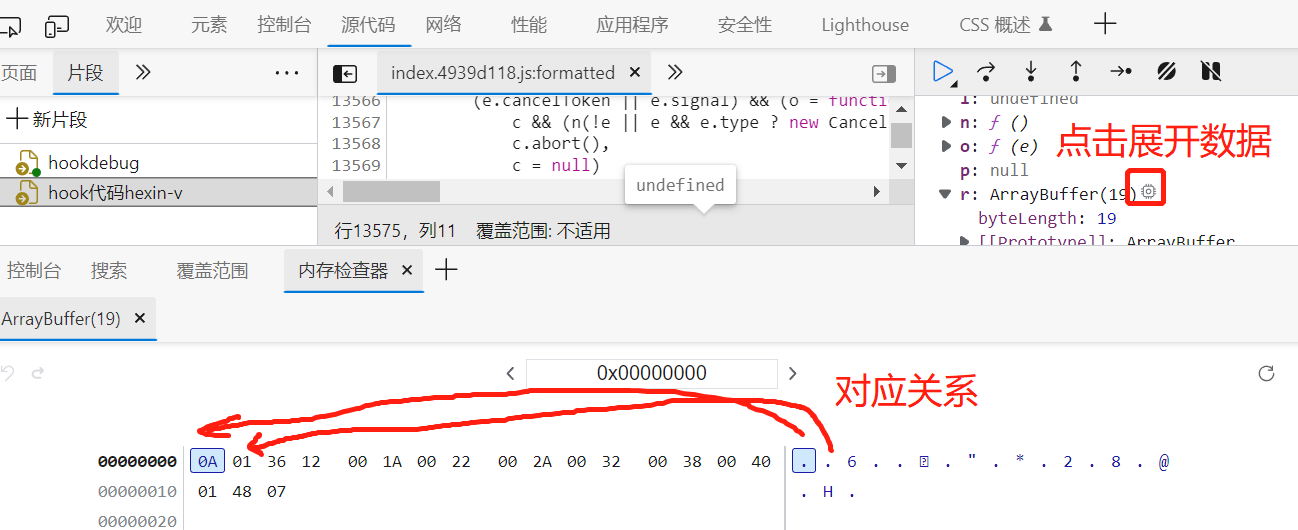
发现,我们请求表单的乱码,在程序中它有一一对应的关系,虽然都是点,但是他们的进制是不同的,因为内存地址不同。
现在我们需要找到它被加密之前是什么数据,我们用到向上跟栈,它捕获不到请求,因此我们要找的是它在什么时候触发respose拦截器。
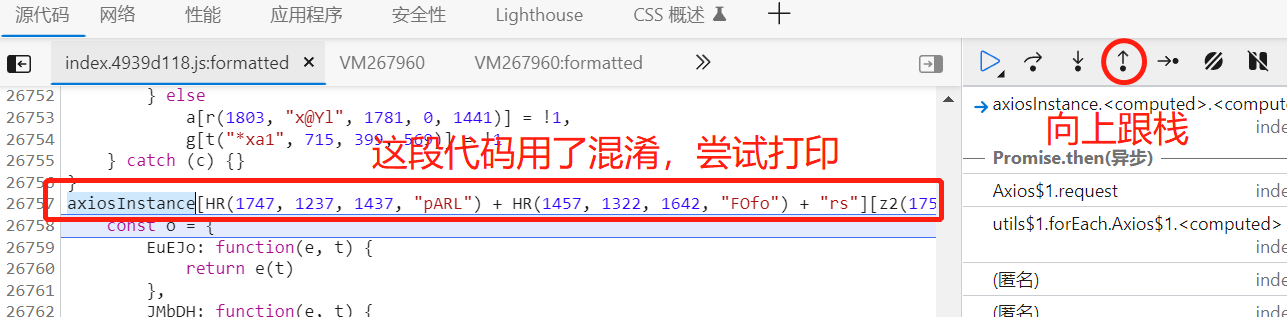
每个网站不同,向上跟栈根据经验,发现有特殊的代码,拷贝到控制台进行打印,看看输出什么:
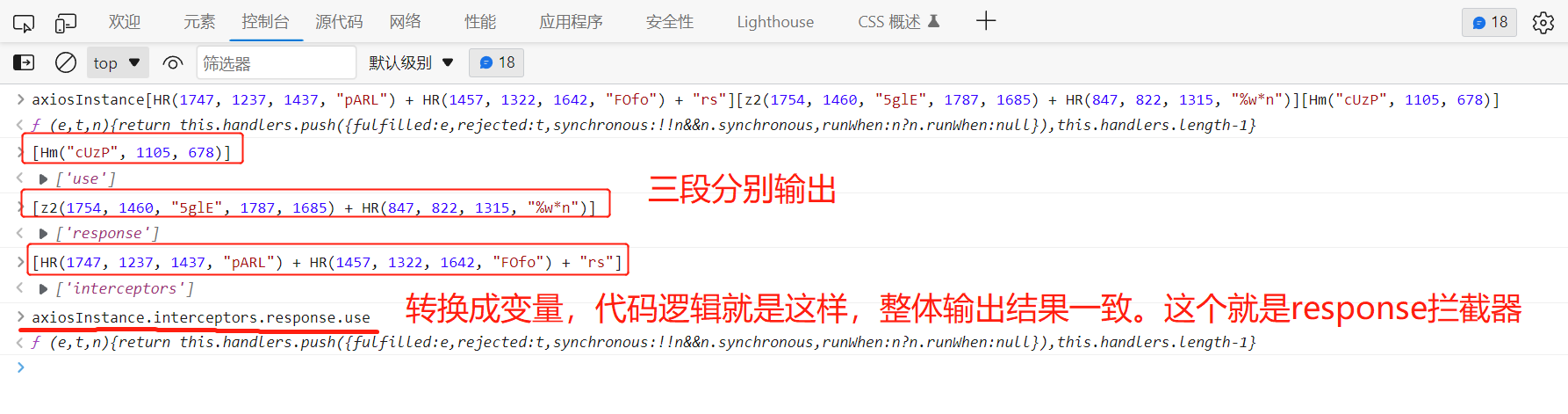
整体输出为一个函数,我们把三段分别输出,还原得到axiosInstance.interceptors.response.use,就是response拦截器。
axiosInstance.interceptors就是拦截器,对应混淆就是axiosInstance[HR(1747, 1237, 1437, "pARL") + HR(1457, 1322, 1642, "FOfo") + "rs"]
因此,我们用这段混淆后的代码去搜索拦截器,再从拦截器去找到request。
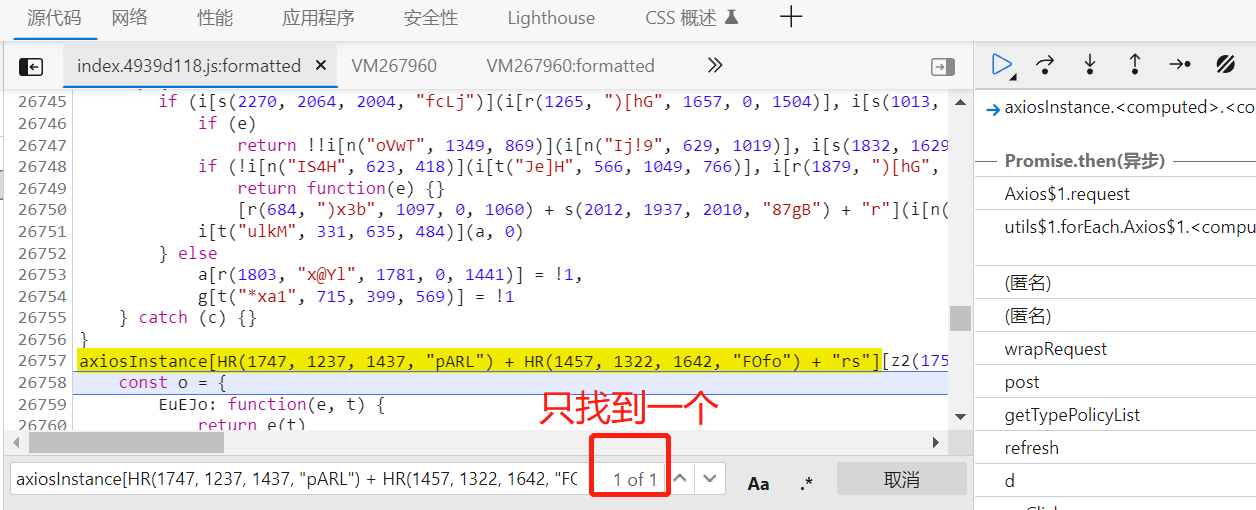
我们搜这段代码只找到一个,并且还是先前那个response拦截器,说明request拦截器名称混淆不一样,那么我们尝试只搜索明文,扩大范围:
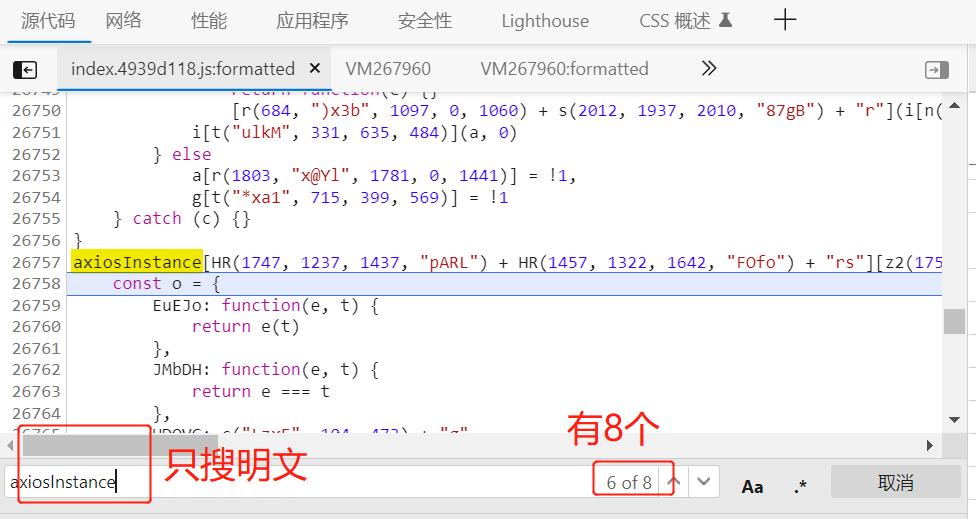
我们要找格式跟response拦截器混淆相似的,我们找到两个段比较像的,在他们前或后打上断点
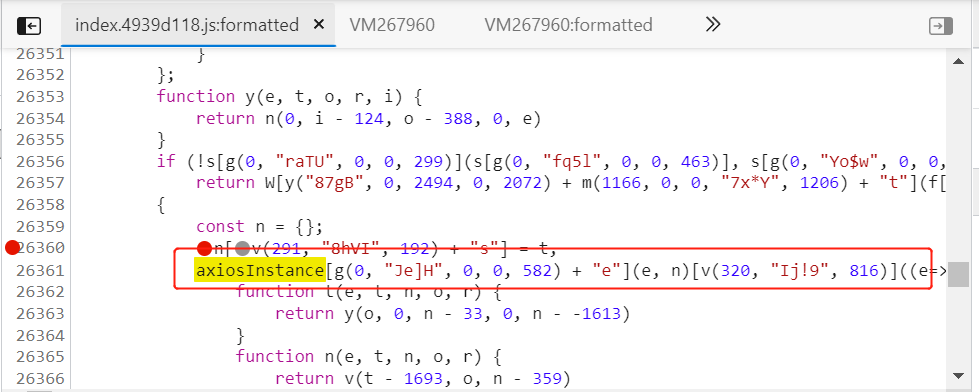
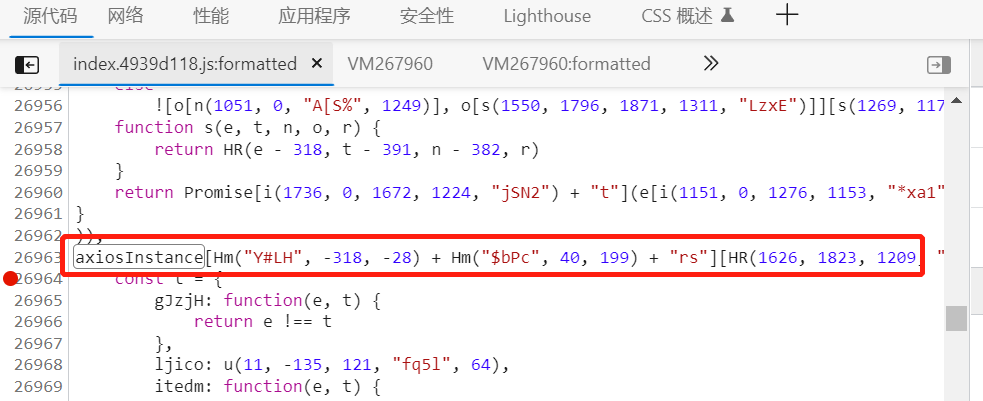
然后我们释放断点,切换标签,如果是拦截器的request,它会在我们XHR断点之前停留:
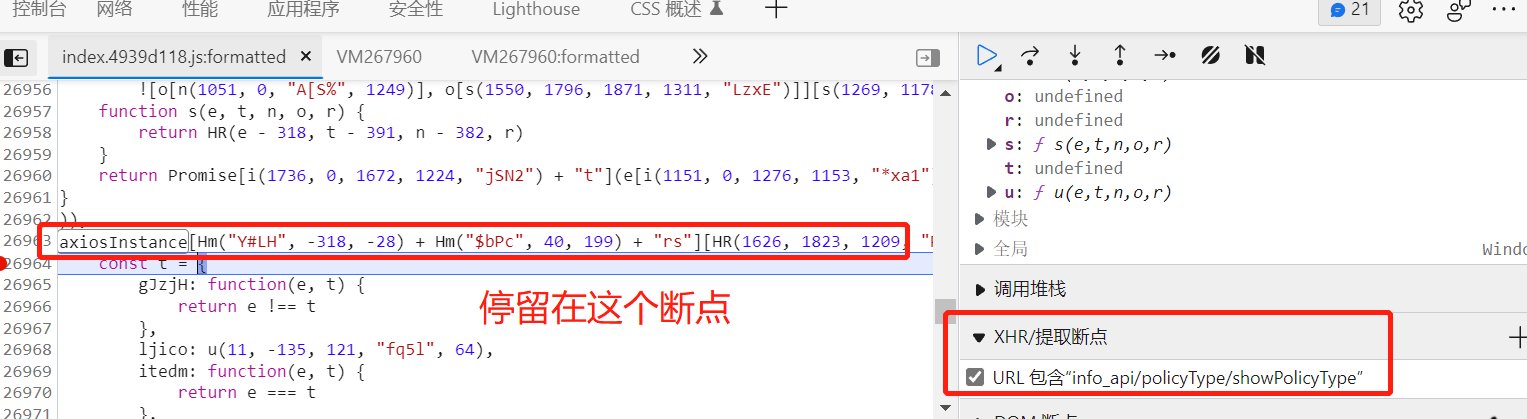
找到这个断点的代码,拷贝到控制台进行输出:
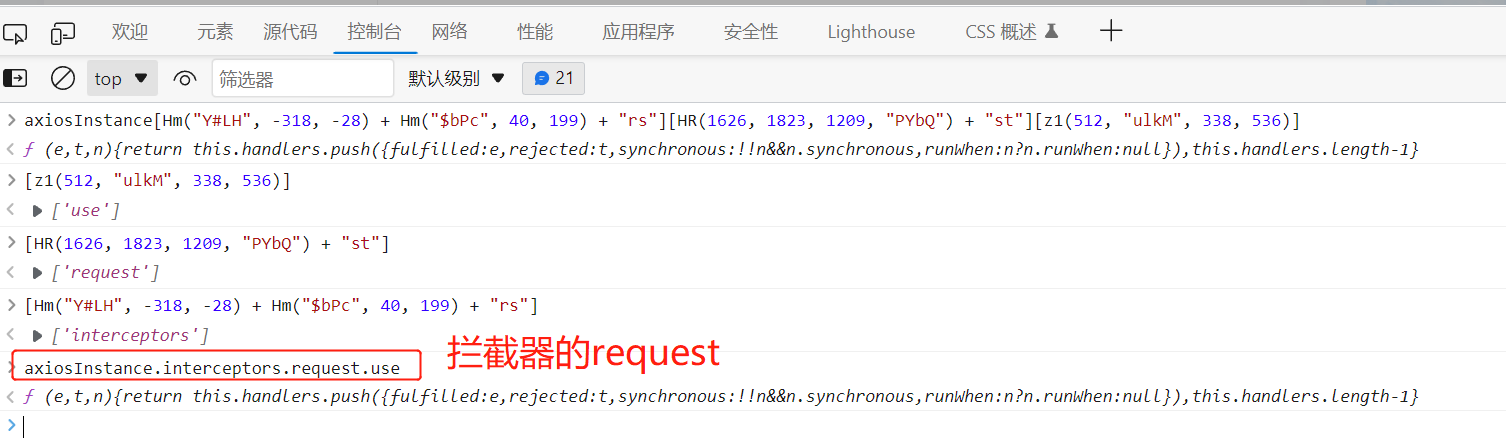
但是请求的内容很多,有请求参数、请求头、请求表单等,我们要找的是请求表单加密前的内容,可以找到这个函数整体结尾处,打上断点。

我们运行脚本,断点停留在这里,我们可以在作用域查看,现在的表单是还没有被加密的状态。
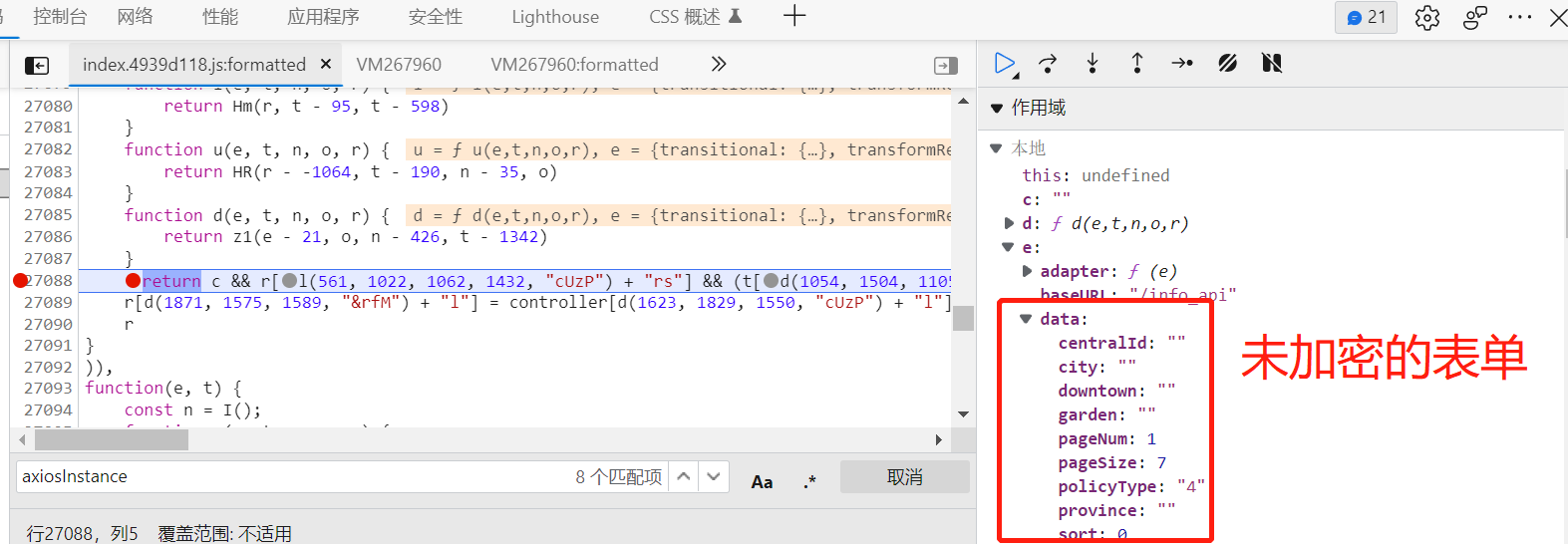
我们要想知道我们的数据是按什么条件(规则)加密的,我们用单步调试,让代码一步一步走,我们来查看它是什么时候变成密文数据。
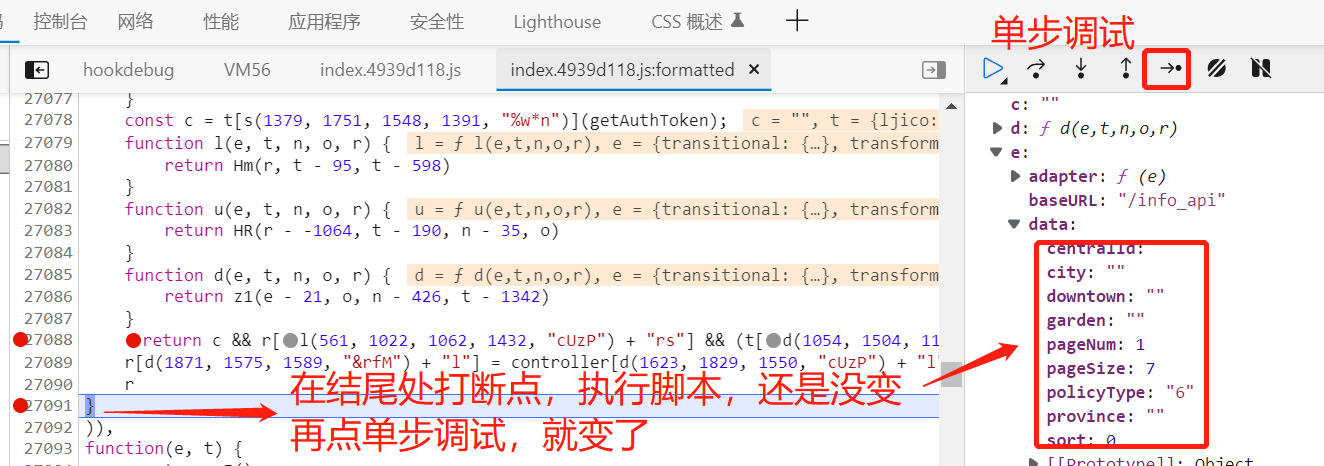
调试走到这一步发现数据从明文变成二进制数据,可以确定e就是表单数据。
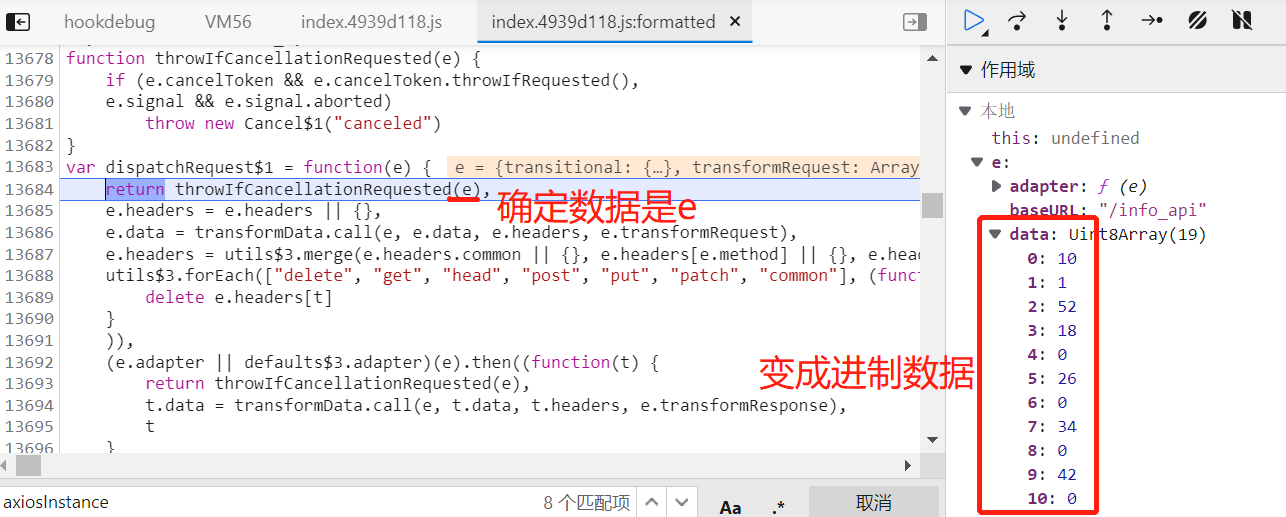
我们跳出当前函数,释放断点,重新切换标签,断点停留在response拦截器:
我们看到 r 就是加密后的数据,我们要找到 r 的赋值方式: 把鼠标光标停留在带有 r 的方法中挨个去找,也可以拷贝到控制台输出,看是否生成数组
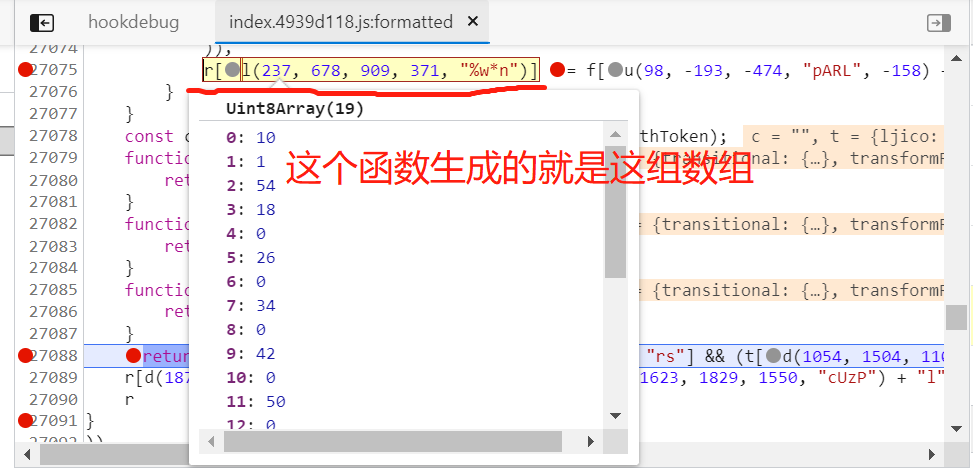
我们给这行加上断点,切换标签,执行脚本,当程序断在该位置时,它就是明文的表单数据,在控制台打印输出:

得到我们需要被加密之前的原数据,我们新建一个js文件,把这个数据拷贝到文件中:
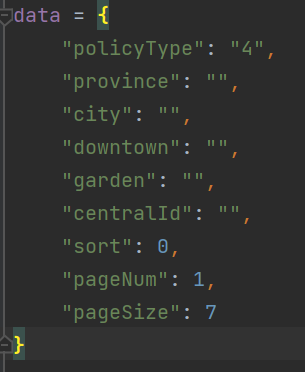
我们找到给 r 赋值的 f 函数,在控制台输出,然后分段输出,反混淆出可读性高的代码:
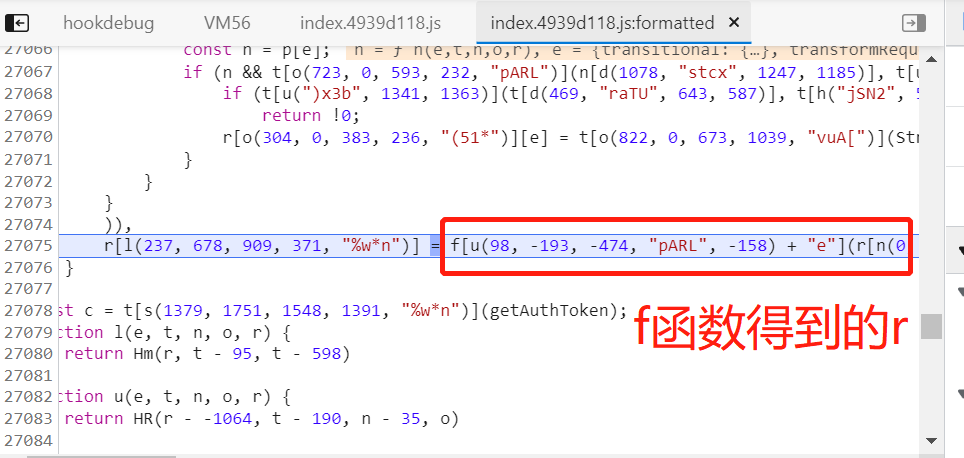
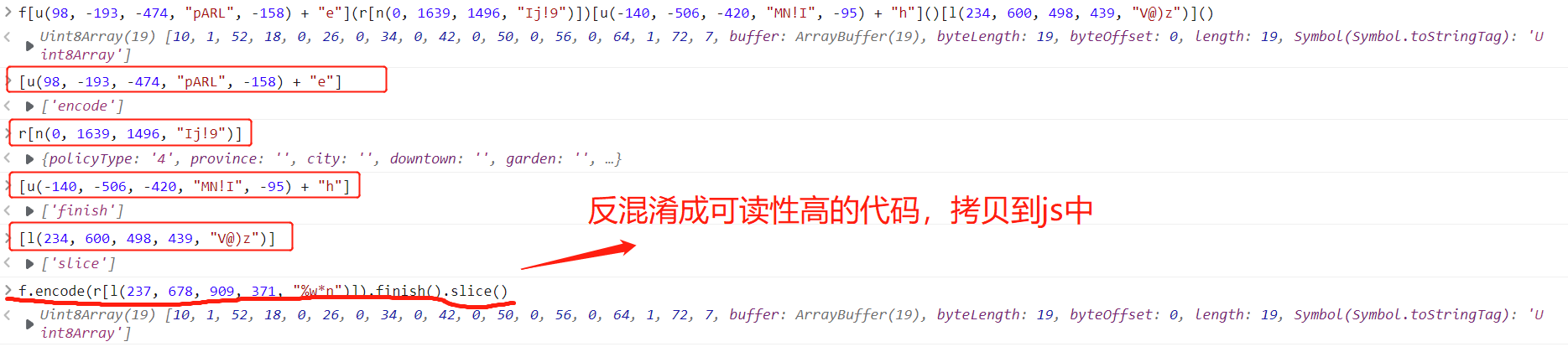
encode的参数就是需要加密的数据(就是 r[l(237, 678, 909, 371, "%w*n")]),然后把这段代码拷贝到我们的js文件中,把数据部分替换成data,接下来的目标就是找这个 f 函数
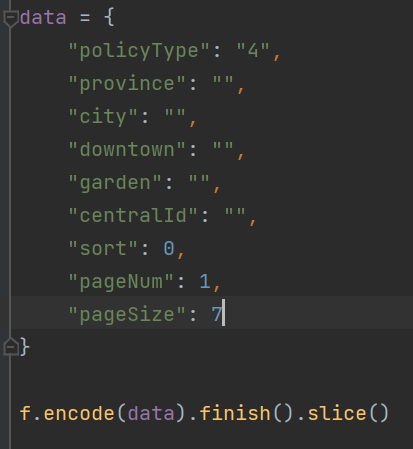
我们在源代码中,选中f.encode部分,鼠标悬浮显示出 f 函数本地生成地址
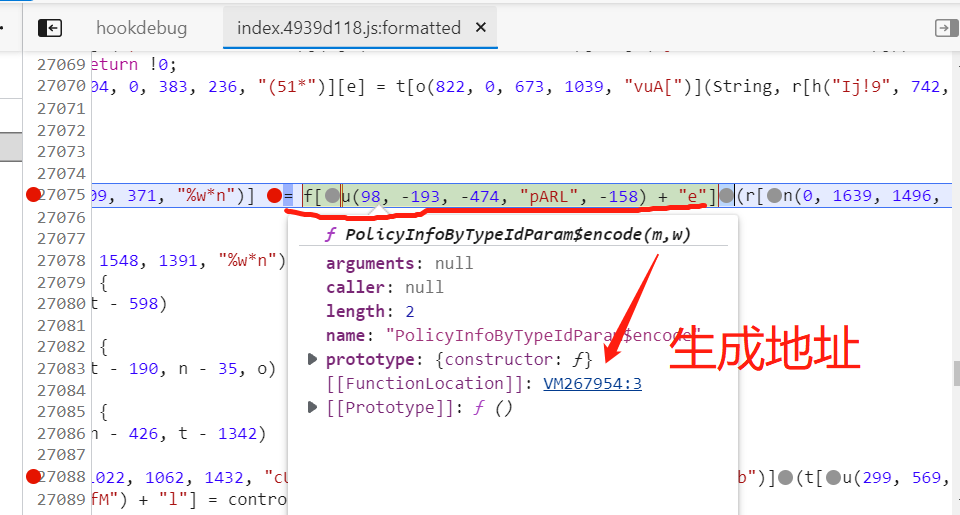
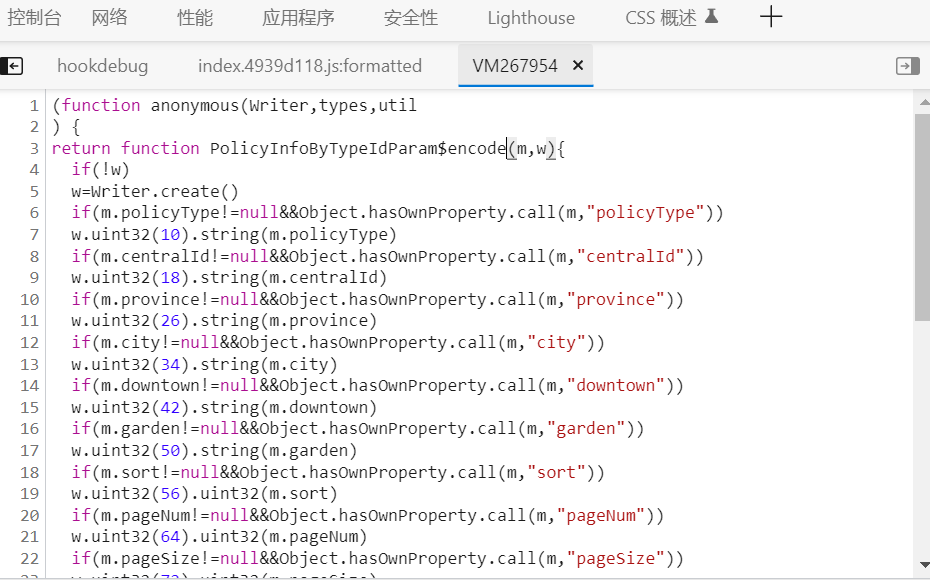
我们这道这段就是 f 函数,把它拷贝到js文件中:
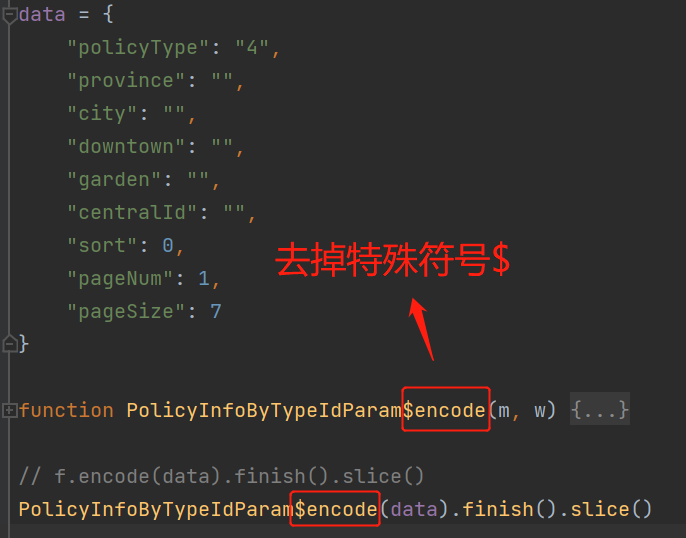
这个函数整个替换代 f.encode,我们运行这段js代码:
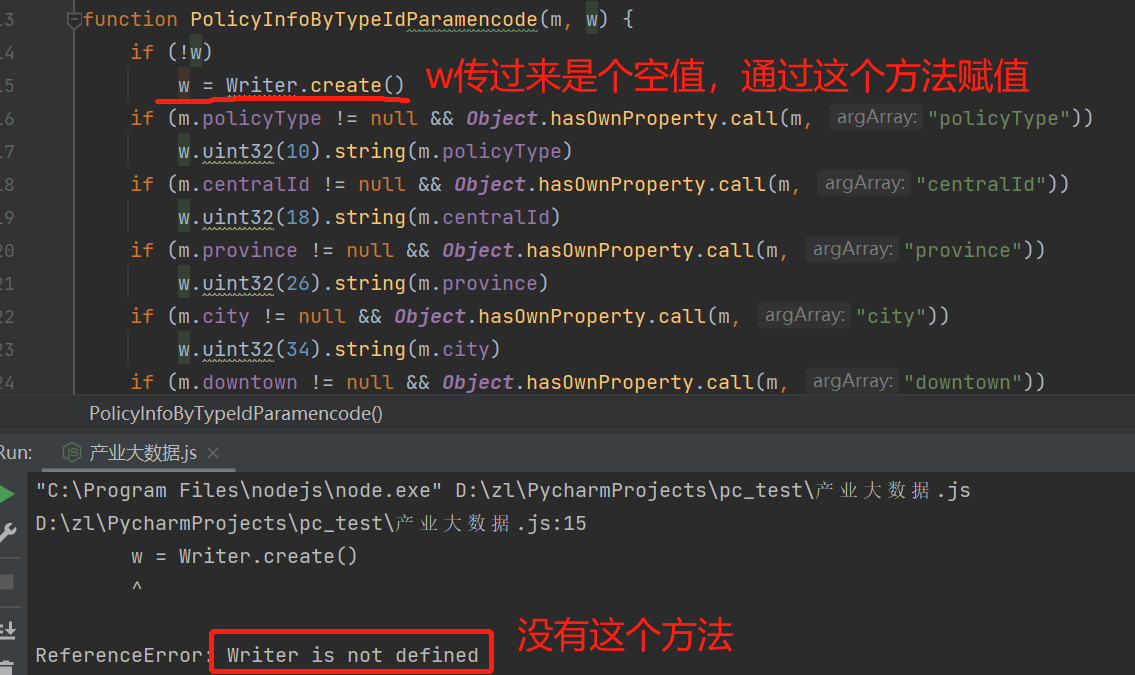
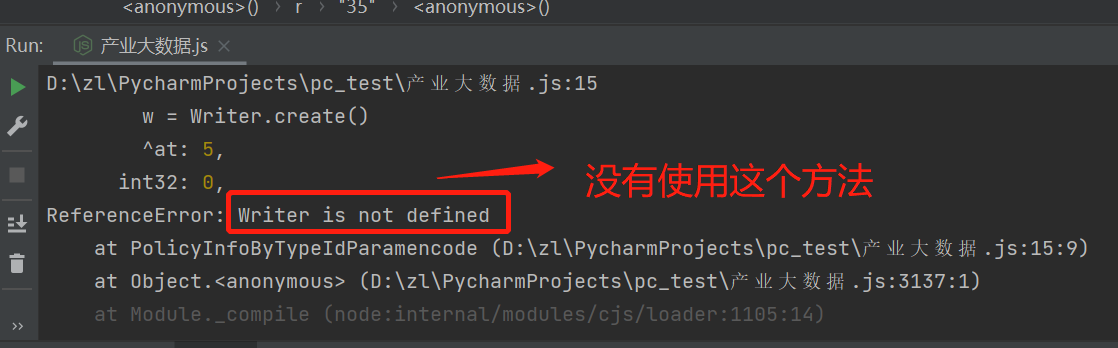
报错的是Writer方法,我们整个的程序调用PolicyInfoByTypeIdParamencode(data).finish().slice()是没有错的。
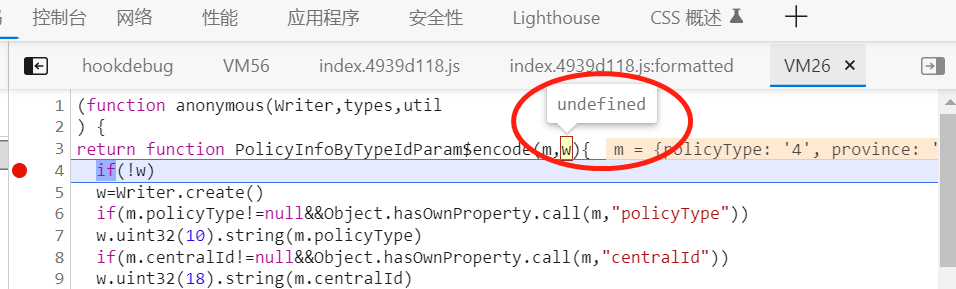
在网页程序中加断点,看到w参数一开始传的是个空值,是通过Writer.cteate() 创建的。
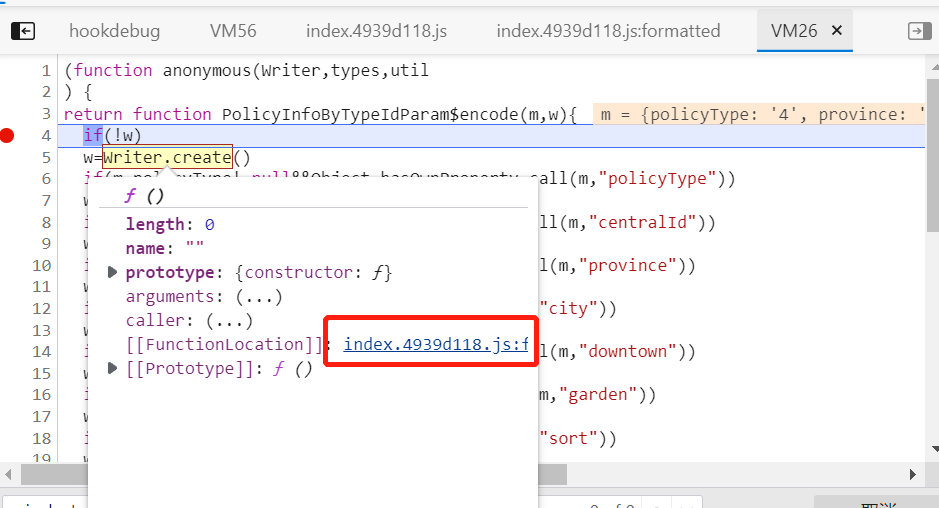
我们尝试通过Writer.cteate() 本地地址跳转,发现跳转不到正确的地址,因为它是框架里自带的代码,无法准确定位。我们用全局搜索关键字方式:
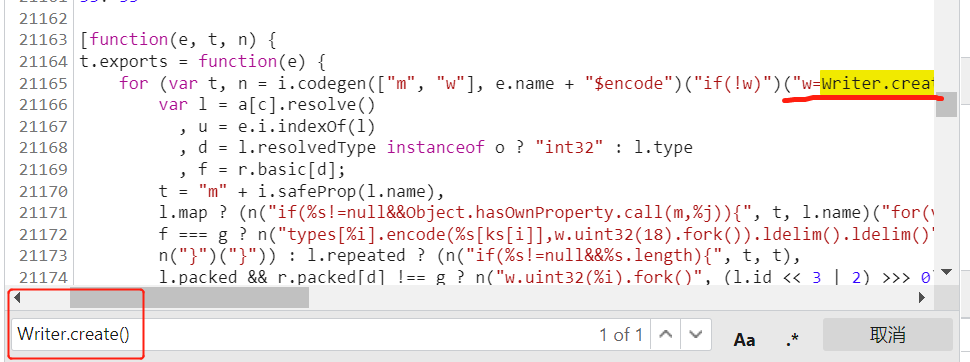
但因为这个方法是框架里的一段代码,框架里的方法都有嵌套,我们不知道如何去整体框架中扣取。那么全部拷贝可行吗?总代码3万多行,也不合适。
一个对象肯定写不到几万行代码,在整个框架中应该分成了多个独立的对象,我们需要去找出这个方法的对象。

这个方法所在的代码块,标识是13,我们从下往上翻找,找得这个独立对象的开始地方:

我们选中函数开始的大括号(高亮),一直往下找到这个整体函数的尾部(高亮),把整个代码拷贝到我们的js文件中。
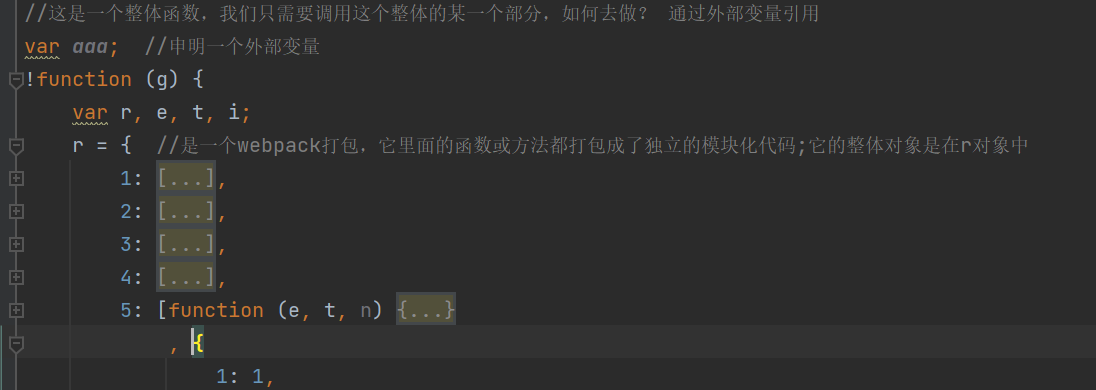
r 对象中的每一个模块,又是放到 i 函数中去进行处理的:
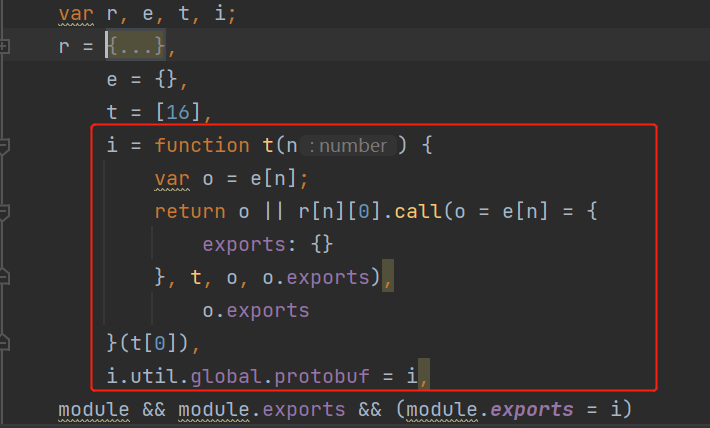
我们用外部变量引用的方式,把 i 赋值给外部变量,再打印输出,看看结果:
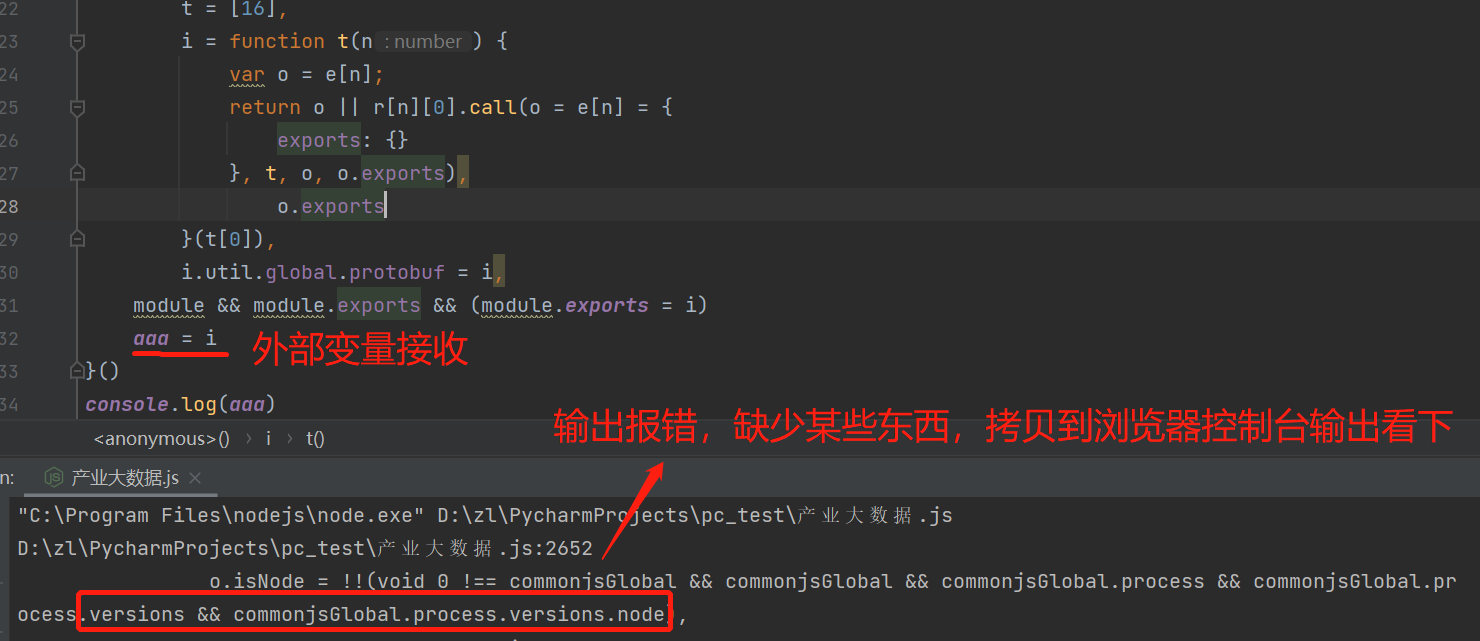

输出不了,没有结果。我们在源代码进行搜索:
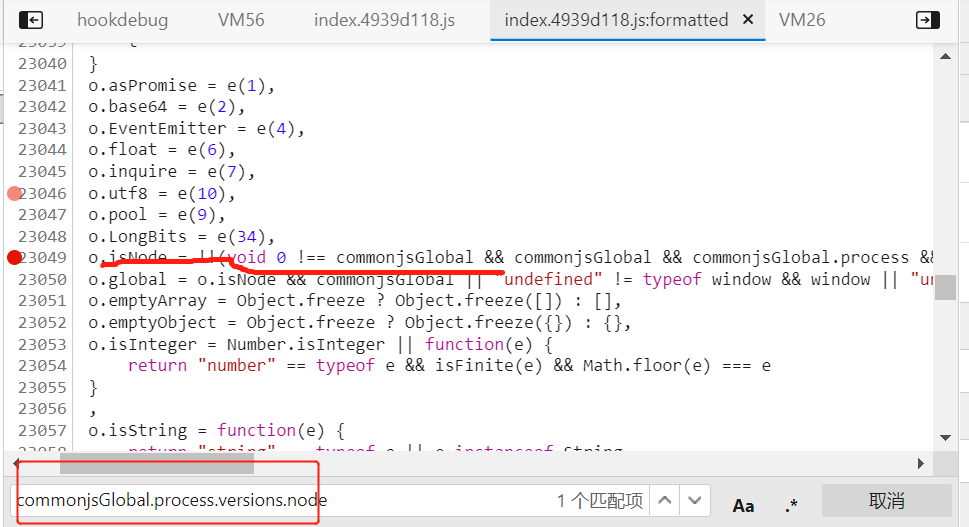
找到这行代码,打上断点,释放之前的断点,切换标签,但是程序不会在这个断点停留。我们如果刷新页面,重新hookdebug,会出现页面不会返回任何数据情况,这是网页的一种风控,只要删除所有断点,重新刷新就可以了,这是绕开风控的方法,但是无法进行断点调试,如果要解决此问题,要进行整体js注入而不是hook注入,让这个网站在我们本地跑我们本地的前端js和html。
因为这是一个整体文件,它是一种特殊的对象文件(模块化文件),它是由一个框架生成的,因此我们用断点调试的方法没有用,需要解析别人的js框架,难度是很高的。
不能在源代码中调试,我们在js文件中,去分析这段出错的代码,它实际是缺乏一种环境,是commonjsGlobal在调用
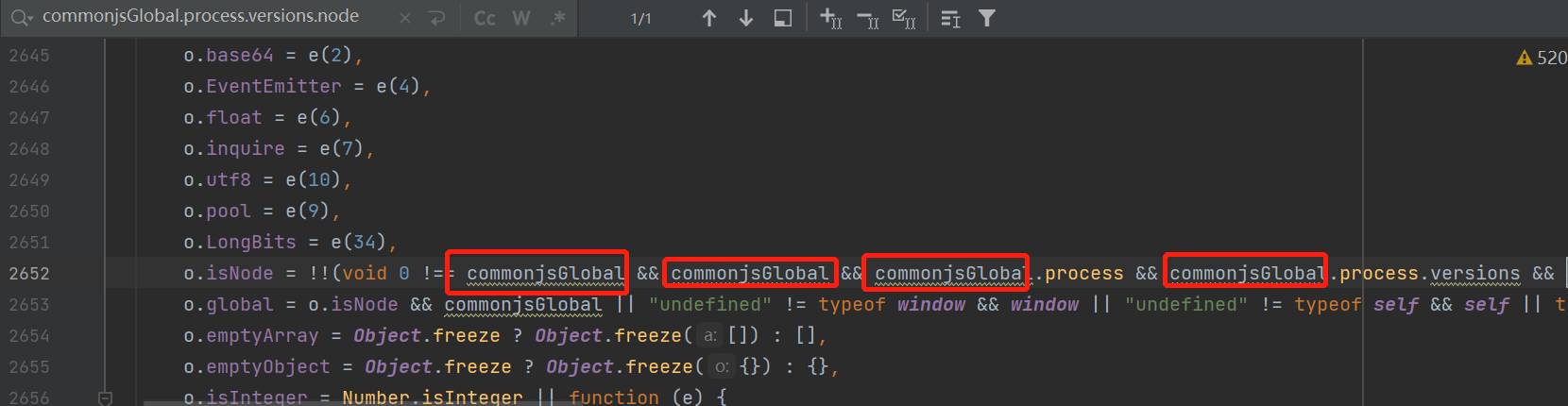
它的外部是 i 函数在进行处理,我们再看 i 函数,实际是由util这个工具在调度整个框架,它这里用了混淆,把commonjsGlobal全部替换成global
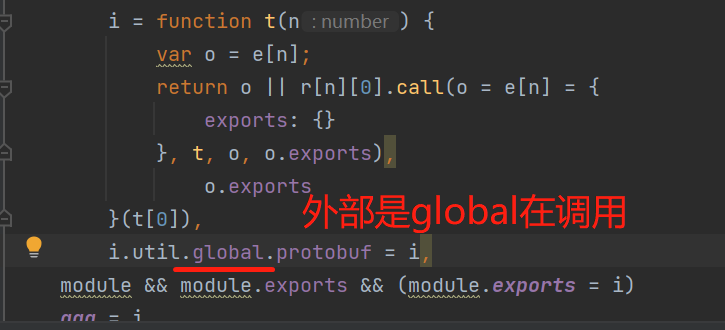
替换后,我们运行程序,继续报错,但是这个问题已经解决了,报错的还是没有使用Writer.create()方法
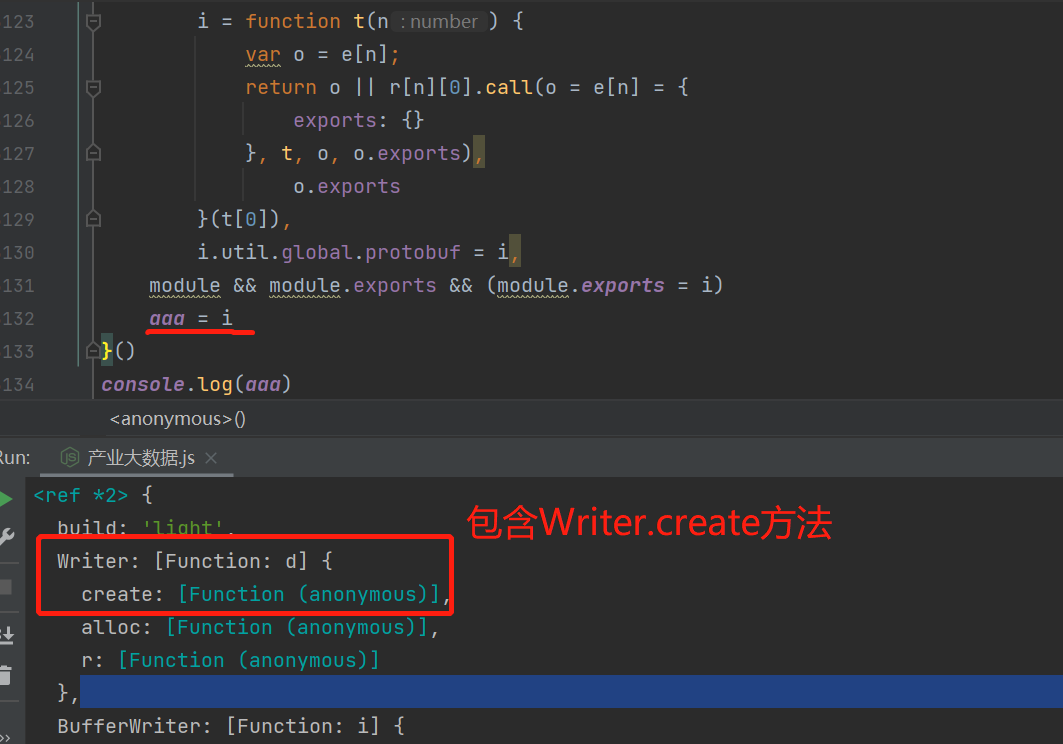
但是打印的aaa有输出,aaa是 i 函数,里面包含了所有方法。
我们把这个 i 函数放到前面,后面的代码才能调用:
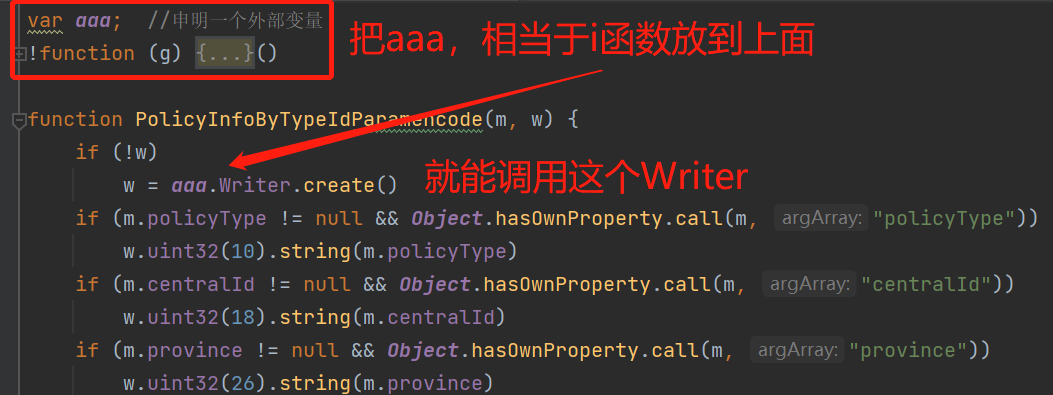
再执行打印aaa,程序没有报错。然后,注释掉aaa的输出,在下方打印整个函数的输出:
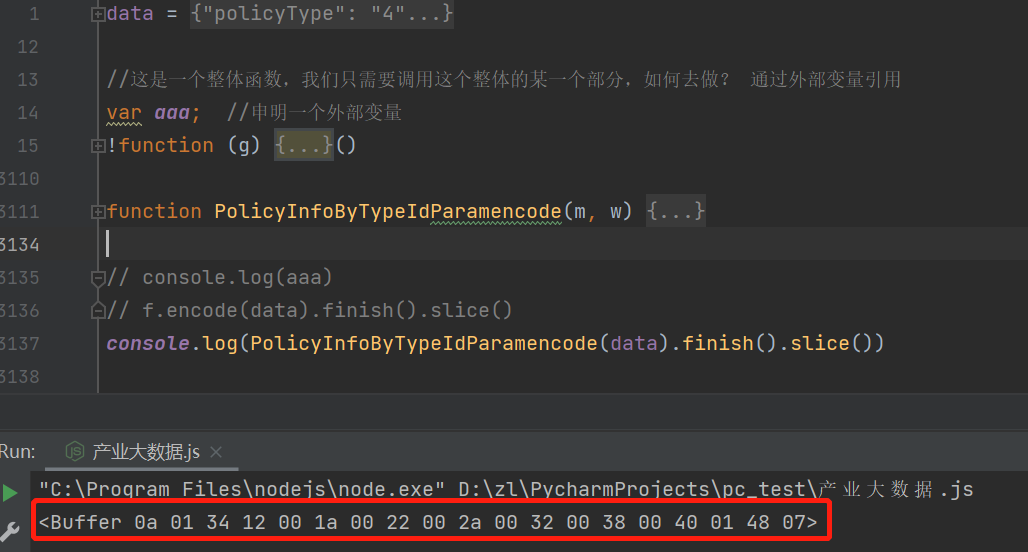
这样得到了二进制数据,但是python中没有这样的数据格式,怎么在python中去执行呢?
我们用工具网站快速生成一段python爬虫程序:
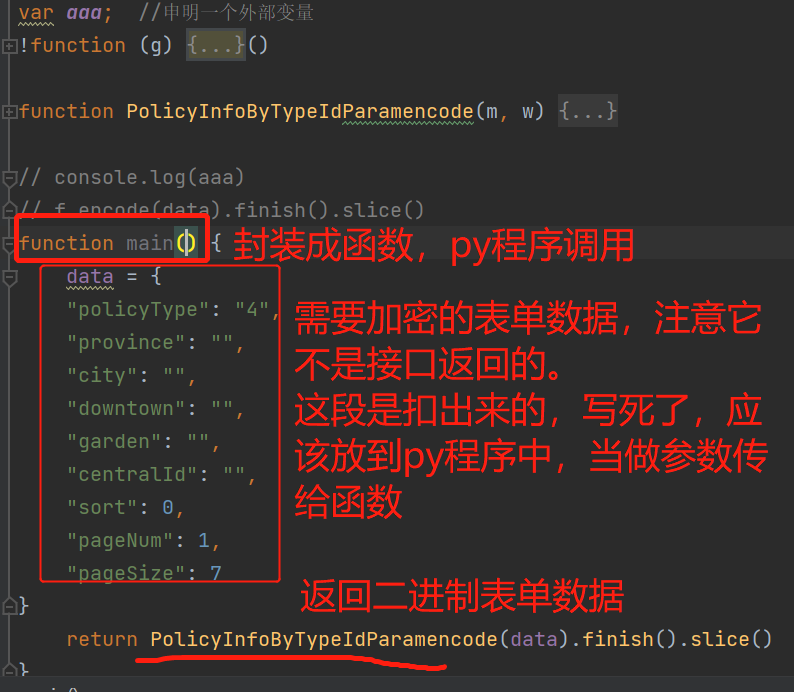
我们在js文件中,把data和解密方法封装成一个函数,供py程序调用:
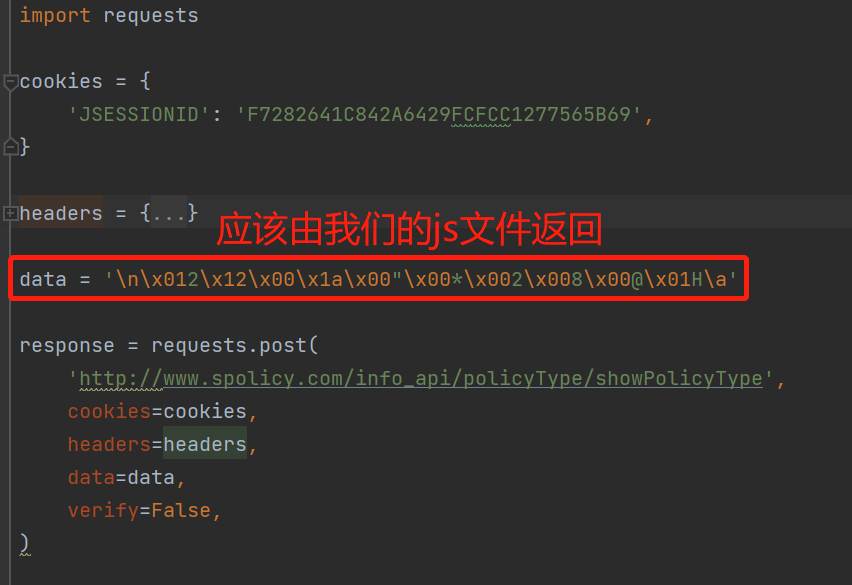
我们在py程序中调用js文件:
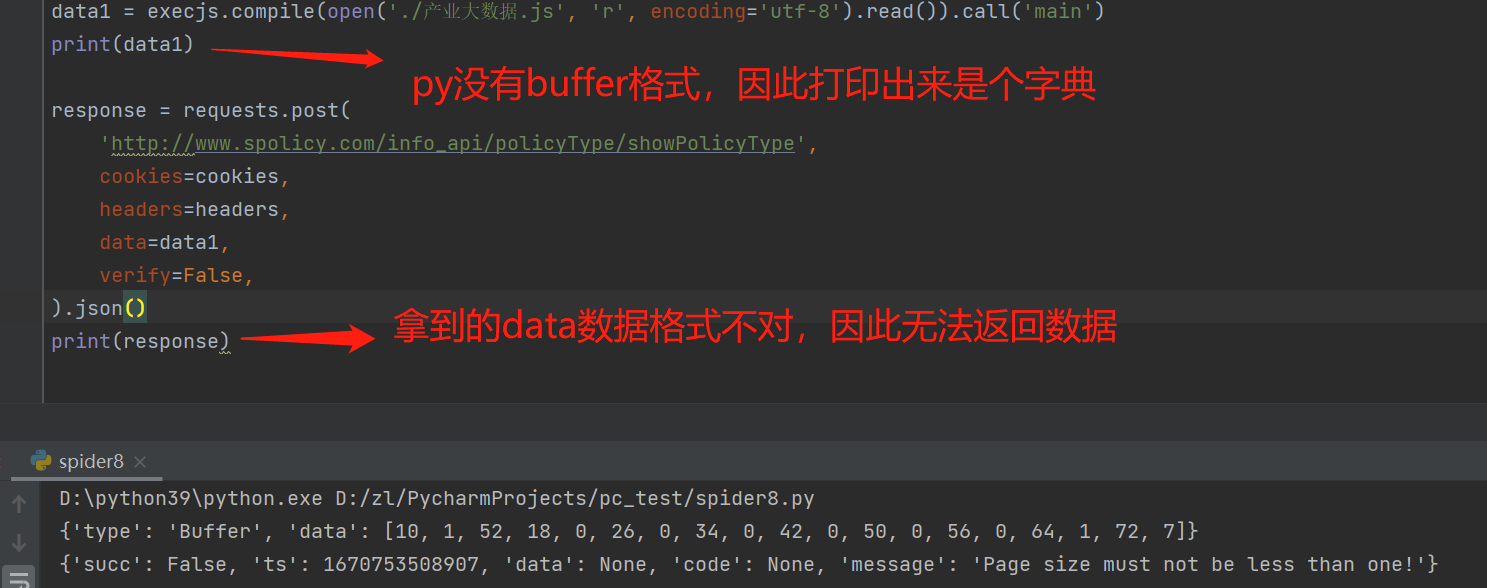
我们从字典取值,再进行数据转换,就能成功的返回数据:
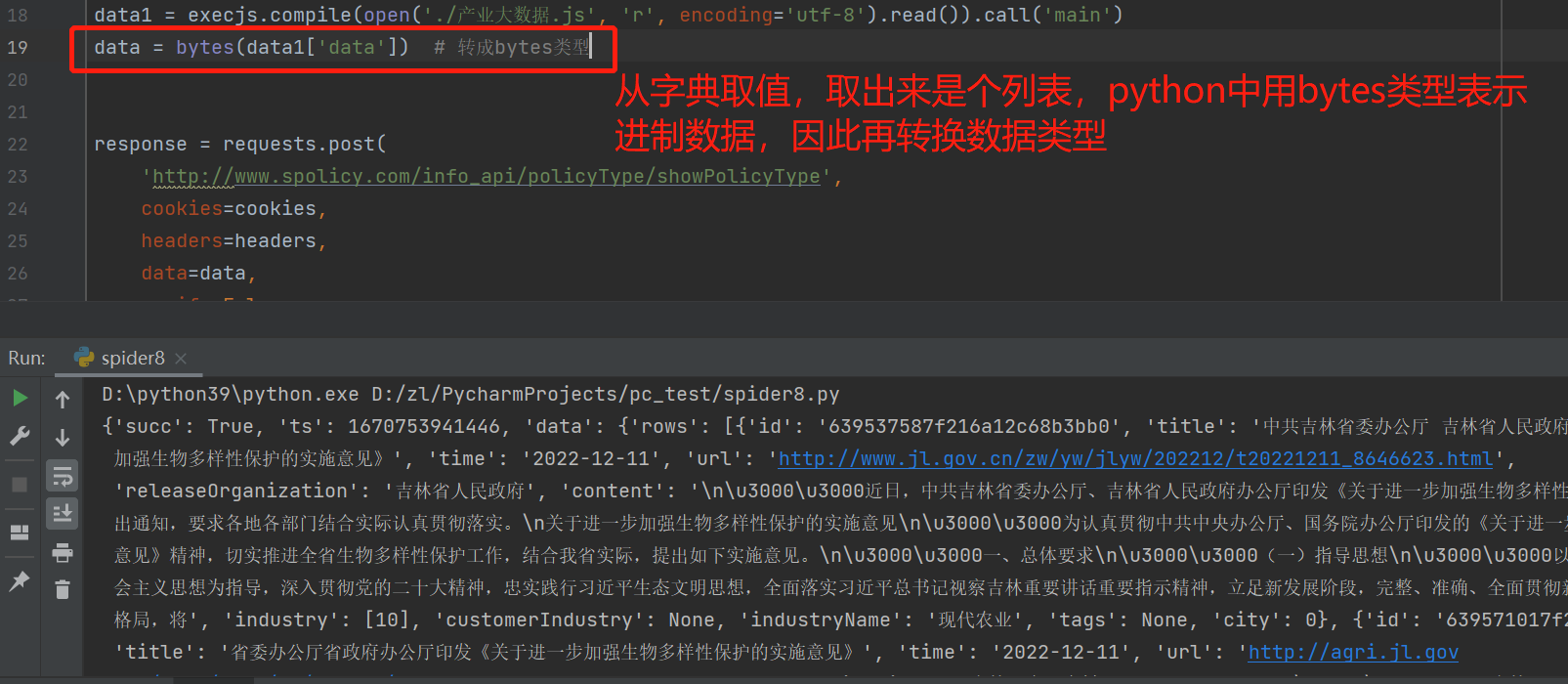
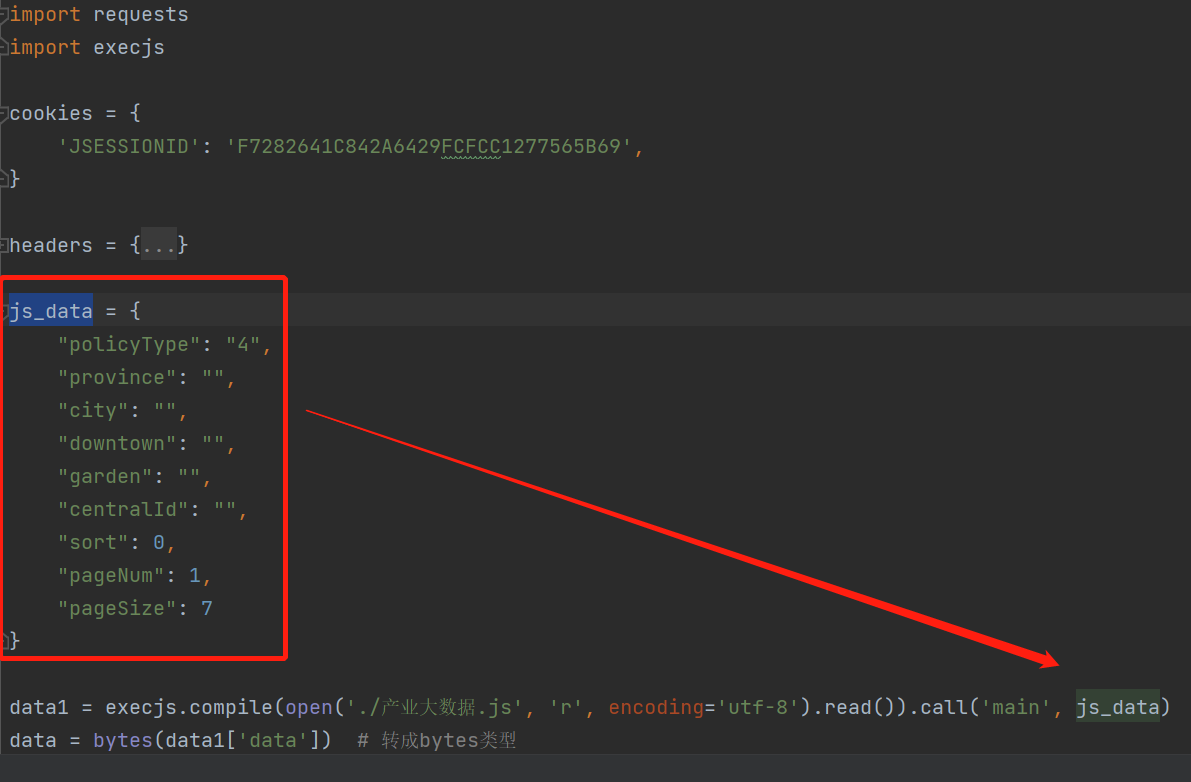
我们已经知道表单的原始数据格式,可以放到py文件中,当做参数传给js文件,再由js文件返回二进制数据:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号