ElasticSearch之-插件
es插件是一种增强Elasticsearch核心功能的途径。它们可以为es添加自定义映射类型、自定义分词器、原生脚本、自伸缩等等扩展功能。
es插件包含JAR文件,也可能包含脚本和配置文件,并且必须在集群中的每个节点上安装。安装之后,需要重启集群中的每个节点才能使插件生效。 es插件包含核心插件和第三方插件两种:
1.1
1.2 第三方插件
第三方插件是有开发者或者第三方组织自主开发便于扩展elasticsearch功能,它们拥有自己的许可协议,在使用它们之前需要清楚插件的使用协议,不一定随着elasticsearch版本升级, 所以使用者自行辨别插件和es的兼容性。第三方插件必须要与elasticsearch版本兼容。
elasticsearch的插件安装方式还是很方便易用的。
它包含了命令行,url,离线安装三种方式。
核心插件随便选择一种方式安装均可,第三方插件建议使用离线安装方式
第一种:命令行
bin/elasticsearch-plugin install [plugin_name]
# bin/elasticsearch-plugin install analysis-smartcn 安装中文分词器第二种:url安装
bin/elasticsearch-plugin install [url]
#bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-smartcn/analysis-smartcn-6.4.0.zip第三种:离线安装
https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-smartcn/analysis-smartcn-6.4.0.zip
#点击下载analysis-smartcn离线包
#将离线包解压到ElasticSearch 安装目录下的 plugins 目录下
#重启es。新装插件必须要重启es注意:插件的版本要与 ElasticSearch 版本要一致
2 Kibana安装
es的架构:C/S架构,也是B/S架构
需要有客户端:浏览器(浏览器发不出post请求),postman,kibana(官方提供的前端),elasticsearch-head(第三方写的),没有专门的桌面版客户端(例如mysql的navicate)
2.1 Kibana介绍
Kibana 是一款开源的数据分析和可视化平台,它是 ElasticStack 成员之一,设计用于和 Elasticsearch 协作。
您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
# 更多配置信息,详见 https://www.elastic.co/guide/cn/kibana/current/settings.html
server.port: 5601
server.host: "127.0.0.1"
server.name: zell
elasticsearch.hosts: ["http://localhost:9200/"]
./bin/kibana
#正常启动
#windows平台, bin\kibana.bat2.4 查看
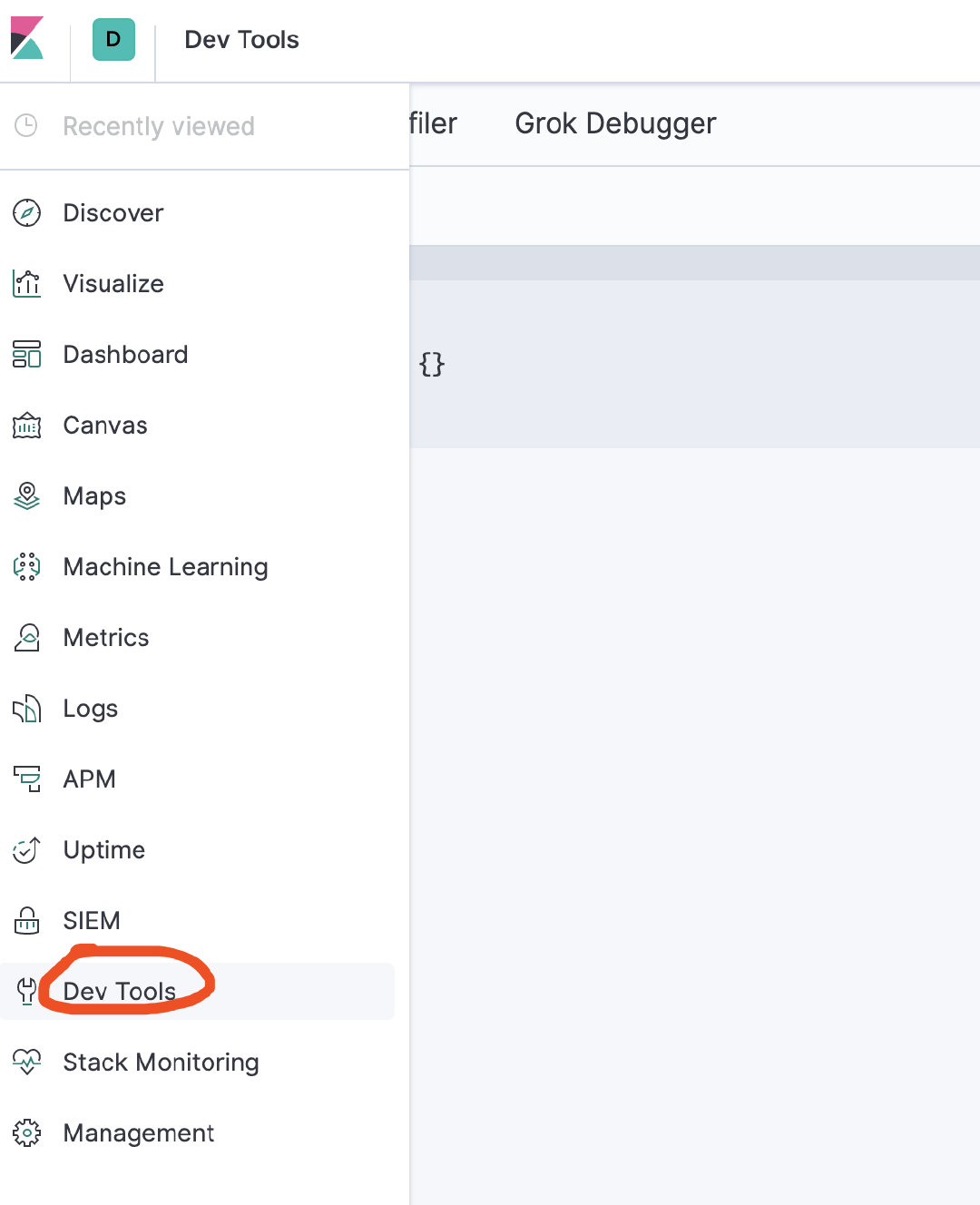
在console中输入GET _settings ,查询可以看到如下
3 ElasticSearch-head安装
elasticsearch-head是elasticsearch的一款可视化工具,依赖于node.js ,所以需要先安装node.js
Node.js 就是运行在服务端的 JavaScript。
Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台。
Node.js 是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
为什么要安装Node.js呢,下面用到的Grunt 工具是基于Node.js 使用的
下载地址 https://nodejs.org/en/download/releases/
选择版本下载, 一直下一步确定即可,安装后进入命令行中 输入 :
node -v
# 显示版本号即安装成功
npm get registry
# 输出:https://registry.npmjs.org/#切换阿里源
npm config set registry https://registry.npm.taobao.org/
#查看是否成功
npm config get registry
#或者
npm get registry
#可以看到输出
#https://registry.npm.taobao.org/
npm install -g cnpm --registry=https://registry.npm.taobao.org
#查看是否安装成功
cnpm -v
#成功后可以使用cnpm代替npm命令3.1.4 改变原有的环境变量
首先配置npm的全局模块的存放路径、cache的路径
npm config set prefix "路径"
npm config set cache "路径"3.2
#Grunt是基于Node.js的项目构建工具。它可以自动运行你所设定的任务
cnpm install grunt -g3.3
#地址:https://github.com/mobz/elasticsearch-head,可以用git下载,或者下载zip
#解压后切换到目录下
cd elasticsearch-head
#通过npm安装依赖
npm install
#启动
npm run start
#在浏览器里打开
http://localhost:9100/3.4 配置跨域
Head是第三方提供的插件,会出现跨域,修改服务端配置让它允许跨域,修改es配置
修改 Elasticsearch 安装目录中config 文件夹下 elasticsearch.yml 文件,加入下面两行:
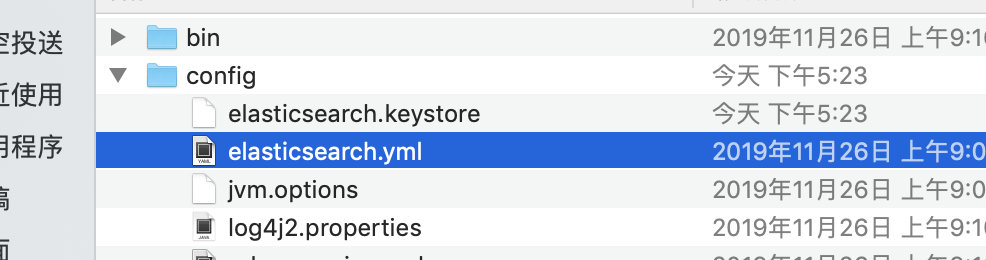
添加配置时,:后必须空格,不然启动闪退
http.cors.enabled: true
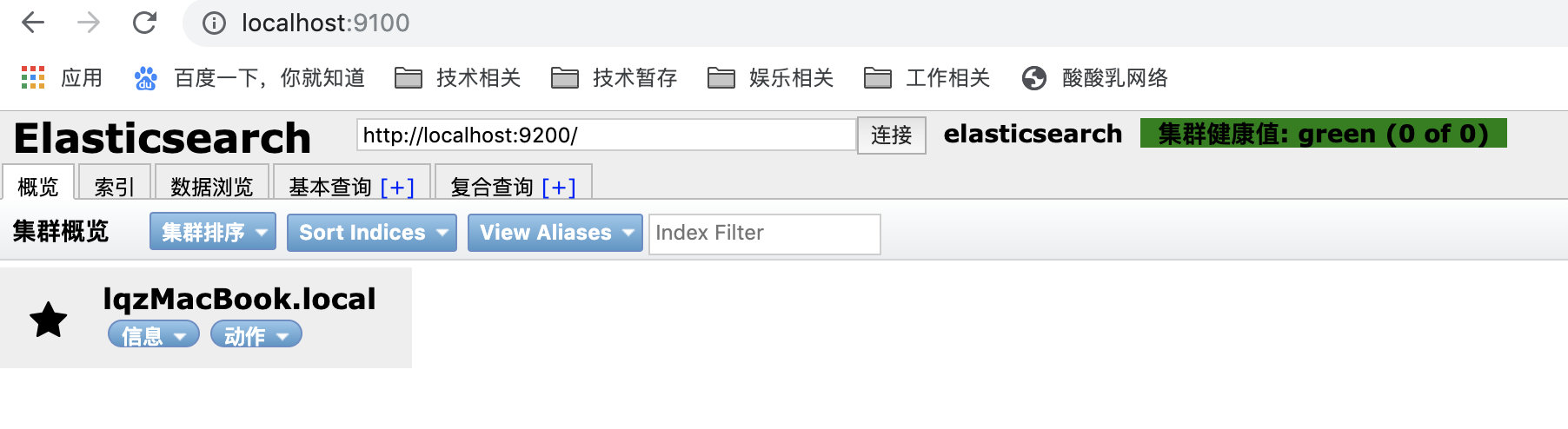
http.cors.allow-origin: "*"3.5 查看
看到如下效果表示成功
总结: kibana和elasticserach-head都可以作为es的客户端,都可以用来跟es做交互(get\post\put...)
elasticserach-head首页有概览,可以直观的查看数据(可以看到节点、索引、分片、副本)
4 安装
elasticsearch提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whitespace analyzer(空格分词器)、language analyzer(语言分词器)
而如果我们不指定分词器类型的话,elasticsearch默认是使用标准分词器的
我们需要下载中文分词插件,来实现中文分词
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IK Analyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 IK Analyzer 2012特性:
-
采用了特有的
正向迭代最细粒度切分算法,支持细粒度和智能分词两种切分模式。在系统环境:Core2 i7 3.4G双核,4G内存,window 7 64位, Sun JDK 1.6_29 64位 普通pc环境测试,IK2012具有160万字/秒(3000KB/S)的高速处理能力。 -
2012版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
-
采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
-
优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在2012版本,词典支持中文,英文,数字混合词语。
后来,被一个叫medcl(曾勇 elastic开发工程师与布道师,elasticsearch开源社区负责人,2015年加入elastic)的人集成到了elasticsearch中, 并支持自定义字典....... ps:elasticsearch的ik中文分词器插件由medcl的github上下载,而 IK Analyzer 这个分词器,如果百度搜索的,在开源中国中的提交者是,由此推断之下,才有了上面的一番由来........... 才有了接下来一系列的扯淡..........
4.3
-
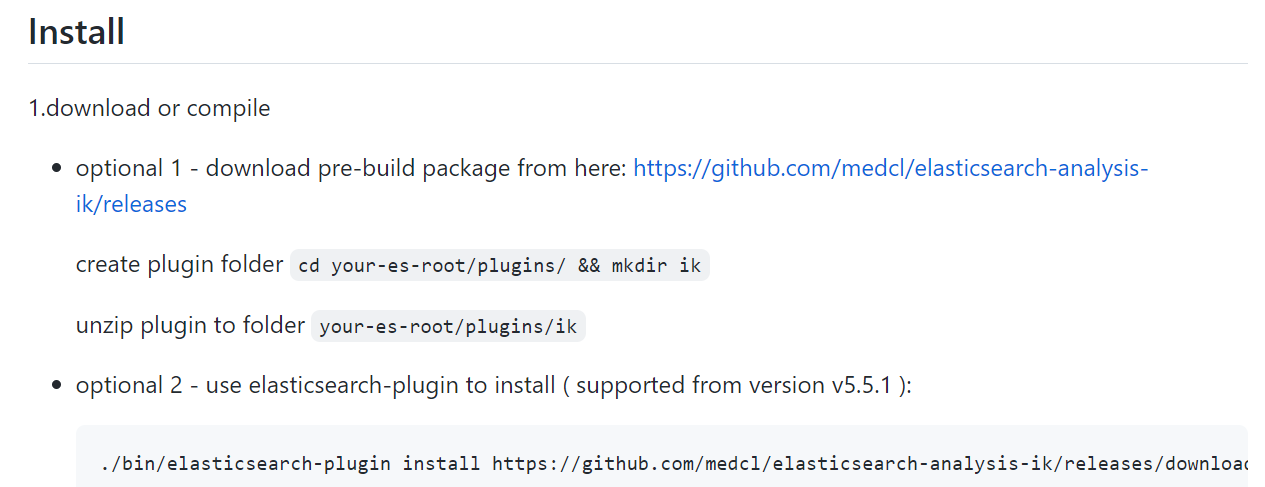
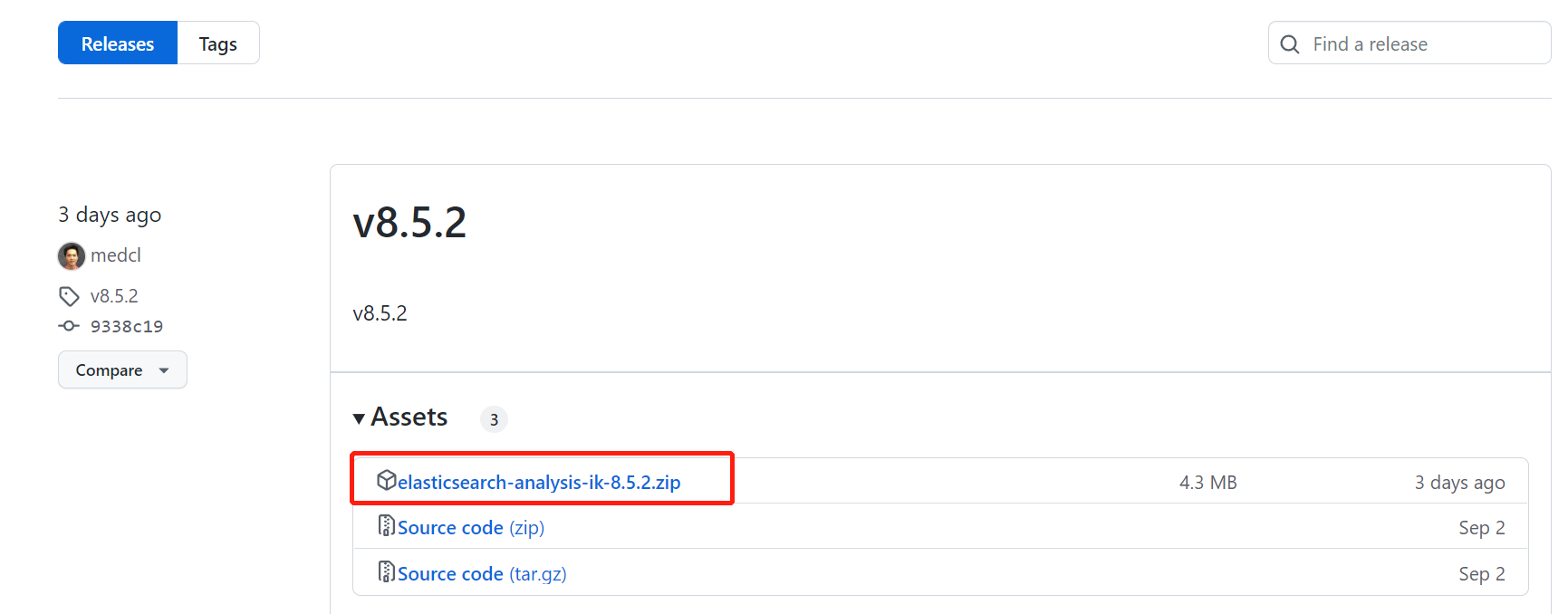
ik与elasticsearch存在兼容问题。所以在下载ik时要选择和elasticsearch版本一致的
-
zip -
C:\Program Files\elasticseach-7.5.0\plugins目录,新建一个名为ik的子目录,并将elasticsearch-analysis-ik-7.5.0.zip包解压到该ik目录内也就是C:\Program Files\elasticseach-7.5.0\plugins\ik
4.4
-
elascticsearch和kibana服务重启。 -
然后地址栏输入
http://localhost:5601,在Dev Tools中的Console
GET _analyze
{
"analyzer": "ik_max_word",
"text": "上海自来水来自海上"
}右侧就显示出结果了如下所示:
{
"tokens" : [
{
"token" : "上海",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "自来水",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "自来",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "水",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "来自",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "海上",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
}
]
}OK,安装完毕,非常的简单。
4.5
我们简要的介绍一下ik分词配置文件:
-
IKAnalyzer.cfg.xml,用来配置自定义的词库
-
main.dic,ik原生内置的中文词库,大约有27万多条,只要是这些单词,都会被分在一起。
-
surname.dic,中国的姓氏。
-
suffix.dic,特殊(后缀)名词,例如
乡、江、所、省等等。 -
preposition.dic,中文介词,例如
不、也、了、仍等等。 -
stopword.dic,英文停用词库,例如
a、an、and、the等。 -
quantifier.dic,单位名词,如
厘米、件、倍、像素等。
4.6
before
-
首先将
elascticsearch和kibana服务重启,让插件生效。 -
然后地址栏输入
http://localhost:5601,在Dev Tools中的Console界面的左侧输入命令,再点击绿色的执行按钮执行
4.6.1 第一个ik示例
GET _analyze
{
"analyzer": "ik_max_word",
"text": "上海自来水来自海上"
}右侧就显示出结果了如下所示:
{
"tokens" : [
{
"token" : "上海",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "自来水",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "自来",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "水",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "来自",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "海上",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
}
]
}那么你可能对开始的`analyzer:ik_max_word`有一丝的疑惑,这个家伙是干嘛的呀?我们就来看看这个家伙到底是什么鬼!
4.6.2
PUT ik1
{
"mappings": {
"doc": {
"dynamic": false,
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
PUT ik1/doc/1
{
"content":"今天是个好日子"
}
PUT ik1/doc/2
{
"content":"心想的事儿都能成"
}
PUT ik1/doc/3
{
"content":"我今天不活了"
}现在让我们开始查询,随便查!
GET ik1/_search
{
"query": {
"match": {
"content": "心想"
}
}
}查询结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "2",
"_score" : 0.2876821,
"_source" : {
"content" : "心想的事儿都能成"
}
}
]
}
}今天
GET ik1/_search
{
"query": {
"match": {
"content": "今天"
}
}
}结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"content" : "今天是个好日子"
}
},
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"content" : "我今天不活了"
}
}
]
}
} 与ik_max_word对应还有另一个参数。让我们一起来看下。
4.6.3
ik_max_word对应的是ik_smart
GET _analyze
{
"analyzer": "ik_smart",
"text": "今天是个好日子"
}
{
"tokens" : [
{
"token" : "今天是",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "个",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "好日子",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 2
}
]
}再来看看以最细粒度的拆分文档。
GET _analyze
{
"analyzer": "ik_max_word",
"text": "今天是个好日子"
}结果如下:
{
"tokens" : [
{
"token" : "今天是",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "今天",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "个",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "好日子",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "日子",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 5
}
]
}
4.6.4
GET ik1/_search
{
"query": {
"match_phrase": {
"content": "今天"
}
}
}结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"content" : "今天是个好日子"
}
},
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"content" : "我今天不活了"
}
}
]
}
}4.6.5 ik之短语前缀查询
同样的,我们第2部分的快速上手部分的操作在ik中同样适用。
GET ik1/_search
{
"query": {
"match_phrase_prefix": {
"content": {
"query": "今天好日子",
"slop": 2
}
}
}
}结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"content" : "今天是个好日子"
}
},
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"content" : "我今天不活了"
}
}
]
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人