Redis-Cluster
1 Redis Cluser介绍背景
1.1问题
# 存在问题
1 并发量:单机redis qps为10w/s,但是我们可能需要百万级别的并发量
2 数据量:机器内存16g--256g,如果存500g数据呢?1.2 解决
# 解决:加机器,分布式
redis cluster 在2015年的 3.0 版本加入了,满足分布式的需求,在3.0----5.0版本之间,需要利用ruby脚本,5.0版本以后,内置了
2 数据分布(分布式数据库)
2.1 存在问题
假设全量的数据非常大,500g,单机已经无法满足,我们需要进行分区,分到若干个子集中2.2 分区技术
Redis 分区技术(又称 Redis Partition)指的是将 Redis 中的数据进行拆分,然后把拆分后的数据分散到多个不同的 Redis 实例(即服务器)中,每个实例仅存储数据集的某一部分(一个子集),我们把这个过程称之为 Redis 分区操作。分区(Partition)不仅是 Redis 中的概念,几乎所有数据库管理系统都会涉及到“分区”的应用。
2.3 分区的优势
Redis 分区技术有两个方面的优势,一是提升服务器的性能,二是提高了服务器的数据存储能力。
一方面,单台机器的 Redis 服务器,其网络 IO 能力和计算资源都是非常有限的,但是如果我们将请求分散到多台机器上,那么就能充分利用多台计算机的算力和网络带宽,从而整体上提升 Redis 服务器的性能。另一方面,随着存储数据的不断增加,单台机器的存储容量会达到极限,若将数据分散存储到多台 Redis 服务器上,其存储能力也将得到大幅度提升。
注意,Redis 分区技术可以利用多台计算机的内存总和,从而创建出大型的 Redis 数据库。
2.4 分区常用方法
1) 范围分区
范围分区又称为顺序分区,是最简单、最有效的分区方法之一。所谓范围分区指的是将特定范围的 key 映射到指定的 Redis 实例上。key 的命名格式如下:
object_name:<id>比如:user:1、user:2 ...用来表示不同 id 的用户。下面通过一个示例了解范围分区的具体流程:
假设现在共有 3000 个用户,您可以把 id 从 0 到 1000 的用户映射到实例 R0 上,id 从 1001 到 2000 的用户映射到实例 R1 上,以此类推,将 id 从 2001 到 3000 的用户映射到实例 R2 上。
范围分区不仅简单,而且实用,适合许多的特定场景。但当存储的 key 不能按照范围划分时,那么范围分区就不再适用了,比如 key 是一组 uuid(通用唯一识别码)。
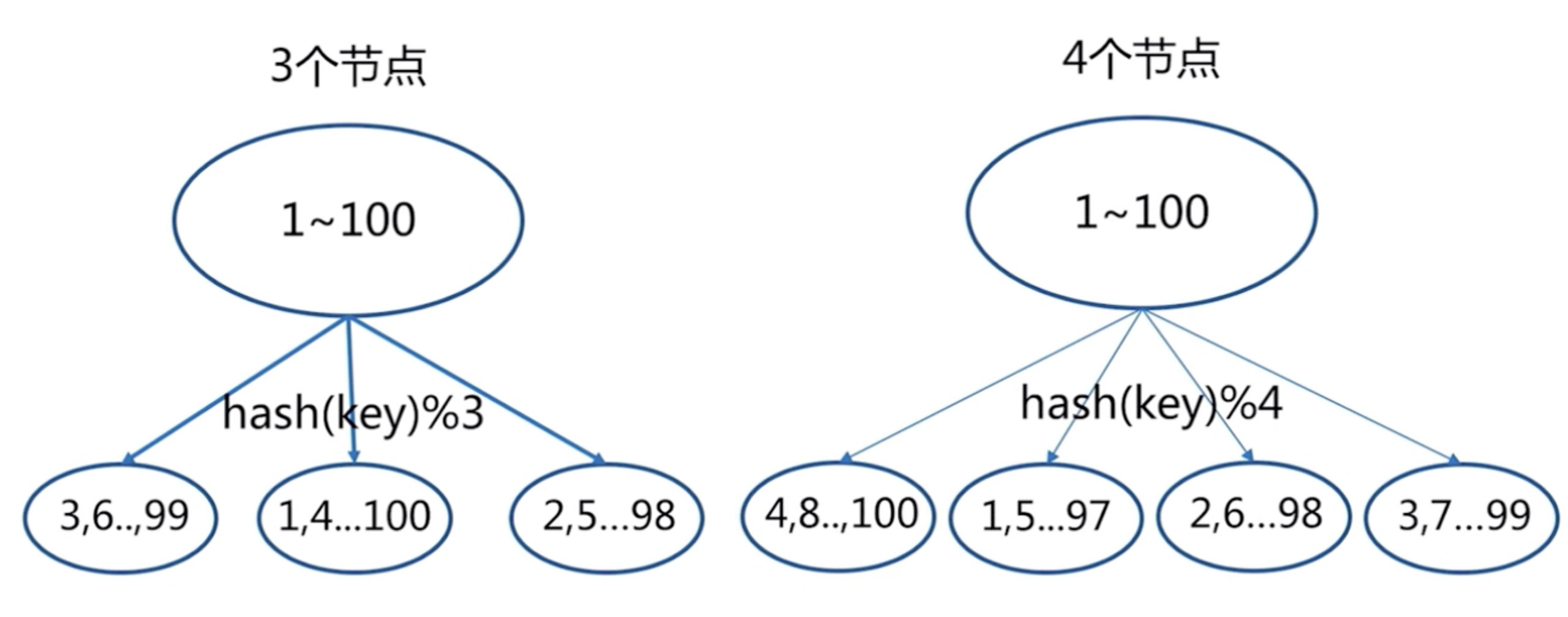
2) 哈希分区
哈希分区与范围分区相比,它最显著的优势是适合任何形式的 key。哈希分区方法并不复杂比,id 表达式如下所示:
id=hash(key)%N这里的 id 指的是 Redis 实例的编号,而 N 表示共有多少个 Redis 实例。首先调用一个 crc32() 哈希函数,它可以将 key 转换为一个整数。 如下所示:
crc32(key)假如转换后的整数是 93024922,此时共有 4 个 Redis 实例,对整数与实例的数量进行取模运算,就会得到一个 0 到 3 之间的整数,如下所示:
93024922 % 4 = 2上述计算结果为 2 ,我们就把这个 key 映射到 R2 实例中,如果为 3 就映射到 R3实例中。以此类推,通过这种方式可以将所有的 key 分散到 4 个不同的 Redis 实例中。
3) 分区方式的比较
| 分布方式 | 特点 | 产品 |
|---|---|---|
| 哈希分布 | 数据分散度高,键值分布与业务无关,无法顺序访问,支持批量操作 | 一致性哈希memcache,redis cluster,其他缓存产品 |
| 范围分布 | 数据分散度易倾斜,键值与业务相关,可顺序访问,支持批量操作 | BigTable,HBase |
4) 哈希分区的几种机制
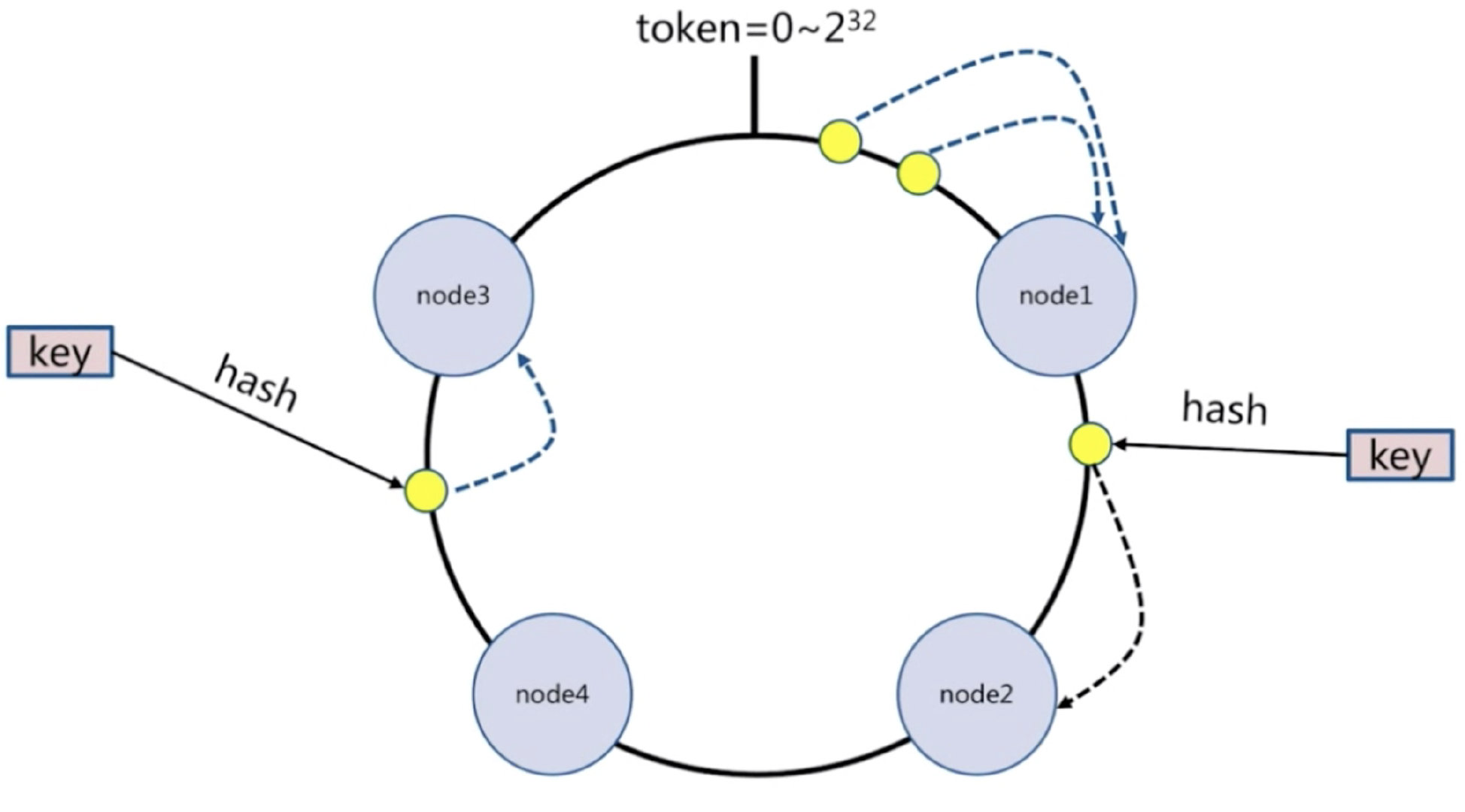
4.1) 节点取余分区
节点扩容,添加一个节点(比如从3个节点扩容到4个节点),存在问题,很多数据需要偏移,总偏移量大于80%

推荐翻倍扩容,由3变成6,数据量迁移为50%,比80%降低

# 总结:
客户端分片,通过hash+取余
节点伸缩,数据节点关系发生变化,导致影响数据迁移过大
迁移数量和添加节点数量有关:建议翻倍扩容4.2) 一致性哈希分区
每个节点负责一部分数据,对key进行hash,得到结果在node1和node2之间,就放到node2中,顺时针查找
假设添加一个新节点node5,现在只需要迁移一小部分数据,不会影响node3和node4的数据,只会迁移node1和node2的数据
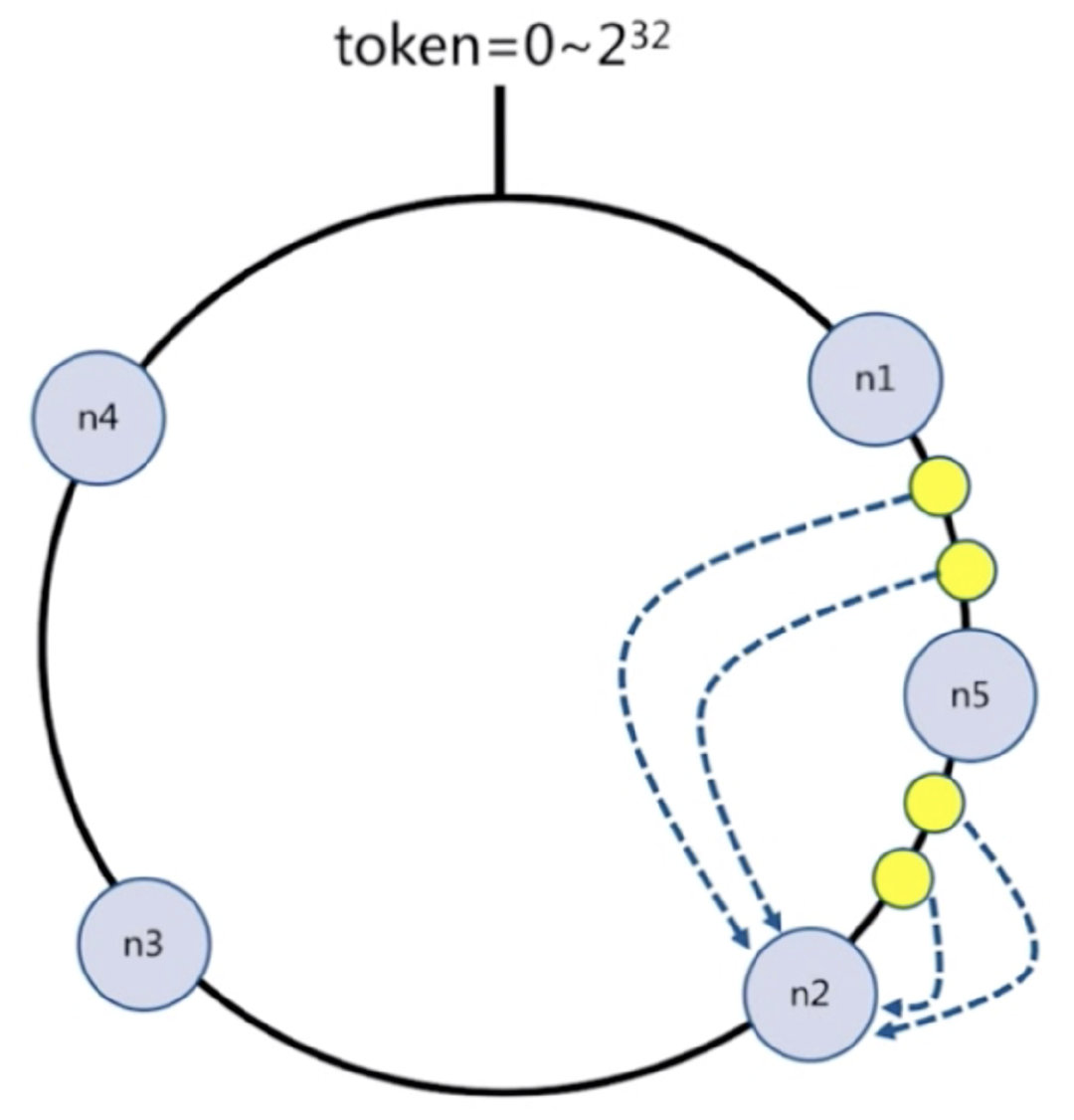
节点比较多的话合适,假设有1000个节点,加一个只要迁移千分之一的数据
#总结:
客户端分片:哈希+顺时针(优化取余)
节点伸缩:只影响临近节点,但是还有数据迁移的情况
伸缩:保证最小迁移数据和无法保证负载均衡(这样总共5个节点,数据就不均匀了),翻倍扩容可以实现负载均衡4.3) 虚拟槽分区
预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
良好的哈希函数:如CRC16
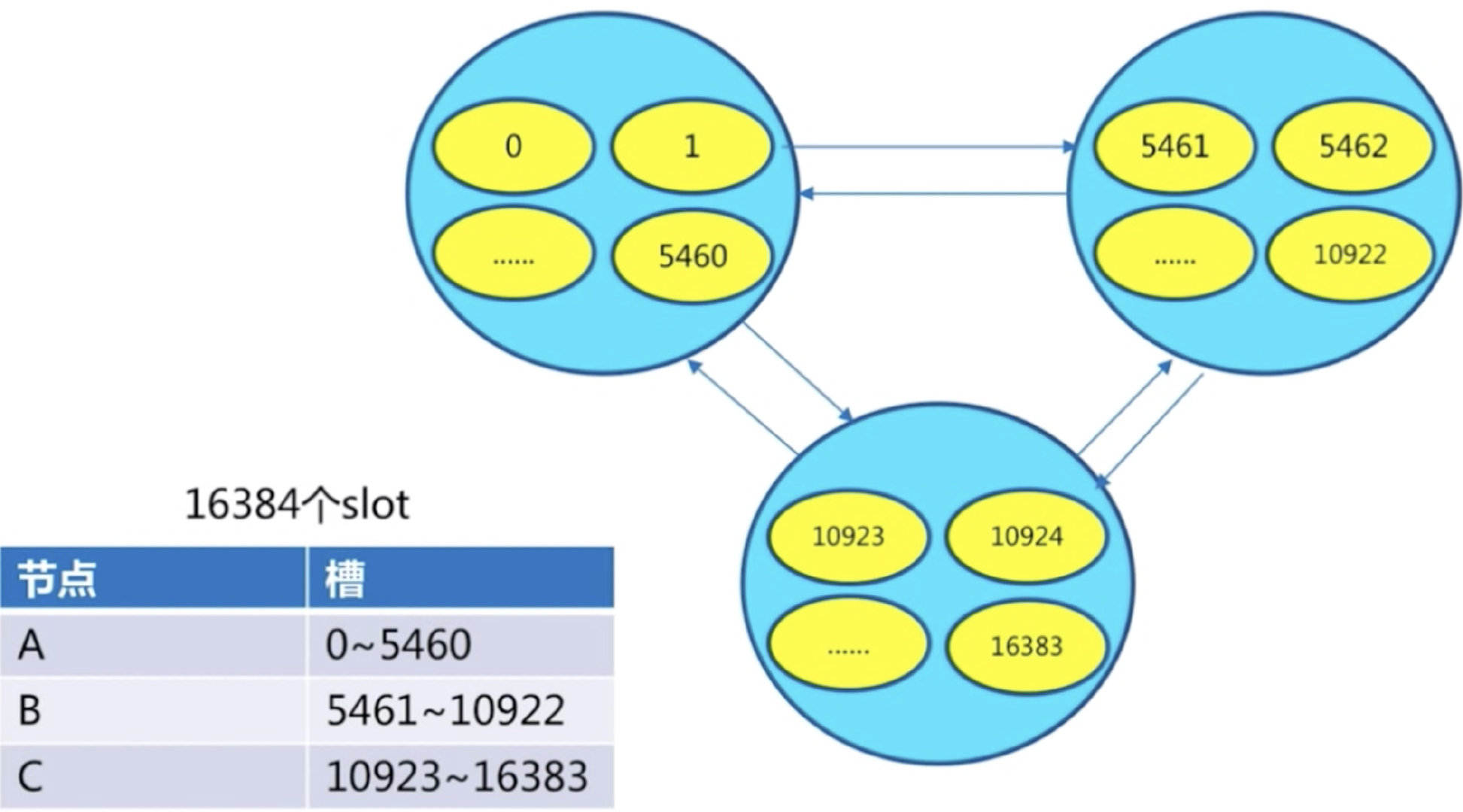
服务端管理节点、槽、数据:如redis cluster(槽的范围0–16383)
比如有5个节点,把16384个槽平均分配到每个节点,客户端会把数据发送给任意一个节点,通过CRC16对key进行哈希对16383进行取余,算出当前key属于哪部分槽,属于哪个节点。
每个节点都会记录是不是负责这部分槽,如果是负责的,进行保存,如果槽不在自己范围内,redis cluster是共享消息的模式,它知道哪个节点负责哪些槽。
返回结果,让客户端找对应的节点去存服务端管理节点,槽,关系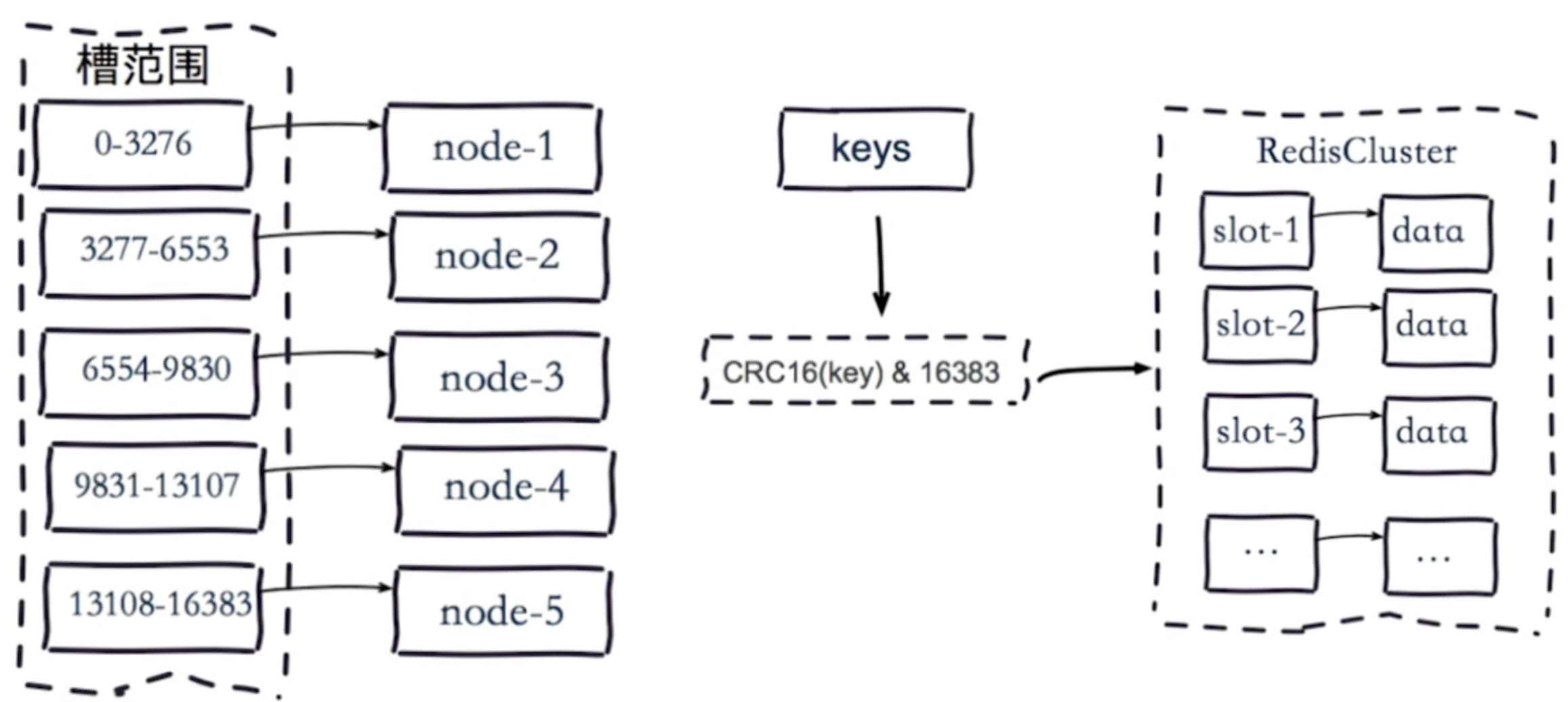
3 集群搭建
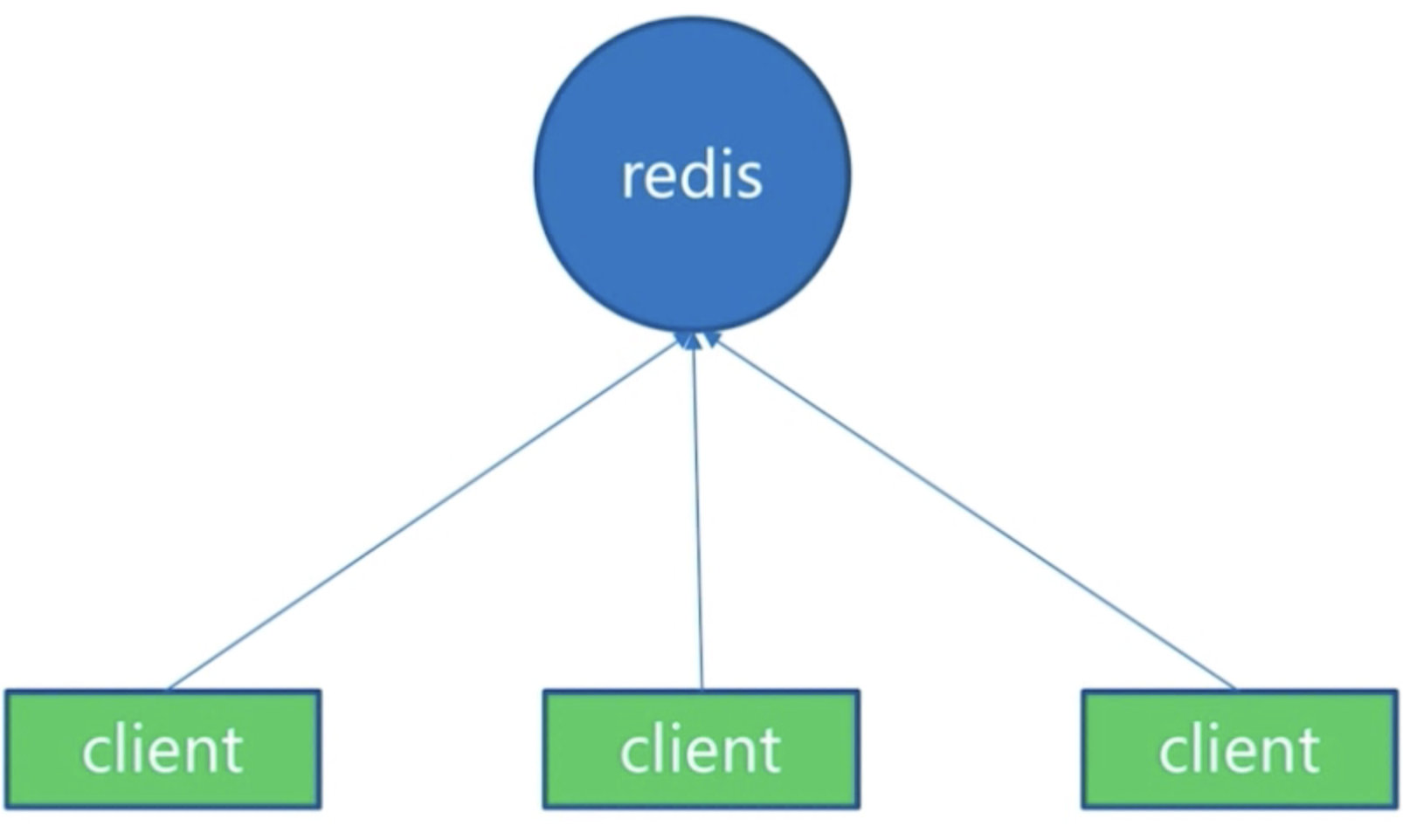
3. 1 单机架构
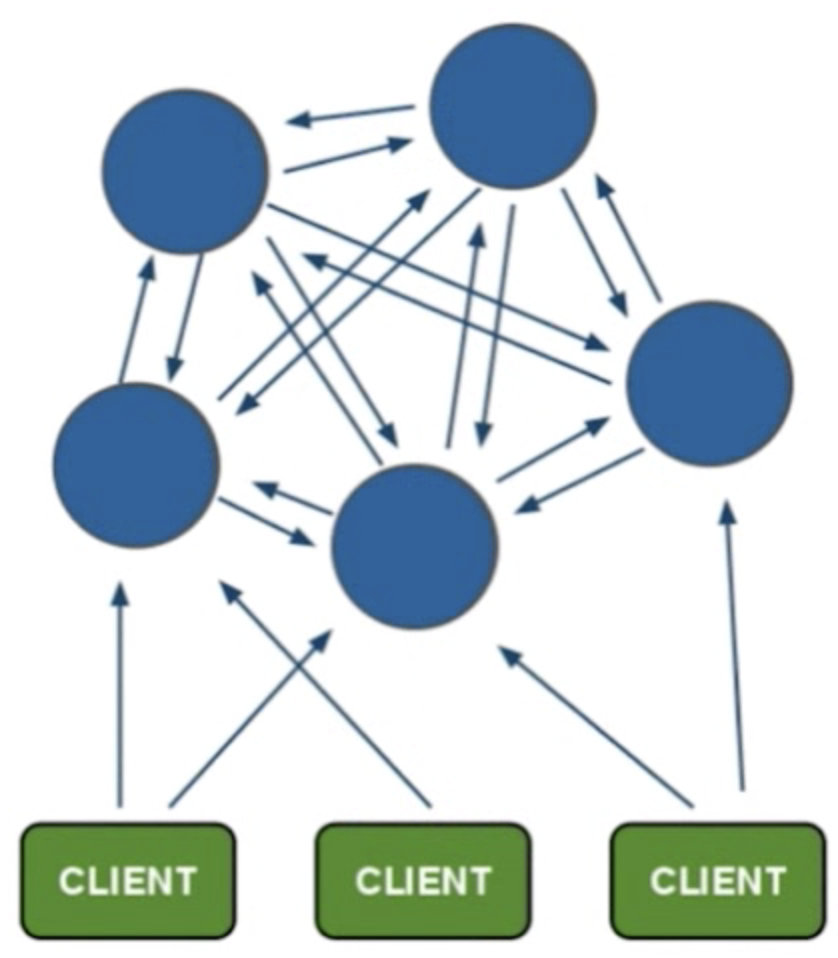
3.2 分布式架构
每个节点之间相互通信,都负责读写,客户端去存,如果不是当前节点,会返回应该存到哪个节点
3.3 Redis Cluster架构
节点(redis实例),meet(节点间通信),指派槽(redis的哈希槽,用作数据存储),复制(主从模式),高可用(sentinel模式)
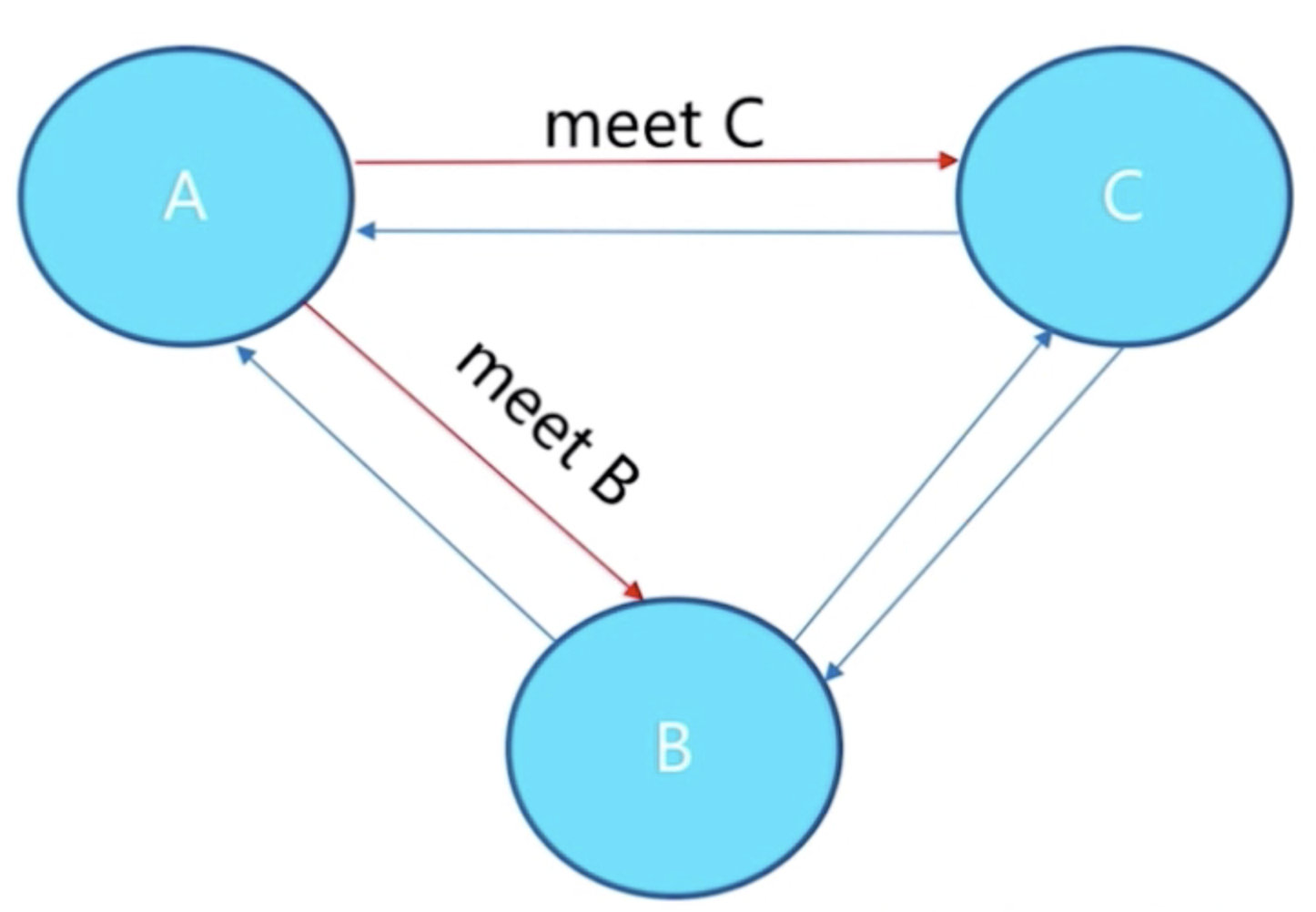
1) meet解释
A meet一下C,C回复一下,A meet一下B ,B回复一下,这样B和C也能相互感知,A,B,C之间就可以相关交互数据,所有节点共享消息
2) 指派槽
总共有16384个槽,平均分配到每个节点上
3.4 原生安装(不推荐)
以3个节点的集群为例,因为要做主从复制,一个节点配置一主一从,因此要启动6个redis实例,一般分布在6个服务器上,最少也要3个服务器(每台机器上两个redis实例,主从交叉复制)。
1) 配置开启节点
# 1 配置
port ${port}
daemonize yes
dir "/opt/soft/redis/data/"
logfile "${port}.log"
#masterauth 集群搭建时,主的密码
cluster-enabled yes # 开启cluster
cluster-node-timeout 15000 # 故障转移(主挂掉后会转移到从),超时时间 15s,集群开启后自动带了哨兵
cluster-config-file nodes-${port}.conf # 给cluster节点增加一个自己的配置文件
# 只要集群中有一个节点故障了(主从都没了,故障节点的槽不会自动迁移到别的地方,本来存放该节点槽的数据只能存放到其他节点),整个就不对外提供服务
# 了。这样设置有合理之处,当然也可以设置为no
cluster-require-full-coverage yes
# 2 开启6个节点
redis-server redis-7000.conf
redis-server redis-7001.conf
redis-server redis-7002.conf
redis-server redis-7003.conf
redis-server redis-7004.conf
redis-server redis-7005.conf2) meet(相互通信),7000节点meet了所有其他节点,所有节点就能共享消息
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7002
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7003
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7004
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 70053) 指派槽,自己根据节点计算平均划分
redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0...5461}
redis-cli -h 127.0.0.1 -p 7001 cluster addslots {5462...10922}
redis-cli -h 127.0.0.1 -p 7002 cluster addslots {10923...16383}4) 搭建主从
# cluster replicate node-id
# 让7003复制7000,7004复制7001,7005复制7002
redis-cli -h 127.0.0.1 -p 7003 cluster replicate ${node-id-7000}
redis-cli -h 127.0.0.1 -p 7004 cluster replicate ${node-id-7001}
redis-cli -h 127.0.0.1 -p 7005 cluster replicate ${node-id-7002}5) 实操
cd /opt/soft/redis/config
vim redis-7000.conf
# 写入
port 7000
daemonize yes
dir "/opt/soft/redis/data/"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage yes
# sed命令,快速生成其他配置, 不用手动一个个改,生成的配置文件里的port、logfile等自动修改
sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf
sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf
sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf
sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf
sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf
# 启动6个节点
redis-server ./config/redis-7000.conf
redis-server ./config/redis-7001.conf
redis-server ./config/redis-7002.conf
redis-server ./config/redis-7003.conf
redis-server ./config/redis-7004.conf
redis-server ./config/redis-7005.conf
# 连接其中一个,set数据(失败,因为没有分配槽)
redis-cli -p 7000
set hello world #报错
# config文件夹下出现了:nodes-7000.conf,查看一下可以看到节点的id
# 也可以:查看集群节点信息
redis-cli -p 7000 cluster nodes
# 也可以: 查看更详细信息
redis-cli -p 7000 cluster info
##### 节点握手(meet操作)
# 7000和7001 握手
redis-cli -p 7000 cluster meet 127.0.0.1 7001
# 查看握手情况
redis-cli -p 7000 cluster nodes # 可以看到已经达成了握手
redis-cli -p 7002 cluster nodes # 没有握手,还是孤立
# 继续握手
redis-cli -p 7000 cluster meet 127.0.0.1 7002
redis-cli -p 7000 cluster meet 127.0.0.1 7003
redis-cli -p 7000 cluster meet 127.0.0.1 7004
redis-cli -p 7000 cluster meet 127.0.0.1 7005
# 查看最后结果
redis-cli -p 7000 cluster info # 可以看到6个节点握手成功了
##### 当前还是不可以读写,还没分配槽
redis-cli -p 7000 cluster addslots 0 # 给7000分配第0个槽
# 这样一个个设置太麻烦,咱们写个shell脚本执行
mkdir script
cd script
vim addslots.sh
# 写入
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
done
# 保存退出,测试
sh addslots.sh 0 4096 7000
# 写具体命令
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done
# 写入
sh addslots.sh 0 5641 7000
# 查看
redis-cli -p 7000
cluster info
cluster nodes
# 继续分槽
sh addslots.sh 5641 10922 7001
sh addslots.sh 10923 16383 7002
# 查看集群状态
redis-cli -p 7000 cluster info
##### 配置主从
# 7003是7000的从
# 7004是7001的从
# 7005是7002的从
redis-cli -p 7003 cluster replicate 7000id
redis-cli -p 7004 cluster replicate 7001id
redis-cli -p 7005 cluster replicate 7002id
##### 查看
redis-cli -p 7000 cluster info # 查看某个节点详细信息
redis-cli -p 7000 cluster nodes # 查看集群节点信息
redis-cli -p 7000 cluster slots # 查看槽的信息
##### 存放数据
redis-cli -p 7000
set name lqz # 失败,name被hash后,算出来的槽位不在7000这个节点槽的范围内,因此不能放进去
redis-cli -c -p 7000
set hello world # 成功,加入 -c参数,在任意节点都能存放和获取到整个集群的数据3.5 官方工具安装(Ruby脚本)
3.0-5.0版本安装集群需要准备Ruby环境
##### 下载编译安装ruby
wget https://cache.ruby-lang.org/pub/ruby/2.5/ruby-2.5.8.tar.gz
tar -zxvf ruby-2.5.8.tar.gz
cd ruby
./configure -prefix=/usr/local/ruby
make && make install
cd /usr/local/ruby
cp bin/ruby /usr/local/bin # ruby是一种编程语言
cp bin/gem /usr/local/bin # gem类似于pip
ruby -v # 检查版本
##### 安装rubygem redis
### 更换gem源
gem sources -l
# 移除https://rubygems.org源
gem sources --remove https://rubygems.org/
# 增加https://gems.ruby-china.com/源
gem sources -a https://gems.ruby-china.com/
# 查看
gem sources -l
###### 安装gem redis
gem install redis -v 3.3.3
# 查看
gem list check redis gem
##### 安装redis-trib.rb
cd /opt/soft/redis/src
./redis-trib.rb # Redis Cluster 在5.0之后取消了ruby脚本 redis-trib.rb的支持5.0版本之后,集成到redis-cli命令里,避免了再安装ruby的相关环境。直接使用redis-clit的参数–cluster 来取代
在配置并启动6个节点后,手动命令添加集群过于繁琐,使用脚本命令就能快速创建集群,命令如下:
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
# --cluster-replicas 表示给主节点配置的从节点个数,因为我们建立的3对主从,每个主节点只有1个从节点,因此设置为1
# 创建集群命令干了几件事:
# 1、搭建主从
# 2、节点握手(meet操作)
# 3、把16384个槽平均分配到3个主节点redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.1) 集群相关操作
① 创建集群主节点
redis-cli --cluster create 192.168.163.132:6379 192.168.163.132:6380 192.168.163.132:6381② 创建集群主从节点
redis-cli --cluster create --cluster-replicas 1 192.168.163.132:6379 192.168.163.132:6380 192.168.163.132:6381 192.168.163.132:6382 192.168.163.132:6383 192.168.163.132:6384 通过该方式创建的带有从节点的机器不能够自己手动指定主节点,所以如果需要指定的话,需要自己手动指定,先使用①或③创建好主节点后,再通过④来处理。
③ 添加集群主节点
redis-cli --cluster add-node 192.168.163.132:6382 192.168.163.132:6379说明:为一个指定集群添加节点,需要先连到该集群的任意一个节点IP(192.168.163.132:6379),再把新节点加入。该2个参数的顺序有要求:新加入的节点放前。
④ 添加集群从节点
redis-cli --cluster add-node 192.168.163.132:6382 192.168.163.132:6379 --cluster-slave --cluster-master-id 117457eab5071954faab5e81c3170600d5192270说明:把6382节点加入到6379节点的集群中,并且当做node_id为 117457eab5071954faab5e81c3170600d5192270 的从节点。如果不指定 –cluster-master-id 会随机分配到任意一个主节点。
⑤ 删除节点
redis-cli --cluster del-node 192.168.163.132:6384 f6a6957421b80409106cb36be3c7ba41f3b603ff说明:指定IP、端口和node_id 来删除一个节点,从节点可以直接删除,主节点不能直接删除,删除之后,该节点会被shutdown。
注意:当被删除掉的节点重新起来之后不能自动加入集群,但其和主的复制还是正常的,也可以通过该节点看到集群信息(通过其他正常节点已经看不到该被del-node节点的信息)。
如果想要再次加入集群,则需要先在该节点执行cluster reset,再用add-node进行添加,进行增量同步复制。
⑥ 检查集群
redis-cli --cluster check 192.168.163.132:6384 --cluster-search-multiple-owners说明:任意连接一个集群节点,进行集群状态检查
⑦ 集群信息查看
redis-cli --cluster info 192.168.163.132:6384⑧ 修复集群
redis-cli --cluster fix 192.168.163.132:6384 --cluster-search-multiple-owners说明:修复集群和槽的重复分配问题
⑨ 设置集群的超时时间
redis-cli --cluster set-timeout 192.168.163.132:6382 10000说明:连接到集群的任意一节点来设置集群的超时时间参数cluster-node-timeout
⑩ 集群中执行相关命令
redis-cli --cluster call 192.168.163.132:6381 config set requirepass cc
redis-cli -a cc --cluster call 192.168.163.132:6381 config set masterauth cc
redis-cli -a cc --cluster call 192.168.163.132:6381 config rewrite说明:连接到集群的任意一节点来对整个集群的所有节点进行设置。
到此,相关集群的基本操作已经介绍完,现在说明集群迁移的相关操作。
2) 迁移相关操作
① 在线迁移slot :在线把集群的一些slot从集群原来slot节点迁移到新的节点,即可以完成集群的在线横向扩容和缩容。有2种方式进行迁移
一是根据提示来进行操作:
直接连接到集群的任意一节点
redis-cli -a cc --cluster reshard 192.168.163.132:6379二是根据参数进行操作:
redis-cli -a cc --cluster reshard 192.168.163.132:6379 --cluster-from 117457eab5071954faab5e81c3170600d5192270 --cluster-to 815da8448f5d5a304df0353ca10d8f9b77016b28 --cluster-slots 10 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 10 --cluster-replace说明:连接到集群的任意一节点来对指定节点指定数量的slot进行迁移到指定的节点。
② 平衡(rebalance)slot :
1)平衡集群中各个节点的slot数量
redis-cli -a cc --cluster rebalance 192.168.163.132:63792)根据集群中各个节点设置的权重等平衡slot数量(不执行,只模拟)
redis-cli -a cc --cluster rebalance --cluster-weight 117457eab5071954faab5e81c3170600d5192270=5 815da8448f5d5a304df0353ca10d8f9b77016b28=4 56005b9413cbf225783906307a2631109e753f8f=3 --cluster-simulate 192.168.163.132:6379③ 导入集群
redis-cli --cluster import 192.168.163.132:6379 --cluster-from 192.168.163.132:9021 --cluster-replace说明:外部Redis实例(9021)导入到集群中的任意一节点。
注意:测试下来发现参数–cluster-replace没有用,如果集群中已经包含了某个key,在导入的时候会失败,不会覆盖,只有清空集群key才能导入。
并且发现如果集群设置了密码,也会导入失败,需要设置集群密码为空才能进行导入(call)。通过monitor(9021)的时候发现,在migrate的时候需要密码进行auth认证。
4 集群伸缩
4.1 伸缩原理
# 加入节点,删除节点:槽和数据在节点之间的移动
4.2 集群扩容
# 作用:为它迁移槽和数据实现扩容 作为从节点负责故障转移
#####1 准备新节点,准备两个节点,一主一从
-集群模式
-配置和其他节点统一, sed命令
-启动后是孤儿节点
sed 's/7000/7006/g' redis-7000.conf > redis-7006.conf
sed 's/7000/7007/g' redis-7000.conf > redis-7007.conf
redis-server conf/redis-7006.conf
redis-server conf/redis-7007.conf
# 孤立状态,没有meet
redis-cli -p 7006 cluster nodes
#####2 加入集群
### 方式一
在7000上执行,6个节点已经相互感知了,因此只用跟其中一个meet就可以加入进来
redis-cli -p 7000 cluster meet 127.0.0.1 7006
redis-cli -p 7000 cluster meet 127.0.0.1 7007
### 方式二
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000
# 查看配置,没有分配槽
redis-cli -p 7006 cluster nodes
# 把7007做为7006的从
redis-cli -p 7007 cluster replicate 7006的id
#####3 迁移槽和数据,手动命令执行
# 槽迁移计划
# 迁移数据
# 添加从节点
######4 我们不用手动迁移槽和数据,直接使用redis-trip
redis-cli --cluster reshard 127.0.0.1:7000
# 打印当前集群状态
# 希望迁移多少个槽:4096(16384/4,扩容后4个节点平均分配,可以不用平均分配)
# 希望哪个id是接收的:7006的id
# 传入source id :all 可以指定从node1、node2、node3各迁入多少个,写入all表示平均从3个节点迁入,总数为4096
# yes
# 查看
redis-cli -p 7000 cluster nodes
redis-cli -p 7000 cluster slots## 其他:
-如果想给7000再加一个从节点怎么弄?
# 启动起7006,meet进入集群,再让7006复制7000
redis-cli -p 7000 cluster meet 127.0.0.1 7006
redis-cli -p 7006 cluster replicate 7000的id4.3 集群缩容
# 下线迁槽(把7006的4096个槽分别迁移到7000、7001、7002上)
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7000的id --cluster-slots 1365 127.0.0.1:7000
yes
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7001的id --cluster-slots 1365 127.0.0.1:7001
yes
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7002的id --cluster-slots 1366 127.0.0.1:7002
yes
# 忘记节点,关闭节点
redis-cli --cluster del-node 127.0.0.1:7007 要下线的7007id # 先下从,再下主,因为先下主会触发故障转移
redis-cli --cluster del-node 127.0.0.1:7006 要下线的7006id
5 客户端连接
# rediscluster
# pip3 install redis-py-cluster
from rediscluster import RedisCluster
startup_nodes = [{"host":"127.0.0.1", "port": "7000"},{"host":"127.0.0.1", "port": "7001"},{"host":"127.0.0.1", "port": "7002"}]
# rc = RedisCluster(startup_nodes=startup_nodes,decode_responses=True)
rc = RedisCluster(startup_nodes=startup_nodes)
rc.set("foo", "bar")
print(rc.get("foo"))
6 集群原理
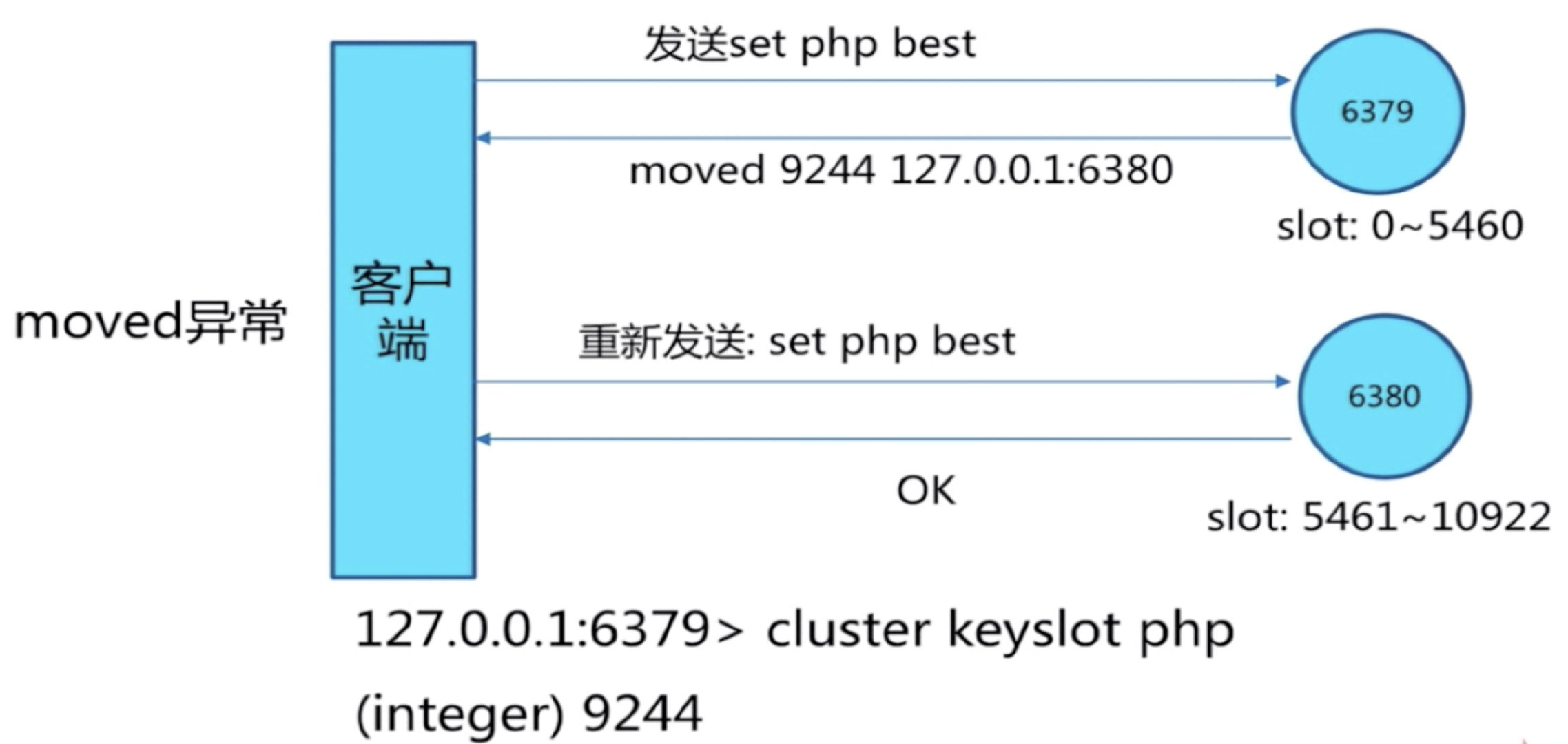
move重定向

槽命中
cluster keyslot hello 可以计算出槽的值

槽不命中:moved异常