高级api使用
1 慢查询
1.1 生命周期
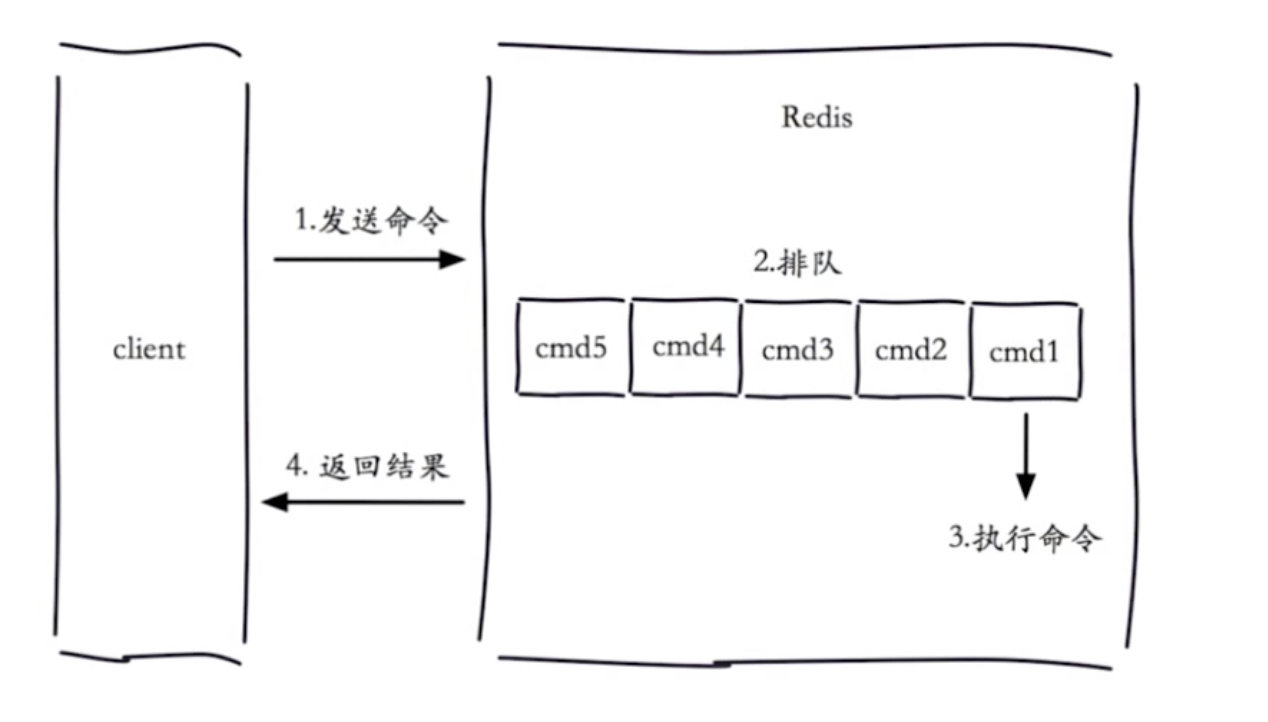
我们配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询.
慢查询发生在第三阶段
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
1.2 两个配置
1.2.1 slowlog-max-len
慢查询是一个先进先出的队列,决定 slow log 最多能保存多少条日志
固定长度
保存在内存中
1.2.2 slowlog-log-slower-than
慢查询阈值(单位:微秒), 它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
slowlog-log-slower-than=0,记录所有命令
slowlog-log-slower-than <0,不记录任何命令
1.2.3 配置方法
1 默认配置
config get slowlog-max-len=128
Config get slowly-log-slower-than=10000
2 修改配置文件重启
3 动态配置
# 设置记录所有命令
config set slowlog-log-slower-than 0
# 最多记录100条
config set slowlog-max-len 100
# 持久化到本地配置文件
config rewrite
'''
config set slowlog-max-len 1000
config set slowlog-log-slower-than 1000
'''1.3 三个命令
slowlog get [n] #获取慢查询队列,n是命令的索引
'''
日志由4个属性组成:
1)日志的标识id
2)发生的时间戳
3)命令耗时
4)执行的命令和参数
'''
slowlog len #获取慢查询队列长度
slowlog reset #清空慢查询队列1.4 经验
1 slowlog-max-len
2 slowlog-log-slower-than # 不要设置过小,通常设置1000左右
3 理解命令生命周期
4 定期持久化慢查询
5 用慢查询命令排除redis性能
2 pipeline与事务
2.1 什么是pipeline(管道)
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现
将一批命令,批量打包,在redis服务端批量计算(执行),然后把结果批量返回
1次pipeline(n条命令)=1次网络时间+n次命令时间
pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到pipeline关闭;
如果你的pipeline的指令集很庞大,为了不干扰链接中的其他操作,你可以为pipeline操作新建Client链接,让pipeline和其他正常操作分离在2个client中。
不过pipeline事实上所能容忍的操作个数,和socket-output缓冲区大小/返回结果的数据尺寸都有很大的关系;
同时也意味着每个redis-server同时所能支撑的pipeline链接的个数,也是有限的,这将受限于server的物理内存或网络接口的缓冲能力2.2 客户端实现
以python语言为例
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
conn = redis.Redis(connection_pool=pool)
# 创建pipeline
pipe = conn.pipeline(transaction=True)
# 开启事务
pipe.multi()
pipe.set('name', 'lqz')
# 其他代码,可能出异常
pipe.set('role', 'nb')
pipe.execute()2.3 与原生操作对比
通过pipeline提交的多次命令,在服务端执行的时候,可能会被拆成多次执行,而mget等操作,是一次性执行的,所以,pipeline执行的命令并非原子性的2.4 使用建议
1 注意每次pipeline携带的数据量
2 pipeline每次只能作用在一个Redis的节点上
3 M(mset,mget….)操作和pipeline的区别
# set和mset比较: mset批量存入,减少了网络io次数
# mset和pipline比较:虽然都是批量一次性插入,但mset从内核缓冲区到用户缓冲区,还是搬运了多次,而pipline就是一次,少了这部分的io,效率略高2.5 原生事务操作
Redis 事务的目的是方便用户一次执行多个命令。执行 Redis 事务可分为三个阶段:
- 开始事务
- 命令入队
- 执行事务
Redis 事务具有两个重要特性:
1) 单独的隔离操作
事务中的所有命令都会被序列化,它们将按照顺序执行,并且在执行过的程中,不会被其他客户端发送来的命令打断。
2) 不保证原子性
在 Redis 的事务中,如果存在命令执行失败的情况,那么其他命令依然会被执行,不支持事务回滚机制。
注意:Redis 不支持事务回滚,原因在于 Redis 是一款基于内存的存储系统,其内部结构比较简单,若支持回滚机制,则让其变得冗余,并且损耗性能,这与 Redis 简单、快速的理念不相符合。
Redis 事务命令:
| 命令 | 说明 |
|---|---|
| MULTI | 开启一个事务 |
| EXEC | 执行事务中的所有命令 |
| WATCH key [key ...] | 在开启事务之前用来监视一个或多个key 。如果事务执行时这些 key 被改动过,那么事务将被打断。 |
| DISCARD | 取消事务。 |
| UNWATCH | 取消 WATCH 命令对 key 的监控。 |
Redis 事务应用:
您可以把事务可以理解为一个批量执行 Redis 命令的脚本,但这个操作并非原子性操作,也就是说,如果中间某条命令执行失败,并不会导致前面已执行命令的回滚,同时不会中断后续命令的执行(不包含监听 key 的情况)。示例如下:
开启事务
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR 1
QUEUED #命令入队成功
127.0.0.1:6379> SET num 10
QUEUED #命令入队成功
127.0.0.1:6379> EXEC #批量执行命令
1) (integer) 1
2) OK若您在事务开启之前监听了某个 key,那么您不应该在事务中尝试修改它,否则会导致事务中断。
# 客户端1 监听着一个key
127.0.0.1:6379> set name lqz
OK
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> WATCH name
OK
# 客户端1 开启事务
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> incr age
QUEUED
127.0.0.1:6379> incr age
QUEUED
# 在客户端1执行exec命令前,如果有其他客户端修改了客户端1监听的key,如 set name egon
# 客户端1执行exec命令失败
127.0.0.1:6379> EXEC
(nil)
#取消监听key
127.0.0.1:6379> UNWATCH
OK
3 发布订阅
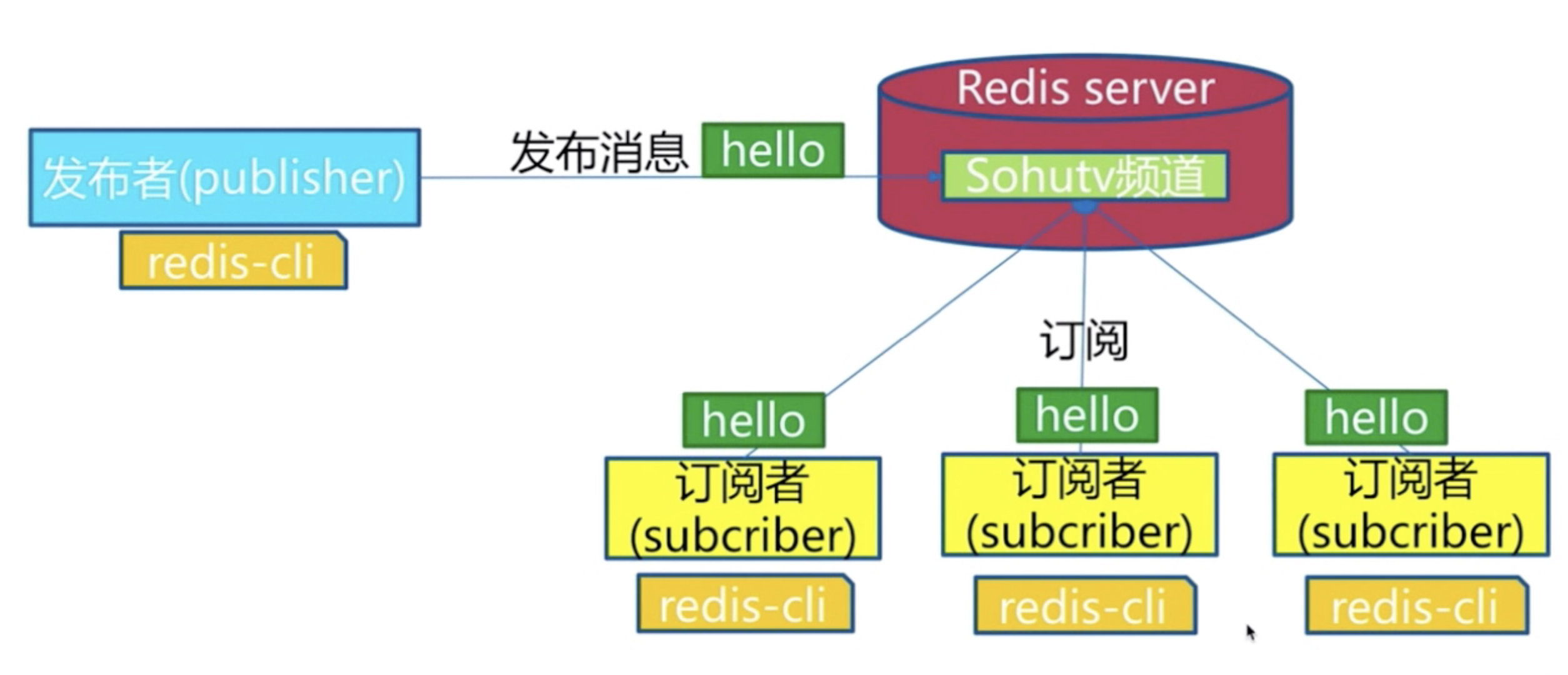
Redis PubSub 模块又称发布订阅者模式,是一种消息传递系统,实现了消息多播功能。发布者(即发送方)发送消息,订阅者(即接收方)接收消息,而用来传递消息的链路则被称为 channel。在 Redis 中,一个客户端可以订阅任意数量的 channel(可译为频道)。
消息多播:生产者生产一次消息,中间件负责将消息复制到多个消息队列中,每个消息队列由相应的消费组进行消费,这是分布式系统常用的一种解耦方式。
3.1 角色
发布者/订阅者/频道
发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(消息发布后订阅的,无法获取历史消息)
3.2 模型
3.3 API
1) 订阅者/等待接收消息
首先打开 Redis 客户端,然后订阅了一个名为“souhu:tv”的 channel,使用如下命令:
# 订阅channel,可以订阅一个或多个
# subscribe [channel]
127.0.0.1:6379> SUBSCRIBE souhu:TV
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "souhu:TV"
3) (integer) 1 上述示例使用SUBSCRIBE命令订阅了名为 souhu:TV 的 channel。命令执行后该客户端会出处于等待接收消息的阻塞状态
2) 发布者/发送消息
下面再启动一个 Redis 客户端,输入如下命令:
# 发布命令 publish channel message
# publish souhu:tv "hello world" 在souhu:tv频道发布一条hello world 返回订阅者个数
127.0.0.1:6379> PUBLISH souhu:tv "hello world"
(integer) 1
127.0.0.1:6379> PUBLISH souhu:tv "how are you"
(integer) 1通过上述PUBLISH命令发布了三条信息。现在两个客户端在处于同一个名为“souhu:TV”的频道上,前者负责接收消息,后者负责发布消息。
3) 订阅者/成功接收消息
完成了上述操作后,您会在接收消息的客户端得到如下输出结果:
127.0.0.1:6379> SUBSCRIBE souhu:TV
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "souhu:TV"
3) (integer) 1
1) "message"
2) "souhu:TV"
3) "hello world"
1) "message"
2) "souhu:TV"
3) "how are you"3.4 常用命令汇总
| 命令 | 说明 |
|---|---|
| PSUBSCRIBE pattern [pattern ...] | 订阅一个或多个符合指定模式的频道。 |
| PUBSUB subcommand [argument [argument ...]] | 查看发布/订阅系统状态,可选参数 1) channel 返回在线状态的频道。 2) numpat 返回指定模式的订阅者数量。 3) numsub 返回指定频道的订阅者数量。 |
| PUBSUB subcommand [argument [argument ...]] | 将信息发送到指定的频道。 |
| PUNSUBSCRIBE [pattern [pattern ...]] | 退订所有指定模式的频道。 |
| SUBSCRIBE channel [channel ...] | 订阅一个或者多个频道的消息。 |
| UNSUBSCRIBE [channel [channel ...]] | 退订指定的频道。 |
3.5 基本命令使用
#1、订阅匹配模式的频道,*代表通配符,会匹配所有www开头的频道
127.0.0.1:6379> PSUBSCRIBE www*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "www*"
3) (integer) 1
#按ctrl+c退出阻塞状态
^C
C:\Users\Administrator>redis-cli
#2、查看发布订阅系统状态,返回相应的频道
127.0.0.1:6379> PUBSUB channels
1) "www.biancheng.net"
#3、退订匹配模式的频道
127.0.0.1:6379> PUNSUBSCRIBE www*
1) "punsubscribe"
2) "www*"
3) (integer) 0
#4、退订指定频道
127.0.0.1:6379> UNSUBSCRIBE souhu:TV
1) "unsubscribe"
2) "souhu:TV"
3) (integer) 0
#5、#列出给定频道的订阅者数量
pubsub numsub [channel...]
#6、列出被订阅模式的数量
pubsub numpat3.6 发布订阅和消息队列
发布订阅数全收到,消息队列有个抢的过程,只有一个抢到
4 Bitmap位图
4.1 位图是什么
在平时开发过程中,经常会有一些 bool 类型数据需要存取。比如记录用户一年内签到的次数,签了是 1,没签是 0。如果使用 key-value 来存储,那么每个用户都要记录 365 次,当用户成百上亿时,需要的存储空间将非常巨大。为了解决这个问题,Redis 提供了位图结构。

位图适用于一些特定的应用场景,比如用户签到次数、或者登录次数等。上图是表示一位用户 10 天内来网站的签到次数,1 代表签到,0 代表未签到,这样可以很轻松地统计出用户的活跃程度。相比于直接使用字符串而言,位图中的每一条记录仅占用一个 bit 位,从而大大降低了内存空间使用率。
Redis 官方也做了一个实验,他们模拟了一个拥有 1 亿 2 千 8 百万用户的系统,然后使用 Redis 的位图来统计“日均用户数量”,最终所用时间的约为 50ms,且仅仅占用 16 MB内存。
位图(bitmap)同样属于 string 数据类型。Redis 中一个字符串类型的值最多能存储 512 MB 的内容,每个字符串由多个字节组成,每个字节又由 8 个 Bit 位组成。位图结构正是使用“位”来实现存储的,它通过将比特位设置为 0 或 1来达到数据存取的目的,这大大增加了 value 存储数量,它存储上限为2^32 。位图本质上就是一个普通的字节串,也就是 bytes 数组。您可以使用getbit/setbit命令来处理这个位数组。
下图是字符串big对应的二进制(b是98)

4.2 相关命令
set hello big #放入key为hello 值为big的字符串
getbit hello 0 #取位图的第0个位置,返回0
getbit hello 1 #取位图的第1个位置,返回1 如上图
##直接操纵位图
setbit key offset value #给位图指定索引设置值,用来设置或者清除某一位上的值,其返回值是原来位上存储的值。key 在初始状态下所有的位都为 0
setbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig
setbit test 50 1 #test不存在,在key为test的value的第50位设为1,那其他位都以0补
bitcount key [start end] #获取位图指定范围(start到end,单位为字节,注意一个字节8个bit位,如果不指定就是获取全部)位值为1的个数
bitop op destkey key [key...] #将多个Bitmap的and(交集)/or(并集)/not(非)/xor(异或),操作并将结果保存在destkey中
bitop and after_lqz lqz lqz2 #把lqz和lqz2按位与操作,放到after_lqz中
bitpos key targetBit start end #计算位图指定范围(start到end,单位为字节,如果不指定是获取全部)第一个偏移量对应的值等于targetBit的位置
bitpos hello 1 #big 对应位图中第一个1的位置,在第二个位置上,由于从0开始返回1
bitpos hello 0 #big 对应位图中第一个0的位置,在第一个位置上,由于从0开始返回0
bitpos hello 1 1 2 #返回9:返回从第一个字节到第二个字节之间 第一个1的位置,看上图,为9
4.3 位图应用原理
某网站要统计一个用户一年的签到记录,若用 sring 类型存储,则需要 365 个键值对。若使用位图存储,用户签到就存 1,否则存 0。最后会生成 11010101... 这样的存储结果,其中每天的记录只占一位,一年就是 365 位,约为 46 个字节。如果只想统计用户签到的天数,那么统计 1 的个数即可。
Redis 的位数组是自动扩展的,如果设置了某个偏移位置超出了现有的内容范围,位数组就会自动扩充。
下面设置一个名为 a 的 key,我们对这个 key 进行位图操作,使得 a 的对应的 value 变为“he”。
首先我们分别获取字符“h”和字符“e”的八位二进制码,如下所示:
>>> bin(ord("h"))
'0b1101000'
>>> bin(ord("e"))
'0b1100101'接下来,只要对需值为 1 的位进行操作即可。如下图所示:
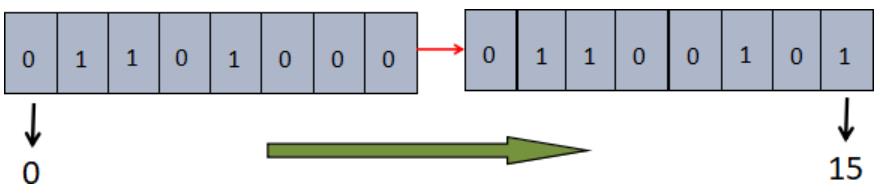
把 h 和 e 的二进制码连接在一起,第一位的下标是 0,依次递增至 15,然后将数字为 1 的位置标记出来,得到 1/2/4/9/10/13/15,我们把这组数字称为位的“偏置数”,最后按照上述偏置数对字符 a 进行如下位图操作。注意,key 的初始二进制位全部为 0。
C:\Users\Administrator>redis-cli
127.0.0.1:6379> SETBIT a 1 1
(integer) 0
127.0.0.1:6379> SETBIT a 2 1
(integer) 0
127.0.0.1:6379> SETBIT a 4 1
(integer) 0
127.0.0.1:6379> get a
"h"
127.0.0.1:6379> SETBIT a 9 1
(integer) 0
127.0.0.1:6379> SETBIT a 10 1
(integer) 0
127.0.0.1:6379> SETBIT a 13 1
(integer) 0
127.0.0.1:6379> SETBIT a 15 1
(integer) 0
127.0.0.1:6379> get a
"he"从上述示例可以得出,位图操作会自动对 key 进行扩容。
如果对应位的字节是不可以被打印的,那么 Redis 会以该字符的十六进制数来表示它,如下所示:
127.0.0.1:6379> SETBIT b 0 1
(integer) 0
127.0.0.1:6379> SETBIT b 1 1
(integer) 0
127.0.0.1:6379> get b
"\xc0"4.4 独立用户统计
1 使用set string和Bitmap对比
2 1亿用户,5千万独立(1亿用户量,约5千万人访问,统计活跃用户数量)
| 数据类型 | 每个userid占用空间 | 需要存储用户量 | 全部内存量 |
|---|---|---|---|
| set string | 32位(假设userid是整形,占32位) | 5千万 | 32位*5千万=200MB |
| bitmap | 1位 | 1亿 | 1位*1亿=12.5MB |
假设有10万独立用户,使用位图还是占用12.5mb,使用set需要32位*1万=4MB
4.5 总结
1 位图类型是string类型,最大512M
2 使用setbit时偏移量如果过大,会有较大消耗
3 位图不是绝对好用,需要合理使用
5 HyperLogLog 基数统计
5.1 介绍
HyperLoglog 是 Redis 重要的数据类型之一,它非常适用于海量数据的计算、统计,其特点是占用空间小,计算速度快。
HyperLoglog 采用了一种基数估计算法,因此,最终得到的结果会存在一定范围的误差(标准误差为 0.81%)。每个 HyperLogLog key 只占用 12 KB 内存,所以理论上可以存储大约2^64个值,而 set(集合)则是元素越多占用的内存就越多,两者形成了鲜明的对比 。
基于HyperLogLog算法:极小的空间完成独立数量统计,本质还是字符串。
5.2 基数定义
一个集合中不重复的元素个数就表示该集合的基数,比如集合 {1,2,3,1,2} ,它的基数集合为 {1,2,3} ,所以基数为 3。HyperLogLog 正是通过基数估计算法来统计输入元素的基数。
HyperLoglog 不会储存元素值本身,因此,它不能像 set 那样,可以返回具体的元素值。HyperLoglog 只记录元素的数量,并使用基数估计算法,快速地计算出集合的基数是多少。
5.3 场景应用
HyperLogLog 也有一些特定的使用场景,它最典型的应用场景就是统计网站用户月活量,或者网站页面的 UV(网站独立访客)数据等。
UV 与 PV(页面浏览量) 不同,UV 需要去重,同一个用户一天之内的多次访问只能计数一次。这就要求用户的每一次访问都要带上自身的用户 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
当一个网站拥有巨大的用户访问量时,我们可以使用 Redis 的 HyperLogLog 来统计网站的 UV (网站独立访客)数据,它提供的去重计数方案,虽说不精确,但 0.81% 的误差足以满足 UV 统计的需求。
5.4 常用命令
| 命令 | 说明 |
|---|---|
| PFADD key element [element ...] | 添加指定元素到 HyperLogLog key 中,可以同时添加多个。 |
| PFCOUNT key [key ...] | 返回指定 HyperLogLog key 的基数估算值(独立总数)。 |
| PFMERGE destkey sourcekey [sourcekey ...] | 将多个 HyperLogLog key 合并为一个 key。 |
命令演示:
pfadd uuids "uuid1" "uuid2" "uuid3" "uuid4" #向uuids中添加4个uuid
pfcount uuids #统计独立总数,返回4
pfadd uuids "uuid1" "uuid5" #重复元素不能添加成功,其实只把uuid5添加了
pfcount uuids #统计独立总数,返回5
pfadd uuids1 "uuid1" "uuid2" "uuid3" "uuid4"
pfadd uuids2 "uuid3" "uuid4" "uuid5" "uuid6"
pfmerge uuidsall uuids1 uuids2 #合并,去重
pfcount uuidsall #统计独立总数, 返回65.5 内存消耗&总结
百万级别独立用户统计,百万条数据只占15k
错误率 0.81%
无法取出单条数据,只能统计个数
6 Redis布隆过滤器
布隆过滤器(Bloom Filter)是 Redis 4.0 版本提供的新功能,它被作为插件加载到 Redis 服务器中,给 Redis 提供强大的去重功能。
相比于 Set 集合的去重功能而言,布隆过滤器在空间上能节省 90% 以上,但是它的不足之处是去重率大约在 99% 左右,也就是说有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。俗话说“鱼与熊掌不可兼得”,如果想要节省空间,就需要牺牲 1% 的误判率,而且这种误判率,在处理海量数据时,几乎可以忽略。
6.1 应用场景
布隆过滤器是 Redis 的高级功能,虽然这种结构的去重率并不完全精确,但和其他结构一样都有特定的应用场景,比如当处理海量数据时,就可以使用布隆过滤器实现去重。
下面举两个简单的例子:
1) 示例:
百度爬虫系统每天会面临海量的 URL 数据,我们希望它每次只爬取最新的页面,而对于没有更新过的页面则不爬取,因此爬虫系统必须对已经抓取过的 URL 去重,否则会严重影响执行效率。但是如果使用一个 set(集合)去装载这些 URL 地址,那么将造成资源空间的严重浪费。
2) 示例:
垃圾邮件过滤功能也采用了布隆过滤器。虽然在过滤的过程中,布隆过滤器会存在一定的误判,但比较于牺牲宝贵的性能和空间来说,这一点误判是微不足道的。
6.2 工作原理
布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。
布隆过滤器使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。
1) 工作流程-添加元素
布隆过滤器主要由位数组和一系列 hash 函数构成,其中位数组的初始状态都为 0。
下面对布隆过滤器工作流程做简单描述,如下图所示:

当使用布隆过滤器添加 key 时,会使用不同的 hash 函数对 key 存储的元素值进行哈希计算,从而会得到多个哈希值。根据哈希值计算出一个整数索引值,将该索引值与位数组长度做取余运算,最终得到一个位数组位置,并将该位置的值变为 1。每个 hash 函数都会计算出一个不同的位置,然后把数组中与之对应的位置变为 1。通过上述过程就完成了元素添加(add)操作。
2) 工作流程-判定元素是否存在
当我们需要判断一个元素是否存时,其流程如下:首先对给定元素再次执行哈希计算,得到与添加元素时相同的位数组位置,判断所得位置是否都为 1,如果其中有一个为 0,那么说明元素不存在,若都为 1,则说明元素有可能存在。
3) 为什么是可能“存在”
您可能会问,为什么是有可能存在?其实原因很简单,那些被置为 1 的位置也可能是由于其他元素的操作而改变的。比如,元素1 和 元素2,这两个元素同时将一个位置变为了 1(图1所示)。在这种情况下,我们就不能判定“元素 1”一定存在,这是布隆过滤器存在误判的根本原因。
6.3 安装与使用
在 Redis 4.0 版本之后,布隆过滤器才作为插件被正式使用。布隆过滤器需要单独安装,下面介绍安装 RedisBloom 的几种方法:
1) docker安装
docker 安装布隆过滤器是最简单、快捷的一种方式:
docker pull redislabs/rebloom:latest
docker run -id -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
docker exec -it redis-redisbloom /bin/bash
redis-cli
#测试是否安装成功
127.0.0.1:6379> bf.add name lqz2) 直接编译安装
如果您对 docker 不熟悉,也可以采用直接编译的方式来安装。
下载地址:
https://github.com/RedisBloom/RedisBloom
解压文件:
unzip RedisBloom-master.zip
进入目录:
cd RedisBloom-master
执行编译命令,生成redisbloom.so 文件:
make
拷贝至指定目录:
cp redisbloom.so /usr/local/redis/bin/redisbloom.so
在redis配置文件里加入以下配置:
loadmodule /usr/local/redis/bin/redisbloom.so
配置完成后重启redis服务:
/etc/init.d/redis-server restart
#测试是否安装成功
127.0.0.1:6379> bf.add name lqz6.4 常用命令汇总
| 命令 | 说明 |
|---|---|
| bf.add | 只能添加元素到布隆过滤器。 |
| bf.exists | 判断某个元素是否在于布隆过滤器中。 |
| bf.madd | 同时添加多个元素到布隆过滤器。 |
| bf.mexists | 同时判断多个元素是否存在于布隆过滤器中。 |
| bf.reserve | 以自定义的方式设置布隆过滤器参数值,共有 3 个参数分别是 key、error_rate(错误率)、initial_size(初始大小)。 |
1) 命令应用
127.0.0.1:6379> bf.add spider:url www.biancheng.net
(integer) 1
127.0.0.1:6379> bf.exists spider:url www.biancheng.net
(integer) 1
127.0.0.1:6379> bf.madd spider:url www.taobao.com www.123qq.com
1) (integer) 1
2) (integer) 1
127.0.0.1:6379> bf.mexists spider:url www.jd.com www.taobao.com
1) (integer) 0
2) (integer) 16.5 测试误判率
下面使用 Python 测试布隆过滤器的误判率,代码如下所示:
import redis
size=10000
conn = redis.Redis()
count = 0
for i in range(size):
# redis中没有的命令可以用execute_command, redis.set本质还是调用的execute_command
# 添加元素,key为userid,值为user0...user9999
conn.execute_command("bf.add", "userid", "user%d" % i)
# 判断元素是否存在,此处切记 i+1
res = conn.execute_command("bf.exists", "userid", "user%d" % (i + 1))
if res == 1:
print(i)
count += 1
# 求误判率,round()中的5表示保留的小数点位数
# round(number,num_digits) number:需要四舍五入的数 digits:需要小数点后保留的位数
print("size: {} ,error rate:{}%".format(size, round(count / size * 100, 5)))执行三次测试,size 从小到大。输出结果如下:
size: 1000 , error rate: 1.0%
size: 10000 , error rate: 1.25%
size: 100000 , error rate: 1.305%通过上述结果可以看出布隆过滤器的错误率为 1% 多点,当 size 越来越大时,布隆过滤器的错误率就会升高,那么有没有办法降低错误率呢?这就用到了布隆过滤器提供的bf.reserve方法。如果不使用该方法设置参数,那么布隆过滤器将按照默认参数进行设置,如下所示:
key #指定存储元素的键,若已经存在,则bf.reserve会报错
error_rate=0.01 #表示错误率
initial_size=100 #表示预计放入布隆过滤器中的元素数量当放入过滤器中的元素数量超过了 initial_size 值时,错误率 error_rate 就会升高。因此就需要设置一个较大 initial_size 值,避免因数量超出导致的错误率上升。
解决错误率过高的问题
错误率越低,所需要的空间也会越大,因此就需要我们尽可能精确的估算元素数量,避免空间的浪费。我们也要根据具体的业务来确定错误率的许可范围,对于不需要太精确的业务场景,错误率稍微设置大一点也可以。
注意:如果要使用自定义的布隆过滤器需要在 add 操作之前,使用 bf.reserve 命令显式地创建 key,格式如下:
import redis
size=10000
conn = redis.Redis()
count = 0
conn.execute_command("bf.reserve", "userid", 0.001, size) # 新增
for i in range(size):
conn.execute_command("bf.add", "userid", "user%d" % i)
res = conn.execute_command("bf.exists", "userid", "user%d" % (i + 1))
if res == 1:
print(i)
count += 1
print("size: {} ,error rate:{}%".format(size, round(count / size * 100, 5)))布隆过滤器相比于平时常用的的列表、散列、集合等数据结构,其占用空间更少、效率更高,但缺点就是返回的结果具有概率性,并不是很准确。在理论情况下,添加的元素越多,误报的可能性就越大。再者,存放于布隆过滤器中的元素不容易被删除,因为可能出现会误删其他元素情况。
7 GEO
在 Redis 3.2 版本中,新增了存储地理位置信息的功能,即 GEO(英文全称 geographic),它的底层通过 Redis 有序集合(zset)实现。不过 Redis GEO 并没有与 zset 共用一套的命令,而是拥有自己的一套命令。
Redis GEO 有很多应用场景,举一个简单的例子,你一定点过外卖,或者用过打车软件,在这种 APP上会显示“店家距离你有多少米”或者“司机师傅距离你有多远”,类似这种功能就可以使用 Redis GEO 实现。数据库中存放着商家所处的经纬度,你的位置则由手机定位获取,这样 APP 就计算出了最终的距离。再比如微信中附近的人、摇一摇、实时定位等功能都依赖地理位置实现。
7.1 介绍
GEO(地理信息定位):存储经纬度,计算两地距离,范围等
北京:116.28,39.55
天津:117.12,39.08
可以计算天津到北京的距离,天津周围50km的城市,外卖等
7.2 5个城市纬度
| 城市 | 经度 | 纬度 | 简称 |
|---|---|---|---|
| 北京 | 116.28 | 39.55 | beijing |
| 天津 | 117.12 | 39.08 | tianjin |
| 石家庄 | 114.29 | 38.02 | shijiazhuang |
| 唐山 | 118.01 | 39.38 | tangshan |
| 保定 | 115.29 | 38.51 | baoding |
7.3 常用命令
| 序号 | 命令 | 说明 |
|---|---|---|
| 1 | GEOADD | 将指定的地理空间位置(纬度、经度、名称)添加到指定的 key 中。 |
| 2 | GEOPOS | 从 key 里返回所有给定位置元素的位置(即经度和纬度) |
| 3 | GEODIST | 返回两个地理位置间的距离,如果两个位置之间的其中一个不存在, 那么命令返回空值。 |
| 4 | GEORADIUS | 根据给定地理位置坐标(经纬度)获取指定范围内的地理位置集合。 |
| 5 | GEORADIUSBYMEMBER | 根据给定地理位置(具体的位置元素)获取指定范围内的地理位置集合。 |
| 6 | GEOHASH | 获取一个或者多个的地理位置的 GEOHASH 值。 |
| 7 | ZREM | 通过有序集合的 zrem 命令实现对地理位置信息的删除。 |
1) GEOADD
将指定的地理空间位置(纬度、经度、名称)添加到指定的 key 中。语法格式如下:
GEOADD key longitude latitude member [longitude latitude member ...]
- longitude:位置地点所处的经度;
- latitude:位置地点所处的纬度;
- member:位置名称。
将给定的经纬度的位置名称(纬度、经度、名字)与 key 相对应,这些数据以有序集合的形式进行储存。GEOADD命令以标准的x,y形式接受参数, 所以用户必须先输入经度,然后再输入纬度。GEOADD命令能够记录的坐标数量是有限的,如果位置非常接近两极(南极/北极)区域,那么将无法被索引到。因此当您输入经纬度时,需要注意以下规则:
- 有效的经度介于 -180 度至 180 度之间。
- 有效的纬度介于 -85.05112878 度至 85.05112878 度之间。
示例演示如下:
# 添加城市地理位置
127.0.0.1:6379> geoadd cities:locations 116.20 39.56 beijing 117.12 39.08 tianjin 114.29 38.02 shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
# 查询城市地理位置
127.0.0.1:6379> GEOPOS cities:locations beijing tianjin
1) 1) "116.19999736547470093"
2) "39.56000019952067248"
2) 1) "117.12000042200088501"
2) "39.0800000535766543"2) GEODIST
该命令用于获取两个地理位置间的距离。返回值为双精度浮点数,其语法格式如下:
GEODIST key member1 member2 [unit]
参数 unit 是表示距离单位,取值如下所示:
- m 表示单位为米;
- km 表示单位为千米;
- mi 表示单位为英里;
- ft 表示单位为英尺。
注意:如果没有指出距离单位,那么默认取值为m。示例如下:
127.0.0.1:6379> GEODIST cities:locations beijing tianjin
"95483.0433"
127.0.0.1:6379> GEODIST cities:locations beijing tianjin km
"95.4830"
127.0.0.1:6379> GEODIST cities:locations beijing tianjin mi
"59.3306"注意:计算举例时存在 0.5% 左右的误差,这是由于 Redis GEO 把地球假设成了完美的球体。
3) GEORADIUS
以给定的经纬度为中心,计算出 key 包含的地理位置元素与中心的距离不超过给定最大距离的所有位置元素,并将其返回。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [store key][storedist key]
参数说明:
- WITHDIST :在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
- WITHCOORD :返回位置元素的经度和维度。
- WITHHASH :采用 GEOHASH 对位置元素进行编码,以 52 位有符号整数的形式返回有序集合的分值,该选项主要用于底层调试,实际作用不大。
- COUNT:指定返回位置元素的数量,在数据量非常大时,可以使用此参数限制元素的返回数量,从而加快计算速度。
- store key:将返回结果的地理位置信息保存到指定键。
- storedist key:将返回结果距离中心点的距离保存到指定键。
注意:该命令默认返回的是未排序的位置元素。通过 ASC 与 DESC 可让返回的位置元素以升序或者降序方式排列。
命令应用示例如下:
#添加几个地理位置元素
127.0.0.1:6379> GEOADD city 106.45 29.56 chongqing 120.33 36.06 qingdao 103.73 36.03 lanzhou
(integer) 3
#以首都的坐标为中心,计算各个城市距离首都的距离,最大范围设置为1500km
#同时返回距离,与位置元素的经纬度
127.0.0.1:6379> GEORADIUS city 116.41 39.91 1500 km WITHCOORD WITHDIST
1) 1) "chongqing"
2) "1465.5618"
3) 1) "106.4500012993812561"
2) "29.56000053864853072"
2) 1) "lanzhou"
2) "1191.2793"
3) 1) "103.72999995946884155"
2) "36.03000049919800318"
3) 1) "qingdao"
2) "548.9304"
3) 1) "120.3299984335899353"
2) "36.05999892411877994"4) GEORADIUSBYMEMBER
根据给定的地理位置坐标(即经纬度)获取指定范围内的位置元素集合。其语法格式如下:
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DES]
该命令与 GEORADIUS 命令相似,不过它选择的中心的是具体的位置元素,而非经纬度坐标。示例如下:
#以贵阳为中心,最大距离不超过900km
127.0.0.1:6379> GEORADIUSBYMEMBER city guiyang 900 km WITHCOORD WITHDIST
1) 1) "guiyang"
2) "0.0000"
3) 1) "106.70999854803085327"
2) "26.56000089385899798"
#只有重庆符合条件
2) 1) "chongqing"
2) "334.6529"
3) 1) "106.4500012993812561"
2) "29.56000053864853072"5) GEOHASH
返回一个或多个位置元素的哈希字符串,该字符串具有唯一 ID 标识,它与给定的位置元素一一对应。示例如下:
127.0.0.1:6379> GEOHASH city lanzhou beijing shanghai
1) "wq3ubrjcun0"
2) "wx49h1wm8n0"
3) "wtmsyqpuzd0"6) ZREM
用于删除指定的地理位置元素,示例如下:
127.0.0.1:6379> zrem city beijing tianjin
(integer) 2
