API的使用
1 通用命令
1.1 通用命令
1-keys 可以匹配正则
#打印出所有redis的name,for循环把所有的name全拿出来,时间复杂度是o(n),表示从头到尾循环一次,如果循环多次才能获取结果,时间复杂度更高
keys *
#打印出所有以he开头的name
keys he*
#打印出所有以he开头,第三个字母是h到l的范围
keys he[h-l]
#三位长度,以he开头,?表示任意一位
keys he?
# 注意:keys命令一般不在生产环境中使用,生产环境可能有上亿个name,循环一次不知道需要多少时间,时间复杂度为o(n),用scan命令2-dbsize
# 计算redis的name的总数
dbsize
# redis内置了计数器,插入删除值该计数器会更改,因此可以直接拿回数字,不用循环,所以可以在生产环境使用,时间复杂度是o(1)
# 时间复杂度是算法中的一种统计方式3-exists key 时间复杂度o(1)
# 判断redis的name在不在,存在返回1,不存在返回0
exists key
# 设置a
set a b
# 查看a是否存在
exists a
(integer) 14-del key 时间复杂度o(1)
# 删除成功返回1,key不存在返回0
del key5-expire key seconds 时间复杂度o(1)
# 给redis的name设置过期时间
expire key seconds
# 设置 3s过期
expire name 3
# 在name设置过期时间的情况下,查看name还有多长时间过期,应用于查看vip过期时间
# 当name没有设置过期时间,表示是永久有效时,TTL 命令返回 -1;当键过期或者被删除时,TTL 命令返回 -2。
ttl name
# 去掉name的过期时间
persist name6-type key 时间复杂度o(1)
# 查看name类型,返回string
type name7-dump key 时间复杂度o(1)
# 用于将redis的name对应的值做序列化处理
dump key
127.0.0.1:6379> SET num 12
OK
127.0.0.1:6379> DUMP num
"\x00\xc0\x0c\t\x00\xec\xd8\xa9\x9d\b\x82\xdfd"8-random key
# 随机获取一个redis的name,不会删除name,应用于抽奖
random key9-SCAN cursor
SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 否则将无法继续跌代。如果新游标返回 0 则表示迭代结束。
# SCAN 命令的语法格式如下:
SCAN cursor [MATCH pattern] [COUNT count]
参数说明:
cursor :指定游标,从 0 开始新的迭代。
pattern:指定匹配的模式。
count:返回多少个元素,默认值为 10 。SCAN 命令可以迭代数据库中的所有键,如果想针对特定的数据类型迭代,那么命令自然也要做相应的变化。如下所示:
SSCAN 命令用于迭代集合键中的元素。
ZSCAN 命令用于迭代有序集合中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
10-其他
info # 查看计算机信息,内存,cpu,主从相关
client list # 查看正在连接的会话,应用于自动化运维项目,项目远程连接redis,用subprocess模块执行外部命令redis-cli -a 123456 client list拿到结果
# 前端可以监控redis,查看有哪些客户端正在连接redis服务
client kill ip:端口 # 把链接的客户端干掉,让客户端强行下线
flushall # 清空所有数据库
flushdb # 只清空当前库
select 数字 # 选择某个库,总共16个库
monitor # 输入命令后夯住,一直连在这儿,只要有操作该redis,就记录操作日志(用来做日志审计)1.2 数据结构和内部编码

1.3 单线程架构
1.3.1 单线程架构
一个瞬间只会执行一条命令
1.3.2 单线程为什么这么快
1 纯内存
2 IO多路复用技术 (epoll机制),自身实现了事件处理,不在网络io上浪费过多时间
3 避免线程间切换和竞态消耗
1.3.3 注意
1 一次只运行一条命令
2 拒绝长慢命令,时间复杂o(n)的命令
-keys,flushall, flushdb, 慢的lua脚本,mutil/exec,operate,big value
3 其实不是完全单线程(做持久化是另外的线程)
-fysnc file descriptor
-close file descriptor
2 字符串类型
2.1 字符串键值结构
key value
hello world string类型,可以很复杂,如json格式字符串
counter 1 数字类型
bits 10101010 二进制(位图)
#字符串value不能大于512m,一般建议100k以内
#用于缓存,计数器,分布式锁...2.2 常用命令
###1---基本使用get,set,del
set name lqz #时间复杂度 o(1)
get name #时间复杂度 o(1)
del name #时间复杂度 o(1)
###2---其他使用incr,decr,incrby,decrby
incr age #对age这个key的value值自增1
decr age #对age这个key的value值自减1
incrby age 10 #对age这个key的value值增加10
decrby age 10 #对age这个key的value值减10
#统计网站访问量(单线程无竞争,天然适合做计数器)
#缓存mysql的信息(json格式)
#分布式id生成(多个机器同时并发着生成,不会重复)
比如3台机器生成3个订单号,用当前时间肯定重复,用mysql自增效率低,用redis 当前时间+自增,因为是单线程,自增不会乱
###3---set,setnx,setxx
set name lqz #不管key是否存在,都设置
setnx name lqz #key不存在时才设置(新增操作)
set name lqz nx #同上
set name lqz xx #key存在,才设置(更新操作)
###4---mget mset
mget key1 key2 key3 #批量获取key1,key2.。。时间复杂度o(n)
mset key1 value1 key2 value2 key3 value3 #批量设置时间复杂度o(n)
#n次get和mget的区别
#n次get时间=n次执行命令时间+n次网络时间
#mget时间=1次网络时间+n次执行命令时间
###5---其他:getset,append,strlen
getset name lqznb #设置新值并返回旧值 时间复杂度o(1)
append name 666 #将value追加到旧的value 时间复杂度o(1)
strlen name #计算字符串长度(一个汉字3个字节) 时间复杂度o(1)
###6---其他:incrybyfloat,getrange,setrange
increbyfloat age 3.5 #为age自增3.5,传负值表示自减 时间复杂度o(1)
getrange key start end #获取字符串制定下标所有的值 时间复杂度o(1)
setrange key index value #从指定index开始设置value值 时间复杂度o(1)
3 哈希类型
Redis hash(哈希散列)是由字符类型的 field(字段)和 value 组成的哈希映射表结构(也称散列表),它非常类似于表格结构。在 hash 类型中,field 与 value 一一对应,且不允许重复。
Redis hash 特别适合于存储对象。一个 filed/value 可以看做是表格中一条数据记录;而一个 key 可以对应多条数据。如下图结构:
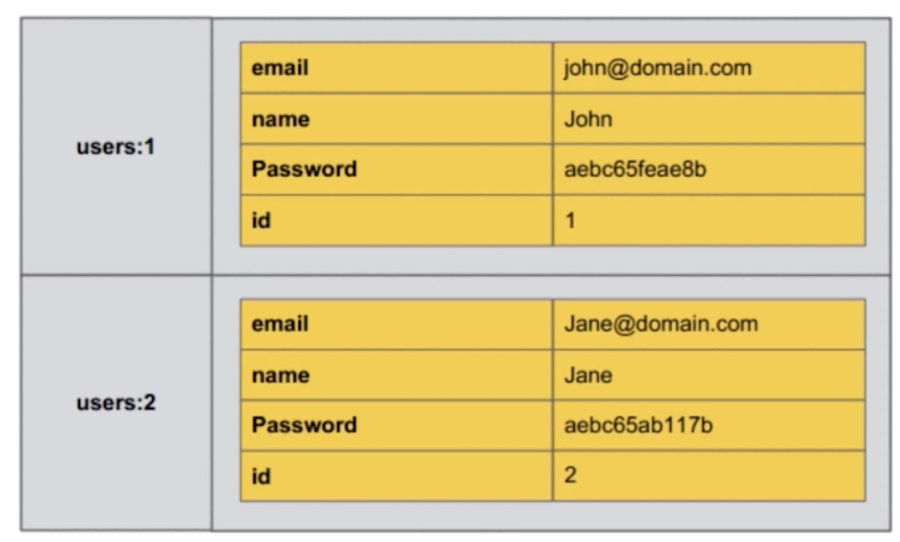
命令实例演示:
# 以user为key,设置 id+序号为字段,name+名字为值
127.0.0.1:6379> HMSET user id:1 name:Cao id:2 name:Zhao
OK
# 查询 user 这个key下所有的数据,并以字符串的形式将值返回
127.0.0.1:6379> HGETALL user
1) "id:1"
2) "name:Cao"
3) "id:2"
4) "name:Zhao"注意:当我们对 value 进行查询时,这个值只能以字符串的形式返回。
一个 hash 类型的 key 最多可以存储 2^32-1(约 40 亿个)字段/值。同时 Redis hash 会为这个 key 额外储存一些附加的管理信息,比如这个键的类型、最后一次访问这个键的时间等,所以 hash 键越来越多时,Redis 耗费在管理信息方面的内存就越多。当 hash 类型移除最后一个元素后,该存储结构就会被自动删除,其占用内存也会被系统回收。
3.1 重要api
###1---hget,hset,hdel
hget key field #获取hash key对应的field的value 时间复杂度为 o(1)
hset key field value #设置hash key对应的field的value值 时间复杂度为 o(1)
hdel key field #删除hash key对应的field的值 时间复杂度为 o(1)
#测试 以user:1:info作为redis的name,即hash key,见名知意且不重复
hset user:1:info age 23
hget user:1:info ag
hset user:1:info name lqz
hgetall user:1:info
hdel user:1:info age
###2---hexists,hlen
hexists key field #判断hash key 是否存在field 时间复杂度为 o(1)
hlen key #获取hash key field的数量 时间复杂度为 o(1)
hexists user:1:info name
hlen user:1:info #返回数量
###3---hmget,hmset 用这种命令前,评估下数据量大小,如果太大,时间复杂度是o(n),一旦执行,因为是单线程,其他所有命令都要等待
hmget key field1 field2 ...fieldN #批量获取hash key 的一批field对应的值 时间复杂度是o(n)
hmset key field1 value1 field2 value2 #批量设置hash key的一批field value 时间复杂度是o(n)
###4--hgetall,hvals,hkeys
hgetall key #返回hash key 对应的所有field和value 时间复杂度是o(n)
hvals key #返回hash key 对应的所有field的value 时间复杂度是o(n)
hkeys key #返回hash key 对应的所有field 时间复杂度是o(n)
##其他操作 hsetnx,hincrby,hincrbyfloat
hsetnx key field value #设置hash key对应field的value(如果field已存在,则失败),时间复杂度o(1)
hincrby key field intCounter #hash key 对应的field的value自增intCounter 时间复杂度o(1)
hincrbyfloat key field floatCounter #hincrby 浮点数自增 时间复杂度o(1)
# 补充:
#1 小心使用hgetall,先if判断数据量大小hlen user:1:info ,如大于多少就不用,采用分批取值
#2 计算网站每个用户主页的访问量,注意不是统计整个网站访问量,是统计每个用户主页访问量
hincrby user_info_pagecount user:1:info count 统一存放到公共的hash key,field是每个用户,value是统计量
#3 缓存mysql的信息,直接设置hash格式,转成json格式用字符串存取更方便3.2 缓存三种方案
直接json格式字符串
每个字段一个key
使用hash操作
4 列表类型
Redis list(列表)相当于 Java 语言中的 LinkedList 结构,是一个链表而非数组,其插入、删除元素的时间复杂度为 O(1),但是查询速度欠佳,时间复杂度为 O(n)。
当向列表中添加元素值时,首先需要给这个列表指定一个 key 键,然后使用相应的命令,从列表的左侧(头部)或者右侧(尾部)来添加元素,这些元素会以添加时的顺序排列。一个列表最多可以包含 2^32 - 1 个元素(约 40 亿个元素),当列表弹出最后一个元素时,该结构会被自动删除。
4.1 列表特点
有序队列,可以从左侧添加,右侧添加,可以重复,可以从左右两边弹出
4.2 API操作
#####1 插入操作
#rpush 从右侧插入
rpush key value1 value2 ...valueN #时间复杂度为o(1~n),放一个时间复杂度为1,放n个为n
#lpush 从左侧插入
#linsert
linsert key before|after value newValue #从元素value的前或后插入newValue 时间复杂度o(n) ,需要遍历列表
linsert listkey before b java
linsert listkey after b php
#####2 删除操作
lpop key #从列表左侧弹出一个item 时间复杂度o(1)
rpop key #从列表右侧弹出一个item 时间复杂度o(1)
lrem key count value #在name对应的list中删除指定的值, 可能有重复的value,count用来控制删除重复的个数 时间复杂度o(n)
1 count>0 从左到右,删除最多count个value相等的项
2 count<0 从右向左,删除最多Math.abs(count)个value相等的项
3 count=0 删除所有value相等的项
lrem listkey 0 a #删除列表中所有值a
lrem listkey -1 c #从右向左删除1个c
ltrim key start end #按照索引范围修剪列表 o(n)
ltrim listkey 1 4 #只保留下标1--4的元素,顾头顾尾
#####3 查询操作
lrange key start end #分片获取数据,包含end获取列表指定索引范围所有item o(n)
lrange listkey 0 2
lrange listkey 1 -1 #获取第一个位置到倒数第一个位置的元素
lindex key index #获取列表指定索引的item o(n)
lindex listkey 0
lindex listkey -1
llen key #获取列表长度
#####4 修改操作
lset listkey index newValue #设置列表指定索引值为newValue o(n)
lset listkey 2 ppp #把第二个位置设为ppp
#####5 其他操作
blpop key timeout #lpop的阻塞版,timeout是阻塞超时时间,timeout=0为永远阻塞 o(1)
brpop key timeout #rpop的阻塞版,timeout是阻塞超时时间,timeout=0为永远阻塞 o(1)4.3 队列和栈实现
Redis 列表可以被当做栈、队列来使用,如果列表的元素是“右进左出”那就是队列模型;如果元素是“右进右出”那就是栈模型,示例如下:
1) 右进左出(左进右出同理) FIFO
127.0.0.1:6379> Rpush book c python java
(integer) 3
127.0.0.1:6379> lpop book
"c"
127.0.0.1:6379> lpop book
"python"
127.0.0.1:6379> lpop book
"java"
127.0.0.1:6379> lpop book
(nil)2) 右进右出(左进左出同理) FILO
127.0.0.1:6379> RPUSH book c python java
(integer) 3
127.0.0.1:6379> rpop book
"java"
127.0.0.1:6379> rpop book
"python"
127.0.0.1:6379> rpop book
"c"
127.0.0.1:6379> rpop book
(nil)3) 消息队列
利用blpop,brpop的阻塞,用作异步队列。使用流程大致如下:一个线程将需要延时处理的任务序列化成字符串,并“塞”进 Redis 列表中,而另外一个线程则以轮询的方式从该列表中读取“任务”。
lpush+brpop
4) 固定大小的列表
lpush+ltrim
4.4 实战
实现timeLine功能,时间轴,应用如下:
1、微博关注的人,按时间轴排列,在列表中放入关注人的微博的即可
2、朋友圈发一个状态,把状态id放到列表里,拿的时候就是根据列表顺序排序
5 集合类型
Redis set (集合)遵循无序排列的规则,集合中的每一个成员(也就是元素,叫法不同而已)都是字符串类型,并且不可重复。Redis set 是通过哈希映射表实现的,所以它的添加、删除、查找操作的时间复杂度为 O(1)。集合中最多可容纳 2^32 - 1 个成员(40 多亿个)。
5.1 特点
无序,无重复,集合间操作(交叉并补)
5.2 API操作
sadd key element #向集合key添加element(如果element存在,添加失败) o(1)
srem key element #从集合中的element移除掉 o(1)
scard key #计算集合大小
sismember key element #判断element是否在集合中
srandmember key count #从集合中随机取出count个元素,不会破坏集合中的元素,用于抽奖,把参与抽奖的用户id放入集合,随机从集合中取几个
spop key #从集合中随机弹出一个元素,弹出去就不在集合中了,用于连续抽出几等奖
smembers key #获取集合中所有元素 ,无序,小心使用,会阻塞住
sdiff user:1:follow user:2:follow #计算user:1:follow和user:2:follow的差集
sinter user:1:follow user:2:follow #计算user:1:follow和user:2:follow的交集
sunion user:1:follow user:2:follow #计算user:1:follow和user:2:follow的并集
sdiffstore sinterstore suionstore + destkey user:1 user:2 #将user:1 user:2 求差集,交集,并集,结果保存在destkey集合中5.3 实战
抽奖系统 :通过spop来弹出用户的id,活动取消,直接删除
点赞,点踩,喜欢等,用户如果点了赞,就把用户id放到该条记录的集合中(去重)
标签:给用户/文章等添加标签,sadd user:1:tags 标签1 标签2 标签3
给标签添加用户,关注该标签的人有哪些,做个性化推荐
共同好友:集合间的操作
5.4 总结
sadd:可以做标签相关
spop/srandmember:可以做随机数相关
sadd/sinter:社交相关
6 有序集合类型
顾名思义,Redis zset(有序集合)中的成员是有序排列的,它和 set 集合的相同之处在于,集合中的每一个成员都是字符串类型,并且不允许重复;而它们最大区别是,有序集合是有序的,set 是无序的,这是因为有序集合中每个成员都会关联一个 double(双精度浮点数)类型的 score (分数值),Redis 正是通过 score 实现了对集合成员的排序。
zset 是 Redis 常用数据类型之一,它适用于排行榜类型的业务场景,比如 QQ 音乐排行榜、用户贡献榜等。在音乐排行榜单中,我们可以将歌曲的点击次数作为 score 值,把歌曲的名字作为 value 值,通过对 score 排序就可以得出歌曲“热度榜单”。
Redis 使用以下命令创建一个有序集合:
127.0.0.1:6379> ZADD key score member [score member ...] key:指定一个键名;
score:分数值,用来描述 member,它是实现排序的关键;
member:要添加的成员(元素)。
当 key 不存在时,将会创建一个新的有序集合,并把分数/成员(score/member)添加到有序集合中;当 key 存在时,但 key 并非 zset 类型,此时就不能完成添加成员的操作,同时会返回一个错误提示。
注意:在有序集合中,成员是唯一存在的,但是分数(score)却可以重复。有序集合的最大的成员数为 2^32 - 1 (大约 40 多亿个)。
6.1 特点
#有一个分值字段,来保证顺序
key score value
user:ranking 1 lqz
user:ranking 99 lqz2
user:ranking 88 lqz3
#集合有序集合
集合:无重复元素,无序,element
有序集合:无重复元素,有序,element+score
#列表和有序集合
列表:可以重复,有序,element
有序集合:无重复元素,有序,element+score6.2 API使用
zadd key score element #用于将一个或多个成员添加到有序集合中,score可以重复,element o(logN)重复则更新已存在成员的score值
zrem key element #删除元素,可以多个同时删除 o(1)
zscore key element #获取元素的分数 o(1)
zcard key #获取有序集合中成员的数量 o(1)
zincrby key increScore element #增加或减少元素的分数,increScore为负数则减少 o(1)
zrank key element #返回element元素的排名(从小到大排,第一位是0)
zrange key 0 -1 #返回有序集合中指定索引区间内的成员,不带分数 o(log(n)+m) n是元素个数,m是要获取的值
zrange key 0 -1 withscores #返回有序集合中指定索引区间内的成员,带分数
zrangebyscore key minScore maxScore #返回指定分数范围内的升序元素 o(log(n)+m) n是元素个数,m是要获取的值
zrangebyscore key 90 210 withscores #获取90分到210分的元素,withscores带分数
zcount key minScore maxScore #返回有序集合内在指定分数范围内的个数 o(log(n)+m)
zremrangebyrank key start end #删除指定排名内的升序元素 o(log(n)+m)
zremrangebyrank key 1 2 #删除升序排名中1到2的元素
zremrangebyscore key minScore maxScore #删除指定分数内的升序元素 o(log(n)+m)
zremrangebyscore key 90 210 #删除分数90到210之间的元素6.3 实战
排行榜:音乐排行榜,销售榜,关注榜,游戏排行榜
6.4 其他操作
zrevrank #从高到低排序
zrevrange #从高到低排序取一定范围
zrevrangebyscore #返回指定分数范围内的降序元素
zinterstore #对两个有序集合交集
zunionstore #对两个有序集合求并集6.5 总结
| 操作类型 | 命令 |
|---|---|
| 基本操作 | zadd/ zrem/ zcard/ zincrby/ zscore |
| 范围操作 | zrange/ zrangebyscore/ zcount/ zremrangebyrank |
| 集合操作 | zunionstore/ zinterstore |
