一、爬虫是什么
1、浏览器获取数据的方式
浏览器提交请求->下载网页代码->解析/渲染成页面
2、爬虫获取数据的方式
模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
二、爬虫的基本流程
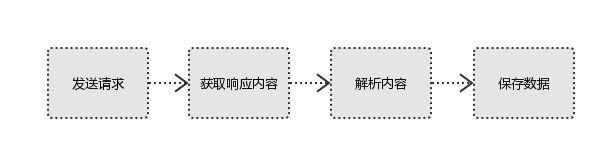
1、发起请求
模拟浏览器发送请求(requests,selenium),Request包含请求地址(浏览器调试/抓包工具 分析请求地址),请求头,请求体,请求方法
2、拿到响应
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等(bs4或xpath解析)
解析json数据:json模块
解析二进制数据:以b的方式写入文件
加密的未知格式:需要解密
4、保存数据
文件或数据库:redis, MySQL, Mongodb(json格式数据)
利用多线程,多进程,协程,scrapy框架处理性能
只针对与python语言的cpython解释器(GIL:同一时刻只能由一个线程在执行),其他语言都是直接开多线程(很少开进程)
python由于GIL锁的存在,如果需要cpu计算,开多线程没有用,只有开多进程(每个进程起一个cpython解释器),但io密集型可以利用多线程,因为遇到io线程就切换了
-io密集型:用线程
-计算密集型:用进程
三、请求与响应
了解http协议:
http://www.cnblogs.com/linhaifeng/articles/8243379.html
http://www.cnblogs.com/linhaifeng/p/6266327.html
https://juejin.im/post/6857287743966281736
1、请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内,可用浏览器查看,存放于form data内;get请求的参数直接放在url后
2、请求url
url全称统一资源定位符,如一个网页文档,一张图片,一个视频等都可以用url唯一来确定
url编码:https://www.baidu.com/s?wd=图片,“图片”会被编码
解决中文参数编码问题:
from urllib.parse import quote
quote("图片", "utf-8")
3、请求头
User-agent:请求头中如果没有user-agent客户端类型,服务端可能将你当做一个非法用户
referer:大型网站通常都会根据该参数判断请求的来源,也用做图片防盗链
cookie: 用来保存登录信息
Connection: Keep-Alive 浏览器1.1版本后,多次请求用一个socket链接,不然每次请求都要三次握手、四次挥手,消耗服务器性能
自定制字段:靠猜
4、请求体
如果是get方式,请求体没有内容
如果是post方式,编码格式:json,urlencoded,formdata
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post(分析url,formdata),正确登录后页面通常会跳转,无法捕捉到post
3、网页的加载过程:加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
----------------------------------------------------------------------
响应首行(状态码),响应头:(cookie,响应的编码格式), 响应体(html格式,前后端分离返回json格式,还需要js把数据渲染到页面)
preview就是网页源代码,最主要的部分,包含了请求资源的内容,如网页html、图片、二进制数据等
四、总结
1、总结爬虫流程:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests,selenium
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongodb,Redis
3、爬虫常用框架:
scrapy
补充:爬虫协议(txt,上面写了哪些路径允许你爬还是不允许你爬)
www.baidu.com/robots.txt
五、反爬措施
1 user-agent 浏览器识别
2 referer 图片防盗链,运用于本次访问必须来自上次的url
3 cookie 登录没登录都需要带
4 频率限制
5 js加密
6 css加密
7 验证码
8 图片懒加载


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人