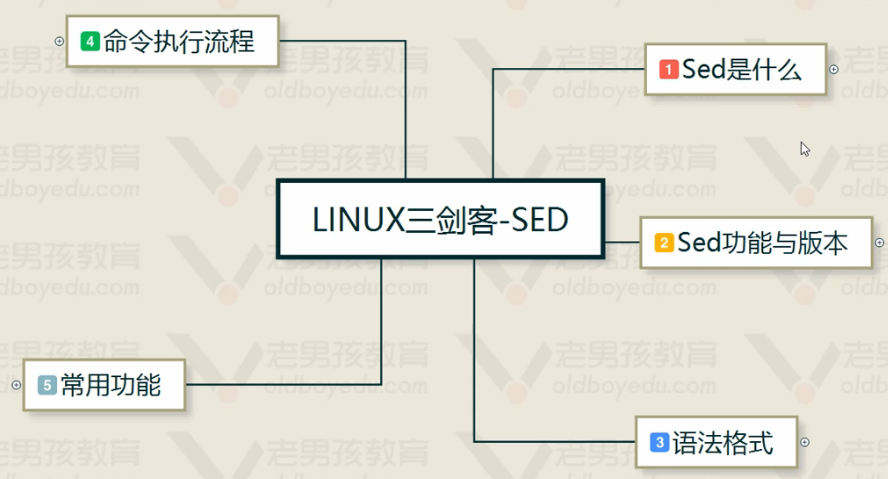
四.awk、sde深度讲解
###sed###






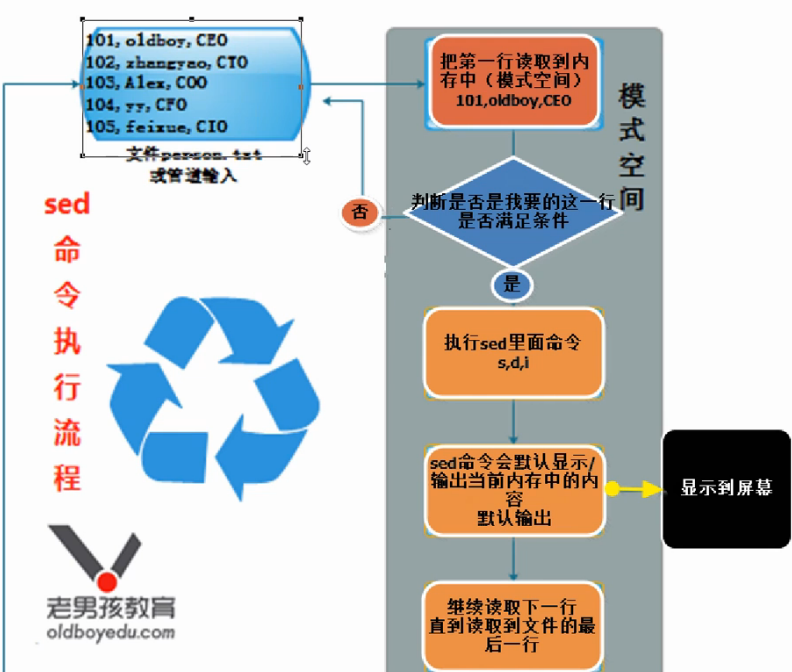


查询

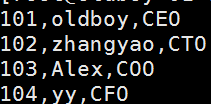
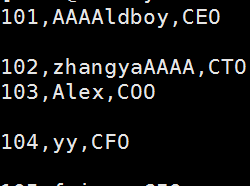
1创建测试文件
cat>person.txt<<EOF
> 101,oldboy,CEO
> 102,zhangyao,CTO
> 103,Alex,COO
> 104,yy,CFO
> 105,feixue.CIO
> EOF
2查询单行文本

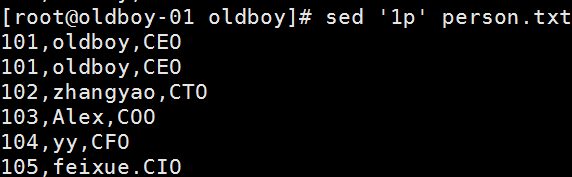


2连续查询多行文本

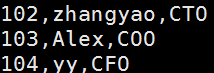
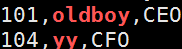
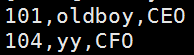
3显示出文件包含oldboy的行到包含104的行

 等于grep 'oldboy' person.txt
等于grep 'oldboy' person.txt

^104以104开头更加精确
4过滤多个字符串

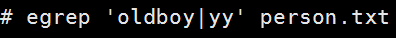

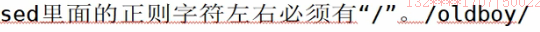


7查询指定多行 使用;分号

增加

1增加单行文本

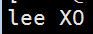
#sed '3a 103.5,Lee,UFO' person.txt
101,oldboy,CEO
102,zhangyao,CTO
103,Alex,COO
103.5,Lee,UFO
104,yy,CFO
105,feixue.CIO
# sed '3i 103.5,Lee,UFO' person.txt
101,oldboy,CEO
102,zhangyao,CTO
103.5,Lee,UFO
103,Alex,COO
104,yy,CFO
105,feixue.CIO
2增加多行文本
# sed '$a new,new,new,' person.txt
$a 最后一行
101,oldboy,CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue.CIO
new,new,new,
# sed '2a 106,xiaoyu,CXO\n107\n108\n109' person.txt
101,oldboy,CEO
102,zhangyao,CTO
106,xiaoyu,CXO
107
108
109
103,Alex,COO
104,yy,CFO
105,feixue.CIO
一般追加到行位用的cat>person.txt<<EOF
追加到某一行就用sed i a
删除
sed '/^$/d' person.txt
删除空行
sed -n '/^$/!p' person.txt
/^$/p显示空行加!排除取反
sed '$d' person.txt
删除最后一行
sed '$!d' person.txt
删除不是最后一行
替换
文本替换

测试

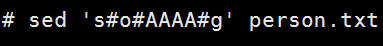

变量替换

这里要用双引号 单引号不执行

# x=oldboy
# y=oldgirl
# sed "s#$x#$y#g" person.txt
101,oldgirl,CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue.CIO
反向引用

扩展

回顾

###awk####

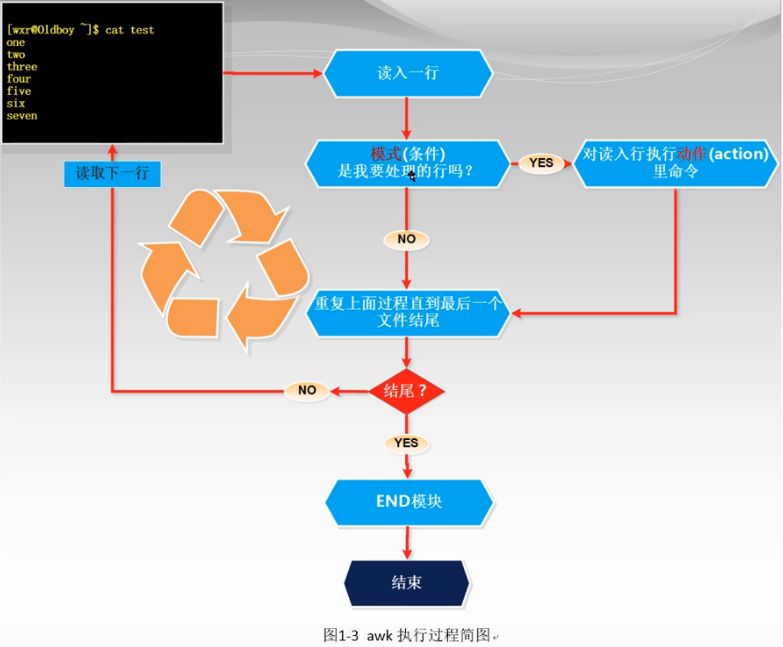
执行过程 按照下面的命令来理解


主要讲不同的模式或者说是条件
创建环境
# mkdir -p /server/files
#cat>>/server/files/reg.txt<<EOF
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :205:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :205:100:175
EOF
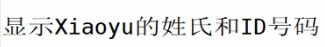

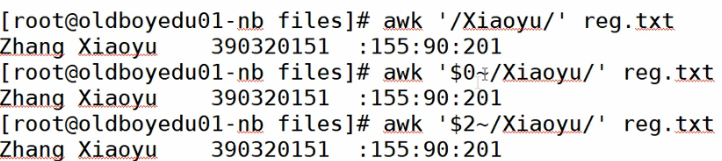
# awk '/Xiaoyu/' reg.txt 过滤出来
Zhang Xiaoyu 390320151 :155:90:201
# awk '/Xiaoyu/{print $1,$2,$3}' reg.txt 花括号前面就是条件或者说模式
Zhang Xiaoyu 390320151
精确一点就是
# awk '$2~/Xiaoyu/{print $1,$2,$3}' reg.txt
$2~/Xiaoyu/第二列包含xiaoyu
$0~ ===/Xiaoyu/
# awk '$3~/^41/' reg.txt

# awk '$3~/^41/{print $1,$2,$3}' reg.txt

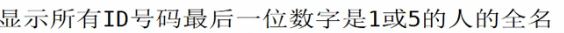
# awk '$3~/[15]$/' reg.txt
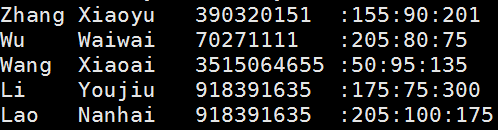
# awk '$3~/[15]$/{print $1,$2}' reg.txt


$0 就是所有列
# awk '{gsub(/:/,"$",$4);print}' reg.txt
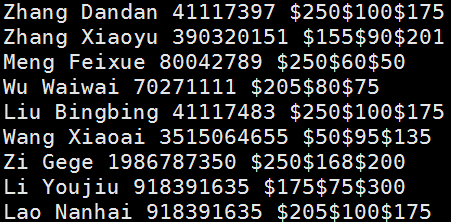

特殊模式BEGIN和GND




i每加1就显示出来
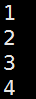
。。


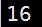
END 显示最后的结果

awk数组统计
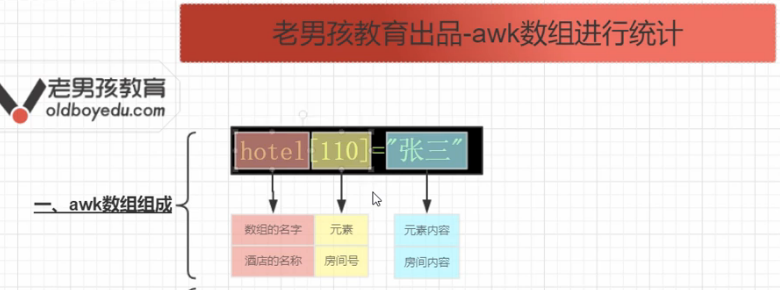
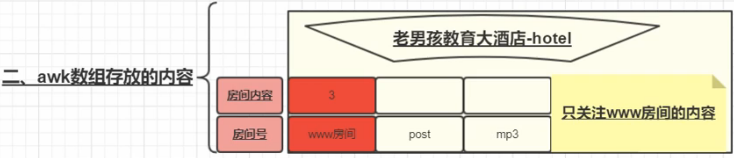
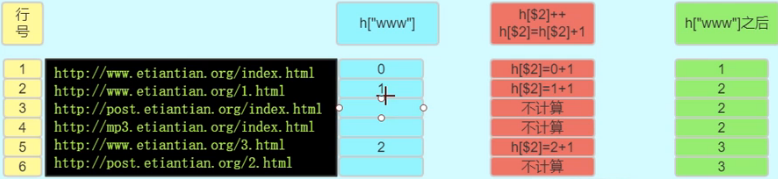



############

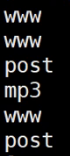
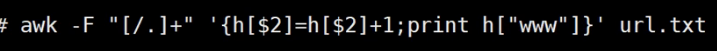
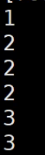
最终计算


或者用awk中for循环for (pol in h)==pol随便写就是个变量
in就是去哪里 awk循环里h这个位置是数组的名字
会自动打开h成为数组名字

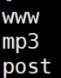


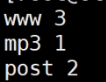
以后可以把它当做一个公式用$2用那一列自己选比如说第一列是ip地址

作业

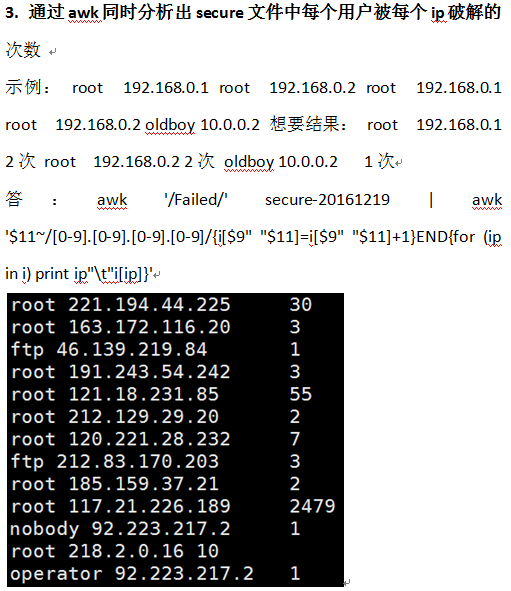
awk '/Failed/' secure-20161219 |awk '$11~/[0-9].[0-9].[0-9].[0-9]/{i[$9" "$11]=i[$9" "$11]+1}END{for(ip in i) print ip"\t"i[ip]}'




 浙公网安备 33010602011771号
浙公网安备 33010602011771号