

CNN 卷积神经网络
个人学习所用,内容来源于网络,侵权删
1. CNN定义
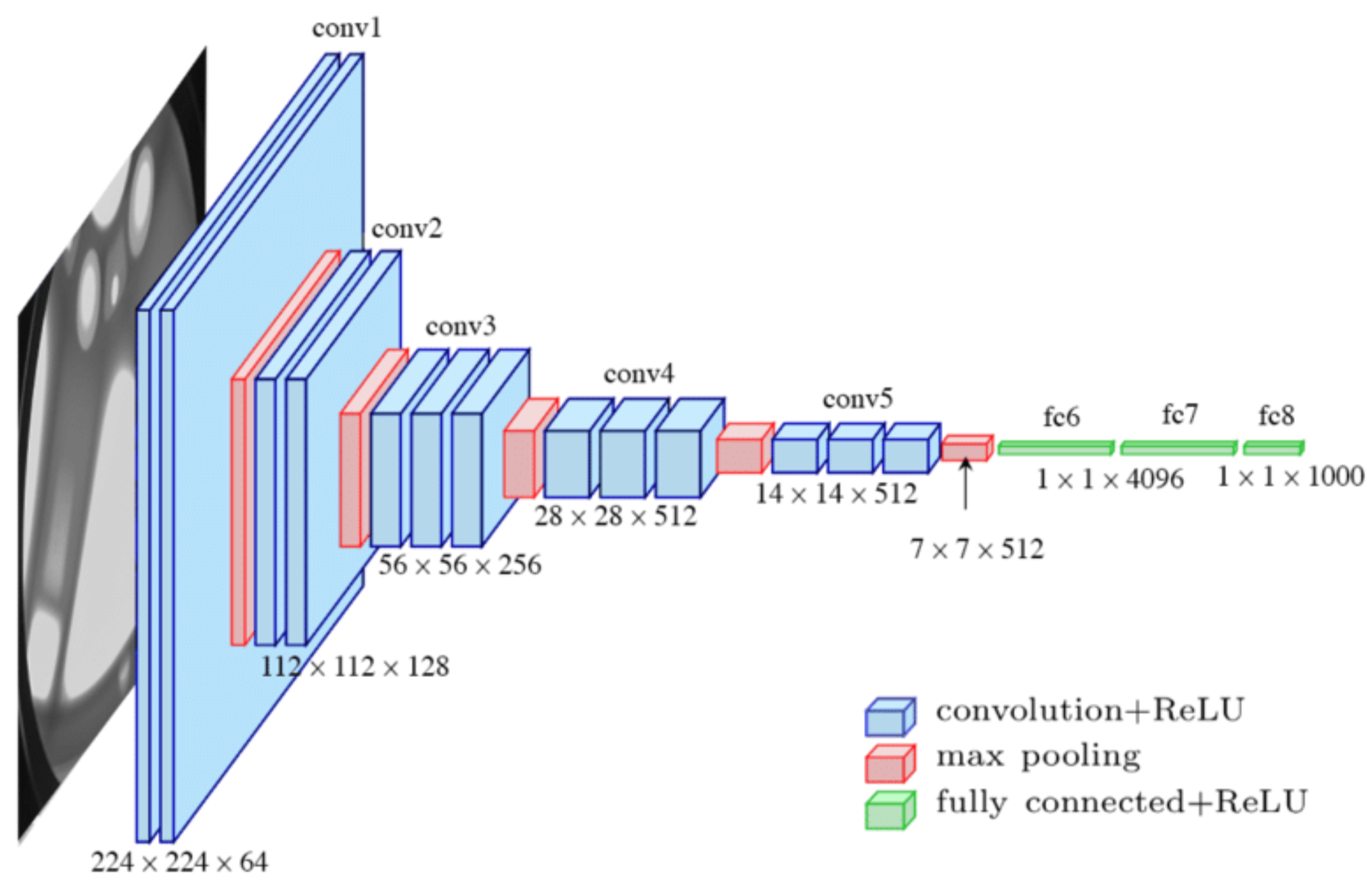
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一,擅长处理图像特别是图像识别等相关机器学习问题。
2. 卷积
CNN的核心即为卷积运算,其相当于图像处理中的滤波器运算。对于一个
卷积核
卷积过程如下所示,
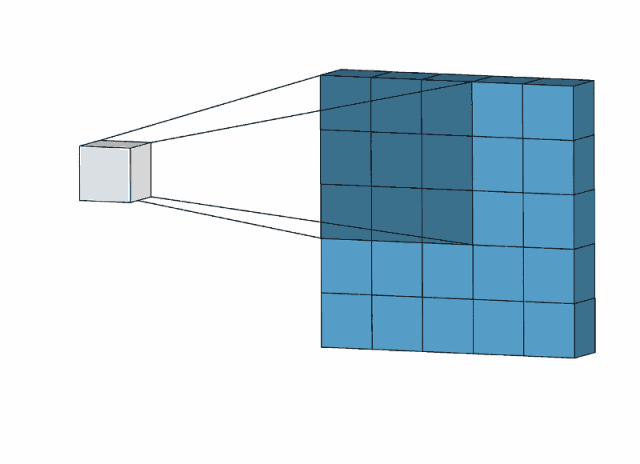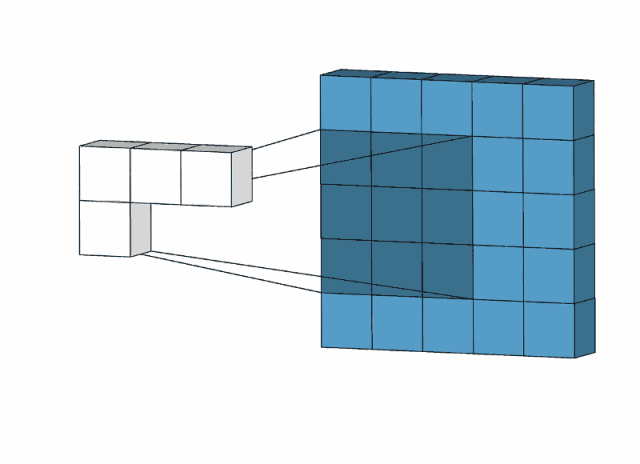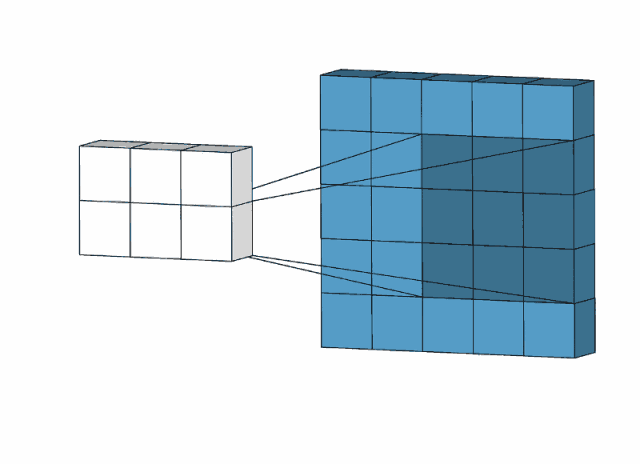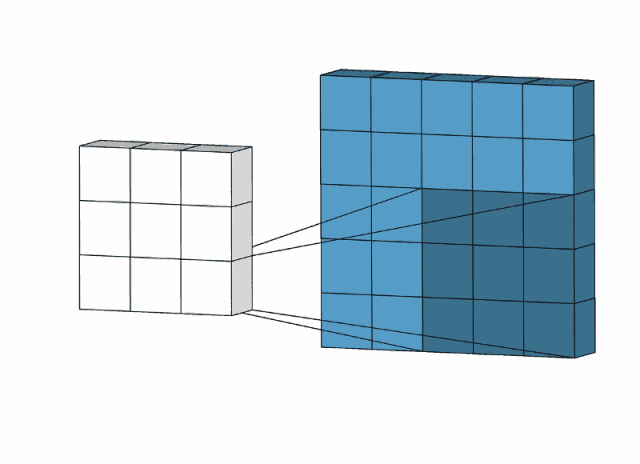
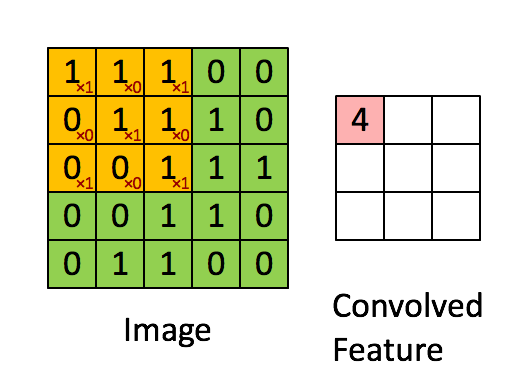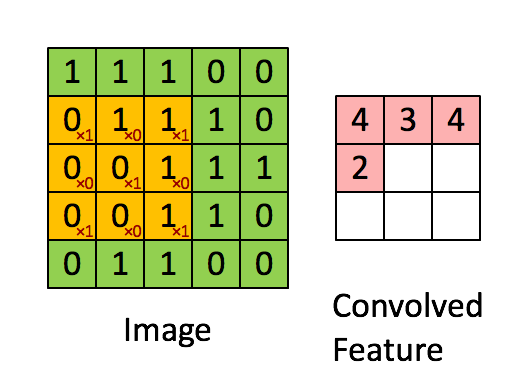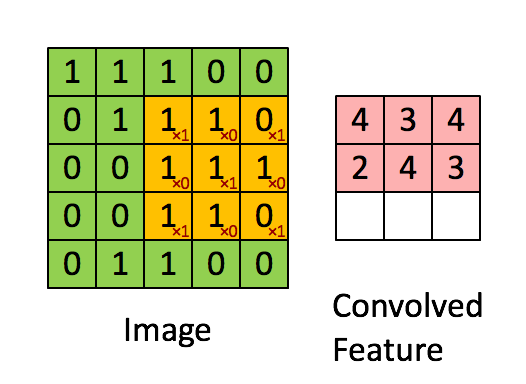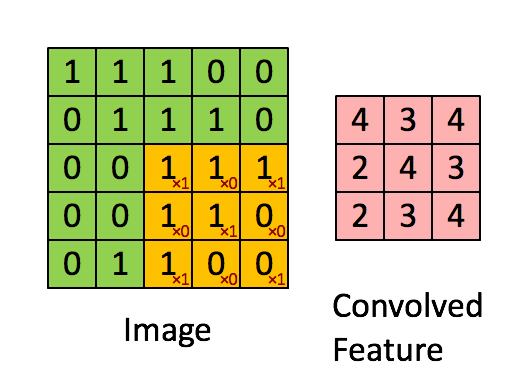
对于一个大小为
3. 步长
卷积核每计算一次都需要滑动一段距离,以覆盖下一部分像素,这个滑动的距离就是步长(stride),经过步长
其中
stride = 1 表示卷积核滑过每一个相距是 1 的像素,是最基本的单步滑动,作为标准卷积模式。Stride 是 2 表示卷积核的移动步长是 2,跳过相邻像素,输出图像缩小为原来的 1/2。Stride 是 3 表示卷积核的移动步长是 3,跳过 2 个相邻像素,图像缩小为原来的 1/3,以此类推。。。
详细计算过程可参考如下链接:
CNN中卷积层的计算细节
4. 填充(padding)
在标准的卷积过程中,存在两个问题:
- 每次卷积运算后,图像就会缩小尺寸。在经历多次运算后,图像最终会失去其本来的形状,变为
- 对于图像边缘的像素,只被一个输出使用,但图像中间的像素,则被多个输出使用。这意味着卷积过程丢掉了图像边缘位置的许多信息。
对于这个问题,可以采用额外的 “假” 像素(通常值为0,因此经常使用的术语 零填充 )填充边缘。这样,在滑动时的卷积核可以允许原始边缘像素位于其中心,同时延伸到边缘之外的假像素。假设填充的像素大小为
至于是否选择填充像素,通常有两个选择,分别叫做 Valid 卷积和 Same 卷积。
- Valid 卷积意味着不填充,即图像会通过卷积并逐渐缩小,输出的图像尺寸即为上述公式:
- Same卷积意味填充,输出图像的尺寸与输入图像的尺寸相同。
根据上述尺寸的计算公式,令
5. 池化(Pooling)
随着模型网络不断加深,卷积核越来越多,要训练的参数还是很多,而且直接拿卷积核提取的特征直接训练也容易出现过拟合的现象。CNN使用的另一个有效的工具被称为“池化(Pooling)”出现并解决了上面这些问题,为了有效地减少计算量,池化就是将输入图像进行缩小,减少像素信息,只保留重要信息;为了有效地解决过拟合问题,池化可以减少数据,但特征的统计属性仍能够描述图像,而由于降低了数据维度,可以有效地避免过拟合。
给出池化的定义,对不同位置区域提取出有代表性的特征(进行聚合统计,例如最大值、平均值等),这种聚合的操作就叫做池化,池化的过程通常也被称为特征映射的过程(特征降维)。听起来很高深,其实简单地说就是下采样。
池化的过程如下图所示:
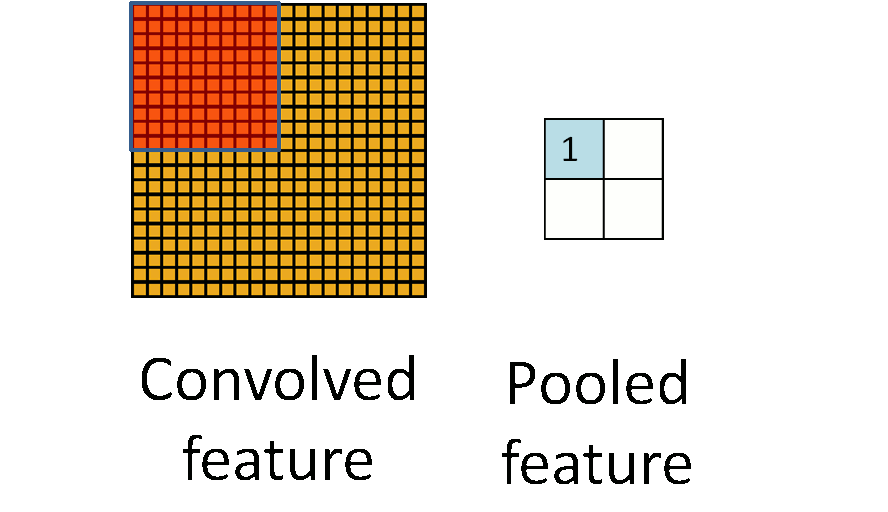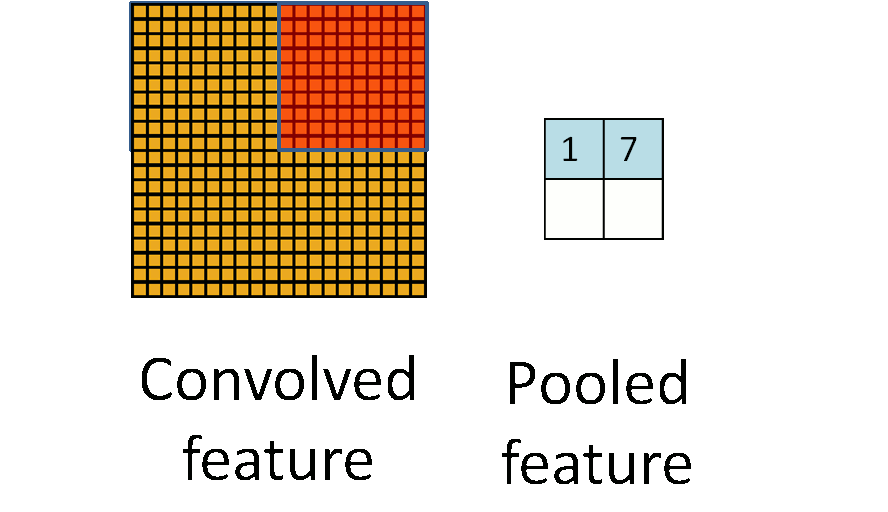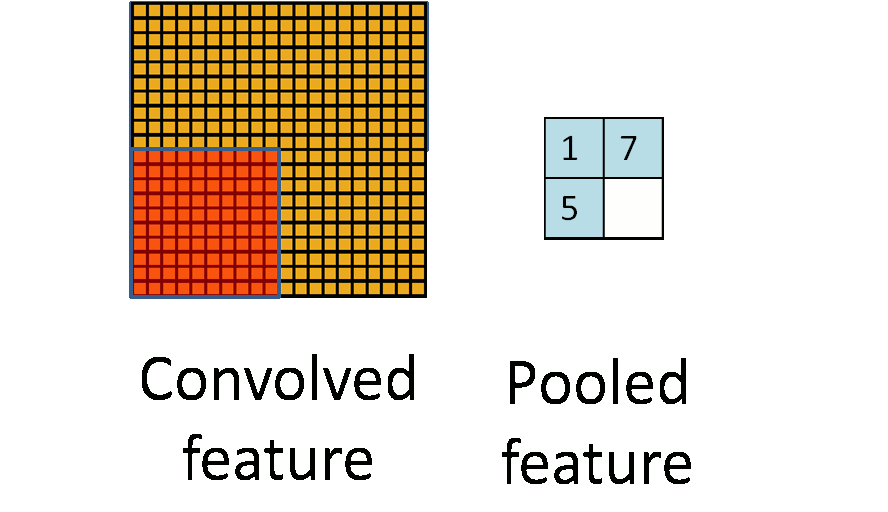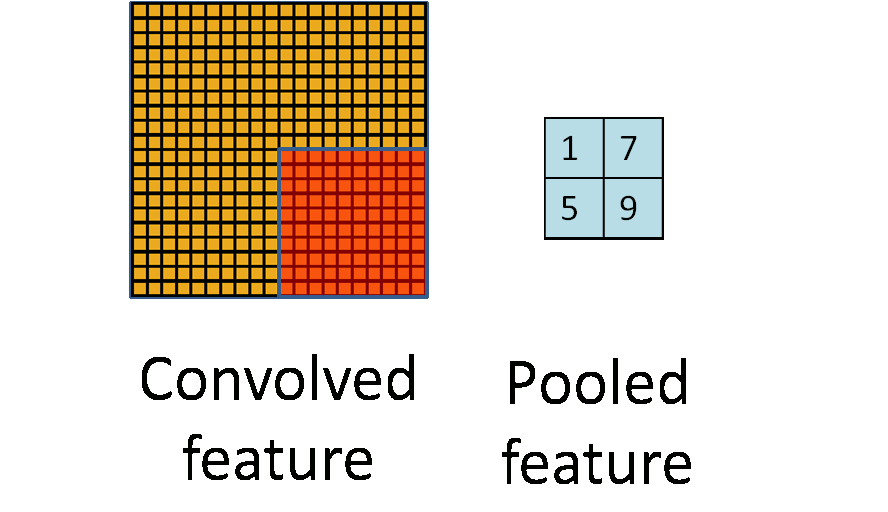
池化主要有两种,除了最大值池化(Max Pooling)之外,还有平均值池化(Average pooling),CNN中随机池化使用的较少。
最大池化是对局部的值取最大;平均池化是对局部的值取平均;随机池化是根据概率对局部的值进行采样,采样结果便是池化结果。概念非常容易理解,其示意图如下所示:
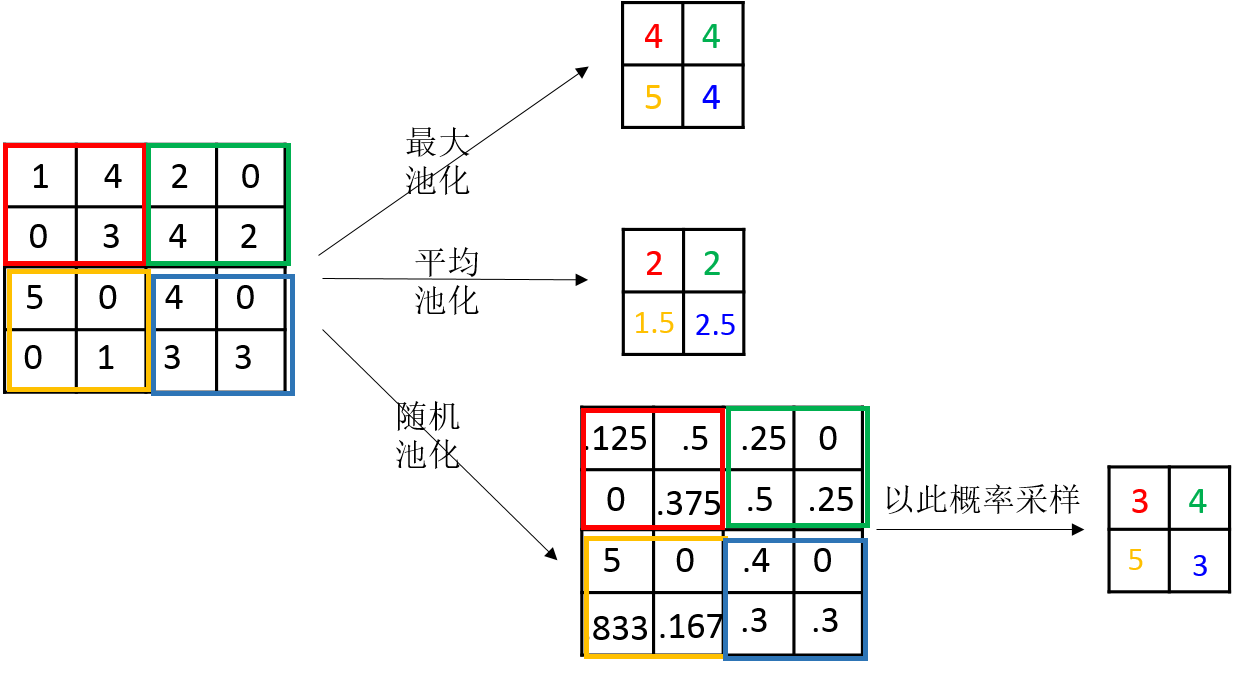
三种池化的意义:
-
最大池化可以获取局部信息,可以更好保留纹理上的特征。如果不用观察物体在图片中的具体位置,只关心其是否出现,则使用最大池化效果比较好。
-
平均池化往往能保留整体数据的特征,能凸出背景的信息。
-
随机池化中元素值大的被选中的概率也大,但不是像最大池化总是取最大值。随机池化一方面最大化地保证了Max值的取值,一方面又确保了不会完全是max值起作用,造成过度失真。除此之外,其可以在一定程度上避免过拟合。
6. 激活函数
为了使神经网络能够拟合出各种复杂的函数,必须使用非线性激活函数,用来加入非线性因素,把卷积层输出结果做非线性映射。
使用激活函数的意义参考激活函数
7. 局部感知
为什么要采用局部感知呢?因为可以降低参数量级。为什么要降低参数量级呢?因为如果采用经典的神经网络模型,如下图所示:
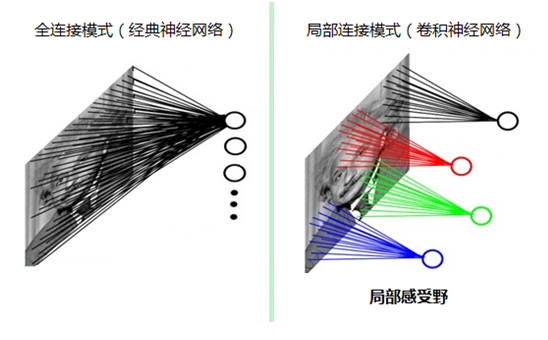
则需要读取整幅图像作为神经网络模型的输入(即全连接的方式),当图像的尺寸越大时,其连接的参数将变得很多,从而导致计算量非常大。比如对于一张1000x1000像素的图片,如果我们有1M隐藏层单元,那么一共有
而人类对外界的认知一般是从局部到全局、从片面到全面,先对局部有感知的认识,再逐步对全体有认知,这是人类的认识模式。类似的,在机器识别图像时也没有必要把整张图像按像素全部都连接到神经网络中,局部范围内的像素之间联系较为紧密,而距离较远的像素则 相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。这种模式就是卷积神经网络中降低参数数目的重要神器:局部感受野,节省了内存。
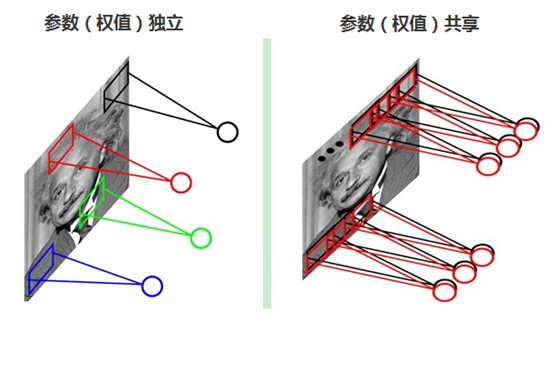
8. 参数(权值)共享
每张自然图像(人物、山水、建筑等)都有其固有特性,也就是说,图像其中一部分的统计特性与其它部分是接近的。这也意味着这一部分学习的特征也能用在另一部分上。因此,在局部连接中隐藏层的每一个神经元连接的局部图像的权值参数(例如5×5),将这些权值参数共享给其它剩下的神经元使用,那么此时不管隐藏层有多少个神经元,需要训练的参数就是这个局部图像的全部参数(例如5×5),也就是卷积核的大小,这样大大减少了训练参数。如下图所示:
9. 感受野(Receptive field)
感受野用来表示网络内部的不同神经元对原图像的感受范围的大小,换句话说,即为每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部连接。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。
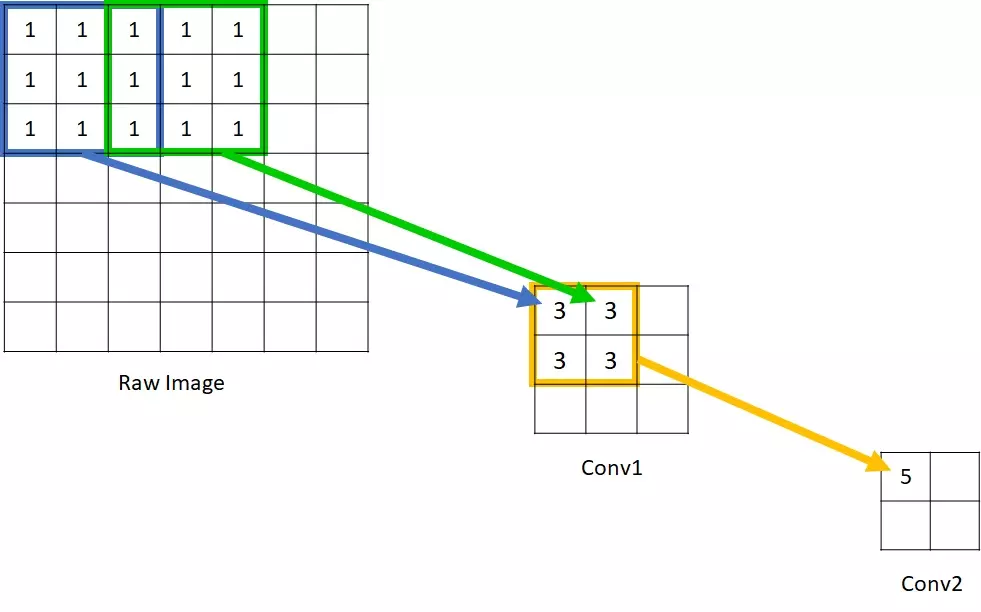
可以看到在Conv1中的每一个单元所能看到的原始图像范围是
感受野计算公式:
其中,
参考文章:
大话卷积神经网络CNN(干货满满)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?