


第三章:关系数据库标准语言SQL
不用纠结于 语法
create tableM<> 创建表
alter table <>更改表的结构
drop table<> 删除表
查询:顺序文件索引、B+树、散列索引(用公式计算出位置,而不是遍历)、
位图索引
cluster:聚簇索引。
UNIQUE:每一个表的索引是唯一的
查询语法:
SELECT[ALL|DISTINCT]<目标表达式>[,<目标表达式>]
FROM<><>
比如:
select R.A ,S.D //R表的A属性,S表的D属性
from R,S //从R表的S属性
where R.C = S.C //顺序是:from where select
查询经过计算的值:
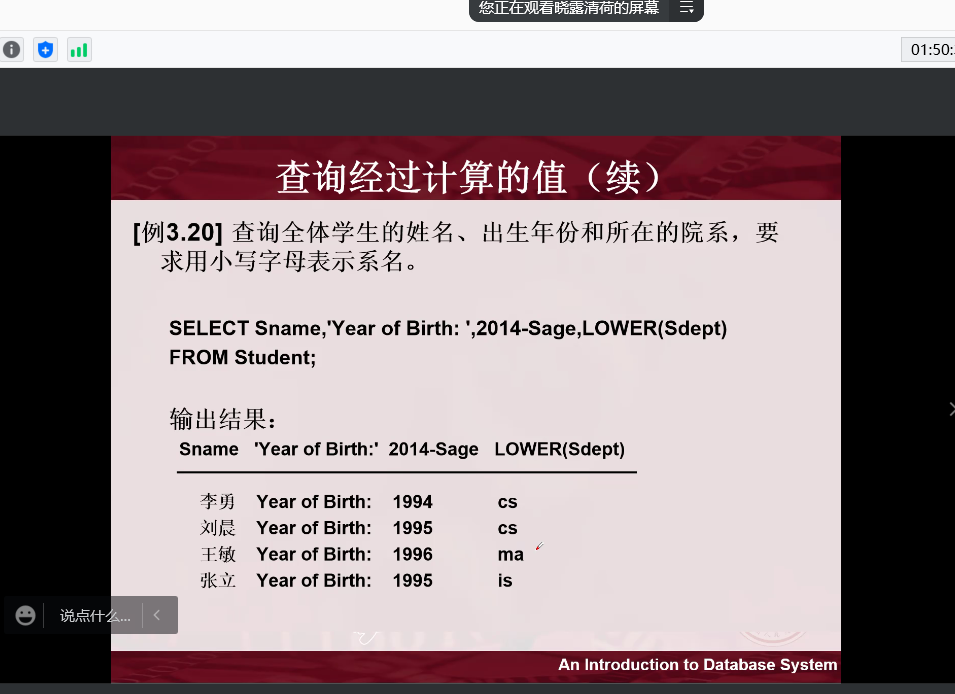
模糊查询,(通配符字符串)在关键词后面加字符。比如说搜索姓刘的,就是 like‘刘%’

练习题:查询语句(一下都是单表查询),伪代码 select * 代表搜索 所有满足这些信息的内容


聚集函数:

例子:

打开SC表,逐行扫描,相同学号的分到一个组,分成很多组,每一组行数不同,选修三门以上的。
能用where实现的,就不用having

where 和 having 的区别

集函数的课堂练习:

考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
考试必考!!!!!!
