

2022-2023-1 20201324《信息安全系统设计与实现(上)》第4章
1 并发计算导论
在早期,大多数计算机只有一个处理组件,称为处理器或中央处理器(CPU)。受这种硬件条件的限制,计算机程序通常是为串行计算编写的。要求解某个问题,先要设计一种算法,描述如何一步步地解决问题,然后用计算机程序以串行指令流的形式实现该算法。在只有一个CPU的情况下,每次只能按顺序执行某算法的一个指令和步骤。但是,基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。并行计算是一种计算方案,它尝试使用多个执行并行算法的处理器更快速地解决问题。过去,由于并行计算对计算资源的大量需求,普通程序员很少能进行并行计算近年来,随着多核处理器的出现,大多数操作系统(如Linux)都支持对称多处理(SMP)。甚至对于普通程序员来说,并行计算也已经成为现实。显然,计算的未来发展方向是并行计算
(1)顺序算法与并行算法
在描述顺序算法时,常用的方法是用一个begin-end代码块列出算法。begin-end代码块中的顺序算法可能包含多个步骤。所有步骤都是通过单个任务依次执行的, 每次执行一个步骤。当所有步骤执行完成时,算法结束。
相反,并行算法的描述使用cobegin-coend代码块来指定并行算法的独立任务。在cobegin-coend块中.所有任务都是并行执行的,紧接着cobegin-coend代码块的下一个步骤将只在所有这些任务完成之后执行
(2)并行性与并发性
通常,并行算法只识别可并行执行的任务,但是它没有规定如何将任务映射到处理组件。在理想情况下,并行算法中的所有任务都应该同时实时执行。然而,真正的并行执行只曲在有多个处理组件的系统中实现,比如多处理器或多核系统。在单CPU系统中,一次只能执行一个任务。在这种情况下,不同的任务只能并发执行,即在逻辑上并行执行。在单CPU系统中,并发性是通过多任务处理来实现的
2 线程
(1)线程的原理
一个操作系统(OS)包含许多并发进程“在进程模型中,进程是独立的执行单元。所有进程均在内核模式或用户模式下执行。在内核模式下,各进程在唯一地址空间上执行,与其他进程是分开的。虽然每个进程都是一个独立的单元,但是它只有一个执行路径。当某进程必须等待某事件时,例如I/O完成事件,它就会暂停,整个进程会停止执行匸线程是某进程同一地址空间上的独立执行单元。创建某个进程就是在一个唯一地址空间创建一个主线程。当某进程开始时,就会执行该进程的主线程。如果只有一个主线程,那么进程和线程实际上并没有区别。但是,主线程可能会创建其他线程。每个线程又可以创建更多的线程等。某进程的所有线程都在该进程的相同地址空间中执行,但每个线程都是一个独立的执行单元。在线程模型中,如果一个线程被挂起,其他线程可以继续执行。除了共享共同的地址空间之外.线程还共享进程的许多其他资源,如用户id、打开的文件描述符和信号等。打个简单的比方,进程是一个有房屋管理员(主线程)的房子,线程是住在进程房子里的人。房子里的每个人都可以独立做自己的事情,但是他们会共用一些公用设施,比如同一个信箱、厨房和浴室等。过去,大多数计算机供应商都是在自己的专有操作系统中支持线程。不同系统之间的实现有极大的区别。目前,几乎所有的操作系统都支持Pthread,它是IEEE POSIX 1003.1c的线程标准(POS1X 1995)
(2)线程的优点
- 线程创建和切换速度更快
- 线程的响应速度更快
- 线程更适合并行计算
(3)线程的缺点
- 由于地址空间共享,线程需要来自用户的明确同步。
- 许多库函数可能对线程不安全,例如传统strtok()函数将一个字符串分成一连串令牌。通常,任何使用全局变量或依赖于静态内存内容的函数.线程都不安全。为了使库函数适应线程环境,还需要做大量的工作。
- 在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
3 线程操作
线程的执行轨迹与进程类似。线程可在内核模式或用户模式下执行在用户模式下,线程在进程的相同地址空间中执行,但每个线程都有自己的执行堆栈。线程是独立的执行単元,可根据操作系统内核的调度策略,对内核进行系统调用,变为挂起、激活以继续执行等。为了利用线程的共享地址空间,操作系统内核的调度策略可能会优先选择同-进程中的线程,而不是不同进程中的线程。
4 线程管理函数
Pthread库提供了用于线程管理的以下API。
pthread_create(thread, attr, function, arg): create thread
pthread_exit(status) : terminate thread
pthread_cancel(thread) : cancel thread
pthread_attr_init(attr) : initialize thread attributes
pthread_attr_destroy(attr): destroy thread attribute
(1)创建线程
使用pthread_create()函数创建线程
int pthread_create (pthread_t *pthread_id, pthread_attr_t *attr, void *(*func)(void *), void *arg);
如果成功则返回0,如果失败则返回错误代码。pthread_create()函数的参数为
- pthread_id是指向pthread_t类型变量的指针。它会被操作系统内核分配的唯一线程ID填充。在POSIX中,pthread_t是一种不透明的类型。程序员应该不知道不透明对象的内容,因为它可能取决于实现情况。线程可通过pthread_self()函数获得自己的ID。在Linux中,pthreadj类型被定义为无符号长整型,因此线程1D可以打印为%111。
- attr是指向另一种不透明数据类型的指针,它指定线程属性,下面将对此进行更详细的说明。
- fimc是要执行的新线程函数的入口地址。
- arg是指向线程函数参数的指针,可写为:
void *func(void *arg)
其中,attr参数最复杂。下面给出了attr参数的使用步骤。
- 定义一个pthread属性变量pthread_attr_t attr
- 用pthread_attr_init(&attr)初始化属性变量。
- 设置属性变量并在pthread_create()调用中使用。
- 必要时,通过pthread_attr_destroy(&attr)释放attr资源。
下面列出了使用属性参数的一些示例。每个线程在创建时都默认可与其他线程连接。必要时,可使用分离属性创建一个线程,使它不能与其他线程连接。下面的代码段显示了如何创建一个分离线程。
pthread_attr_t attr; // define an attr variable
pthread_attr_init(&attr); // initialize attr
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); // set attr pthread_create(&thread_idz func, NULL); // create thread with attr
pthread_attr_destroy; // optional: destroy attr
每个线程都使用默认堆栈的大小来创建。在执行过程中,线程可通过函数找到它的堆栈大小:
size_t pthread_attr_getstacksize()
它可以返回默认的堆栈大小。下面的代码段显示了如何创建具有特定堆栈大小的线程。
pthread_attr_t attr; // attr variable
size_t stacksize; // stack size
pthread_attr_init(&attr); // initialize attr
stacksize = 0x10000; // stacksize=16KB;
pthread_attr_setstacksize(ftattr, stacksize); // set stack size in attr
pthread_create(&threads[t], &attr, func, NULL); // create thread with stack size
如果attr参数为NULL,将使用默认属性创建线程。实际上,这是创建线程的建议方法,除非有必要更改线程属性,否则应该遵循这种方法。接下来,我们将attr设置为NULL,就可始终使用默认属性。
(2)线程ID
线程ID是一种不透明的数据类型,取决于实现情况。因此,不应该直接比较线程ID。如果需要,可以使用pthread_equal()函数对它们进行比较。
int pthread_equal (pthread_t tl, pthread_t t2);
如果是不同的线程,则返回0,否则返回非0。
(3)线程终止
线程函数结束后,线程即终止。或者,线程可以调用函数
int pthread_exit (void *status);
进行显式终止,其中状态是线程的退出状态。通常,0退出值表示正常终止,非0值表示异常终止。
(4)线程连接
一个线程可以等待另一个线程的终止,通过:
int pthread_join (pthread_t thread, void **status_ptr);
终止线程的退出状态以status_ptr返回
(5)用线程快速排序
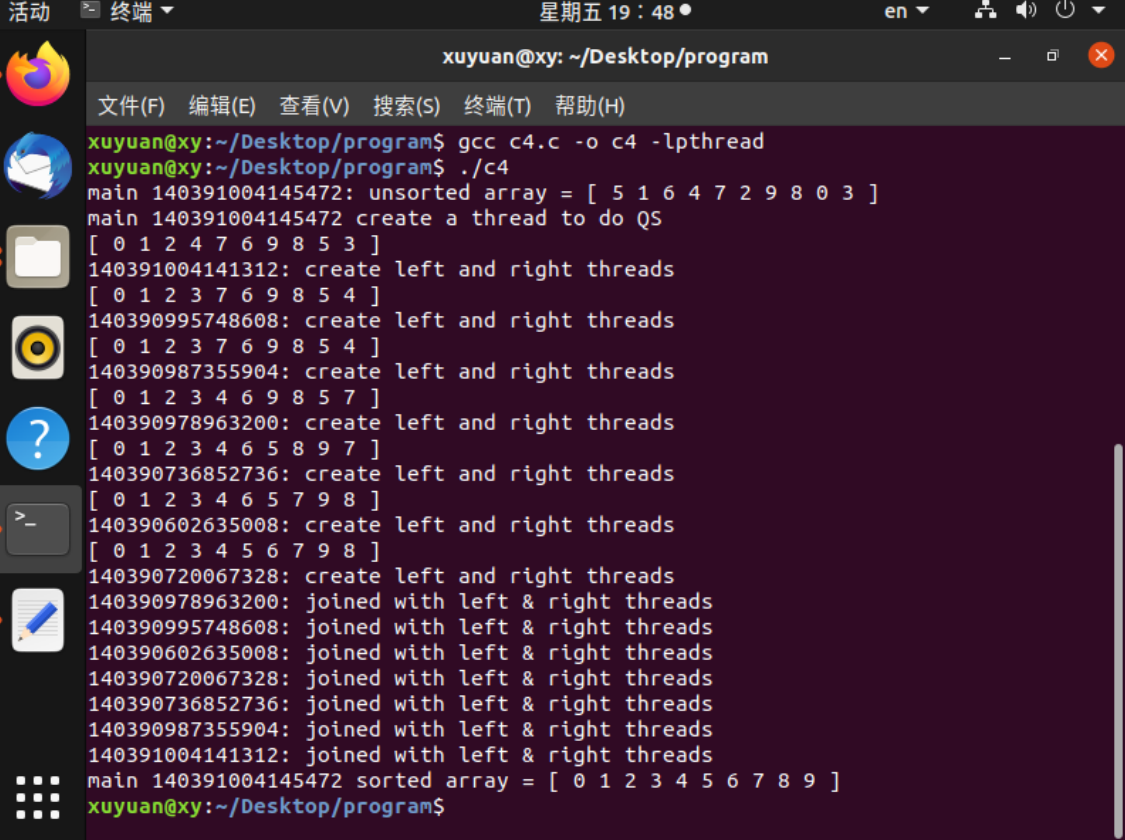
5 线程同步
由于线程在进程的同一地址空间中执行,它们共享同一地址空间中的所有全局变量和数据结构。当多个线程试图修改同一共享变量或数据结构时,如果修改结果取决于线程的执行 顺序,则称之为竞态条件。在并发程序中,绝不能有竞态条件。否则,结果可能不一致。除 了连接操作之外,并发执行的线程通常需要相互协作。为了防止出现竞态条件并且支持线程 协作,线程需要同步。通常,同步是一种机制和规则,用于确保共享数据对象的完整性和并 发执行实体的协调性。它可以应用于内核模式下的进程,也可以应用于用户模式下的线程。
(1)互斥量
最简单的同步工具是锁,它允许执行实体仅在有锁的情况下才能继续执行,在Pthread 中,锁被称为“互斥量”,意思是相互排斥。互斥变量是用pthread_mutex_t类型声明的,在使用之前必须对它们进行初始化。有两种方法可以初始化互斥量。
①静态方法
定义互斥量m,并使用默认属性对其进行初始化。
②动态方法
使用pthread_mutex_init()函数,可通过attr参数设置互斥属性;
(2)死锁预防
死锁是一种状态,在这种状态下,许多执行实体相互等待,因此都无法继续下去。有多种方法可以解决可能的死锁问题,其中包括死锁预防、死锁规避、死锁检测和恢复等。在实际系统中,唯一可行的方法是死锁预防,试图在设计并行算法时防止死锁的发生。
(3)条件变量
作为锁,互斥量仅用于确保线程只能互斥地访问临界区中的共享数据对象。条件变量提供了一种线程协作的方法。在Pthread中,使用类型pthread_cond_t来声明条件变量,而且必须在使用前进行初始化。与互斥量一样,条件变量也可以通过两种方法进行初始化。
①静态方法,在声明时,如:
pthread_cond_t con = PTHREAD_COND_INITIALIZER;
定义一个条件变量con,并使用默认属性対其进行初始化。
②另一种是动态方法,使用pthread_cond_init()函数,可通过attr参数设置条件变量 为简便起见,我们总是使用NULL attr参数作为默认属性。
(4)屏障
线程连接操作允许某线程(通常是主线程)等待其他线程终止。在等待的所有线程都终 止后,主线程可创建新线程来继续执行并行程序的其余部分。创建新线程需要系统开销。在 某些情况下,保持线程活动会更好,但应要求它们在所有线程都达到指定同步点之前不能继续活动。在Pthreads中,可以采用的机制是屏障以及一系列屏障函数。
创建屏障步骤
①主线程创建一个屏障对象pthread_barrier_t barrier;
②调用pthread_barrier_init(&barrier NULL, nthreads);,用屏障中同步的线程数字对它进行初始化
③工作线程使用pthread_barrier_wait(&barrier)在屏障中等待指定数量的线程到达屏障
(5)Linux中的线程
与许多其他操作系统不同,Linux不区分进程和线程。对于Linux内核,线程只是一个 与其他进程共享某些资源的进程。在Linux中,进程和线程都是由clone()系统调用创建的
