

2022-2023-1 20201324《信息安全系统设计与实现(上)》第7章
1 文件操作级别
文件操作分为五个级别:
(1)硬件级别:
- fdisk:将硬件、U盘或SDC盘分区。
- mkfs:格式化磁盘分区,为系统做好准备。
- fsck:检查和维修系统。
- 碎片整理:压缩文件系统中的文件。
(2)操作系统中的文件系统函数
每个操作系统内核均可为基本文件操作提供支持,下文列出了类unix系统内核中的一些函数,其中前缀k表示内核函数。
kmount () . kumount ( ) (mount/umount file systems)
kmkdir(), krmdir() (make/ remove directory)
kchdir(), kgetcwd () (change directory, get CWD pathname)
klink(),kunlink() (hard link/unlink files)
kchmod(), kchown(),kutime() (change r|w|x permissions, owner,time)
kcreat (), kopen() (create/open file for R,W,RW,APPEND)
kread(),kwrite() (read/write opened files)
klseek(): kclose() (lseak/close file descriptors)
ksymlink(), kreadlink () (create/read symbolic link files)
kstat(), kfstat(),klstat() (get file status/information)
kopendir(), kreaddiz() (open/read airectories)
(3)系统调用
用户模式程序使用系统调用来访问内核函数
open(),read(),lseek()和close()都是c语言库函数。每个库函数都会发出一个系统调用,使进程进入内核模式来执行相应的内核函数,当进程结束执行内核函数使,会返回到用户模式,并得到所需的结果。
(4)I/O库函数
系统调用可以让用户读/写多个数据块,这些数据块只是一系列字节。他们不知道,也不关心数据的意义。用户通常需要读/写单独的字符、行或数据结构记录等。C语言库提供了一系列标准的I/O函数,包括:
FILE mode I/O: fopen(),fread();fwrite(),fseek(),fclose(),fflush()
char mode I/O: getc(), getchar(); ugetc(); putc(),putchar()
line mode I/O: gets() , fgets();puts( ) , fputs()
formatted I/O: scanf(),fscanf().sscanf(); printf(),fprintf() , sprintf()
(5)用户命令
用户可以使用Unix/Linux命令来执行文件操作,而不是编写程序。用户命令如下:
mkdir,rmdir,cd,pwd,ls,link,unlink,rm,cat,cp,mv,chmod,etc.
(6)sh脚本
虽然比系统调用方便的多,但是必须要手动呼入命令
2 文件I/O操作
(1)文件I/O操作示意图
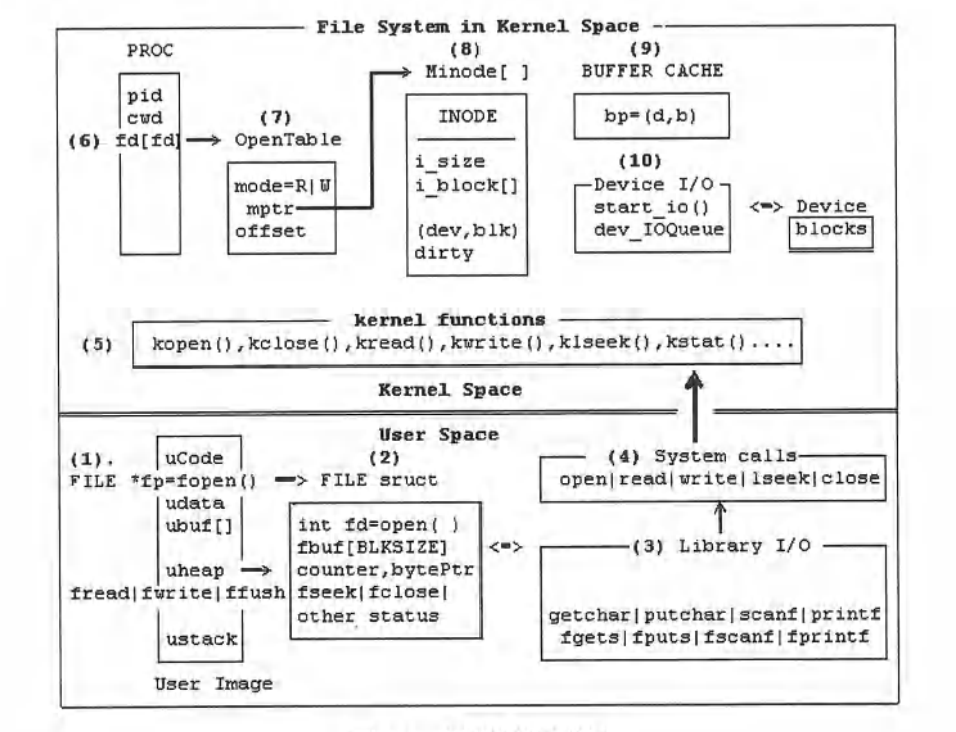
(2)用户模式下的程序执行操作
打开一个读文件流
FILE *fp = fopen("file", "r");
或:
打开一个读/写文件流
FILE *fp = fopen("file", "w");
fopen()在用户( heap)空间中创建一个FILE结构体,包含一个文件描述符fd、一个fbuf [BLKSIZE]和一些控制变量。它会向内核中的 kopen()发出一个fd = open("file",flags=READ or WRITE)系统调用,构建一个OpenTable来表示打开文件示例。成功后,fp会指向FILE结构体,其中fd是 open()系统调用返回的文件描述符。
fread(ubuf,size,nitem,fp):将nitem个size字节读取到ubuf上
- 将数据从FILE结构体的fbuf上复制到ubuf上,若数据足够,则返回。
- 如果fbuf没有更多数据,则执行(4a)。
(4a)发出read(fd, fbuf, BLKSIZE)系统调用,将文件数据块从内核读取到fbuf上,然后将数据复制到ubuf上,直到数据足够或者文件无更多数据可复制
(4b) fwrite(ubuf,size,nitem, fp):将数据从ubuf复制到 fbuf
-
若(fbuf有空间):将数据复制到fbuf上,并返回
-
若(fbuf已满);发出 write(fd,fbuf,BLKSIZE)系统调用,将数据块写入内核,然后再次写入fbuf
这样,fread()/fwrite()会向内核发出read()/write()系统调用,但仅在必要时发出,而且它们会以块集大小来传输数据,提高效率。同样,其他库IO函数,如 fgetc/fputc、fgetsllputs、fscanf/fprintf等也可以在用户空间内的FILE结构体中对fbuf进行操作。
3 低级别文件操作
(1)分区
一个块存储设备,如硬盘、U盘、SD卡等,可以分为几个逻辑单元,称为分区。各分区均可以格式化为特定的文件系统,也可以安装在不同的操作系统上。大多数引导程序,如GRUB、LILO等,都可以配置为从不同的分区引导不同的操作系统。分区表位于第一个扇区的字节偏移446(0x1BE)处,该扇区称为设备的主引导记录(MBR)。表有4个条目,每个条目由一个16字节的分区结构体定义,即:
struct partition {
u8 drive; // 0x80 - active
u8 head; // starting head
u8 sector; // starting sector
u8 cylinder; // starting cylinder
u8 sys_type; // partition type
u8 end_head; // end head
u8 end_sector; // end sector
u8 end_cylinder; // end cylinder
u32 start_sector; // starting sector counting from 0
u32 nr_sectors; // number of sectors in partition
};
每个扩展分区的第一个扇区是一个本地MBR。每个本地MBR在字节偏移量0xIBE处也有一个分区表,只包含两个条目。第一个条目定义了扩展分区的起始扇区和大小。第二个条目指向下一个本地MBR。
下面在Linux下创建一个虚拟磁盘映像文件,在虚拟磁盘映像文件上运行fdisk,并查看帮助文档
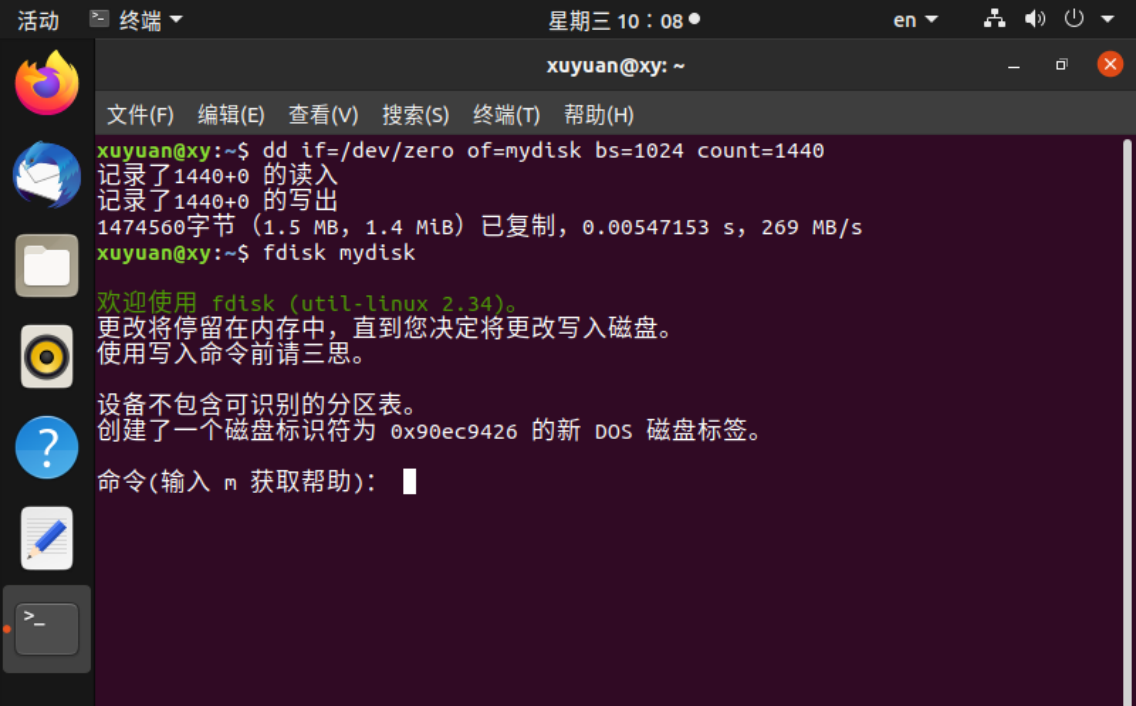
(2)格式化分区
fdisk只将一个存储设备划分为多个分区。每个分区都有特定的文件系统类型,但是分区还不能使用。为了存储文件,必须先为特定的文件系统准备好分区。该操作习惯上称为格式化磁盘或磁盘分区。在Linux中,它被称为mkfs,表示Make文件系统。Linux支持多种不同类型的文件系统。每个文件系统都期望存储设备上有特定的格式。在Linux中,命令
mkfs -t TYPE [-b bsize] device nblocks
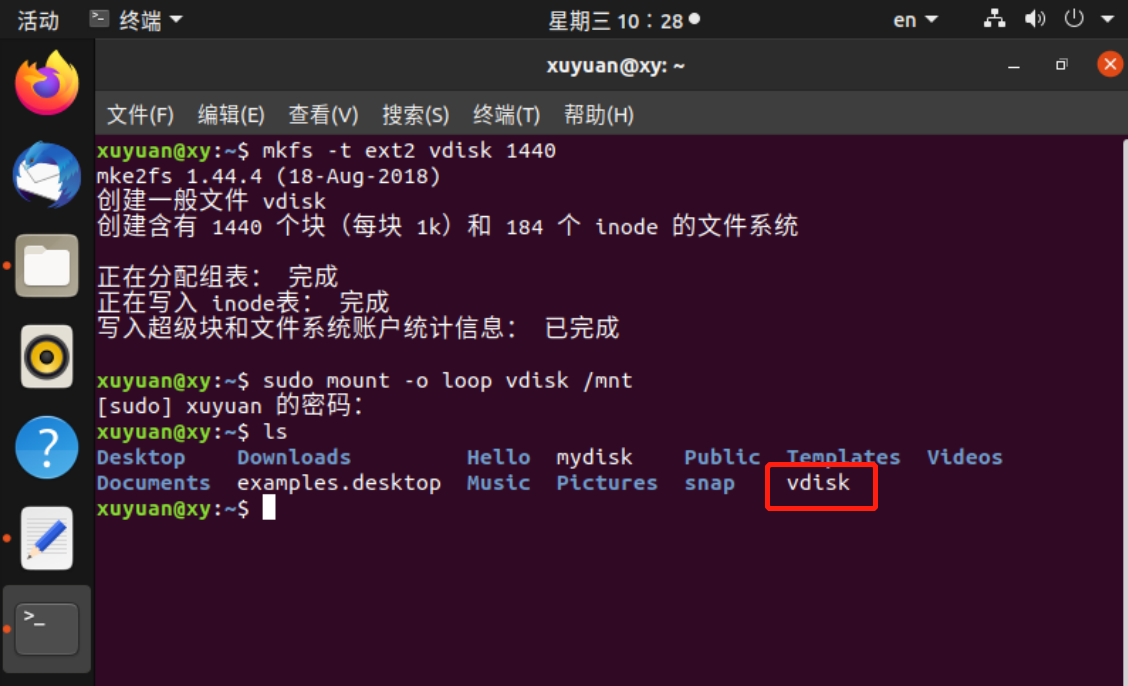
在一个nblocks设备上创建一个TYPE文件系统,每个块都是bsize字节。如果bsize未指定,则默认块大小为1KB。具体来说,假设是EXT2/3文件系统,它是Linux的默认文件系统。因此,
mkfs -t ext2 vdisk 1440
或
mke2fs vdisk 1440
格式化后的磁盘应是只包含根目录的空文件系统。但是,Linux的mkfs始终会在根目录下创建一个默认的lost+found目录。
/mnt目录通常用于挂载其他文件系统。
(3)挂载分区
创建一个虚拟磁盘映像,在vdisk上运行fdisk来创建一个分区P1
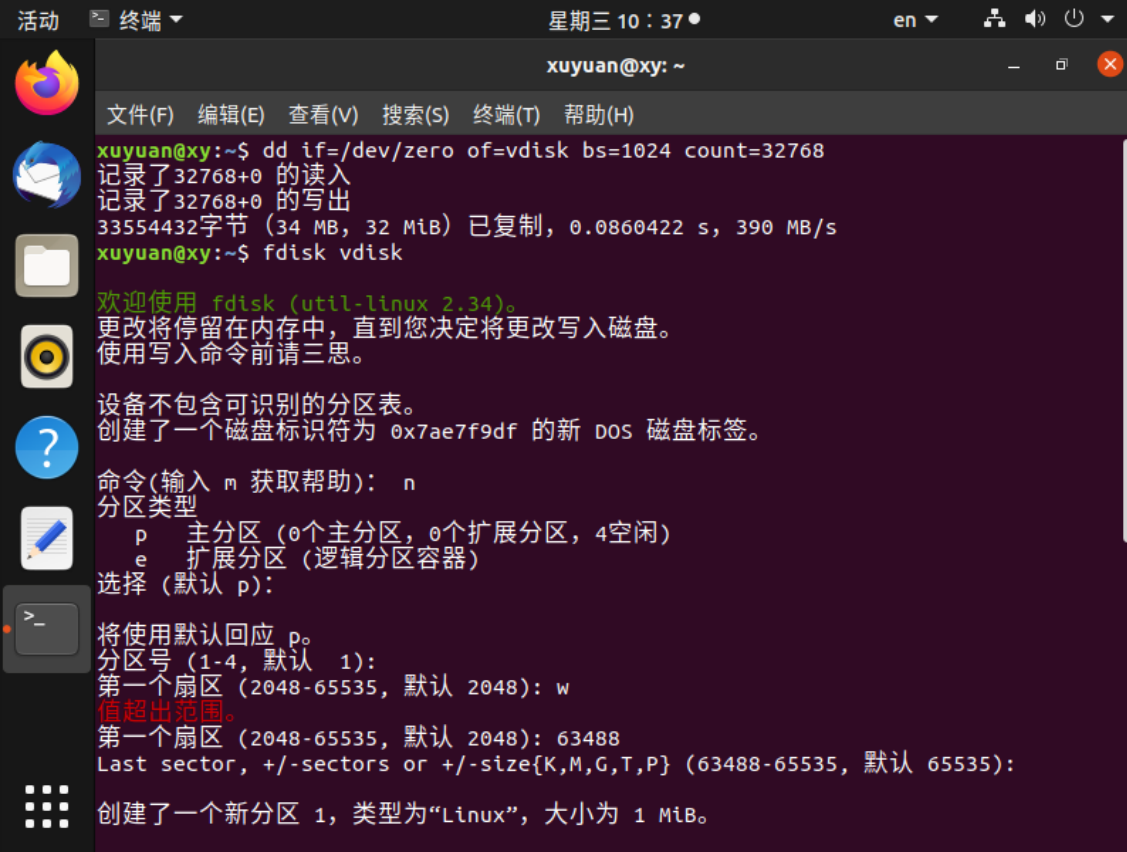
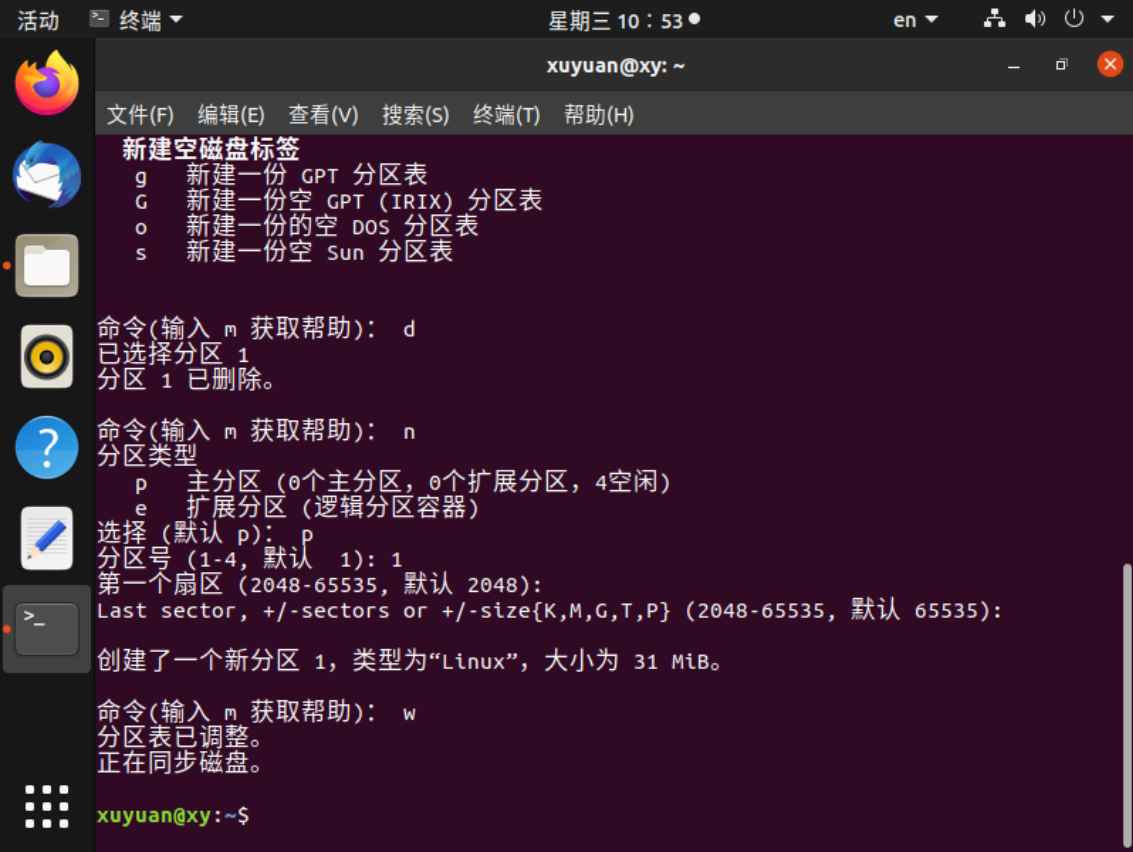
发现分区过小,于是删除分区1
输入d删除分区1

重新创建分区1
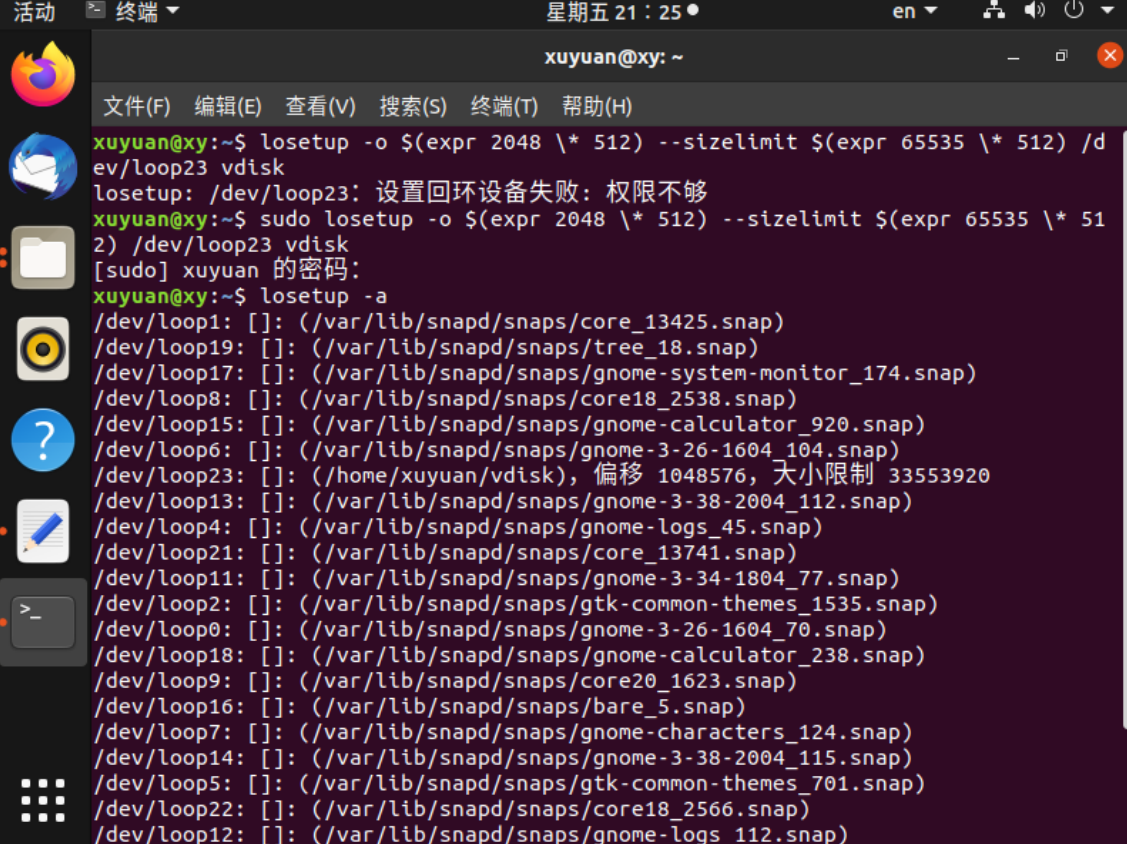
创建循环设备
如果报错losetup: /dev/loop1:设置回环设备失败:没有那个文件或目录 ,则用sudo losetup -f 找到第一个为空的回环,替换loop1
4 EXT2文件系统简介
(1)EXT2文件系统数据结构
在Linux下,我们可以创建一个包含简单EXT2文件系统的虚拟磁盘。
dd if=/dev/zero of=mydisk bs=1024 count=1440
mke2fs -b 1024 mydisk 1440
得到的EXT2文件系统有1440个块,每个块大小为1KB
Block#0:引导块 B0是引导块,文件系统不会使用它。它用于容纳从磁盘引导操作系统的引导程序
(2)超级块
Block#1:超级块(在硬盘分区中字节偏移量为1024)B1是超级块,用于容纳关于整个文件系统的信息。下文说明了超级块结构中的一些重要字段。
struct ext2_super_block {
u32 s_inodes_count; // Inodes count
u32 s_blocks_count; // Blocks count
u32 s_r_blocks_count; // Reserved blocks count
u32 s_free_blocks_count; // Free blocks count
u32 s_free_inodes_count; // Free inodes count
u32 s_first_data_block; // First Data Block
u32 s_log_block_size; // Block size
u32 s_log_cluster_size; // Allocation cluster size
u32 s_blocks_per_group; // # Blocks per group
u32 s_clusters_per_group; // # Fragments per group
u32 s_inodes_per_group; // # Inodes per group
u32 s_mtime; // Mount time
u32 s_wtime; // Write time
u32 s_mnt_count; // Mount count
u16 s_max_mnt_count; // Maximal mount count
u16 s_magic; // Magic signature
// more non-essential fields
u16 s_inode_size; // size of inode structure
};
(3)块组描述符
Block#2:块组描述符块(硬盘上的s_first_data_blocks-1)EXT2将磁盘块分成几个组。每个组有8192个块(硬盘上的大小为32K)。每组用一个块组描述符结构体描述
(4)位图
Block#8:块位图 (Bmap)(bg_blockbitmap)位图是用来表示某种项的位序列,例如磁盘块或索引节点。位图用于分配和回收项。在位图中,0位表示对应项处于FREE状态,1位表示对应项处于INUSE状态。一个软盘有1440个块,但是Block#0未被文件系统使用。所以,位图只有1439个有效位。无效位视作INUSE处理,设置为1。
Block#9:索引节点位图 (Imap)(bg_inodebitmap)一个索引节点就是用来代表一个文件的数据结构。EXT2文件系统是使用有限数量的索引节点创建的。各索引节点的状态用 B9中Imap中的一个位表示。在EXT2FS中,前10个索引节点是预留的。所以,空EXT2 FS的Imap以10个1开头,然后是0。无效位再次设置为1。
(5)索引节点
Block#10:索引(开始)节点块(bg_inode_table)每个文件都用一个128字节(EXT4中的是256字节)的独特索引节点结构体表示
