
前提:如果namenode没有做HA,那么至少应该启用secondarynamenode,以便namenode宕机之后手动恢复数据
实验环境:3个节点(cenos 6.10)
测试前数据: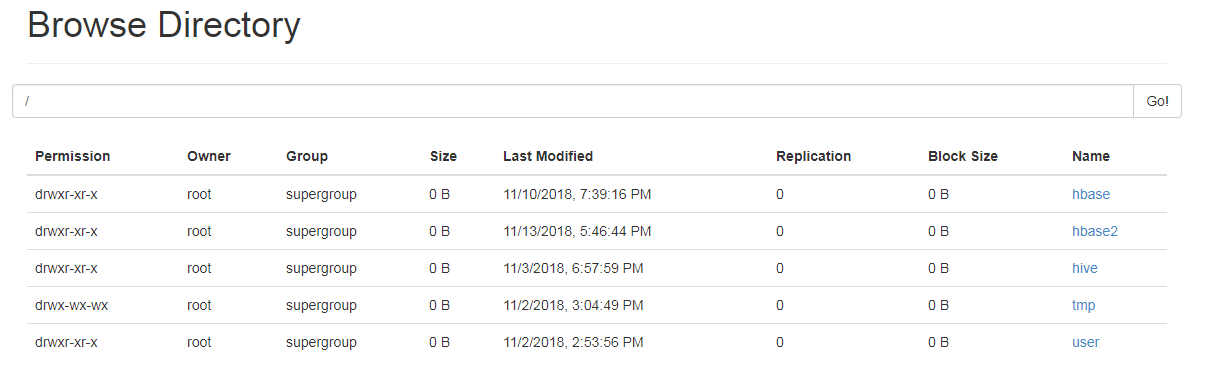
1.为了确保数据尽可能恢复,手动checkpoint一下
[root@hadoop1 dfs]# hdfs secondarynamenode -checkpoint force /************************************************************ STARTUP_MSG: Starting SecondaryNameNode STARTUP_MSG: host = hadoop1/192.168.110.11 STARTUP_MSG: args = [-checkpoint, force] STARTUP_MSG: version = 2.7.3 。。。。。。 。。。。。。 18/11/14 16:15:12 WARN namenode.SecondaryNameNode: Checkpoint done. New Image Size: 57464 18/11/14 16:15:12 INFO util.ExitUtil: Exiting with status 0 18/11/14 16:15:12 INFO namenode.SecondaryNameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down SecondaryNameNode at hadoop1/192.168.110.11 ************************************************************/
2.从1的输出可以看到,checkpoint成功。现在kill掉namenode,删除namenode的元数据文件夹。
3.停止所有节点,格式化namenode
4.用/tmp/hadoop-root/dfs/namesecondary/current/VERSION的内容替换掉新生成的元数据文件夹里面的VERSION文件内容,同时复制/tmp/hadoop-root/dfs/namesecondary/current文件夹下以fsimage开头的文件到namenode的元数据文件夹下
5.重启集群。通过UI界面可以看到数据已经恢复。
生产环境中数据可能不会完全恢复,因为宕机时没有机会来做checkpoint。

