
Postgresql使用explain分析sql
explain ANALYZE
SELECT zei.*,a.name areaName
from
zh_food_restaurant_entity zfre
left join zh_entity_info zei on zfre.social_code = zei.social_code
left join (select code,type,name from areapandect where "level"=5)a on a.code = zei.belong_area
where active_flag = '1'
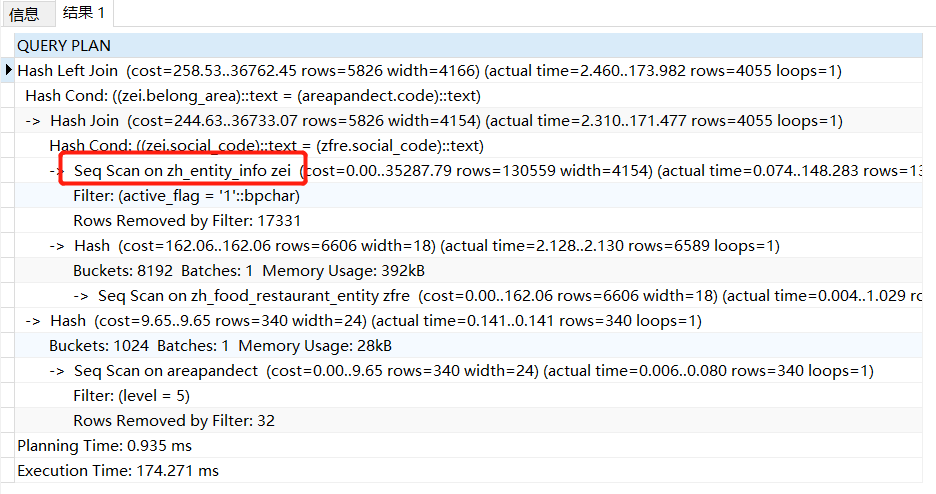
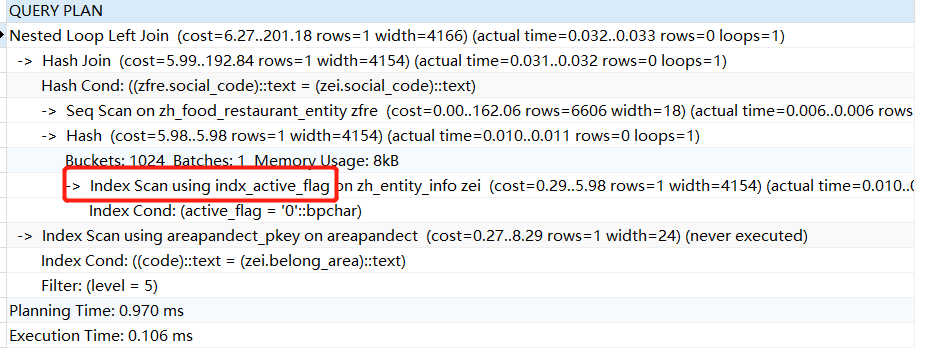
当添加active_flag的索引后,进行分析还是使用的是seq scan全表扫描,这是因为表zh_entity_info中大部分数据都是active_flag='1',此时全表顺序扫描比索引查询更快。若我们将sql语句中的active_flag='0',则使用的是索引查询。
扫描节点:
扫描节点,简单来说就是为了扫描表的元组,每次获取一条元组(Bitmap Index Scan除外)作为上层节点的输入。当然严格的说,不光可以扫描表,还可以扫描函数的结果集、链表结构、子查询结果集等。
目前在PostgreSQL 中支持:
参考地址:PgSQL · 最佳实践 · EXPLAIN 使用浅析(优化器,查询计划) - 雪球球 - 博客园 (cnblogs.com)
1、Seq Scan,全表顺序扫描
一般查询没有创建索引的表需要全表顺序扫描,例如下面的explain输出。

其中:Seq Scan on zh_entity_licence表明了这个节点的类型和作用对象,即在zh_entity_licence表上进行了全表扫描。
(cost=0.00..486.55 rows=8555 width=756)表明了这个节点的代价估计。
(actual time=0.167..5.289 rows=8555 loops=1)表明了这个节点的真实执行信息。
Filter: (found_time > '2000-02-03'::date) 表明了Seq Scan 节点之上的Filter 操作,即全表扫描时对每行记录进行过滤操作。
Rows Removed by Filter表明过滤操作过滤了多少行记录。
Planning time表明生成查询计划的时间。
Execution time:表明了实际的sql执行时间,其中不包括查询计划的生成时间。
2、Index Scan,基于索引扫描,但不只是返回索引列的值。
主要用来在where条件中存在的索引列时的扫描。

Index Scan using idx_found_date on zh_entity_licence表明使用表zh_entity_licence的idx_found_date 索引进行索引扫描。
Index Cond: (found_time = '2000-02-23'::date)表明索引扫描条件。
3、IndexOnly Scan,基于索引扫描,但只返回索引列的值,简称为覆盖索引。
4、BitmapIndex Scan,利用Bitmap 结构扫描;BitmapHeap Scan,把BitmapIndex Scan 返回的Bitmap 结构转换为元组结构
BitmapIndex Scan和Index Scan很相似,都是基于索引的扫描,但是BitmapIndex Scan节点每次执行返回的是一个位图而不是一个元组,其中位图中
每一个代表扫描到的一个数据块。而BitmapHeap Scan一般会作为BitmapIndex Scan的父节点,将BitmapIndex Scan 返回的Bitmap 结构转换为元组结构。
这样做最大的好处就是把Index Scan的随机读转换成了按照数据块的物理顺序读取,在数据量比较大的时候,这会大大提升扫描的性能。

Bitmap Index Scan on idx_found_date 表明使用idx_found_date 索引进行位图索引扫描。
Bitmap Heap Scan 表明对表zh_entity_licence进行Bitmap Heap扫描。
一般来说,index scan 要比sep scan快,但是如果获取的结果集占所有结果的比重很大时,这是index scan因为要先扫描索引,再读表数据,
反而不如全表扫描来的快。如果获取的结果集占比比较小,但元组数很多时,可能 Bitmap Index Scan的性能要比index scan好。如果获取的结果集
能够被索引覆盖,则index only scan因为不用去读取数据表,只去读取索引,所以一般性能最好,但是如果VM文件还未生成,可能性能就会比
index scan 差些。
5、Tid Scan,用于扫描一个元组的TID数组。
6、Subquery Scan,扫描一个子查询。
7、Function Scan,处理含有函数的扫描。
8、TableFunc Scan,处理tableFunc扫描。
9、Values Scan,用于扫描Values链表的扫描。
10、Cte Scan,用于扫描WITH 字句的结果集(递归)。
11、NamedTuplestore Scan,用于某些命名的结果集的扫描。
12、WorkTable Scan,用于扫描Recursive Union 的中间数据。
13、Foreign Scan,用于外键扫描。
14、Custom Scan,用于用户自定义的扫描。
