
jvm调优杂记
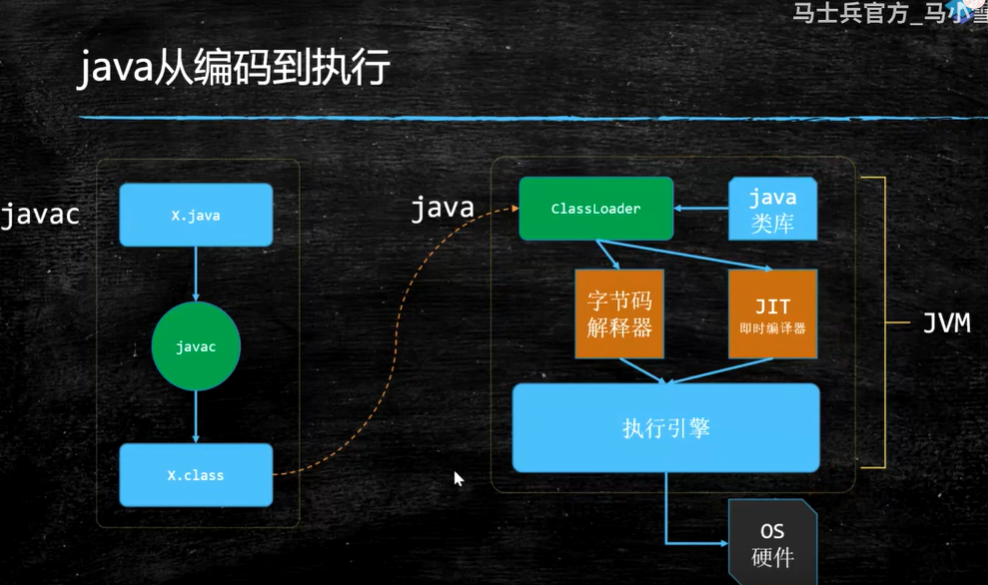
从上图可以看出,Java既是解释、也是编译型的语言。
参考地址:https://blog.csdn.net/qq_36704549/article/details/109390566
一、Java内存模型(JMM)
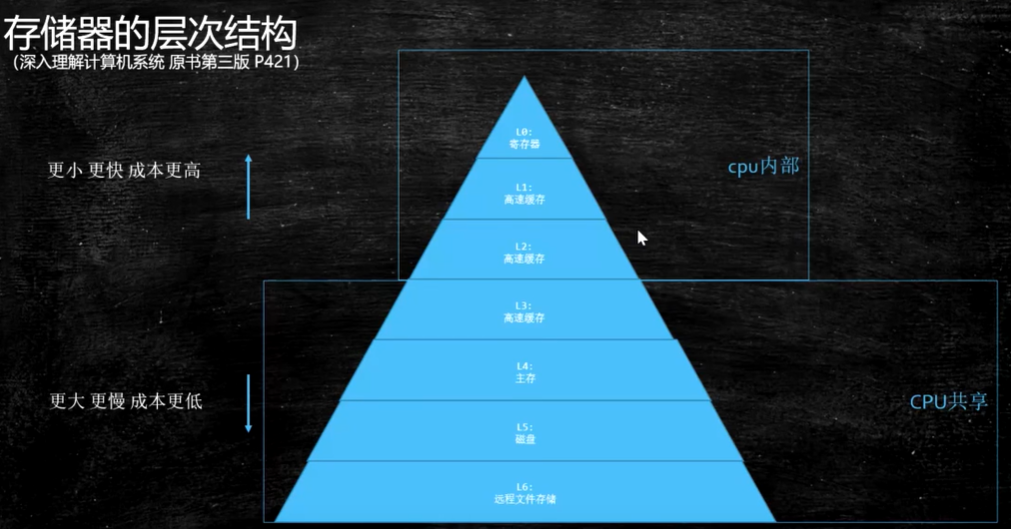
由下往上,访问速度越来越快,cpu的执行速度比内存和磁盘快得多,但是数据存储越来越小。
二、jmap命令
注意:生产线不建议使用,因为该命令会使堆运行暂停,堆越大,暂停时间越长。
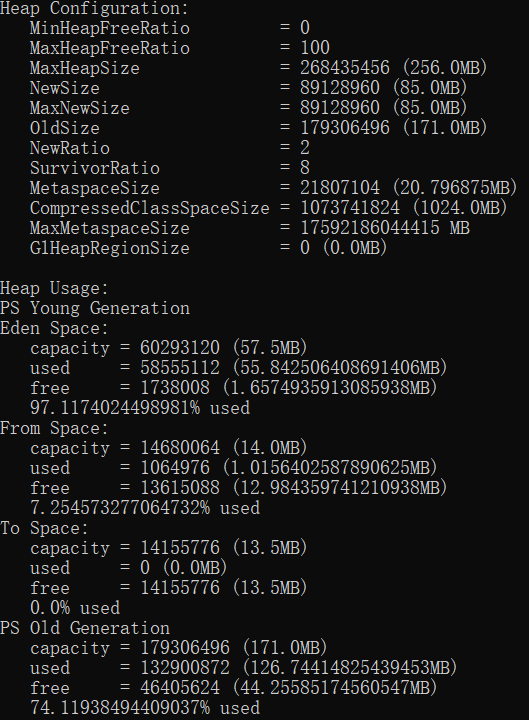
1、查看堆内存
jmap -heap pid
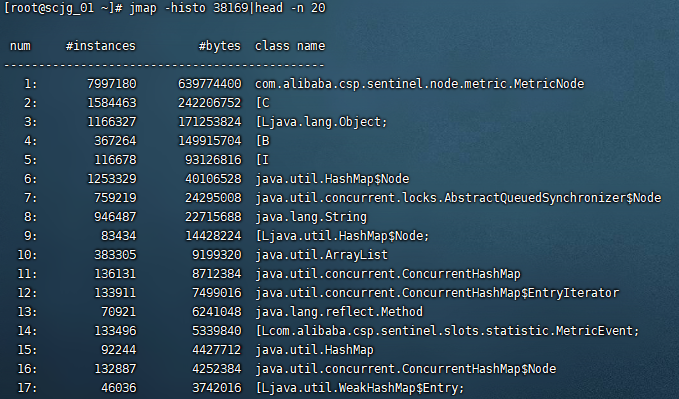
2、查看最占用内存的前n个对象
jmap -histo | head -n 20
jmap -histo | more(windows可以采用)
补充:
获取Java进程的相关信息
jinfo pid
获取Java的统计信息(跟踪信息)
跟踪GC信息
jstat -gc pid

获取进程里面的线程栈信息
jstack pid
如何定位jvm中cpu满了的问题:
1、使用top命令,查看占用cpu最多的进程号。
2、使用top -Hp pid命令查看该进程哪个线程占用cpu最多。
3、然后使用jstack 找到对应的线程(也可以使用arthas中的thread 线程号直接列出信息)。
如何定位死锁:
1、使用jstack观察线程情况
2、arthas中的命令thread -b 直接定位出来。
三、使用HeapDumpOnOutOfMemoryError将内存溢出信息导出到指定文件
注意:(中小企业,系统内存较小的情况)实际生产环境中,使用这个命令。
在java应用启动的时候添加该命令
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${目录}
然后可以使用MAT/jmap 进行分析dump文件
导出整个JVM 中内存信息
jmap -dump:format=b,file=文件名 [pid]
或者arthas的heapdump命令
heapdump --live dump文件
或者使用Jdk自带的工具jvisualvm/jconsole也可以查看。
栈空间是自动释放的。
四、GC的演化
GC的算法一般包含:复制算法、标记-清除算法、标记-整理(压缩)算法。
复制算法:没有碎片,浪费空间
这个算法将可用的内存空间分为大小相等的两块,每次只是用其中的一块,当这一块被用完的时候,就将还存活的对象复制到另一块中,然后把原已使用过的那一块内存空间一次回收掉。这个算法常用于新生代的垃圾回收。
复制算法解决了标记-清除算法的效率问题,以空间换时间,但是当存活对象非常多的时候,复制操作效率将会变低,而且每次只能使用一半的内存空间,利用率不高。
标记-清除算法:位置不连续、 产生碎片 效率偏低(两遍扫描)
从算法的名称上可以看出,这个算法分为两部分,标记和清除。首先标记出所有需要被回收的对象,然后在标记完成后统一回收掉所有被标记的对象。
这个算法简单,但是有两个缺点:一是标记和清除的效率不是很高;二是标记和清除后会产生很多的内存碎片,导致可用的内存空间不连续,当分配大对象的时候,没有足够的空间时不得不提前触发一次垃圾回收。
标记-整理(压缩)算法:没有碎片,效率偏低(两遍扫描,指针需要调整)
这个算法分为三部分:一是标记出所有需要被回收的对象;二是把所有存活的对象都向一端移动;三是把所有存活对象边界以外的内存空间都回收掉。
标记-整理算法解决了复制算法复制效率低、空间利用率低的问题,同时也解决了内存碎片的问题。
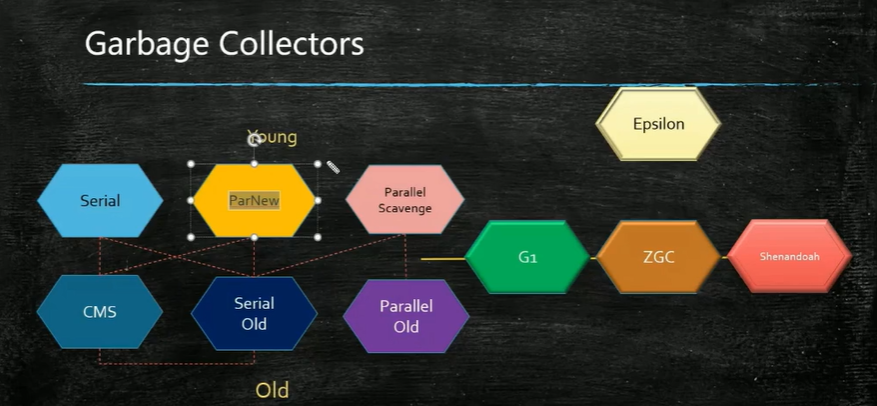
查看jdk默认使用的垃圾回收器
java -XX:+PrintCommandLineFlags -version

1、serial+serial old
单线程回收,出现STW(stop-the-world),适用于内存小(几兆--几十兆)的情况,年轻代和老年代都是这样。
2、Parallel Scavenge(PS) + Parallel Old(PO)
PS:工作在年轻代,PO:工作在老年代
并行垃圾回收:适用于内存在几十兆--上百兆或1G
3、Concurrent GC
并发GC:适用于在几十G。GC线程执行的时候,业务线程可以继续,出现STW非常短暂(前面2中都会出现,比较长),
包含:CMS(Concurrent Mark Sweep:并发标记清除)、ParNew、G1、ZGC等。
①、CMS(jdk1.5-jdk1.7,并发GC,只能采用这种方式):工作在老年代,年轻代使用serial或者ParNew(一般搭配是:CMS+ParNew),ParNew是多线程的,会产生STW,它是PS的增强,为了更好地和CMS搭配使用。
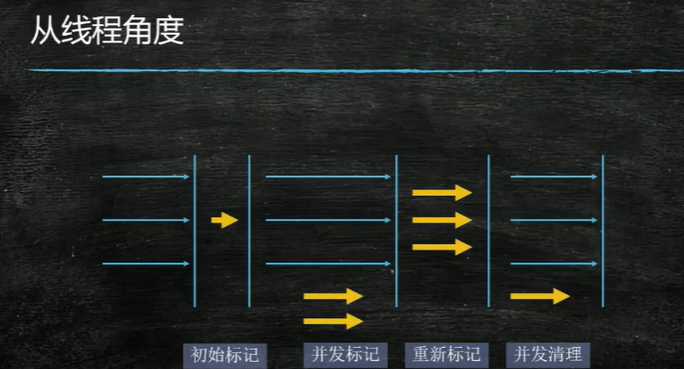
在初始标记和重新标记的时候,会出现短暂的STW
三色标记法:用在并发标记阶段
在线程运行中,找到并标记了该节点的所有子节点,则该节点标记为黑色,他的所有子节点标记为灰色,其他的为白色,下次直接从灰色节点开始扫描标记(但是不是扫描自己,而是直接扫描它的子节点)。
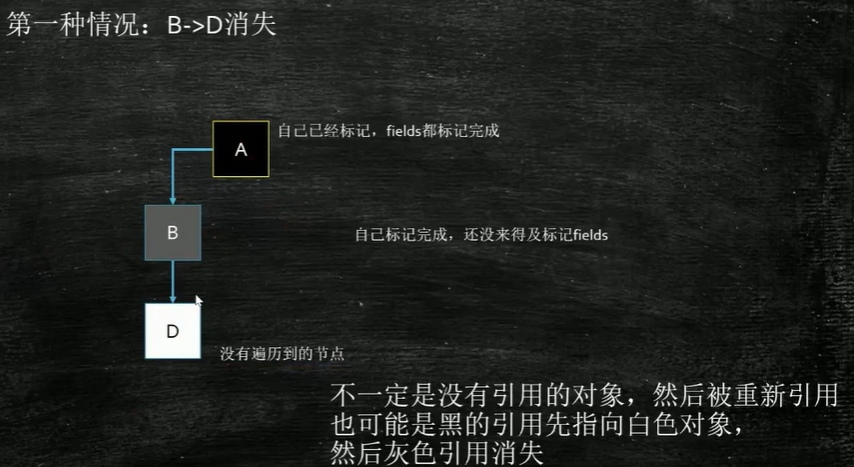
颜色的标记就是在对象上面进行标记记录(比如每个对象都有对象头,可以记录在里面,我们可以规定00:白色 01:灰色 11:黑色)
参考:https://blog.csdn.net/qq_26542493/article/details/90938070
存在的问题:当扫描到B的时候,业务程序开始运行了,这时候业务程序把B->D的引用剪短,变成A->D,但是A已经被标记成了黑色,将不再扫描,所以D没有可达的对象,此时会被当成垃圾清除掉。
CMS解决方案:把A变成灰色。
CMS天生的bug(偶尔会出现):

描述:

当m1线程标记对象A的属性1,但还未标记对象2时,m2业务线程将A的属性1指向D,将B指向C的引用剪掉,此时m3线程将A标记成灰色,此时m1线程再次扫描执行,它认为A的属性1已经标记了,则直接扫描A的属性2,
然后把A标记成黑色,这样造成D漏标,将找不到D,将D当成垃圾清理掉。
因此,CMS在remark(重新标记)阶段,必须重新扫描一遍(在并发标记的基础上),这样STW的时间可能依然非常长。
②、G1(分区算法):物理上不分代,逻辑上分代,G1的某个区域并不是固定的E或者O,回收之后,下次分配,可能变成E或者O。
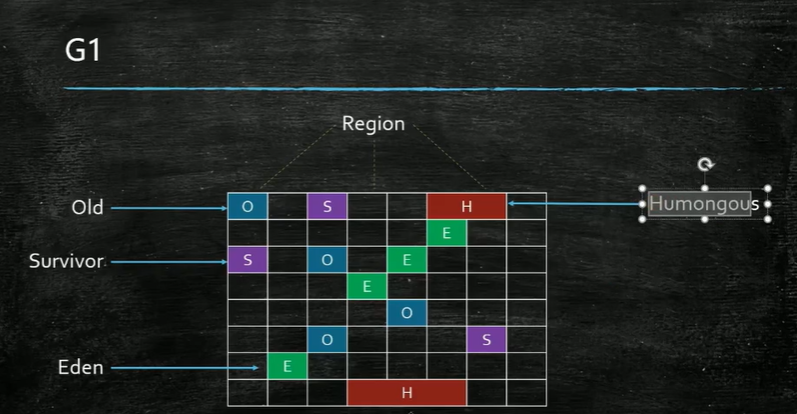
只回收其中几个快满了的区域,一边清理区域,一边使用,这样理想情况下,永远有空闲的区域可用,如果需要连续内存,则放到Humongous区域中,如果没有这种区域了,则开始进行full gc。
G1一次回收将把年轻代(S+E)全部回收,这样当年轻代非常大的时候,一次YGC,产生的STW的时间将比较长,因此诞生了ZGC。
