启动YARN并运行MapReduce程序
备注:此处的hadoop版本是3.1.4
一、配置集群
1.1、配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>k8smaster</value>
</property>
备注:k8smaster在hosts文件中需要指定为具体ip,不然在宿主机访问不到。
1.2、配置mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
二、启动集群
注意:启动前必须保证NameNode和DataNode已经启动
2.1、启动ResourceManager
yarn --daemon start resourcemanager
2.2、启动NodeManager
yarn --daemon start nodemanager
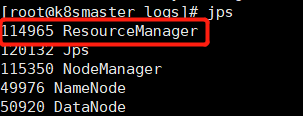
2.3、查看时启动成功
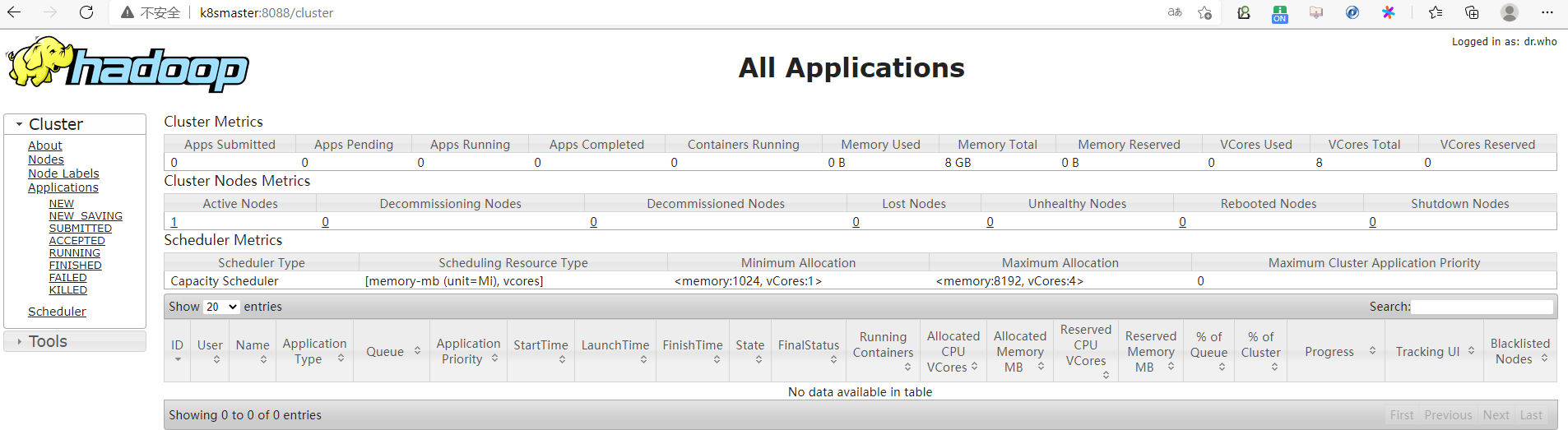
2.4、web页面访问
http://k8smaster:8088/
2.5、测试wordcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /home/yzh/hadoop/user/input /home/yzh/hadoop/user/output
此处wordcount后面的路径都是hdfs文件系统路径。
如果需要删除hdfs文件系统的路径,则执行下面的命令
hdfs dfs -rm -r /home/yzh/hadoop/user/output
2.6、遇到的问题
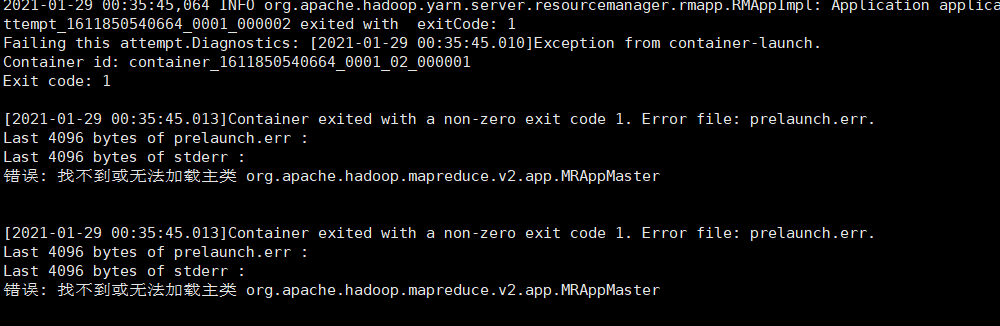
解决:在命令行输入:hadoop classpath

把上述输出的值添加到yarn-site.xml文件对应的属性 yarn.application.classpath下面,eg:
<property>
<name>yarn.application.classpath</name>
<value>具体的hadoop classpath</value>
</property>

mapred-site.xml中设置map和reduce任务的内存配置如下:(value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改) <property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
修改配置文件之后都要重启resourcemanager和nodemanager
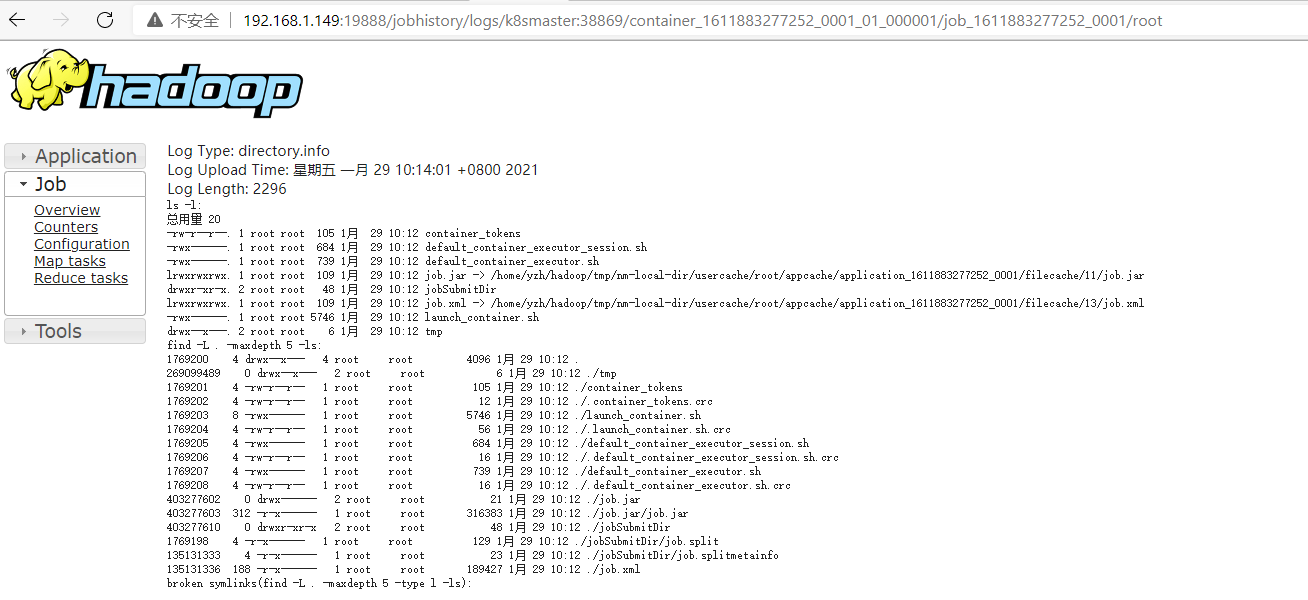
2.7、查看结果
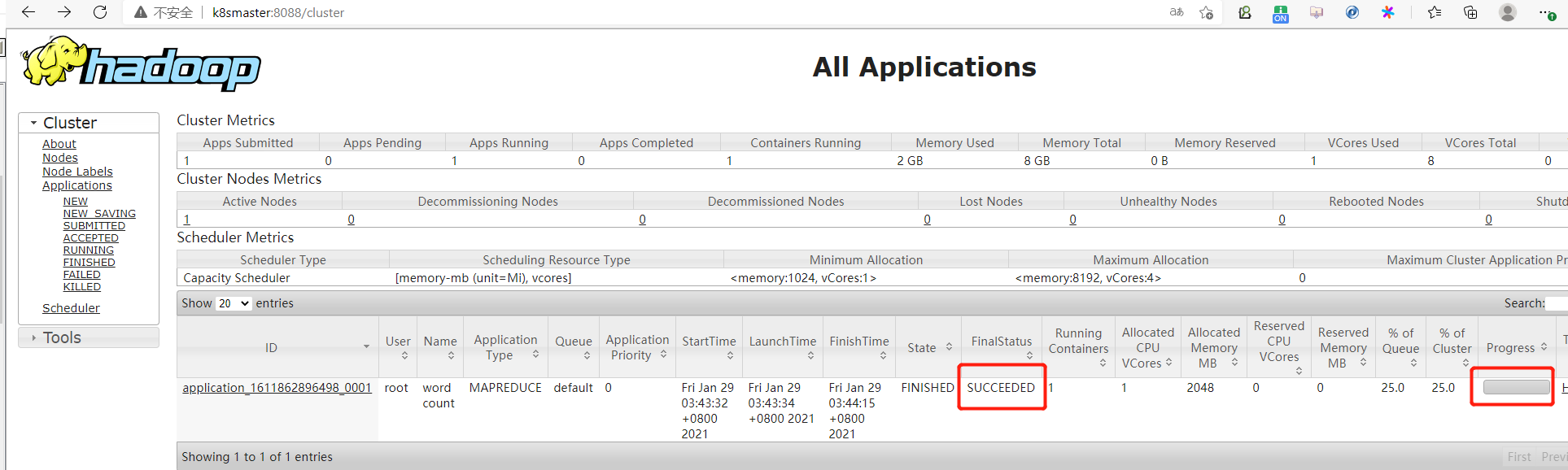
2.8、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤入校:
1、配置mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>k8smaster:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>k8smaster:19888</value>
</property>
2、启动历史服务器
mapred --daemon start historyserver
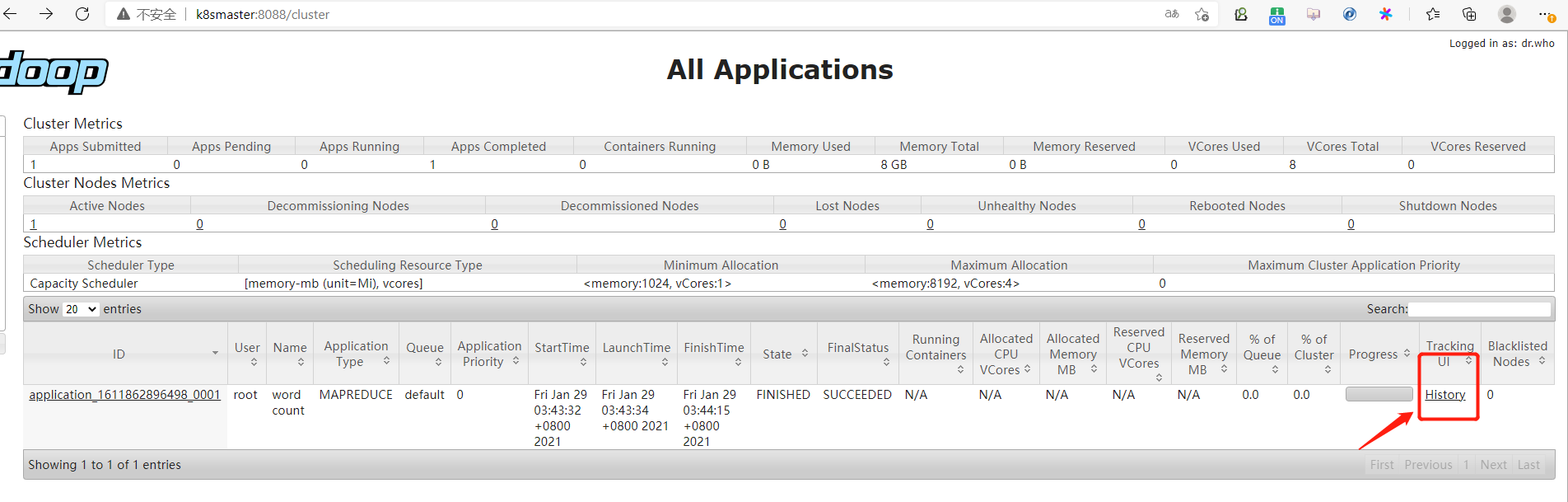
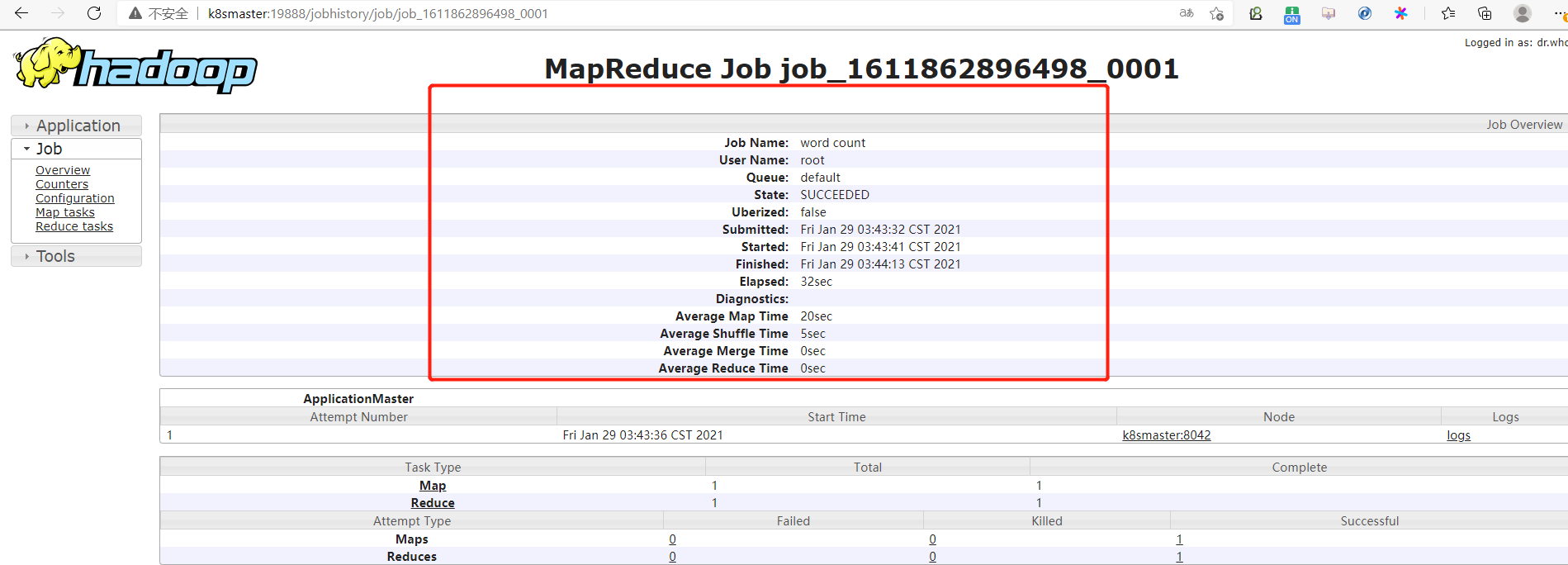
2.9、配置日志的聚集
日志聚集的概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动nodemanager、resourcemanager和historymanager。
yarn --daemon stop nodemanager
yarn --daemon stop resourcemanager
mapred --daemon stop historyserver
1、配置yarn-site.xml
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2、重新启动nodemanager、resourcemanager、historymanager
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
mapred --daemon start historyserver
3、删除hdfs上已经存在的输出文件
hdfs dfs -rm -r /home/yzh/hadoop/user/output
4、执行wordcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /home/yzh/hadoop/user/input /home/yzh/hadoop/user/output