传统高斯模糊与优化算法(附完整C++代码)
高斯模糊(英语:Gaussian Blur),也叫高斯平滑,是在Adobe Photoshop、GIMP以及Paint.NET等图像处理软件中广泛使用的处理效果,通常用它来减少图像噪声以及降低细节层次。这种模糊技术生成的图像,其视觉效果就像是经过一个半透明屏幕在观察图像,这与镜头焦外成像效果散景以及普通照明阴影中的效果都明显不同。高斯平滑也用于计算机视觉算法中的预先处理阶段,以增强图像在不同比例大小下的图像效果(参见尺度空间表示以及尺度空间实现)。 从数学的角度来看,图像的高斯模糊过程就是图像与正态分布做卷积。由于正态分布又叫作高斯分布,所以这项技术就叫作高斯模糊。图像与圆形方框模糊做卷积将会生成更加精确的焦外成像效果。由于高斯函数的傅立叶变换是另外一个高斯函数,所以高斯模糊对于图像来说就是一个低通滤波器。
高斯模糊是一种图像模糊滤波器,它用正态分布计算图像中每个像素的变换。N维空间正态分布方程为

在二维空间定义为
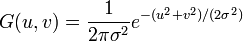
其中r是模糊半径 ( ),σ是正态分布的标准偏差。在二维空间中,这个公式生成的曲面的等高线是从中心开始呈正态分布的同心圆。分布不为零的像素组成的卷积矩阵与原始图像做变换。每个像素的值都是周围相邻像素值的加权平均。原始像素的值有最大的高斯分布值,所以有最大的权重,相邻像素随着距离原始像素越来越远,其权重也越来越小。这样进行模糊处理比其它的均衡模糊滤波器更高地保留了边缘效果,参见尺度空间实现。
),σ是正态分布的标准偏差。在二维空间中,这个公式生成的曲面的等高线是从中心开始呈正态分布的同心圆。分布不为零的像素组成的卷积矩阵与原始图像做变换。每个像素的值都是周围相邻像素值的加权平均。原始像素的值有最大的高斯分布值,所以有最大的权重,相邻像素随着距离原始像素越来越远,其权重也越来越小。这样进行模糊处理比其它的均衡模糊滤波器更高地保留了边缘效果,参见尺度空间实现。
理论上来讲,图像中每点的分布都不为零,这也就是说每个像素的计算都需要包含整幅图像。在实际应用中,在计算高斯函数的离散近似时,在大概3σ距离之外的像素都可以看作不起作用,这些像素的计算也就可以忽略。通常,图像处理程序只需要计算 的矩阵就可以保证相关像素影响。对于边界上的点,通常采用复制周围的点到另一面再进行加权平均运算。
的矩阵就可以保证相关像素影响。对于边界上的点,通常采用复制周围的点到另一面再进行加权平均运算。
除了圆形对称之外,高斯模糊也可以在二维图像上对两个独立的一维空间分别进行计算,这叫作线性可分。这也就是说,使用二维矩阵变换得到的效果也可以通过在水平方向进行一维高斯矩阵变换加上竖直方向的一维高斯矩阵变换得到。从计算的角度来看,这是一项有用的特性,因为这样只需要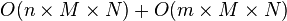 次计算,而不可分的矩阵则需要
次计算,而不可分的矩阵则需要 次计算,其中
次计算,其中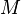 ,
, 是需要进行滤波的图像的维数,
是需要进行滤波的图像的维数, 、
、 是滤波器的维数。
是滤波器的维数。
对一幅图像进行多次连续高斯模糊的效果与一次更大的高斯模糊可以产生同样的效果,大的高斯模糊的半径是所用多个高斯模糊半径平方和的平方根。例如,使用半径分别为6和8的两次高斯模糊变换得到的效果等同于一次半径为10的高斯模糊效果, 。根据这个关系,使用多个连续较小的高斯模糊处理不会比单个高斯较大处理时间要少。
。根据这个关系,使用多个连续较小的高斯模糊处理不会比单个高斯较大处理时间要少。
在减小图像尺寸的场合经常使用高斯模糊。在进行欠采样的时候,通常在采样之前对图像进行低通滤波处理。这样就可以保证在采样图像中不会出现虚假的高频信息。高斯模糊有很好的特性,如没有明显的边界,这样就不会在滤波图像中形成震荡。
以上资料摘自维基百科(高斯模糊词条):
https://zh.wikipedia.org/wiki/%E9%AB%98%E6%96%AF%E6%A8%A1%E7%B3%8A
那么具体如何实现呢?
代码献上:
inline int* buildGaussKern(int winSize, int sigma)
{
int wincenter, x;
float sum = 0.0f;
wincenter = winSize / 2;
float *kern = (float*)malloc(winSize*sizeof(float));
int *ikern = (int*)malloc(winSize*sizeof(int));
float SQRT_2PI = 2.506628274631f;
float sigmaMul2PI = 1.0f / (sigma * SQRT_2PI);
float divSigmaPow2 = 1.0f / (2.0f * sigma * sigma);
for (x = 0; x < wincenter + 1; x++)
{
kern[wincenter - x] = kern[wincenter + x] = exp(-(x * x)* divSigmaPow2) * sigmaMul2PI;
sum += kern[wincenter - x] + ((x != 0) ? kern[wincenter + x] : 0.0);
}
sum = 1.0f / sum;
for (x = 0; x < winSize; x++)
{
kern[x] *= sum;
ikern[x] = kern[x] * 256.0f;
}
free(kern);
return ikern;
}
void GaussBlur(unsigned char* pixels, unsigned int width, unsigned int height, unsigned int channels, int sigma)
{
width = 3 * width;
if ((width % 4) != 0) width += (4 - (width % 4));
unsigned int winsize = (1 + (((int)ceil(3 * sigma)) * 2));
int *gaussKern = buildGaussKern(winsize, sigma);
winsize *= 3;
unsigned int halfsize = winsize / 2;
unsigned char *tmpBuffer = (unsigned char*)malloc(width * height* sizeof(unsigned char));
for (unsigned int h = 0; h < height; h++)
{
unsigned int rowWidth = h * width;
for (unsigned int w = 0; w < width; w += channels)
{
unsigned int rowR = 0;
unsigned int rowG = 0;
unsigned int rowB = 0;
int * gaussKernPtr = gaussKern;
int whalfsize = w + width - halfsize;
unsigned int curPos = rowWidth + w;
for (unsigned int k = 1; k < winsize; k += channels)
{
unsigned int pos = rowWidth + ((k + whalfsize) % width);
int fkern = *gaussKernPtr++;
rowR += (pixels[pos] * fkern);
rowG += (pixels[pos + 1] * fkern);
rowB += (pixels[pos + 2] * fkern);
}
tmpBuffer[curPos] = ((unsigned char)(rowR >> 8));
tmpBuffer[curPos + 1] = ((unsigned char)(rowG >> 8));
tmpBuffer[curPos + 2] = ((unsigned char)(rowB >> 8));
}
}
winsize /= 3;
halfsize = winsize / 2;
for (unsigned int w = 0; w < width; w++)
{
for (unsigned int h = 0; h < height; h++)
{
unsigned int col_all = 0;
int hhalfsize = h + height - halfsize;
for (unsigned int k = 0; k < winsize; k++)
{
col_all += tmpBuffer[((k + hhalfsize) % height)* width + w] * gaussKern[k];
}
pixels[h * width + w] = (unsigned char)(col_all >> 8);
}
}
free(tmpBuffer);
free(gaussKern);
}
备注:
之于原始算法,我做了一些小改动,主要是为了考虑一点点性能上的问题。
有时会写太多注释反而显得啰嗦,所以将就着看哈。
这份代码,实测速度非常糟糕,处理一张5000x3000在半径大小5左右都要耗时十来秒至几十秒不等,实在难以接受。
由于速度的问题,网上就有不少优化算法的实现。
之前我也发过一篇《快速高斯模糊算法》,在同等条件下,这个算法已经比如上算法快上十几倍。
由于这份代码实在难以阅读学习,所以,我对其进行了进一步的调整和优化。
void GaussianBlur(unsigned char* img, unsigned int width, unsigned int height, unsigned int channels, unsigned int radius)
{
radius = min(max(1, radius), 248);
unsigned int kernelSize = 1 + radius * 2;
unsigned int* kernel = (unsigned int*)malloc(kernelSize* sizeof(unsigned int));
memset(kernel, 0, kernelSize* sizeof(unsigned int));
int(*mult)[256] = (int(*)[256])malloc(kernelSize * 256 * sizeof(int));
memset(mult, 0, kernelSize * 256 * sizeof(int));
int xStart = 0;
int yStart = 0;
width = xStart + width - max(0, (xStart + width) - width);
height = yStart + height - max(0, (yStart + height) - height);
int imageSize = width*height;
int widthstep = width*channels;
if (channels == 3 || channels == 4)
{
unsigned char * CacheImg = nullptr;
CacheImg = (unsigned char *)malloc(sizeof(unsigned char) * imageSize * 6);
if (CacheImg == nullptr) return;
unsigned char * rCache = CacheImg;
unsigned char * gCache = CacheImg + imageSize;
unsigned char * bCache = CacheImg + imageSize * 2;
unsigned char * r2Cache = CacheImg + imageSize * 3;
unsigned char * g2Cache = CacheImg + imageSize * 4;
unsigned char * b2Cache = CacheImg + imageSize * 5;
int sum = 0;
for (int K = 1; K < radius; K++){
unsigned int szi = radius - K;
kernel[radius + K] = kernel[szi] = szi*szi;
sum += kernel[szi] + kernel[szi];
for (int j = 0; j < 256; j++){
mult[radius + K][j] = mult[szi][j] = kernel[szi] * j;
}
}
kernel[radius] = radius*radius;
sum += kernel[radius];
for (int j = 0; j < 256; j++){
mult[radius][j] = kernel[radius] * j;
}
for (int Y = 0; Y < height; ++Y) {
unsigned char* LinePS = img + Y*widthstep;
unsigned char* LinePR = rCache + Y*width;
unsigned char* LinePG = gCache + Y*width;
unsigned char* LinePB = bCache + Y*width;
for (int X = 0; X < width; ++X) {
int p2 = X*channels;
LinePR[X] = LinePS[p2];
LinePG[X] = LinePS[p2 + 1];
LinePB[X] = LinePS[p2 + 2];
}
}
int kernelsum = 0;
for (int K = 0; K < kernelSize; K++){
kernelsum += kernel[K];
}
float fkernelsum = 1.0f / kernelsum;
for (int Y = yStart; Y < height; Y++){
int heightStep = Y * width;
unsigned char* LinePR = rCache + heightStep;
unsigned char* LinePG = gCache + heightStep;
unsigned char* LinePB = bCache + heightStep;
for (int X = xStart; X < width; X++){
int cb = 0;
int cg = 0;
int cr = 0;
for (int K = 0; K < kernelSize; K++){
unsigned int readPos = ((X - radius + K + width) % width);
int * pmult = mult[K];
cr += pmult[LinePR[readPos]];
cg += pmult[LinePG[readPos]];
cb += pmult[LinePB[readPos]];
}
unsigned int p = heightStep + X;
r2Cache[p] = cr* fkernelsum;
g2Cache[p] = cg* fkernelsum;
b2Cache[p] = cb* fkernelsum;
}
}
for (int X = xStart; X < width; X++){
int WidthComp = X*channels;
int WidthStep = width*channels;
unsigned char* LinePS = img + X*channels;
unsigned char* LinePR = r2Cache + X;
unsigned char* LinePG = g2Cache + X;
unsigned char* LinePB = b2Cache + X;
for (int Y = yStart; Y < height; Y++){
int cb = 0;
int cg = 0;
int cr = 0;
for (int K = 0; K < kernelSize; K++){
unsigned int readPos = ((Y - radius + K + height) % height) * width;
int * pmult = mult[K];
cr += pmult[LinePR[readPos]];
cg += pmult[LinePG[readPos]];
cb += pmult[LinePB[readPos]];
}
int p = Y*WidthStep;
LinePS[p] = (unsigned char)(cr * fkernelsum);
LinePS[p + 1] = (unsigned char)(cg * fkernelsum);
LinePS[p + 2] = (unsigned char)(cb* fkernelsum);
}
}
free(CacheImg);
}
else if (channels == 1)
{
unsigned char * CacheImg = nullptr;
CacheImg = (unsigned char *)malloc(sizeof(unsigned char) * imageSize * 2);
if (CacheImg == nullptr) return;
unsigned char * rCache = CacheImg;
unsigned char * r2Cache = CacheImg + imageSize;
int sum = 0;
for (int K = 1; K < radius; K++){
unsigned int szi = radius - K;
kernel[radius + K] = kernel[szi] = szi*szi;
sum += kernel[szi] + kernel[szi];
for (int j = 0; j < 256; j++){
mult[radius + K][j] = mult[szi][j] = kernel[szi] * j;
}
}
kernel[radius] = radius*radius;
sum += kernel[radius];
for (int j = 0; j < 256; j++){
mult[radius][j] = kernel[radius] * j;
}
for (int Y = 0; Y < height; ++Y) {
unsigned char* LinePS = img + Y*widthstep;
unsigned char* LinePR = rCache + Y*width;
for (int X = 0; X < width; ++X) {
LinePR[X] = LinePS[X];
}
}
int kernelsum = 0;
for (int K = 0; K < kernelSize; K++){
kernelsum += kernel[K];
}
float fkernelsum = 1.0f / kernelsum;
for (int Y = yStart; Y < height; Y++){
int heightStep = Y * width;
unsigned char* LinePR = rCache + heightStep;
for (int X = xStart; X < width; X++){
int cb = 0;
int cg = 0;
int cr = 0;
for (int K = 0; K < kernelSize; K++){
unsigned int readPos = ( (X - radius + K+width)%width);
int * pmult = mult[K];
cr += pmult[LinePR[readPos]];
}
unsigned int p = heightStep + X;
r2Cache[p] = cr * fkernelsum;
}
}
for (int X = xStart; X < width; X++){
int WidthComp = X*channels;
int WidthStep = width*channels;
unsigned char* LinePS = img + X*channels;
unsigned char* LinePR = r2Cache + X;
for (int Y = yStart; Y < height; Y++){
int cb = 0;
int cg = 0;
int cr = 0;
for (int K = 0; K < kernelSize; K++){
unsigned int readPos = ((Y - radius + K+height)%height) * width;
int * pmult = mult[K];
cr += pmult[LinePR[readPos]];
}
int p = Y*WidthStep;
LinePS[p] = (unsigned char)(cr* fkernelsum);
}
}
free(CacheImg);
}
free(kernel);
free(mult);
}
其中有部分算法优化技巧,想来也能起到一点抛砖引玉的作用。
贴个效果图:

本文只是抛砖引玉一下,若有其他相关问题或者需求也可以邮件联系我探讨。
邮箱地址是:
gaozhihan@vip.qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号