
理解Javascript的状态容器Redux
Redux要解决什么问题?
随着 JavaScript 单页应用开发日趋复杂,JavaScript 需要管理比任何时候都要多的 state (状态)。 这些 state 可能包括服务器响应、缓存数据、本地生成尚未持久化到服务器的数据,也包括 UI 状态,如激活的路由,被选中的标签,是否显示加载动效或者分页器等等。
管理不断变化的 state 非常困难。如果一个 model 的变化会引起另一个 model 变化,那么当 view 变化时,就可能引起对应 model 以及另一个 model 的变化,依次地,可能会引起另一个 view 的变化。直至你搞不清楚到底发生了什么。state 在什么时候,由于什么原因,如何变化已然不受控制。 当系统变得错综复杂的时候,想重现问题或者添加新功能就会变得举步维艰。
Redux的设计借鉴Flux、 Elm、Immutable,它的出现就是为了解决state里的数据问题。Redux和Flux的主要区别是Redux里面是单一的数据源设计,而Flux(或者Reflux)里面有多个数据源。
Redux是如何工作的?
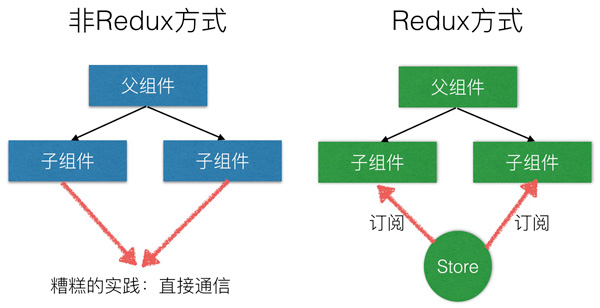
我们知道,在React中,数据在组件中是单向流动的。数据从一个方向父组件流向子组件(通过props),由于这个特征,两个非父子关系的组件(或者称作兄弟组件)之间的通信并不是那么清楚。
React并不建议直接采用组件到组件的通信方式,尽管它有一些特性可以支持这么做(比如先将子组件的值传递给父组件,然后再由父组件在分发给指定的子组件)。这被很多人认为是糟糕的实践方式,因为这样的方式容易出错而且会让代码向“拉面”一样不容易理解。
当然React也没有直接建议如何去处理这种情形,以下是React的文档中关于这部分的描述:
对于非父子关系的组件,你可以自己建立一个全局的事件系统,Flux的模式也是一种可行的方式。
Redux的出现就让这个问题的解决变得更加方便了。Redux提供一种存储整个应用状态到一个地方的解决方案(可以理解为统一状态层),称为“store”,组件将状态的变化转发通知(dispatch)给store,而不是直接通知其它的组件。组件内部依赖的state的变化情况可以通过订阅store来实现。
使用Redux,所有的组件都从store里面获取它们依赖的state,同时也需要将state的变化告知store。组件不需要关注在这个store里面其它组件的state的变化情况,Redux让数据流变得更加简单。这种思想最初来自Flux,它是一种和React相同的单向数据流的设计模式。
Redux的核心设计理念
Redux有三大原则
- 单一数据源,整个应用的 state 被储存在一棵 object tree 中,并且这个 object tree 只存在于唯一一个 store 中
- State 是只读的,惟一改变 state 的方法就是触发 action,action 是一个用于描述已发生事件的普通对象。
- 使用纯函数来执行修改,为了描述 action 如何改变 state tree ,你需要编写 reducers。
单一数据源的设计让React的组件之间的通信更加方便,同时也便于状态的统一管理。
根据Redux的文档,状态变化的唯一方式是触发一个action(一个可以描述发生了什么的对象),这意味着我们不能直接的去修改状态,取而代之的是我们可以通过转发action去告诉store我们有改变状态的意图。store对象提供了非常少的API,仅仅只有4个方法:
store.dispatch(action)
store.subscribe(listener)
store.getState()
replaceReducer(nextReducer)
通过这几个API不难发现,store并没有直接提供setState()方法。
另外,由于它大量使用 pure function 和 plain object 等概念(reducer 和 action creator 是 pure function,state 和 action 是 plain object)这对于项目的稳定性会是非常好的保证。
理解Action、Reducer
一个action的例子:
var action = {
type: 'ADD_USER',
user: {name: 'Dan'}
};
// 假设store对象已经通过Redux.createStore()创建
store.dispatch(action);
这段代码中,通过dispatch() 方法将action传递给了store。Action 本质上是 JavaScript 普通对象。我们约定,action 内必须使用一个字符串类型的 type 字段来表示将要执行的动作。多数情况下,type 会被定义成字符串常量。当应用规模越来越大时,建议使用单独的模块或文件来存放 action。
import { ADD_TODO, REMOVE_TODO } from '../actionTypes'
前面描述过,Redux不允许直接去改变state,必须通过转发action来告诉store有这个意图要去改变这个状态。reducer正是扮演处理转发过来的action的意图的函数并且可以改变状态的角色。一个reducer接受当前的state作为参数,通过返回新的state去改变原有的state:
var someReducer = function(state, action) {
...
return state;
}
由于reducer是纯函数,需要注意:
- 不允许在reducer函数内部进行网络调用或者数据库查询操作
- 不能改变它的参数
这样做的好处是:每次调用同样的一个函数,传入相同的值可以得到相同的结果。对系统的其它部分也不会产生副作用。
第一个Redux store
使用Redux.createStore()来创建一个store,并且将所有的reducers作为参数传递给它,此处以一个reducer为例子:
var userReducer = function(state=[], action) {
if (action.type === 'ADD_USER') {
var newState = state.concat([action.user]);
return newState;
}
return state;
}
// 创建一个store,并且将reducer作为参数传递给它
var store = Redux.createStore(userReducer);
// 将action传递给store,告诉store我们有改变状态的意向
store.dispatch({
type: 'ADD_USER',
user: {name: 'cpselvis'}
});
上述代码运行后发生的事情:
- Store被创建
- reducer确定初始的state的值是空数组
- action被转发给store
- reducer将newUser添加到state中,并且将它返回,更新store
通过这段代码可以发现:reducer函数实际上被执行了2次,一次是store创建的时候,一次是action被转发之后。另外需要注意:Redux希望reducer函数总是返回一个新的状态。这时的结果:
store.getState(); // => [{name: 'cpselvis'}]
通过这个例子,可以总结出Redux的工作流程如图:
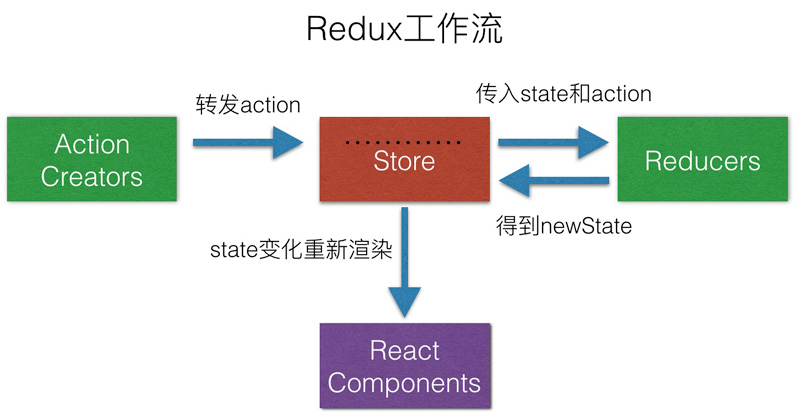
到这里,component -> action -> store -> reducer -> state 的单向数据流的问题就讲完了。概括的说就是:React组件里面获取了数据之后(比如ajax请求),然后创建一个action通知store我有这个想改变state的意图,然后reducers(一个action可能对应多个reducer,可以理解为action为订阅的主题,可能有多个订阅者)来处理这个意图并且返回新的state,接下来store会收集到所有的reducer的state,最后更新state。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号