Swift 值类型和引用类型深度对比
- 值类型和引用类型的概念
- 他们在内存中时如何存储的?
- 值类型和引用类型分别有哪些表现?
- 如果将两者混合使用会怎样?
- 什么时候使用值类型,什么时候使用引用类型?
定义值类型和引用类型
Swift有三种声明类型的方式:class,struct和enum。 它们可以分为值类型(struct和enum)和引用类型(class)。 它们在内存中的存储方式不同决定它们之间的区别:
-
值类型存储在栈区。 每个值类型变量都有其自己的数据副本,并且对一个变量的操作不会影响另一个变量。 -
引用类型存储在其他位置(堆区),我们在内存中有一个指向该位置的引用。 引用类型的变量可以指向相同类型的数据。 因此,对一个变量进行的操作会影响另一变量所指向的数据。
从性能出发
导致Swift结构体(和枚举)与类的性能差异的三个维度是:
- 复制消耗的成本;
- 创建和销毁时花费成本;
- 引用计数造成的成本;
下面我们可能会经常讨论内存,因此请确保你了解什么是内存以及内存是如何存储数据的。
内存段
内存可以理解为字节的集合。字节在内存中有序排列,每个字节都有自己的地址。 所有地址的范围称为地址空间。
iOS应用程序的地址空间在逻辑上由四个部分组成:代码段,数据段,栈区和堆区:
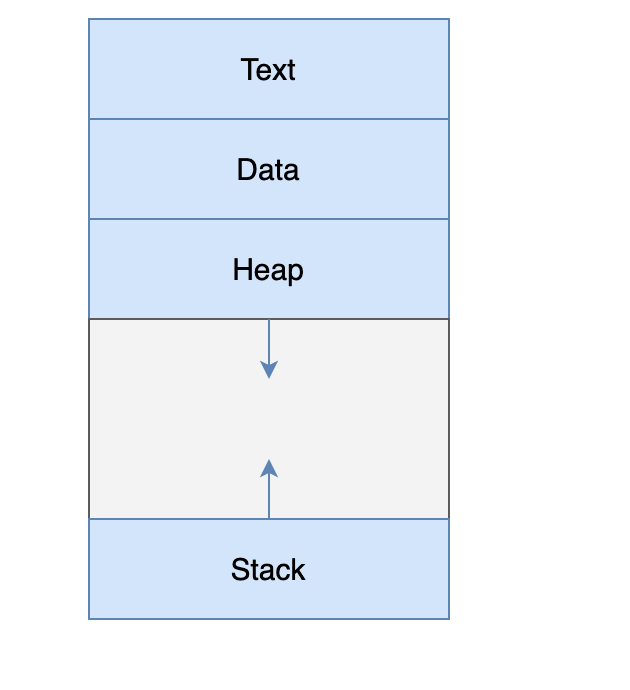
代码段包含构成App可执行代码的机器指令。 它是由编译器通过将Swift代码转换为机器代码而产生的。 该段是只读的,并占用固定不变的空间。
数据段存储Swift静态变量,常量和类型元数据。 程序启动时所有需要初始值的全局数据都在此处。
栈区存储临时数据:方法的参数和局部变量。 每次我们调用一个方法时,都会在栈上分配一块新的内存。 该方法退出时,将释放该内存。 除特殊情况(下面会讲),所有Swift值类型都在此处。
堆区存储具有生存期的对象。 这些都是Swift引用类型,还有一些值类型的情况。 堆和栈朝着彼此增长堆区的分配一般按照地址从小到大进行,而栈区的分配一般按照地址从大到小进行分配。
一般Swift值类型在栈上分配。 引用类型在堆上分配。
现在,我们已经研究了内存段的工作原理,让我们来看一下内存中的内容是如何存储的。
堆与栈分配的成本
栈区内存分配和销毁的工作原理与数据结构中的栈相同。 你只能从栈顶压栈或出栈。 指向栈顶的指针足以实现这两个操作。 因此,栈指针可以腾出空间来分配其他更多的内存。 当函数执行完退出时,我们将栈指针增加到调用此方法之前的位置。(为什么增加才能回到调用之前的地址,刚说了栈是从大到小进行分配的)
栈分配和释放的成本相当于整数复制的成本【WWDC-416】
堆分配过程涉及的东西很多。 我们必须搜索堆区以找到适合它大小的空内存块。 我们还必须同步堆,因为多个线程可能同时在其中分配内存。 为了从堆中释放内存,我们必须将该内存重新插入适当的位置。
堆分配和释放的成本比栈要大得多
通常值类型和引用类型分别在栈和堆上分配,但是这个规则有一些例外情况需要注意。
Swift 引用类型关于栈的优化
当引用类型的大小固定或可以预测生存期的时候,Swift编译器可能会将引用类型分配到栈中。 这种优化发生在SIL生成阶段。
Swift中间语言(SIL)是Swift特有的高级中间语言,用于对Swift代码的进一步分析和优化。
下面是我通过阅读Swift编译器源代码发现的示例。
- predictable memory optimization github.com/apple/swift…
- closure capture promotion github.com/apple/swift…
- boxed values promotion github.com/apple/swift…
Swift值类型 -- 装箱
Swift编译器可以将值类型装箱后放到堆上。 我通过阅读Swift编译器源代码来列出了会出现的几种情况。
在以下情况,值类型会被装箱:
-
当值类型遵循了某个协议
当值类型遵循了某个协议,且存储在existential(存在性)容器中超过3个机器字长时,除分配成本外,还会产生额外的开销。
Existential(存在性)容器是用于存储运行时未知类型的值的一种通用容器。 较小的值类型可以内嵌在存在性(existential)容器中。 较大的分配在堆上, 它们的引用存储在存在性(existential)容器缓冲区内。 此类值的生存期由
值见证表(Value Witness Table)管理。 当调用协议方法时会产生引用计数和几个间接级别的开销。值见证表(Value Witness Table): 一种运行时结构,用于描述如何对未知值进行“ assign”,“ copy”和“ destroy”基本操作。 (例如,复制此值是否需要保留?)
详解见官方:github.com/apple/swift…
让我们看看生成的SIL代码他们是如何装箱的。 我们声明一个协议
Bar和一个符合它的结构体Baz:复制代码`protocol Bar {} struct Baz: Bar {}`Swift文件转换成SIL语言的命令是:
复制代码`swiftc -emit-silgen -O main.swift`输出显示self被装在init()中:
复制代码`protocol Bar { } struct Baz : Bar { init() } // Baz.init() sil hidden [ossa] @$s6boxing3BazVACycfC : $@convention(method) (@thin Baz.Type) -> Baz { bb0(%0 : $@thin Baz.Type): %1 = alloc_box ${ var Baz }, var, name "self" // user: %2 ... }` -
值类型和引用类型混合时
结构体中包含类,类中包含结构的情况很常见:
复制代码`// Class inside a struct class A {} struct B { let a = A() } // Struct inside a class struct C {} class D { let c = C() }`SIL输出显示,在两种情况下,结构B和C都分配在堆上:复制代码`// B.init() sil hidden [ossa] @$s6boxing1BVACycfC : $@convention(method) (@thin B.Type) -> @owned B { bb0(%0 : $@thin B.Type): %1 = alloc_box ${ var B }, var, name "self" // user: %2 ... } // C.init() sil hidden [ossa] @$s6boxing1CVACycfC : $@convention(method) (@thin C.Type) -> C { bb0(%0 : $@thin C.Type): %1 = alloc_box ${ var C }, var, name "self" // user: %2 ... }` -
带有泛型的值类型。
让我们声明一个带泛型的结构体:
复制代码`struct Bas<T> { var x: T init(xx: T) { x = xx } }`SIL输出显示self被装在init(xx :)中:复制代码`// Bas.init(xx:) bb0(%0 : $*Bas<T>, %1 : $*T, %2 : $@thin Bas<T>.Type): %3 = alloc_box $<τ_0_0> { var Bas<τ_0_0> } <T>, var, name "self" // user: %4 .... }` -
逃避闭包捕获时。
Swift的闭包对所有局部变量都是通过引用来捕获的。 如CapturePromotion中所述,有些可能仍被放在栈中。
CapturePromotion github.com/apple/swift…
-
Inout参数
让我们为
foo(x :)生成一个接受inout参数的SIL:复制代码`func foo(x: inout Int) { x += 1 }`SIL输出显示foo(x :)正在装箱:
复制代码`// foo(x:) sil hidden [ossa] @$s6boxing3foo1xySiz_tF : $@convention(thin) (@inout Int) -> () { // %0 // users: %7, %1 bb0(%0 : $*Int): ... }`
复制的成本
众所周知,大多数值类型都分配在栈上的,复制它们需要花费固定的时间。 复制操作速度快的原因是整数和浮点数等基本数据类型存储在CPU寄存器中,复制它们时无需访问RAM内存。 Swift的大多数可扩展类型(例如字符串,数组,集合和字典)都在写入时被复制了( copied on write)。 这意味着复制操作消耗很小。
由于引用类型不会直接存储其数据,因此我们在复制它们时只会产生引用计数成本。 引用计数的增加和减少不像整数变化那么简单,还需要额外的花销。因为堆可能同时被多个线程共享,为了保持原子性也需要额外花销。
当我们混合使用值和引用类型时,事情变得很有趣。 如果结构体或枚举包含引用类型时,它们需要的引用计数开销与他们包含引用类型的数量成正比。 下面的代码示例可以最好地证明这一点。 让我们创建一个拥有引用类型属性的结构体和一个具有引用类型属性的类,并打印他们的引用计数。
复制代码`class Ref {}
// Struct with references
struct MyStruct {
let ref1 = Ref()
let ref2 = Ref()
}
// Class with references
class MyClass {
let ref1 = Ref()
let ref2 = Ref()
}`
让我们为MyStruct打印引用计数:
复制代码`let a = MyStruct()
let anotherA = a
print("self:", CFGetRetainCount(a as CFTypeRef))
print("ref1:", CFGetRetainCount(a.ref1))
print("ref1:", CFGetRetainCount(a.ref2))`
打印结果:
复制代码`self: 1
ref1: 2
ref1: 2`
再来看看MyClass:
复制代码`let b = MyClass()
let anotherB = b
print("self:", CFGetRetainCount(b))
print("ref1:", CFGetRetainCount(b.ref1))
print("ref1:", CFGetRetainCount(b.ref2))`
打印:
复制代码`self: 2
ref1: 1
ref1: 1`
输出显示MyStruct结构体产生了两倍的引用计数成本😱。
结构体和类的选择
对于应该使用类还是结构,没有简单的答案。 尽管苹果建议在对具有标识(identity)的东西使用类,其他情况使用结构,但这不足以指导我们做出决定。 由于每种情况都不同,我们还需要虑性能:
- 应当避免值类型包含引用类型的变量,因为它们违反了值的语义并产生额外的引用计数开销。
- 具有动态行为的值类型(例如数组和字符串)应采用
copy-on-write来摊销复制成本。 - 值类型遵循协议时将被装箱,从而导致更高的创建成本。
我们应该尽量避免以上情况的发生,除此之外可以根据你的需求选择合适的类型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号