C++语法
原文地址 zhuanlan.zhihu.com
C++语法

目录收起命名空间:namespace内联函数使用对象指针构造函数初始化列表析构函数(Destructor)thisthis 到底是什么友元函数:friend友元函数可以访问当前类中的所有成员,包括 public、protected、private 属性的。成员函数在调用时会隐式地增加 this 指针,指向调用它的对象,从而使用该对象的成员;而 show() 是非成员函数,没有 this 指针,编译器不知道使用哪个对象的成员,要想明确这一点,就必须通过参数传递对象(可以直接传递对象,也可以传递对象指针或对象引用),并在访问成员时指明对象。2) 将其他类的成员函数声明为友元函数友元类class和struct区别总结C++引用C++引用作为函数参数C++引用作为函数返回值继承和派生三种继承方式public、protected、private 修饰类的成员public、protected、private 指定继承方式改变访问权限基类成员函数和派生类成员函数不构成重载将派生类赋值给基类(向上转型)向上转型非常安全,可以由编译器自动完成;向下转型有风险,需要程序员手动干预。本节只介绍向上转型,向下转型将在后续章节介绍。向上转型和向下转型是面向对象编程的一种通用概念,它们也存在于 Java、C# 等编程语言中。将派生类对象赋值给基类对象将派生类指针赋值给基类指针多态和虚函数:virtual多态的用途虚函数注意事项以及构成多态的条件构成多态的条件什么时候声明虚函数纯虚函数和抽象类抽象基类除了约束派生类的功能,还可以实现多态。请注意第 51 行代码,指针 p 的类型是 Line,但是它却可以访问派生类中的 area() 和 volume() 函数,正是由于在 Line 类中将这两个函数定义为纯虚函数;如果不这样做,51 行后面的代码都是错误的。我想,这或许才是C++提供纯虚函数的主要目的。关于纯虚函数的几点说明typeid运算符:获取类型信息C++ 标准规定,type_info 类至少要有如下所示的 4 个 public 属性的成员函数,其他的扩展函数编译器开发者可以自由发挥,不做限制。可以发现,不像 Java、C# 等动态性较强的语言,C++ 能获取到的类型信息非常有限,也没有统一的标准,如同“鸡肋”一般,大部分情况下我们只是使用重载过的“==”运算符来判断两个类型是否相同。判断类型是否相等typeid 运算符经常被用来判断两个类型是否相等。1) 内置类型的比较需要提醒的是,为了减小编译后文件的体积,编译器不会为所有的类型创建 type_info 对象,只会为使用了 typeid 运算符的类型创建。不过有一种特殊情况,就是带虚函数的类(包括继承来的),不管有没有使用 typeid 运算符,编译器都会为带虚函数的类创建 type_info 对象,我们将在《C++ RTTI机制精讲(C++运行时类型识别机制)》中展开讲解。2) 类的比较type_info 类的声明运算符重载:operator在全局范围内重载运算符小结函数模板:template类模板使用类模板创建对象综合示例模板编程:泛型2) 弱类型语言拷贝构造函数(复制构造函数)默认拷贝构造函数深拷贝和浅拷贝(深复制和浅复制)到底是浅拷贝还是深拷贝重载=(赋值运算符)lambdaexplicit关键字C++ 信号处理
命名空间:namespace
一个中大型软件往往由多名程序员共同开发,会使用大量的变量和函数,不可避免地会出现变量或函数的命名冲突。当所有人的代码都测试通过,没有问题时,将它们结合到一起就有可能会出现命名冲突。
例如小李和小韩都参与了一个文件管理系统的开发,它们都定义了一个全局变量 fp,用来指明当前打开的文件,将他们的代码整合在一起编译时,很明显编译器会提示 fp 重复定义(Redefinition)错误。
- 为了解决合作开发时的命名冲突问题,C++ 引入了命名空间(Namespace)的概念。请看下面的例子:namespace Li{ //小李的变量定义
- FILE* fp = NULL;
- }
- namespace Han{ //小韩的变量定义
- FILE* fp = NULL;
- }
小李与小韩各自定义了以自己姓氏为名的命名空间,此时再将他们的 fp 变量放在一起编译就不会有任何问题。命名空间有时也被称为名字空间、名称空间。namespace 是C++中的关键字,用来定义一个命名空间,语法格式为:namespace name{
//variables, functions, classes
}name是命名空间的名字,它里面可以包含变量、函数、类、typedef、#define 等,最后由{ }包围。
- 使用变量、函数时要指明它们所在的命名空间。以上面的 fp 变量为例,可以这样来使用:Li::fp = fopen("one.txt", "r"); //使用小李定义的变量 fp
- Han::fp = fopen("two.txt", "rb+"); //使用小韩定义的变量 fp
::是一个新符号,称为域解析操作符,在C++中用来指明要使用的命名空间。
- 除了直接使用域解析操作符,还可以采用 using 关键字声明,例如:using Li::fp;
- fp = fopen("one.txt", "r"); //使用小李定义的变量 fp
- Han :: fp = fopen("two.txt", "rb+"); //使用小韩定义的变量 fp
在代码的开头用using声明了 Li::fp,它的意思是,using 声明以后的程序中如果出现了未指明命名空间的 fp,就使用 Li::fp;但是若要使用小韩定义的 fp,仍然需要 Han::fp。
using 声明不仅可以针对命名空间中的一个变量,也可以用于声明整个命名空间,例如:
- using namespace Li;
- fp = fopen("one.txt", "r"); //使用小李定义的变量 fp
- Han::fp = fopen("two.txt", "rb+"); //使用小韩定义的变量 fp
如果命名空间 Li 中还定义了其他的变量,那么同样具有 fp 变量的效果。在 using 声明后,如果有未具体指定命名空间的变量产生了命名冲突,那么默认采用命名空间 Li 中的变量。
命名空间内部不仅可以声明或定义变量,对于其它能在命名空间以外声明或定义的名称,同样也都能在命名空间内部进行声明或定义,例如类、函数、typedef、#define 等都可以出现在命名空间中。
站在编译和链接的角度,代码中出现的变量名、函数名、类名等都是一种符号(Symbol)。有的符号可以指代一个内存位置,例如变量名、函数名;有的符号仅仅是一个新的名称,例如 typedef 定义的类型别名。
-
include <stdio.h>
- //将类定义在命名空间中
- namespace Diy{
- class Student{
- public:
- char *name;
- int age;
- float score;
- public:
- void say(){
- printf("%s的年龄是 %d,成绩是 %f\n", name, age, score);
- }
- };
- }
- int main(){
- Diy::Student stu1;
- stu1.name = "小明";
- stu1.age = 15;
- stu1.score = 92.5f;
- stu1.say();
- return 0;
- }
运行结果:
小明的年龄是 15,成绩是 92.500000
C++ 命名空间的语法比较复杂,本节所讲到的只是冰山一角,主要是为下节《C++头文件和std命名空间》的讲解打基础。关于命名空间的更多内容我们将在后续章节中一一讲解。
内联函数
函数是一个可以重复使用的代码块,CPU 会一条一条地挨着执行其中的代码。CPU 在执行主调函数代码时如果遇到了被调函数,主调函数就会暂停,CPU 转而执行被调函数的代码;被调函数执行完毕后再返回到主调函数,主调函数根据刚才的状态继续往下执行。
一个 C/C++ 程序的执行过程可以认为是多个函数之间的相互调用过程,它们形成了一个或简单或复杂的调用链条,这个链条的起点是 main(),终点也是 main()。当 main() 调用完了所有的函数,它会返回一个值(例如return 0;)来结束自己的生命,从而结束整个程序。
函数调用是有时间和空间开销的。程序在执行一个函数之前需要做一些准备工作,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码;函数体中的代码执行完毕后还要清理现场,将之前压入栈中的数据都出栈,才能接着执行函数调用位置以后的代码。关于函数调用的细节,我们已经在《C语言内存精讲》一章中的《一个函数在栈上到底是怎样的》《用一个实例来深入剖析函数进栈出栈的过程》两节中讲到。
如果函数体代码比较多,需要较长的执行时间,那么函数调用机制占用的时间可以忽略;如果函数只有一两条语句,那么大部分的时间都会花费在函数调用机制上,这种时间开销就就不容忽视。
为了消除函数调用的时空开销,C++ 提供一种提高效率的方法,即在编译时将函数调用处用函数体替换,类似于C语言中的宏展开。这种在函数调用处直接嵌入函数体的函数称为内联函数(Inline Function),又称内嵌函数或者内置函数。
- 指定内联函数的方法很简单,只需要在函数定义处增加 inline 关键字。请看下面的例子:#include
- using namespace std;
- //内联函数,交换两个数的值
- inline void swap(int *a, int *b){
- int temp;
- temp = *a;
- *a = *b;
- *b = temp;
- }
- int main(){
- int m, n;
- cin>>m>>n;
- cout<<m<<", "<<n<<endl;
- swap(&m, &n);
- cout<<m<<", "<<n<<endl;
- return 0;
- }
运行结果:
45 99↙
45, 99
99, 45
注意,要在函数定义处添加 inline 关键字,在函数声明处添加 inline 关键字虽然没有错,但这种做法是无效的,编译器会忽略函数声明处的 inline 关键字。 - 当编译器遇到函数调用swap(&m, &n)时,会用 swap() 函数的代码替换swap(&m, &n),同时用实参代替形参。这样,程序第 16 行就被置换成:int temp;
- temp = *(&m);
- *(&m) = *(&n);
- *(&n) = temp;
编译器可能会将 (&m)、(&n) 分别优化为 m、n。
当函数比较复杂时,函数调用的时空开销可以忽略,大部分的 CPU 时间都会花费在执行函数体代码上,所以我们一般是将非常短小的函数声明为内联函数。 - 由于内联函数比较短小,我们通常的做法是省略函数原型,将整个函数定义(包括函数头和函数体)放在本应该提供函数原型的地方。下面的例子是一个反面教材,这样的写法是不被推荐的:#include
- using namespace std;
- //声明内联函数
- void swap1(int *a, int *b); //也可以添加inline,但编译器会忽略
- int main(){
- int m, n;
- cin>>m>>n;
- cout<<m<<", "<<n<<endl;
- swap1(&m, &n);
- cout<<m<<", "<<n<<endl;
- return 0;
- }
- //定义内联函数
- inline void swap1(int *a, int *b){
- int temp;
- temp = *a;
- *a = *b;
- *b = temp;
- }
使用内联函数的缺点也是非常明显的,编译后的程序会存在多份相同的函数拷贝,如果被声明为内联函数的函数体非常大,那么编译后的程序体积也将会变得很大,所以再次强调,一般只将那些短小的、频繁调用的函数声明为内联函数
new 和 delete - 在C语言中,动态分配内存用 malloc() 函数,释放内存用 free() 函数。如下所示:int p = (int) malloc( sizeof(int) * 10 ); //分配10个int型的内存空间
- free(p); //释放内存
在C++中,这两个函数仍然可以使用,但是C++又新增了两个关键字,new 和 delete:new 用来动态分配内存,delete 用来释放内存。
- 用 new 和 delete 分配内存更加简单:int *p = new int; //分配1个int型的内存空间
- delete p; //释放内存
new 操作符会根据后面的数据类型来推断所需空间的大小。
- 如果希望分配一组连续的数据,可以使用 new[]:int *p = new int[10]; //分配10个int型的内存空间
- delete[] p;
用 new[] 分配的内存需要用 delete[] 释放,它们是一一对应的。
和 malloc() 一样,new 也是在堆区分配内存,必须手动释放,否则只能等到程序运行结束由操作系统回收。为了避免内存泄露,通常 new 和 delete、new[] 和 delete[] 操作符应该成对出现,并且不要和C语言中 malloc()、free() 一起混用。
在C++中,建议使用 new 和 delete 来管理内存,它们可以使用C++的一些新特性,最明显的是可以自动调用构造函数和析构函数
使用对象指针
C语言中经典的指针在 C++ 中仍然广泛使用,尤其是指向对象的指针,没有它就不能实现某些功能。
上面代码中创建的对象 stu 在栈上分配内存,需要使用&获取它的地址,例如:
- Student stu;
- Student *pStu = &stu;
pStu 是一个指针,它指向 Student 类型的数据,也就是通过 Student 创建出来的对象。
- 当然,你也可以在堆上创建对象,这个时候就需要使用前面讲到的new关键字(C++ new和delete运算符简介),例如:Student *pStu = new Student;
在栈上创建出来的对象都有一个名字,比如 stu,使用指针指向它不是必须的。但是通过 new 创建出来的对象就不一样了,它在堆上分配内存,没有名字,只能得到一个指向它的指针,所以必须使用一个指针变量来接收这个指针,否则以后再也无法找到这个对象了,更没有办法使用它。也就是说,使用 new 在堆上创建出来的对象是匿名的,没法直接使用,必须要用一个指针指向它,再借助指针来访问它的成员变量或成员函数。
- 栈内存是程序自动管理的,不能使用 delete 删除在栈上创建的对象;堆内存由程序员管理,对象使用完毕后可以通过 delete 删除。在实际开发中,new 和 delete 往往成对出现,以保证及时删除不再使用的对象,防止无用内存堆积。栈(Stack)和堆(Heap)是 C/C++ 程序员必须要了解的两个概念,我们已在《C语言内存精讲》专题中进行了深入讲解,相信你必将有所顿悟。有了对象指针后,可以通过箭头->来访问对象的成员变量和成员函数,这和通过结构体指针来访问它的成员类似,请看下面的示例:pStu -> name = "小明";
- pStu -> age = 15;
- pStu -> score = 92.5f;
- pStu -> say();
-
include
- using namespace std;
- class Student{
- public:
- char *name;
- int age;
- float score;
- void say(){
- cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
- }
- };
- int main(){
- Student *pStu = new Student;
- pStu -> name = "小明";
- pStu -> age = 15;
- pStu -> score = 92.5f;
- pStu -> say();
- delete pStu; //删除对象
- return 0;
- }
运行结果:
小明的年龄是15,成绩是92.5
虽然在一般的程序中无视垃圾内存影响不大,但记得 delete 掉不再使用的对象依然是一种良好的编程习惯。
构造函数
C++通过 public、protected、private 三个关键字来控制成员变量和成员函数的访问权限,它们分别表示公有的、受保护的、私有的,被称为成员访问限定符。所谓访问权限,就是你能不能使用该类中的成员。Java、C# 程序员注意,C++ 中的 public、private、protected 只能修饰类的成员,不能修饰类,C++中的类没有共有私有之分。
在C++中,有一种特殊的成员函数,它的名字和类名相同,没有返回值,不需要用户显式调用(用户也不能调用),而是在创建对象时自动执行。这种特殊的成员函数就是构造函数(Constructor)。
- 在《C++类成员的访问权限以及类的封装》一节中,我们通过成员函数 setname()、setage()、setscore() 分别为成员变量 name、age、score 赋值,这样做虽然有效,但显得有点麻烦。有了构造函数,我们就可以简化这项工作,在创建对象的同时为成员变量赋值,请看下面的代码(示例1):#include
- using namespace std;
- class Student{
- private:
- char *m_name;
- int m_age;
- float m_score;
- public:
- //声明构造函数
- Student(char *name, int age, float score);
- //声明普通成员函数
- void show();
- };
- //定义构造函数
- Student::Student(char *name, int age, float score){
- m_name = name;
- m_age = age;
- m_score = score;
- }
- //定义普通成员函数
- void Student::show(){
- cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
- }
- int main(){
- //创建对象时向构造函数传参
- Student stu("小明", 15, 92.5f);
- stu.show();
- //创建对象时向构造函数传参
- Student *pstu = new Student("李华", 16, 96);
- pstu -> show();
- return 0;
- }
运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
该例在 Student 类中定义了一个构造函数Student(char *, int, float),它的作用是给三个 private 属性的成员变量赋值。要想调用该构造函数,就得在创建对象的同时传递实参,并且实参由( )包围,和普通的函数调用非常类似。
在栈上创建对象时,实参位于对象名后面,例如Student stu("小明", 15, 92.5f);在堆上创建对象时,实参位于类名后面,例如new Student("李华", 16, 96)。
构造函数必须是 public 属性的,否则创建对象时无法调用。当然,设置为 private、protected 属性也不会报错,但是没有意义。
构造函数没有返回值,因为没有变量来接收返回值,即使有也毫无用处,这意味着:
- 不管是声明还是定义,函数名前面都不能出现返回值类型,即使是 void 也不允许;
- 函数体中不能有 return 语句。
初始化列表
构造函数的一项重要功能是对成员变量进行初始化,为了达到这个目的,可以在构造函数的函数体中对成员变量一一赋值,还可以采用初始化列表。
- C++构造函数的初始化列表使得代码更加简洁,请看下面的例子:#include
- using namespace std;
- class Student{
- private:
- char *m_name;
- int m_age;
- float m_score;
- public:
- Student(char *name, int age, float score);
- void show();
- };
- //采用初始化列表
- Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){
- //TODO:
- }
- void Student::show(){
- cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
- }
- int main(){
- Student stu("小明", 15, 92.5f);
- stu.show();
- Student *pstu = new Student("李华", 16, 96);
- pstu -> show();
- return 0;
- }
运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
如本例所示,定义构造函数时并没有在函数体中对成员变量一一赋值,其函数体为空(当然也可以有其他语句),而是在函数首部与函数体之间添加了一个冒号:,后面紧跟m_name(name), m_age(age), m_score(score)语句,这个语句的意思相当于函数体内部的m_name = name; m_age = age; m_score = score;语句,也是赋值的意思。
使用构造函数初始化列表并没有效率上的优势,仅仅是书写方便,尤其是成员变量较多时,这种写法非常简单明了。
- 初始化列表可以用于全部成员变量,也可以只用于部分成员变量。下面的示例只对 m_name 使用初始化列表,其他成员变量还是一一赋值:Student::Student(char *name, int age, float score): m_name(name){
- m_age = age;
- m_score = score;
- }
- 注意,成员变量的初始化顺序与初始化列表中列出的变量的顺序无关,它只与成员变量在类中声明的顺序有关。请看代码:#include
- using namespace std;
- class Demo{
- private:
- int m_a;
- int m_b;
- public:
- Demo(int b);
- void show();
- };
- Demo::Demo(int b): m_b(b), m_a(m_b)
- void Demo::show()
- int main(){
- Demo obj(100);
- obj.show();
- return 0;
- }
运行结果:
2130567168, 100
- 在初始化列表中,我们将 m_b 放在了 m_a 的前面,看起来是先给 m_b 赋值,再给 m_a 赋值,其实不然!成员变量的赋值顺序由它们在类中的声明顺序决定,在 Demo 类中,我们先声明的 m_a,再声明的 m_b,所以构造函数和下面的代码等价:Demo::Demo(int b): m_b(b), m_a(m_b){
- m_a = m_b;
- m_b = b;
- }
给 m_a 赋值时,m_b 还未被初始化,它的值是不确定的,所以输出的 m_a 的值是一个奇怪的数字;给 m_a 赋值完成后才给 m_b 赋值,此时 m_b 的值才是 100。obj 在栈上分配内存,成员变量的初始值是不确定的。初始化 const 成员变量
- 构造函数初始化列表还有一个很重要的作用,那就是初始化 const 成员变量。初始化 const 成员变量的唯一方法就是使用初始化列表。例如 VS/VC 不支持变长数组(数组长度不能是变量),我们自己定义了一个 VLA 类,用于模拟变长数组,请看下面的代码:class VLA{
- private:
- const int m_len;
- int *m_arr;
- public:
- VLA(int len);
- };
- //必须使用初始化列表来初始化 m_len
- VLA::VLA(int len): m_len(len){
- m_arr = new int[len];
- }
VLA 类包含了两个成员变量,m_len 和 m_arr 指针,需要注意的是 m_len 加了 const 修饰,只能使用初始化列表的方式赋值,如果写作下面的形式是错误的:纯文本复制
- class VLA{
- private:
- const int m_len;
- int *m_arr;
- public:
- VLA(int len);
- };
- VLA::VLA(int len){
- m_len = len;
- m_arr = new int[len];
- }
析构函数(Destructor)
创建对象时系统会自动调用构造函数进行初始化工作,同样,销毁对象时系统也会自动调用一个函数来进行清理工作,例如释放分配的内存、关闭打开的文件等,这个函数就是析构函数。
析构函数(Destructor)也是一种特殊的成员函数,没有返回值,不需要程序员显式调用(程序员也没法显式调用),而是在销毁对象时自动执行。构造函数的名字和类名相同,而析构函数的名字是在类名前面加一个~符号。
注意:析构函数没有参数,不能被重载,因此一个类只能有一个析构函数。如果用户没有定义,编译器会自动生成一个默认的析构函数。
- 上节我们定义了一个 VLA 类来模拟变长数组,它使用一个构造函数为数组分配内存,这些内存在数组被销毁后不会自动释放,所以非常有必要再添加一个析构函数,专门用来释放已经分配的内存。请看下面的完整示例:#include
- using namespace std;
- class VLA{
- public:
- VLA(int len); //构造函数
- ~VLA(); //析构函数
- public:
- void input(); //从控制台输入数组元素
- void show(); //显示数组元素
- private:
- int *at(int i); //获取第i个元素的指针
- private:
- const int m_len; //数组长度
- int *m_arr; //数组指针
- int *m_p; //指向数组第i个元素的指针
- };
- VLA::VLA(int len): m_len(len){ //使用初始化列表来给 m_len 赋值
- if(len > 0){ m_arr = new int[len]; /分配内存/ }
- else
- }
- VLA::~VLA(){
- delete[] m_arr; //释放内存
- }
- void VLA::input(){
- for(int i=0; m_p=at(i); i++)
- }
- void VLA::show(){
- for(int i=0; m_p=at(i); i++){
- if(i == m_len - 1)
- else
- }
- }
- int * VLA::at(int i){
- if(!m_arr || i<0 || i>=m_len){ return NULL; }
- else{ return m_arr + i; }
- }
- int main(){
- //创建一个有n个元素的数组(对象)
- int n;
- cout<<"Input array length: ";
- cin>>n;
- VLA *parr = new VLA(n);
- //输入数组元素
- cout<<"Input "<<n<<" numbers: ";
- parr -> input();
- //输出数组元素
- cout<<"Elements: ";
- parr -> show();
- //删除数组(对象)
- delete parr;
- return 0;
- }
运行结果:
Input array length: 5
Input 5 numbers: 99 23 45 10 100
Elements: 99, 23, 45, 10, 100
~VLA()就是 VLA 类的析构函数,它的唯一作用就是在删除对象(第 53 行代码)后释放已经分配的内存。
函数名是标识符的一种,原则上标识符的命名中不允许出现符号,在析构函数的名字中出现的可以认为是一种特殊情况,目的是为了和构造函数的名字加以对比和区分。
注意:at() 函数只在类的内部使用,所以将它声明为 private 属性;m_len 变量不允许修改,所以用 const 进行了限制,这样就只能使用初始化列表来进行赋值。
C++ 中的 new 和 delete 分别用来分配和释放内存,它们与C语言中 malloc()、free() 最大的一个不同之处在于:用 new 分配内存时会调用构造函数,用 delete 释放内存时会调用析构函数。构造函数和析构函数对于类来说是不可或缺的,所以在C++中我们非常鼓励使用 new 和 delete。
析构函数的执行时机
析构函数在对象被销毁时调用,而对象的销毁时机与它所在的内存区域有关。不了解内存分区的读者请阅读《C语言内存精讲》专题。
在所有函数之外创建的对象是全局对象,它和全局变量类似,位于内存分区中的全局数据区,程序在结束执行时会调用这些对象的析构函数。
在函数内部创建的对象是局部对象,它和局部变量类似,位于栈区,函数执行结束时会调用这些对象的析构函数。
new 创建的对象位于堆区,通过 delete 删除时才会调用析构函数;如果没有 delete,析构函数就不会被执行。
-
include
-
include
- using namespace std;
- class Demo{
- public:
- Demo(string s);
- ~Demo();
- private:
- string m_s;
- };
- Demo::Demo(string s): m_s(s)
- Demo::~Demo()
- void func(){
- //局部对象
- Demo obj1("1");
- }
- //全局对象
- Demo obj2("2");
- int main(){
- //局部对象
- Demo obj3("3");
- //new创建的对象
- Demo *pobj4 = new Demo("4");
- func();
- cout<<"main"<<endl;
- return 0;
- }
运行结果:
1
main
3
2
this
this 是 C++ 中的一个关键字,也是一个 const 指针,它指向当前对象,通过它可以访问当前对象的所有成员。
所谓当前对象,是指正在使用的对象。例如对于stu.show();,stu 就是当前对象,this 就指向 stu。
- 下面是使用 this 的一个完整示例:#include
- using namespace std;
- class Student{
- public:
- void setname(char *name);
- void setage(int age);
- void setscore(float score);
- void show();
- private:
- char *name;
- int age;
- float score;
- };
- void Student::setname(char *name){
- this->name = name;
- }
- void Student::setage(int age){
- this->age = age;
- }
- void Student::setscore(float score){
- this->score = score;
- }
- void Student::show(){
- cout<<this->name<<"的年龄是"<<this->age<<",成绩是"<<this->score<<endl;
- }
- int main(){
- Student *pstu = new Student;
- pstu -> setname("李华");
- pstu -> setage(16);
- pstu -> setscore(96.5);
- pstu -> show();
- return 0;
- }
运行结果:
李华的年龄是16,成绩是96.5
this 只能用在类的内部,通过 this 可以访问类的所有成员,包括 private、protected、public 属性的。
本例中成员函数的参数和成员变量重名,只能通过 this 区分。以成员函数setname(char *name)为例,它的形参是name,和成员变量name重名,如果写作name = name;这样的语句,就是给形参name赋值,而不是给成员变量name赋值。而写作this -> name = name;后,=左边的name就是成员变量,右边的name就是形参,一目了然。
注意,this 是一个指针,要用->来访问成员变量或成员函数。
this 虽然用在类的内部,但是只有在对象被创建以后才会给 this 赋值,并且这个赋值的过程是编译器自动完成的,不需要用户干预,用户也不能显式地给 this 赋值。本例中,this 的值和 pstu 的值是相同的。
- 我们不妨来证明一下,给 Student 类添加一个成员函数printThis(),专门用来输出 this 的值,如下所示:void Student::printThis(){
- cout<<this<<endl;
- }
- 然后在 main() 函数中创建对象并调用 printThis():Student *pstu1 = new Student;
- pstu1 -> printThis();
- cout<<pstu1<<endl;
- Student *pstu2 = new Student;
- pstu2 -> printThis();
- cout<<pstu2<<endl;
运行结果:
0x7b17d8
0x7b17d8
0x7b17f0
0x7b17f0
可以发现,this 确实指向了当前对象,而且对于不同的对象,this 的值也不一样。
- 几点注意:this 是 const 指针,它的值是不能被修改的,一切企图修改该指针的操作,如赋值、递增、递减等都是不允许的。
- this 只能在成员函数内部使用,用在其他地方没有意义,也是非法的。
- 只有当对象被创建后 this 才有意义,因此不能在 static 成员函数中使用(后续会讲到 static 成员)。
this 到底是什么
this 实际上是成员函数的一个形参,在调用成员函数时将对象的地址作为实参传递给 this。不过 this 这个形参是隐式的,它并不出现在代码中,而是在编译阶段由编译器默默地将它添加到参数列表中。
this 作为隐式形参,本质上是成员函数的局部变量,所以只能用在成员函数的内部,并且只有在通过对象调用成员函数时才给 this 赋值。
友元函数:friend
在 C++ 中,一个类中可以有 public、protected、private 三种属性的成员,通过对象可以访问 public 成员,只有本类中的函数可以访问本类的 private 成员。现在,我们来介绍一种例外情况——友元(friend)。借助友元(friend),可以使得其他类中的成员函数以及全局范围内的函数访问当前类的 private 成员。
friend 的意思是朋友,或者说是好友,与好友的关系显然要比一般人亲密一些。我们会对好朋友敞开心扉,倾诉自己的秘密,而对一般人会谨言慎行,潜意识里就自我保护。在 C++ 中,这种友好关系可以用 friend 关键字指明,中文多译为“友元”,借助友元可以访问与其有好友关系的类中的私有成员。如果你对“友元”这个名词不习惯,可以按原文 friend 理解为朋友。友元函数
在当前类以外定义的、不属于当前类的函数也可以在类中声明,但要在前面加 friend 关键字,这样就构成了友元函数。友元函数可以是不属于任何类的非成员函数,也可以是其他类的成员函数。
友元函数可以访问当前类中的所有成员,包括 public、protected、private 属性的。
- 将非成员函数声明为友元函数。
- 请大家直接看下面的例子:#include
- using namespace std;
- class Student{
- public:
- Student(char *name, int age, float score);
- public:
- friend void show(Student *pstu); //将show()声明为友元函数
- private:
- char *m_name;
- int m_age;
- float m_score;
- };
- Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score)
- //非成员函数
- void show(Student *pstu){
- cout<
m_name<<"的年龄是 "< m_age<<",成绩是 "< m_score<<endl; - }
- int main(){
- Student stu("小明", 15, 90.6);
- show(&stu); //调用友元函数
- Student *pstu = new Student("李磊", 16, 80.5);
- show(pstu); //调用友元函数
- return 0;
- }
运行结果:
小明的年龄是 15,成绩是 90.6
李磊的年龄是 16,成绩是 80.5
show() 是一个全局范围内的非成员函数,它不属于任何类,它的作用是输出学生的信息。m_name、m_age、m_score 是 Student 类的 private 成员,原则上不能通过对象访问,但在 show() 函数中又必须使用这些 private 成员,所以将 show() 声明为 Student 类的友元函数。读者可以亲自测试一下,将上面程序中的第 8 行删去,观察编译器的报错信息。
- 注意,友元函数不同于类的成员函数,在友元函数中不能直接访问类的成员,必须要借助对象。下面的写法是错误的:void show(){
- cout<<m_name<<"的年龄是 "<<m_age<<",成绩是 "<<m_score<<endl;
- }
成员函数在调用时会隐式地增加 this 指针,指向调用它的对象,从而使用该对象的成员;而 show() 是非成员函数,没有 this 指针,编译器不知道使用哪个对象的成员,要想明确这一点,就必须通过参数传递对象(可以直接传递对象,也可以传递对象指针或对象引用),并在访问成员时指明对象。2) 将其他类的成员函数声明为友元函数
- friend 函数不仅可以是全局函数(非成员函数),还可以是另外一个类的成员函数。请看下面的例子:#include
- using namespace std;
- class Address; //提前声明Address类
- //声明Student类
- class Student{
- public:
- Student(char *name, int age, float score);
- public:
- void show(Address *addr);
- private:
- char *m_name;
- int m_age;
- float m_score;
- };
- //声明Address类
- class Address{
- private:
- char *m_province; //省份
- char *m_city; //城市
- char *m_district; //区(市区)
- public:
- Address(char *province, char *city, char *district);
- //将Student类中的成员函数show()声明为友元函数
- friend void Student::show(Address *addr);
- };
- //实现Student类
- Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score)
- void Student::show(Address *addr){
- cout<<m_name<<"的年龄是 "<<m_age<<",成绩是 "<<m_score<<endl;
- cout<<"家庭住址:"<
m_province<<"省"< m_city<<"市"< m_district<<"区"<<endl; - }
- //实现Address类
- Address::Address(char *province, char *city, char *district){
- m_province = province;
- m_city = city;
- m_district = district;
- }
- int main(){
- Student stu("小明", 16, 95.5f);
- Address addr("陕西", "西安", "雁塔");
- stu.show(&addr);
- Student *pstu = new Student("李磊", 16, 80.5);
- Address *paddr = new Address("河北", "衡水", "桃城");
- pstu -> show(paddr);
- return 0;
- }
运行结果:
小明的年龄是 16,成绩是 95.5
家庭住址:陕西省西安市雁塔区
李磊的年龄是 16,成绩是 80.5
家庭住址:河北省衡水市桃城区
本例定义了两个类 Student 和 Address,程序第 27 行将 Student 类的成员函数 show() 声明为 Address 类的友元函数,由此,show() 就可以访问 Address 类的 private 成员变量了。
几点注意:
① 程序第 4 行对 Address 类进行了提前声明,是因为在 Address 类定义之前、在 Student 类中使用到了它,如果不提前声明,编译器会报错,提示'Address' has not been declared。类的提前声明和函数的提前声明是一个道理。
② 程序将 Student 类的声明和实现分开了,而将 Address 类的声明放在了中间,这是因为编译器从上到下编译代码,show() 函数体中用到了 Address 的成员 province、city、district,如果提前不知道 Address 的具体声明内容,就不能确定 Address 是否拥有该成员(类的声明中指明了类有哪些成员)。
这里简单介绍一下类的提前声明。一般情况下,类必须在正式声明之后才能使用;但是某些情况下(如上例所示),只要做好提前声明,也可以先使用。
但是应当注意,类的提前声明的使用范围是有限的,只有在正式声明一个类以后才能用它去创建对象。如果在上面程序的第4行之后增加如下所示的一条语句,编译器就会报错:Address addr; //企图使用不完整的类来创建对象
因为创建对象时要为对象分配内存,在正式声明类之前,编译器无法确定应该为对象分配多大的内存。编译器只有在“见到”类的正式声明后(其实是见到成员变量),才能确定应该为对象预留多大的内存。在对一个类作了提前声明后,可以用该类的名字去定义指向该类型对象的指针变量(本例就定义了 Address 类的指针变量)或引用变量(后续会介绍引用),因为指针变量和引用变量本身的大小是固定的,与它所指向的数据的大小无关。
③ 一个函数可以被多个类声明为友元函数,这样就可以访问多个类中的 private 成员。
友元类
不仅可以将一个函数声明为一个类的“朋友”,还可以将整个类声明为另一个类的“朋友”,这就是友元类。友元类中的所有成员函数都是另外一个类的友元函数。
例如将类 B 声明为类 A 的友元类,那么类 B 中的所有成员函数都是类 A 的友元函数,可以访问类 A 的所有成员,包括 public、protected、private 属性的。
- 更改上例的代码,将 Student 类声明为 Address 类的友元类:#include
- using namespace std;
- class Address; //提前声明Address类
- //声明Student类
- class Student{
- public:
- Student(char *name, int age, float score);
- public:
- void show(Address *addr);
- private:
- char *m_name;
- int m_age;
- float m_score;
- };
- //声明Address类
- class Address{
- public:
- Address(char *province, char *city, char *district);
- public:
- //将Student类声明为Address类的友元类
- friend class Student;
- private:
- char *m_province; //省份
- char *m_city; //城市
- char *m_district; //区(市区)
- };
- //实现Student类
- Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score)
- void Student::show(Address *addr){
- cout<<m_name<<"的年龄是 "<<m_age<<",成绩是 "<<m_score<<endl;
- cout<<"家庭住址:"<
m_province<<"省"< m_city<<"市"< m_district<<"区"<<endl; - }
- //实现Address类
- Address::Address(char *province, char *city, char *district){
- m_province = province;
- m_city = city;
- m_district = district;
- }
- int main(){
- Student stu("小明", 16, 95.5f);
- Address addr("陕西", "西安", "雁塔");
- stu.show(&addr);
- Student *pstu = new Student("李磊", 16, 80.5);
- Address *paddr = new Address("河北", "衡水", "桃城");
- pstu -> show(paddr);
- return 0;
- }
第 24 行代码将 Student 类声明为 Address 类的友元类,声明语句为:friend class Student;
有的编译器也可以不写 class 关键字,不过为了增强兼容性还是建议写上。
- 关于友元,有两点需要说明:友元的关系是单向的而不是双向的。如果声明了类 B 是类 A 的友元类,不等于类 A 是类 B 的友元类,类 A 中的成员函数不能访问类 B 中的 private 成员。
- 友元的关系不能传递。如果类 B 是类 A 的友元类,类 C 是类 B 的友元类,不等于类 C 是类 A 的友元类。
除非有必要,一般不建议把整个类声明为友元类,而只将某些成员函数声明为友元函数,这样更安全一些。
class和struct区别
C++ 中保留了C语言的 struct 关键字,并且加以扩充。在C语言中,struct 只能包含成员变量,不能包含成员函数。而在C++中,struct 类似于 class,既可以包含成员变量,又可以包含成员函数。
- C++中的 struct 和 class 基本是通用的,唯有几个细节不同:使用 class 时,类中的成员默认都是 private 属性的;而使用 struct 时,结构体中的成员默认都是 public 属性的。
- class 继承默认是 private 继承,而 struct 继承默认是 public 继承(《C++继承与派生》一章会讲解继承)。
- class 可以使用模板,而 struct 不能(《模板、字符串和异常》一章会讲解模板)。
C++ 没有抛弃C语言中的 struct 关键字,其意义就在于给C语言程序开发人员有一个归属感,并且能让C++编译器兼容以前用C语言开发出来的项目。
在编写C++代码时,我强烈建议使用 class 来定义类,而使用 struct 来定义结构体,这样做语义更加明确。
- 使用 struct 来定义类的一个反面教材:#include
- using namespace std;
- struct Student{
- Student(char *name, int age, float score);
- void show();
- char *m_name;
- int m_age;
- float m_score;
- };
- Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score)
- void Student::show(){
- cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
- }
- int main(){
- Student stu("小明", 15, 92.5f);
- stu.show();
- Student *pstu = new Student("李华", 16, 96);
- pstu -> show();
- return 0;
- }
运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
这段代码可以通过编译,说明 struct 默认的成员都是 public 属性的,否则不能通过对象访问成员函数。如果将 struct 关键字替换为 class,那么就会编译报错。
类的成员有成员变量和成员函数两种。
总结
成员函数之间可以互相调用,成员函数内部可以访问成员变量。
私有成员只能在类的成员函数内部访问。默认情况下,class 类的成员是私有的,struct 类的成员是公有的。
可以用“对象名.成员名”、“引用名.成员名”、“对象指针->成员名”的方法访问对象的成员变量或调用成员函数。成员函数被调用时,可以用上述三种方法指定函数是作用在哪个对象上的。
对象所占用的存储空间的大小等于各成员变量所占用的存储空间的大小之和(如果不考虑成员变量对齐问题的话)。
定义类时,如果一个构造函数都不写,则编译器自动生成默认(无参)构造函数和复制构造函数。如果编写了构造函数,则编译器不自动生成默认构造函数。一个类不一定会有默认构造函数,但一定会有复制构造函数。
任何生成对象的语句都要说明对象是用哪个构造函数初始化的。即便定义对象数组,也要对数组中的每个元素如何初始化进行说明。如果不说明,则编译器认为对象是用默认构造函数或参数全部可以省略的构造函数初始化。在这种情况下,如果类没有默认构造函数或参数全部可以省略的构造函数,则编译出错。
对象在消亡时会调用析构函数。
每个对象有各自的一份普通成员变量,但是静态成员变量只有一份,被所有对象所共享。静态成员函数不具体作用于某个对象。即便对象不存在,也可以访问类的静态成员。静态成员函数内部不能访问非静态成员变量,也不能调用非静态成员函数。
常量对象上面不能执行非常量成员函数,只能执行常量成员函数。
包含成员对象的类叫封闭类。任何能够生成封闭类对象的语句,都要说明对象中包含的成员对象是如何初始化的。如果不说明,则编译器认为成员对象是用默认构造函数或参数全部可以省略的构造函数初始化。
在封闭类的构造函数的初始化列表中可以说明成员对象如何初始化。封闭类对象生成时,先执行成员对象的构造函数,再执行自身的构造函数;封闭类对象消亡时,先执行自身的析构函数,再执行成员对象的析构函数。
const 成员和引用成员必须在构造函数的初始化列表中初始化,此后值不可修改。
友元分为友元函数和友元类。友元关系不能传递。
成员函数中出现的 this 指针,就是指向成员函数所作用的对象的指针。因此,静态成员函数内部不能出现 this 指针。成员函数实际上的参数个数比表面上看到的多一个,多出来的参数就是 this 指针。
C++引用
参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
对于像 char、bool、int、float 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组、结构体、对象是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行频繁的内存拷贝可能会消耗很多时间,拖慢程序的执行效率。
C/C++ 禁止在函数调用时直接传递数组的内容,而是强制传递数组指针,这点已在《C语言指针变量作为函数参数》中进行了讲解。而对于结构体和对象没有这种限制,调用函数时既可以传递指针,也可以直接传递内容;为了提高效率,我曾建议传递指针,这样做在大部分情况下并没有什么不妥,读者可以点击《C语言结构体指针》进行回顾。
但是在 C++ 中,我们有了一种比指针更加便捷的传递聚合类型数据的方式,那就是引用(Reference)。在 C/C++ 中,我们将 char、int、float 等由语言本身支持的类型称为基本类型,将数组、结构体、类(对象)等由基本类型组合而成的类型称为聚合类型(在讲解结构体时也曾使用复杂类型、构造类型这两种说法)。引用(Reference)是 C++ 相对于C语言的又一个扩充。引用可以看做是数据的一个别名,通过这个别名和原来的名字都能够找到这份数据。引用类似于 Windows 中的快捷方式,一个可执行程序可以有多个快捷方式,通过这些快捷方式和可执行程序本身都能够运行程序;引用还类似于人的绰号(笔名),使用绰号(笔名)和本名都能表示一个人。
引用的定义方式类似于指针,只是用&取代了*,语法格式为:type &name = data;
type 是被引用的数据的类型,name 是引用的名称,data 是被引用的数据。引用必须在定义的同时初始化,并且以后也要从一而终,不能再引用其它数据,这有点类似于常量(const 变量)。
- 下面是一个演示引用的实例:#include
- using namespace std;
- int main() {
- int a = 99;
- int &r = a;
- cout << a << ", " << r << endl;
- cout << &a << ", " << &r << endl;
- return 0;
- }
运行结果:
99, 99
0x28ff44, 0x28ff44
本例中,变量 r 就是变量 a 的引用,它们用来指代同一份数据;也可以说变量 r 是变量 a 的另一个名字。从输出结果可以看出,a 和 r 的地址一样,都是0x28ff44;或者说地址为0x28ff44的内存有两个名字,a 和 r,想要访问该内存上的数据时,使用哪个名字都行。
注意,引用在定义时需要添加&,在使用时不能添加&,使用时添加&表示取地址。如上面代码所示,第 6 行中的&表示引用,第 8 行中的&表示取地址。除了这两种用法,&还可以表示位运算中的与运算。
- 由于引用 r 和原始变量 a 都是指向同一地址,所以通过引用也可以修改原始变量中所存储的数据,请看下面的例子:#include
- using namespace std;
- int main() {
- int a = 99;
- int &r = a;
- r = 47;
- cout << a << ", " << r << endl;
- return 0;
- }
运行结果:
47, 47
最终程序输出两个 47,可见原始变量 a 的值已经被引用变量 r 所修改。
如果读者不希望通过引用来修改原始的数据,那么可以在定义时添加 const 限制,形式为:const type &name = value;
也可以是:type const &name = value;
这种引用方式为常引用
C++引用作为函数参数
在定义或声明函数时,我们可以将函数的形参指定为引用的形式,这样在调用函数时就会将实参和形参绑定在一起,让它们都指代同一份数据。如此一来,如果在函数体中修改了形参的数据,那么实参的数据也会被修改,从而拥有“在函数内部影响函数外部数据”的效果。
至于实参和形参是如何绑定的,我们将在下节《C++引用在本质上是什么,它和指针到底有什么区别?》中讲解,届时我们会一针见血地阐明引用的本质。
- 一个能够展现按引用传参的优势的例子就是交换两个数的值,请看下面的代码:#include
- using namespace std;
- void swap1(int a, int b);
- void swap2(int *p1, int *p2);
- void swap3(int &r1, int &r2);
- int main() {
- int num1, num2;
- cout << "Input two integers: ";
- cin >> num1 >> num2;
- swap1(num1, num2);
- cout << num1 << " " << num2 << endl;
- cout << "Input two integers: ";
- cin >> num1 >> num2;
- swap2(&num1, &num2);
- cout << num1 << " " << num2 << endl;
- cout << "Input two integers: ";
- cin >> num1 >> num2;
- swap3(num1, num2);
- cout << num1 << " " << num2 << endl;
- return 0;
- }
- //直接传递参数内容
- void swap1(int a, int b) {
- int temp = a;
- a = b;
- b = temp;
- }
- //传递指针
- void swap2(int *p1, int *p2) {
- int temp = *p1;
- *p1 = *p2;
- *p2 = temp;
- }
- //按引用传参
- void swap3(int &r1, int &r2) {
- int temp = r1;
- r1 = r2;
- r2 = temp;
- }
运行结果:
Input two integers: 12 34↙
12 34
Input two integers: 88 99↙
99 88
Input two integers: 100 200↙
200 100
本例演示了三种交换变量的值的方法:
- swap1() 直接传递参数的内容,不能达到交换两个数的值的目的。对于 swap1() 来说,a、b 是形参,是作用范围仅限于函数内部的局部变量,它们有自己独立的内存,和 num1、num2 指代的数据不一样。调用函数时分别将 num1、num2 的值传递给 a、b,此后 num1、num2 和 a、b 再无任何关系,在 swap1() 内部修改 a、b 的值不会影响函数外部的 num1、num2,更不会改变 num1、num2 的值。
- swap2() 传递的是指针,能够达到交换两个数的值的目的。调用函数时,分别将 num1、num2 的指针传递给 p1、p2,此后 p1、p2 指向 a、b 所代表的数据,在函数内部可以通过指针间接地修改 a、b 的值。我们在《C语言指针变量作为函数参数》中也对比过第 1)、2) 中方式的区别。
- swap3() 是按引用传递,能够达到交换两个数的值的目的。调用函数时,分别将 r1、r2 绑定到 num1、num2 所指代的数据,此后 r1 和 num1、r2 和 num2 就都代表同一份数据了,通过 r1 修改数据后会影响 num1,通过 r2 修改数据后也会影响 num2。
从以上代码的编写中可以发现,按引用传参在使用形式上比指针更加直观。在以后的 C++ 编程中,我鼓励读者大量使用引用,它一般可以代替指针(当然指针在C++中也不可或缺),C++ 标准库也是这样做的。
C++引用作为函数返回值
- 引用除了可以作为函数形参,还可以作为函数返回值,请看下面的例子:#include
- using namespace std;
- int &plus10(int &r) {
- r += 10;
- return r;
- }
- int main() {
- int num1 = 10;
- int num2 = plus10(num1);
- cout << num1 << " " << num2 << endl;
- return 0;
- }
运行结果:
20 20
在将引用作为函数返回值时应该注意一个小问题,就是不能返回局部数据(例如局部变量、局部对象、局部数组等)的引用,因为当函数调用完成后局部数据就会被销毁,有可能在下次使用时数据就不存在了,C++ 编译器检测到该行为时也会给出警告。
- 更改上面的例子,让 plus10() 返回一个局部数据的引用:#include
- using namespace std;
- int &plus10(int &r) {
- int m = r + 10;
- return m; //返回局部数据的引用
- }
- int main() {
- int num1 = 10;
- int num2 = plus10(num1);
- cout << num2 << endl;
- int &num3 = plus10(num1);
- int &num4 = plus10(num3);
- cout << num3 << " " << num4 << endl;
- return 0;
- }
在 Visual Studio 下的运行结果:20
-858993450 -858993450在 GCC 下的运行结果:20
30 30在 C-Free 下的运行结果:20
30 0而我们期望的运行结果是:20
20 30plus10() 返回一个对局部变量 m 的引用,这是导致运行结果非常怪异的根源,因为函数是在栈上运行的,并且运行结束后会放弃对所有局部数据的管理权,后面的函数调用会覆盖前面函数的局部数据。本例中,第二次调用 plus10() 会覆盖第一次调用 plus10() 所产生的局部数据,第三次调用 plus10() 会覆盖第二次调用 plus10() 所产生的局部数据。
继承和派生
C++ 中的继承是类与类之间的关系,是一个很简单很直观的概念,与现实世界中的继承类似,例如儿子继承父亲的财产。
继承(Inheritance)可以理解为一个类从另一个类获取成员变量和成员函数的过程。例如类 B 继承于类 A,那么 B 就拥有 A 的成员变量和成员函数。
在C++中,派生(Derive)和继承是一个概念,只是站的角度不同。继承是儿子接收父亲的产业,派生是父亲把产业传承给儿子。
被继承的类称为父类或基类,继承的类称为子类或派生类。“子类”和“父类”通常放在一起称呼,“基类”和“派生类”通常放在一起称呼。
派生类除了拥有基类的成员,还可以定义自己的新成员,以增强类的功能。
以下是两种典型的使用继承的场景:
- 当你创建的新类与现有的类相似,只是多出若干成员变量或成员函数时,可以使用继承,这样不但会减少代码量,而且新类会拥有基类的所有功能。
- 当你需要创建多个类,它们拥有很多相似的成员变量或成员函数时,也可以使用继承。可以将这些类的共同成员提取出来,定义为基类,然后从基类继承,既可以节省代码,也方便后续修改成员。
- 下面我们定义一个基类 People,然后由此派生出 Student 类:#include
- using namespace std;
- //基类 Pelple
- class People{
- public:
- void setname(char *name);
- void setage(int age);
- char *getname();
- int getage();
- private:
- char *m_name;
- int m_age;
- };
- void People::setname(char *name)
- void People::setage(int age)
- char* People::getname(){ return m_name; }
- int People::getage(){ return m_age;}
- //派生类 Student
- class Student: public People{
- public:
- void setscore(float score);
- float getscore();
- private:
- float m_score;
- };
- void Student::setscore(float score)
- float Student::getscore(){ return m_score; }
- int main(){
- Student stu;
- stu.setname("小明");
- stu.setage(16);
- stu.setscore(95.5f);
- cout<<stu.getname()<<"的年龄是 "<<stu.getage()<<",成绩是 "<<stu.getscore()<<endl;
- return 0;
- }
运行结果:
小明的年龄是 16,成绩是 95.5
本例中,People 是基类,Student 是派生类。Student 类继承了 People 类的成员,同时还新增了自己的成员变量 score 和成员函数 setscore()、getscore()。这些继承过来的成员,可以通过子类对象访问,就像自己的一样。
请认真观察代码第21行:class Student: public People
这就是声明派生类的语法。class 后面的“Student”是新声明的派生类,冒号后面的“People”是已经存在的基类。在“People”之前有一关键宇 public,用来表示是公有继承。
由此总结出继承的一般语法为:class 派生类名:[继承方式] 基类名{
派生类新增加的成员
};继承方式包括 public(公有的)、private(私有的)和 protected(受保护的),此项是可选的,如果不写,那么默认为 private。我们将在下节详细讲解这些不同的继承方式。
三种继承方式
C++继承的一般语法为:class 派生类名:[继承方式] 基类名{
派生类新增加的成员
};继承方式限定了基类成员在派生类中的访问权限,包括 public(公有的)、private(私有的)和 protected(受保护的)。此项是可选项,如果不写,默认为 private(成员变量和成员函数默认也是 private)。
现在我们知道,public、protected、private 三个关键字除了可以修饰类的成员,还可以指定继承方式。
public、protected、private 修饰类的成员
类成员的访问权限由高到低依次为 public --> protected --> private,我们在《C++类成员的访问权限以及类的封装》一节中讲解了 public 和 private:public 成员可以通过对象来访问,private 成员不能通过对象访问。
现在再来补充一下 protected。protected 成员和 private 成员类似,也不能通过对象访问。但是当存在继承关系时,protected 和 private 就不一样了:基类中的 protected 成员可以在派生类中使用,而基类中的 private 成员不能在派生类中使用,下面是详细讲解。
public、protected、private 指定继承方式
不同的继承方式会影响基类成员在派生类中的访问权限。
- 1) public继承方式基类中所有 public 成员在派生类中为 public 属性;
- 基类中所有 protected 成员在派生类中为 protected 属性;
- 基类中所有 private 成员在派生类中不能使用。
- 2) protected继承方式基类中的所有 public 成员在派生类中为 protected 属性;
- 基类中的所有 protected 成员在派生类中为 protected 属性;
- 基类中的所有 private 成员在派生类中不能使用。
- 3) private继承方式基类中的所有 public 成员在派生类中均为 private 属性;
- 基类中的所有 protected 成员在派生类中均为 private 属性;
- 基类中的所有 private 成员在派生类中不能使用。
通过上面的分析可以发现:
- 基类成员在派生类中的访问权限不得高于继承方式中指定的权限。例如,当继承方式为 protected 时,那么基类成员在派生类中的访问权限最高也为 protected,高于 protected 的会降级为 protected,但低于 protected 不会升级。再如,当继承方式为 public 时,那么基类成员在派生类中的访问权限将保持不变。
也就是说,继承方式中的 public、protected、private 是用来指明基类成员在派生类中的最高访问权限的。 - 不管继承方式如何,基类中的 private 成员在派生类中始终不能使用(不能在派生类的成员函数中访问或调用)。
- 如果希望基类的成员能够被派生类继承并且毫无障碍地使用,那么这些成员只能声明为 public 或 protected;只有那些不希望在派生类中使用的成员才声明为 private。
- 如果希望基类的成员既不向外暴露(不能通过对象访问),还能在派生类中使用,那么只能声明为 protected。
注意,我们这里说的是基类的 private 成员不能在派生类中使用,并没有说基类的 private 成员不能被继承。实际上,基类的 private 成员是能够被继承的,并且(成员变量)会占用派生类对象的内存,它只是在派生类中不可见,导致无法使用罢了。private 成员的这种特性,能够很好的对派生类隐藏基类的实现,以体现面向对象的封装性。
| 继承方式/基类成员 | public成员 | protected成员 | private成员 |
|---|---|---|---|
| public继承 | public | protected | 不可见 |
| protected继承 | protected | protected | 不可见 |
| private继承 | private | private | 不可见 |
由于 private 和 protected 继承方式会改变基类成员在派生类中的访问权限,导致继承关系复杂,所以实际开发中我们一般使用 public。
- 【示例】演示类的继承关系。#include
- using namespace std;
- //基类People
- class People{
- public:
- void setname(char *name);
- void setage(int age);
- void sethobby(char *hobby);
- char *gethobby();
- protected:
- char *m_name;
- int m_age;
- private:
- char *m_hobby;
- };
- void People::setname(char *name)
- void People::setage(int age)
- void People::sethobby(char *hobby)
- char *People::gethobby(){ return m_hobby; }
- //派生类Student
- class Student: public People{
- public:
- void setscore(float score);
- protected:
- float m_score;
- };
- void Student::setscore(float score)
- //派生类Pupil
- class Pupil: public Student{
- public:
- void setranking(int ranking);
- void display();
- private:
- int m_ranking;
- };
- void Pupil::setranking(int ranking)
- void Pupil::display(){
- cout<<m_name<<"的年龄是"<<m_age<<",考试成绩为"<<m_score<<"分,班级排名第"<<m_ranking<<",TA喜欢"<<gethobby()<<"。"<<endl;
- }
- int main(){
- Pupil pup;
- pup.setname("小明");
- pup.setage(15);
- pup.setscore(92.5f);
- pup.setranking(4);
- pup.sethobby("乒乓球");
- pup.display();
- return 0;
- }
运行结果:
小明的年龄是15,考试成绩为92.5分,班级排名第4,TA喜欢乒乓球。
这是一个多级继承的例子,Student 继承自 People,Pupil 又继承自 Student,它们的继承关系为 People --> Student --> Pupil。Pupil 是最终的派生类,它拥有基类的 m_name、m_age、m_score、m_hobby 成员变量以及 setname()、setage()、sethobby()、gethobby()、setscore() 成员函数。
注意,在派生类 Pupil 的成员函数 display() 中,我们借助基类的 public 成员函数 gethobby() 来访问基类的 private 成员变量 m_hobby,因为 m_hobby 是 private 属性的,在派生类中不可见,所以只能借助基类的 public 成员函数 sethobby()、gethobby() 来访问。
在派生类中访问基类 private 成员的唯一方法就是借助基类的非 private 成员函数,如果基类没有非 private 成员函数,那么该成员在派生类中将无法访问。
改变访问权限
使用 using 关键字可以改变基类成员在派生类中的访问权限,例如将 public 改为 private、将 protected 改为 public。
注意:using 只能改变基类中 public 和 protected 成员的访问权限,不能改变 private 成员的访问权限,因为基类中 private 成员在派生类中是不可见的,根本不能使用,所以基类中的 private 成员在派生类中无论如何都不能访问。
- using 关键字使用示例:#include
- using namespace std;
- //基类People
- class People {
- public:
- void show();
- protected:
- char *m_name;
- int m_age;
- };
- void People::show() {
- cout << m_name << "的年龄是" << m_age << endl;
- }
- //派生类Student
- class Student : public People {
- public:
- void learning();
- public:
- using People::m_name; //将protected改为public
- using People::m_age; //将protected改为public
- float m_score;
- private:
- using People::show; //将public改为private
- };
- void Student::learning() {
- cout << "我是" << m_name << ",今年" << m_age << "岁,这次考了" << m_score << "分!" << endl;
- }
- int main() {
- Student stu;
- stu.m_name = "小明";
- stu.m_age = 16;
- stu.m_score = 99.5f;
- stu.show(); //compile error
- stu.learning();
- return 0;
- }
代码中首先定义了基类 People,它包含两个 protected 属性的成员变量和一个 public 属性的成员函数。定义 Student 类时采用 public 继承方式,People 类中的成员在 Student 类中的访问权限默认是不变的。
不过,我们使用 using 改变了它们的默认访问权限,如代码第 21~25 行所示,将 show() 函数修改为 private 属性的,是降低访问权限,将 name、age 变量修改为 public 属性的,是提高访问权限。
因为 show() 函数是 private 属性的,所以代码第 36 行会报错。把该行注释掉,程序输出结果为:
我是小明,今年16岁,这次考了99.5分!
基类成员函数和派生类成员函数不构成重载
基类成员和派生类成员的名字一样时会造成遮蔽,这句话对于成员变量很好理解,对于成员函数要引起注意,不管函数的参数如何,只要名字一样就会造成遮蔽。换句话说,基类成员函数和派生类成员函数不会构成重载,如果派生类有同名函数,那么就会遮蔽基类中的所有同名函数,不管它们的参数是否一样。
- 下面的例子很好的说明了这一点:#include
- using namespace std;
- //基类Base
- class Base{
- public:
- void func();
- void func(int);
- };
- void Base::func()
- void Base::func(int a)
- //派生类Derived
- class Derived: public Base{
- public:
- void func(char *);
- void func(bool);
- };
- void Derived::func(char *str)
- void Derived::func(bool is)
- int main(){
- Derived d;
- d.func("http://c.biancheng.net");
- d.func(true);
- d.func(); //compile error
- d.func(10); //compile error
- d.Base::func();
- d.Base::func(100);
- return 0;
- }
本例中,Base 类的func()、func(int)和 Derived 类的func(char *)、func(bool)四个成员函数的名字相同,参数列表不同,它们看似构成了重载,能够通过对象 d 访问所有的函数,实则不然,Derive 类的 func 遮蔽了 Base 类的 func,导致第 26、27 行代码没有匹配的函数,所以调用失败。
如果说有重载关系,那么也是 Base 类的两个 func 构成重载,而 Derive 类的两个 func 构成另外的重载。
将派生类赋值给基类(向上转型)
在 C/C++ 中经常会发生数据类型的转换,例如将 int 类型的数据赋值给 float 类型的变量时,编译器会先把 int 类型的数据转换为 float 类型再赋值;反过来,float 类型的数据在经过类型转换后也可以赋值给 int 类型的变量。
- 数据类型转换的前提是,编译器知道如何对数据进行取舍。例如:int a = 10.9;
- printf("%d\n", a);
- 输出结果为 10,编译器会将小数部分直接丢掉(不是四舍五入)。再如:float b = 10;
- printf("%f\n", b);
输出结果为 10.000000,编译器会自动添加小数部分。
类其实也是一种数据类型,也可以发生数据类型转换,不过这种转换只有在基类和派生类之间才有意义,并且只能将派生类赋值给基类,包括将派生类对象赋值给基类对象、将派生类指针赋值给基类指针、将派生类引用赋值给基类引用,这在 C++ 中称为向上转型(Upcasting)。相应地,将基类赋值给派生类称为向下转型(Downcasting)。
向上转型非常安全,可以由编译器自动完成;向下转型有风险,需要程序员手动干预。本节只介绍向上转型,向下转型将在后续章节介绍。向上转型和向下转型是面向对象编程的一种通用概念,它们也存在于 Java、C# 等编程语言中。将派生类对象赋值给基类对象
- 下面的例子演示了如何将派生类对象赋值给基类对象:#include
- using namespace std;
- //基类
- class A{
- public:
- A(int a);
- public:
- void display();
- public:
- int m_a;
- };
- A::A(int a): m_a(a)
- void A::display(){
- cout<<"Class A: m_a="<<m_a<<endl;
- }
- //派生类
- class B: public A{
- public:
- B(int a, int b);
- public:
- void display();
- public:
- int m_b;
- };
- B::B(int a, int b): A(a), m_b(b)
- void B::display(){
- cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl;
- }
- int main(){
- A a(10);
- B b(66, 99);
- //赋值前
- a.display();
- b.display();
- cout<<"--------------"<<endl;
- //赋值后
- a = b;
- a.display();
- b.display();
- return 0;
- }
运行结果:
Class A: m_a=10
Class B: m_a=66, m_b=99
Class A: m_a=66
Class B: m_a=66, m_b=99
本例中 A 是基类, B 是派生类,a、b 分别是它们的对象,由于派生类 B 包含了从基类 A 继承来的成员,因此可以将派生类对象 b 赋值给基类对象 a。通过运行结果也可以发现,赋值后 a 所包含的成员变量的值已经发生了变化。
赋值的本质是将现有的数据写入已分配好的内存中,对象的内存只包含了成员变量,所以对象之间的赋值是成员变量的赋值,成员函数不存在赋值问题。运行结果也有力地证明了这一点,虽然有a=b;这样的赋值过程,但是 a.display() 始终调用的都是 A 类的 display() 函数。换句话说,对象之间的赋值不会影响成员函数,也不会影响 this 指针。
将派生类对象赋值给基类对象时,会舍弃派生类新增的成员,也就是“大材小用”,如下图所示:
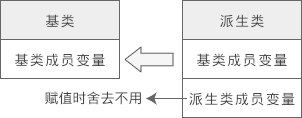
可以发现,即使将派生类对象赋值给基类对象,基类对象也不会包含派生类的成员,所以依然不同通过基类对象来访问派生类的成员。对于上面的例子,a.m_a 是正确的,但 a.m_b 就是错误的,因为 a 不包含成员 m_b。
这种转换关系是不可逆的,只能用派生类对象给基类对象赋值,而不能用基类对象给派生类对象赋值。理由很简单,基类不包含派生类的成员变量,无法对派生类的成员变量赋值。同理,同一基类的不同派生类对象之间也不能赋值。
要理解这个问题,还得从赋值的本质入手。赋值实际上是向内存填充数据,当数据较多时很好处理,舍弃即可;本例中将 b 赋值给 a 时(执行a=b;语句),成员 m_b 是多余的,会被直接丢掉,所以不会发生赋值错误。但当数据较少时,问题就很棘手,编译器不知道如何填充剩下的内存;如果本例中有b= a;这样的语句,编译器就不知道该如何给变量 m_b 赋值,所以会发生错误。
将派生类指针赋值给基类指针
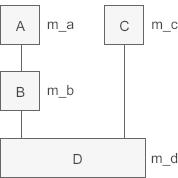
除了可以将派生类对象赋值给基类对象(对象变量之间的赋值),还可以将派生类指针赋值给基类指针(对象指针之间的赋值)。我们先来看一个多继承的例子,继承关系为:
- 下面的代码实现了这种继承关系:#include
- using namespace std;
- //基类A
- class A{
- public:
- A(int a);
- public:
- void display();
- protected:
- int m_a;
- };
- A::A(int a): m_a(a)
- void A::display(){
- cout<<"Class A: m_a="<<m_a<<endl;
- }
- //中间派生类B
- class B: public A{
- public:
- B(int a, int b);
- public:
- void display();
- protected:
- int m_b;
- };
- B::B(int a, int b): A(a), m_b(b)
- void B::display(){
- cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl;
- }
- //基类C
- class C{
- public:
- C(int c);
- public:
- void display();
- protected:
- int m_c;
- };
- C::C(int c): m_c(c)
- void C::display(){
- cout<<"Class C: m_c="<<m_c<<endl;
- }
- //最终派生类D
- class D: public B, public C{
- public:
- D(int a, int b, int c, int d);
- public:
- void display();
- private:
- int m_d;
- };
- D:😄(int a, int b, int c, int d): B(a, b), C(c), m_d(d)
- void D::display(){
- cout<<"Class D: m_a="<<m_a<<", m_b="<<m_b<<", m_c="<<m_c<<", m_d="<<m_d<<endl;
- }
- int main(){
- A *pa = new A(1);
- B *pb = new B(2, 20);
- C *pc = new C(3);
- D *pd = new D(4, 40, 400, 4000);
- pa = pd;
- pa -> display();
- pb = pd;
- pb -> display();
- pc = pd;
- pc -> display();
- cout<<"-----------------------"<<endl;
- cout<<"pa="<<pa<<endl;
- cout<<"pb="<<pb<<endl;
- cout<<"pc="<<pc<<endl;
- cout<<"pd="<<pd<<endl;
- return 0;
- }
运行结果:
Class A: m_a=4
Class B: m_a=4, m_b=40
Class C: m_c=400
pa=0x9b17f8
pb=0x9b17f8
pc=0x9b1800
pd=0x9b17f8
本例中定义了多个对象指针,并尝试将派生类指针赋值给基类指针。与对象变量之间的赋值不同的是,对象指针之间的赋值并没有拷贝对象的成员,也没有修改对象本身的数据,仅仅是改变了指针的指向。
- 通过基类指针访问派生类的成员
请读者先关注第 68 行代码,我们将派生类指针 pd 赋值给了基类指针 pa,从运行结果可以看出,调用 display() 函数时虽然使用了派生类的成员变量,但是 display() 函数本身却是基类的。也就是说,将派生类指针赋值给基类指针时,通过基类指针只能使用派生类的成员变量,但不能使用派生类的成员函数,这看起来有点不伦不类,究竟是为什么呢?第 71、74 行代码也是类似的情况。
pa 本来是基类 A 的指针,现在指向了派生类 D 的对象,这使得隐式指针 this 发生了变化,也指向了 D 类的对象,所以最终在 display() 内部使用的是 D 类对象的成员变量,相信这一点不难理解。
编译器虽然通过指针的指向来访问成员变量,但是却不通过指针的指向来访问成员函数:编译器通过指针的类型来访问成员函数。对于 pa,它的类型是 A,不管它指向哪个对象,使用的都是 A 类的成员函数,具体原因已在《C++函数编译原理和成员函数的实现》中做了详细讲解。
概括起来说就是:编译器通过指针来访问成员变量,指针指向哪个对象就使用哪个对象的数据;编译器通过指针的类型来访问成员函数,指针属于哪个类的类型就使用哪个类的函数。 - 赋值后值不一致的情况
本例中我们将最终派生类的指针 pd 分别赋值给了基类指针 pa、pb、pc,按理说它们的值应该相等,都指向同一块内存,但是运行结果却有力地反驳了这种推论,只有 pa、pb、pd 三个指针的值相等,pc 的值比它们都大。也就是说,执行pc = pd;语句后,pc 和 pd 的值并不相等。
这非常出乎我们的意料,按照我们通常的理解,赋值就是将一个变量的值交给另外一个变量,不会出现不相等的情况,究竟是什么导致了 pc 和 pd 不相等呢?我们将在《将派生类指针赋值给基类指针时到底发生了什么?》一节中解开谜底。将派生类引用赋值给基类引用
引用在本质上是通过指针的方式实现的,这一点已在《引用在本质上是什么,它和指针到底有什么区别》中进行了讲解,既然基类的指针可以指向派生类的对象,那么我们就有理由推断:基类的引用也可以指向派生类的对象,并且它的表现和指针是类似的。
- 修改上例中 main() 函数内部的代码,用引用取代指针:int main(){
- D d(4, 40, 400, 4000);
- A &ra = d;
- B &rb = d;
- C &rc = d;
- ra.display();
- rb.display();
- rc.display();
- return 0;
- }
运行结果:
Class A: m_a=4
Class B: m_a=4, m_b=40
Class C: m_c=400
ra、rb、rc 是基类的引用,它们都引用了派生类对象 d,并调用了 display() 函数,从运行结果可以发现,虽然使用了派生类对象的成员变量,但是却没有使用派生类的成员函数,这和指针的表现是一样的。
引用和指针的表现之所以如此类似,是因为引用和指针并没有本质上的区别,引用仅仅是对指针进行了简单封装,读者可以猛击《引用在本质上是什么,它和指针到底有什么区别》一文深入了解。
最后需要注意的是,向上转型后通过基类的对象、指针、引用只能访问从基类继承过去的成员(包括成员变量和成员函数),不能访问派生类新增的成员。
多态和虚函数:virtual
- 在《C++将派生类赋值给基类(向上转型)》一节中讲到,基类的指针也可以指向派生类对象,请看下面的例子:#include
- using namespace std;
- //基类People
- class People{
- public:
- People(char *name, int age);
- void display();
- protected:
- char *m_name;
- int m_age;
- };
- People::People(char *name, int age): m_name(name), m_age(age){}
- void People::display(){
- cout<<m_name<<"今年"<<m_age<<"岁了,是个无业游民。"<<endl;
- }
- //派生类Teacher
- class Teacher: public People{
- public:
- Teacher(char *name, int age, int salary);
- void display();
- private:
- int m_salary;
- };
- Teacher::Teacher(char *name, int age, int salary): People(name, age), m_salary(salary){}
- void Teacher::display(){
- cout<<m_name<<"今年"<<m_age<<"岁了,是一名教师,每月有"<<m_salary<<"元的收入。"<<endl;
- }
- int main(){
- People *p = new People("王志刚", 23);
- p -> display();
- p = new Teacher("赵宏佳", 45, 8200);
- p -> display();
- return 0;
- }
运行结果:
王志刚今年23岁了,是个无业游民。
赵宏佳今年45岁了,是个无业游民。
我们直观上认为,如果指针指向了派生类对象,那么就应该使用派生类的成员变量和成员函数,这符合人们的思维习惯。但是本例的运行结果却告诉我们,当基类指针 p 指向派生类 Teacher 的对象时,虽然使用了 Teacher 的成员变量,但是却没有使用它的成员函数,导致输出结果不伦不类(赵宏佳本来是一名老师,输出结果却显示人家是个无业游民),不符合我们的预期。
换句话说,通过基类指针只能访问派生类的成员变量,但是不能访问派生类的成员函数。
为了消除这种尴尬,让基类指针能够访问派生类的成员函数,C++ 增加了虚函数(Virtual Function)。使用虚函数非常简单,只需要在函数声明前面增加 virtual 关键字。
- 更改上面的代码,将 display() 声明为虚函数:#include
- using namespace std;
- //基类People
- class People{
- public:
- People(char *name, int age);
- virtual void display(); //声明为虚函数
- protected:
- char *m_name;
- int m_age;
- };
- People::People(char *name, int age): m_name(name), m_age(age){}
- void People::display(){
- cout<<m_name<<"今年"<<m_age<<"岁了,是个无业游民。"<<endl;
- }
- //派生类Teacher
- class Teacher: public People{
- public:
- Teacher(char *name, int age, int salary);
- virtual void display(); //声明为虚函数
- private:
- int m_salary;
- };
- Teacher::Teacher(char *name, int age, int salary): People(name, age), m_salary(salary){}
- void Teacher::display(){
- cout<<m_name<<"今年"<<m_age<<"岁了,是一名教师,每月有"<<m_salary<<"元的收入。"<<endl;
- }
- int main(){
- People *p = new People("王志刚", 23);
- p -> display();
- p = new Teacher("赵宏佳", 45, 8200);
- p -> display();
- return 0;
- }
运行结果:
王志刚今年23岁了,是个无业游民。
赵宏佳今年45岁了,是一名教师,每月有8200元的收入。
和前面的例子相比,本例仅仅是在 display() 函数声明前加了一个virtual关键字,将成员函数声明为了虚函数(Virtual Function),这样就可以通过 p 指针调用 Teacher 类的成员函数了,运行结果也证明了这一点(赵宏佳已经是一名老师了,不再是无业游民了)。
有了虚函数,基类指针指向基类对象时就使用基类的成员(包括成员函数和成员变量),指向派生类对象时就使用派生类的成员。换句话说,基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态,或者说有多种表现方式,我们将这种现象称为多态(Polymorphism)。
上面的代码中,同样是p->display();这条语句,当 p 指向不同的对象时,它执行的操作是不一样的。同一条语句可以执行不同的操作,看起来有不同表现方式,这就是多态。
多态是面向对象编程的主要特征之一,C++中虚函数的唯一用处就是构成多态。
C++提供多态的目的是:可以通过基类指针对所有派生类(包括直接派生和间接派生)的成员变量和成员函数进行“全方位”的访问,尤其是成员函数。如果没有多态,我们只能访问成员变量。
前面我们说过,通过指针调用普通的成员函数时会根据指针的类型(通过哪个类定义的指针)来判断调用哪个类的成员函数,但是通过本节的分析可以发现,这种说法并不适用于虚函数,虚函数是根据指针的指向来调用的,指针指向哪个类的对象就调用哪个类的虚函数。
但是话又说回来,对象的内存模型是非常干净的,没有包含任何成员函数的信息,编译器究竟是根据什么找到了成员函数呢?我们将在《C++虚函数表精讲教程,直戳多态的实现机制》一节中给出答案。借助引用也可以实现多态
引用在本质上是通过指针的方式实现的,这一点已在《C++引用在本质上是什么,它和指针到底有什么区别?》中进行了讲解,既然借助指针可以实现多态,那么我们就有理由推断:借助引用也可以实现多态。
- 修改上例中 main() 函数内部的代码,用引用取代指针:int main(){
- People p("王志刚", 23);
- Teacher t("赵宏佳", 45, 8200);
- People &rp = p;
- People &rt = t;
- rp.display();
- rt.display();
- return 0;
- }
运行结果:
王志刚今年23岁了,是个无业游民。
赵宏佳今年45岁了,是一名教师,每月有8200元的收入。
由于引用类似于常量,只能在定义的同时初始化,并且以后也要从一而终,不能再引用其他数据,所以本例中必须要定义两个引用变量,一个用来引用基类对象,一个用来引用派生类对象。从运行结果可以看出,当基类的引用指代基类对象时,调用的是基类的成员,而指代派生类对象时,调用的是派生类的成员。
不过引用不像指针灵活,指针可以随时改变指向,而引用只能指代固定的对象,在多态性方面缺乏表现力,所以以后我们再谈及多态时一般是说指针。本例的主要目的是让读者知道,除了指针,引用也可以实现多态。
多态的用途
通过上面的例子读者可能还未发现多态的用途,不过确实也是,多态在小项目中鲜有有用武之地。
- 接下来的例子中,我们假设你正在玩一款军事游戏,敌人突然发动了地面战争,于是你命令陆军、空军及其所有现役装备进入作战状态。具体的代码如下所示:#include
- using namespace std;
- //军队
- class Troops{
- public:
- virtual void fight()
- };
- //陆军
- class Army: public Troops{
- public:
- void fight()
- };
- //99A主战坦克
- class _99A: public Army{
- public:
- void fight()
- };
- //武直10武装直升机
- class WZ_10: public Army{
- public:
- void fight()
- };
- //长剑10巡航导弹
- class CJ_10: public Army{
- public:
- void fight()
- };
- //空军
- class AirForce: public Troops{
- public:
- void fight()
- };
- //J-20隐形歼击机
- class J_20: public AirForce{
- public:
- void fight()
- };
- //CH5无人机
- class CH_5: public AirForce{
- public:
- void fight()
- };
- //轰6K轰炸机
- class H_6K: public AirForce{
- public:
- void fight()
- };
- int main(){
- Troops *p = new Troops;
- p ->fight();
- //陆军
- p = new Army;
- p ->fight();
- p = new _99A;
- p -> fight();
- p = new WZ_10;
- p -> fight();
- p = new CJ_10;
- p -> fight();
- //空军
- p = new AirForce;
- p -> fight();
- p = new J_20;
- p -> fight();
- p = new CH_5;
- p -> fight();
- p = new H_6K;
- p -> fight();
- return 0;
- }
运行结果:
Strike back!
--Army is fighting!
----99A(Tank) is fighting!
----WZ-10(Helicopter) is fighting!
----CJ-10(Missile) is fighting!
--AirForce is fighting!
----J-20(Fighter Plane) is fighting!
----CH-5(UAV) is fighting!
----H-6K(Bomber) is fighting!
这个例子中的派生类比较多,如果不使用多态,那么就需要定义多个指针变量,很容易造成混乱;而有了多态,只需要一个指针变量 p 就可以调用所有派生类的虚函数。
从这个例子中也可以发现,对于具有复杂继承关系的大中型程序,多态可以增加其灵活性,让代码更具有表现力。
虚函数注意事项以及构成多态的条件
C++ 虚函数对于多态具有决定性的作用,有虚函数才能构成多态。上节《C++多态和虚函数快速入门教程》我们已经介绍了虚函数的概念,这节我们来重点说一下虚函数的注意事项。
- 只需要在虚函数的声明处加上 virtual 关键字,函数定义处可以加也可以不加。
- 为了方便,你可以只将基类中的函数声明为虚函数,这样所有派生类中具有遮蔽关系的同名函数都将自动成为虚函数。关于名字遮蔽已在《C++继承时的名字遮蔽》一节中进行了讲解。
- 当在基类中定义了虚函数时,如果派生类没有定义新的函数来遮蔽此函数,那么将使用基类的虚函数。
- 只有派生类的虚函数覆盖基类的虚函数(函数原型相同)才能构成多态(通过基类指针访问派生类函数)。例如基类虚函数的原型为virtual void func();,派生类虚函数的原型为virtual void func(int);,那么当基类指针 p 指向派生类对象时,语句p -> func(100);将会出错,而语句p -> func();将调用基类的函数。
- 构造函数不能是虚函数。对于基类的构造函数,它仅仅是在派生类构造函数中被调用,这种机制不同于继承。也就是说,派生类不继承基类的构造函数,将构造函数声明为虚函数没有什么意义。
- 析构函数可以声明为虚函数,而且有时候必须要声明为虚函数,这点我们将在下节中讲解。
构成多态的条件
站在“学院派”的角度讲,封装、继承和多态是面向对象的三大特征,封装、继承分别在《C++类成员的访问权限以及类的封装》《C++继承和派生简明教程》中进行了讲解,而多态是指通过基类的指针既可以访问基类的成员,也可以访问派生类的成员。
下面是构成多态的条件:
- 必须存在继承关系;
- 继承关系中必须有同名的虚函数,并且它们是覆盖关系(函数原型相同)。
- 存在基类的指针,通过该指针调用虚函数。
- 下面的例子对各种混乱情形进行了演示:#include
- using namespace std;
- //基类Base
- class Base{
- public:
- virtual void func();
- virtual void func(int);
- };
- void Base::func(){
- cout<<"void Base::func()"<<endl;
- }
- void Base::func(int n){
- cout<<"void Base::func(int)"<<endl;
- }
- //派生类Derived
- class Derived: public Base{
- public:
- void func();
- void func(char *);
- };
- void Derived::func(){
- cout<<"void Derived::func()"<<endl;
- }
- void Derived::func(char *str){
- cout<<"void Derived::func(char *)"<<endl;
- }
- int main(){
- Base *p = new Derived();
- p -> func(); //输出void Derived::func()
- p -> func(10); //输出void Base::func(int)
- p -> func("http://c.biancheng.net"); //compile error
- return 0;
- }
在基类 Base 中我们将void func()声明为虚函数,这样派生类 Derived 中的void func()就会自动成为虚函数。p 是基类 Base 的指针,但是指向了派生类 Derived 的对象。
语句p -> func();调用的是派生类的虚函数,构成了多态。
语句p -> func(10);调用的是基类的虚函数,因为派生类中没有函数覆盖它。
语句p -> func("http://c.biancheng.net");出现编译错误,因为通过基类的指针只能访问从基类继承过去的成员,不能访问派生类新增的成员。
什么时候声明虚函数
首先看成员函数所在的类是否会作为基类。然后看成员函数在类的继承后有无可能被更改功能,如果希望更改其功能的,一般应该将它声明为虚函数。如果成员函数在类被继承后功能不需修改,或派生类用不到该函数,则不要把它声明为虚函数。
纯虚函数和抽象类
在C++中,可以将虚函数声明为纯虚函数,语法格式为:virtual 返回值类型 函数名 (函数参数) = 0;
纯虚函数没有函数体,只有函数声明,在虚函数声明的结尾加上=0,表明此函数为纯虚函数。最后的=0并不表示函数返回值为0,它只起形式上的作用,告诉编译系统“这是纯虚函数”。包含纯虚函数的类称为抽象类(Abstract Class)。之所以说它抽象,是因为它无法实例化,也就是无法创建对象。原因很明显,纯虚函数没有函数体,不是完整的函数,无法调用,也无法为其分配内存空间。
抽象类通常是作为基类,让派生类去实现纯虚函数。派生类必须实现纯虚函数才能被实例化。
- 纯虚函数使用举例:#include
- using namespace std;
- //线
- class Line{
- public:
- Line(float len);
- virtual float area() = 0;
- virtual float volume() = 0;
- protected:
- float m_len;
- };
- Line::Line(float len): m_len(len)
- //矩形
- class Rec: public Line{
- public:
- Rec(float len, float width);
- float area();
- protected:
- float m_width;
- };
- Rec::Rec(float len, float width): Line(len), m_width(width)
- float Rec::area(){ return m_len * m_width; }
- //长方体
- class Cuboid: public Rec{
- public:
- Cuboid(float len, float width, float height);
- float area();
- float volume();
- protected:
- float m_height;
- };
- Cuboid::Cuboid(float len, float width, float height): Rec(len, width), m_height(height)
- float Cuboid::area(){ return 2 * ( m_lenm_width + m_lenm_height + m_width*m_height); }
- float Cuboid::volume(){ return m_len * m_width * m_height; }
- //正方体
- class Cube: public Cuboid{
- public:
- Cube(float len);
- float area();
- float volume();
- };
- Cube::Cube(float len): Cuboid(len, len, len)
- float Cube::area(){ return 6 * m_len * m_len; }
- float Cube::volume(){ return m_len * m_len * m_len; }
- int main(){
- Line *p = new Cuboid(10, 20, 30);
- cout<<"The area of Cuboid is "<
area()<<endl; - cout<<"The volume of Cuboid is "<
volume()<<endl; - p = new Cube(15);
- cout<<"The area of Cube is "<
area()<<endl; - cout<<"The volume of Cube is "<
volume()<<endl; - return 0;
- }
运行结果:
The area of Cuboid is 2200
The volume of Cuboid is 6000
The area of Cube is 1350
The volume of Cube is 3375
本例中定义了四个类,它们的继承关系为:Line --> Rec --> Cuboid --> Cube。
Line 是一个抽象类,也是最顶层的基类,在 Line 类中定义了两个纯虚函数 area() 和 volume()。
在 Rec 类中,实现了 area() 函数;所谓实现,就是定义了纯虚函数的函数体。但这时 Rec 仍不能被实例化,因为它没有实现继承来的 volume() 函数,volume() 仍然是纯虚函数,所以 Rec 也仍然是抽象类。
直到 Cuboid 类,才实现了 volume() 函数,才是一个完整的类,才可以被实例化。
可以发现,Line 类表示“线”,没有面积和体积,但它仍然定义了 area() 和 volume() 两个纯虚函数。这样的用意很明显:Line 类不需要被实例化,但是它为派生类提供了“约束条件”,派生类必须要实现这两个函数,完成计算面积和体积的功能,否则就不能实例化。
在实际开发中,你可以定义一个抽象基类,只完成部分功能,未完成的功能交给派生类去实现(谁派生谁实现)。这部分未完成的功能,往往是基类不需要的,或者在基类中无法实现的。虽然抽象基类没有完成,但是却强制要求派生类完成,这就是抽象基类的“霸王条款”。
抽象基类除了约束派生类的功能,还可以实现多态。请注意第 51 行代码,指针 p 的类型是 Line,但是它却可以访问派生类中的 area() 和 volume() 函数,正是由于在 Line 类中将这两个函数定义为纯虚函数;如果不这样做,51 行后面的代码都是错误的。我想,这或许才是C++提供纯虚函数的主要目的。
关于纯虚函数的几点说明
- 一个纯虚函数就可以使类成为抽象基类,但是抽象基类中除了包含纯虚函数外,还可以包含其它的成员函数(虚函数或普通函数)和成员变量。
-
- 只有类中的虚函数才能被声明为纯虚函数,普通成员函数和顶层函数均不能声明为纯虚函数。如下例所示://顶层函数不能被声明为纯虚函数
- void fun() = 0; //compile error
- class base{
- public :
- //普通成员函数不能被声明为纯虚函数
- void display() = 0; //compile error
- };
typeid运算符:获取类型信息
- typeid 运算符用来获取一个表达式的类型信息。类型信息对于编程语言非常重要,它描述了数据的各种属性:对于基本类型(int、float 等C++内置类型)的数据,类型信息所包含的内容比较简单,主要是指数据的类型。
- 对于类类型的数据(也就是对象),类型信息是指对象所属的类、所包含的成员、所在的继承关系等。
类型信息是创建数据的模板,数据占用多大内存、能进行什么样的操作、该如何操作等,这些都由它的类型信息决定。
typeid 的操作对象既可以是表达式,也可以是数据类型,下面是它的两种使用方法:typeid( dataType )
typeid( expression )dataType 是数据类型,expression 是表达式,这和 sizeof 运算符非常类似,只不过 sizeof 有时候可以省略括号( ),而 typeid 必须带上括号。
- typeid 会把获取到的类型信息保存到一个 type_info 类型的对象里面,并返回该对象的常引用;当需要具体的类型信息时,可以通过成员函数来提取。typeid 的使用非常灵活,请看下面的例子(只能在 VC/VS 下运行):#include
-
include
- using namespace std;
- class Base{ };
- struct STU{ };
- int main(){
- //获取一个普通变量的类型信息
- int n = 100;
- const type_info &nInfo = typeid(n);
- cout<<nInfo.name()<<" | "<<nInfo.raw_name()<<" | "<<nInfo.hash_code()<<endl;
- //获取一个字面量的类型信息
- const type_info &dInfo = typeid(25.65);
- cout<<dInfo.name()<<" | "<<dInfo.raw_name()<<" | "<<dInfo.hash_code()<<endl;
- //获取一个对象的类型信息
- Base obj;
- const type_info &objInfo = typeid(obj);
- cout<<objInfo.name()<<" | "<<objInfo.raw_name()<<" | "<<objInfo.hash_code()<<endl;
- //获取一个类的类型信息
- const type_info &baseInfo = typeid(Base);
- cout<<baseInfo.name()<<" | "<<baseInfo.raw_name()<<" | "<<baseInfo.hash_code()<<endl;
- //获取一个结构体的类型信息
- const type_info &stuInfo = typeid(struct STU);
- cout<<stuInfo.name()<<" | "<<stuInfo.raw_name()<<" | "<<stuInfo.hash_code()<<endl;
- //获取一个普通类型的类型信息
- const type_info &charInfo = typeid(char);
- cout<<charInfo.name()<<" | "<<charInfo.raw_name()<<" | "<<charInfo.hash_code()<<endl;
- //获取一个表达式的类型信息
- const type_info &expInfo = typeid(20 * 45 / 4.5);
- cout<<expInfo.name()<<" | "<<expInfo.raw_name()<<" | "<<expInfo.hash_code()<<endl;
- return 0;
- }
运行结果:
int | .H | 529034928
double | .N | 667332678
class Base | .?AVBase@@ | 1035034353
class Base | .?AVBase@@ | 1035034353
struct STU | .?AUSTU@@ | 734635517
char | .D | 4140304029
double | .N | 667332678
从本例可以看出,typeid 的使用非常灵活,它的操作数可以是普通变量、对象、内置类型(int、float等)、自定义类型(结构体和类),还可以是一个表达式。
- 本例中还用到了 type_info 类的几个成员函数,下面是对它们的介绍:name() 用来返回类型的名称。
- raw_name() 用来返回名字编码(Name Mangling)算法产生的新名称。关于名字编码的概念,我们已在《C++函数编译原理和成员函数的实现》中讲到。
- hash_code() 用来返回当前类型对应的 hash 值。hash 值是一个可以用来标志当前类型的整数,有点类似学生的学号、公民的身份证号、银行卡号等。不过 hash 值有赖于编译器的实现,在不同的编译器下可能会有不同的整数,但它们都能唯一地标识某个类型。
遗憾的是,C++ 标准只对 type_info 类做了很有限的规定,不仅成员函数少,功能弱,而且各个平台的实现不一致。例如上面代码中的 name() 函数,nInfo.name()、objInfo.name()在 VC/VS 下的输出结果分别是int和class Base,而在 GCC 下的输出结果分别是i和4Base。
C++ 标准规定,type_info 类至少要有如下所示的 4 个 public 属性的成员函数,其他的扩展函数编译器开发者可以自由发挥,不做限制。
- 原型:const char name() const;*
返回一个能表示类型名称的字符串。但是C++标准并没有规定这个字符串是什么形式的,例如对于上面的objInfo.name()语句,VC/VS 下返回“class Base”,但 GCC 下返回“4Base”。 - 原型:bool before (const type_info& rhs) const;
判断一个类型是否位于另一个类型的前面,rhs 参数是一个 type_info 对象的引用。但是C++标准并没有规定类型的排列顺序,不同的编译器有不同的排列规则,程序员也可以自定义。要特别注意的是,这个排列顺序和继承顺序没有关系,基类并不一定位于派生类的前面。 - 原型:bool operator== (const type_info& rhs) const;
重载运算符“==”,判断两个类型是否相同,rhs 参数是一个 type_info 对象的引用。 - 原型:bool operator!= (const type_info& rhs) const;
重载运算符“!=”,判断两个类型是否不同,rhs 参数是一个 type_info 对象的引用。关于运算符重载,我们将在《C++运算符重载》一章中详细讲解。raw_name() 是 VC/VS 独有的一个成员函数,hash_code() 在 VC/VS 和较新的 GCC 下有效。
可以发现,不像 Java、C# 等动态性较强的语言,C++ 能获取到的类型信息非常有限,也没有统一的标准,如同“鸡肋”一般,大部分情况下我们只是使用重载过的“==”运算符来判断两个类型是否相同。
判断类型是否相等
typeid 运算符经常被用来判断两个类型是否相等。1) 内置类型的比较
- 例如有下面的定义:char *str;
- int a = 2;
- int b = 10;
- float f;
类型判断结果为:
| 类型比较 | 结果 | 类型比较 | 结果 |
|---|---|---|---|
| typeid(int) == typeid(int) | true | typeid(int) == typeid(char) | false |
| typeid(char*) == typeid(char) | false | typeid(str) == typeid(char*) | true |
| typeid(a) == typeid(int) | true | typeid(b) == typeid(int) | true |
| typeid(a) == typeid(a) | true | typeid(a) == typeid(b) | true |
| typeid(a) == typeid(f) | false | typeid(a/b) == typeid(int) | true |
typeid 返回 type_info 对象的引用,而表达式typeid(a) == typeid(b)的结果为 true,可以说明,一个类型不管使用了多少次,编译器都只为它创建一个对象,所有 typeid 都返回这个对象的引用。
需要提醒的是,为了减小编译后文件的体积,编译器不会为所有的类型创建 type_info 对象,只会为使用了 typeid 运算符的类型创建。不过有一种特殊情况,就是带虚函数的类(包括继承来的),不管有没有使用 typeid 运算符,编译器都会为带虚函数的类创建 type_info 对象,我们将在《C++ RTTI机制精讲(C++运行时类型识别机制)》中展开讲解。2) 类的比较
- 例如有下面的定义:class Base{};
- class Derived: public Base{};
- Base obj1;
- Base *p1;
- Derived obj2;
- Derived *p2 = new Derived;
- p1 = p2;
类型判断结果为:
| 类型比较 | 结果 | 类型比较 | 结果 |
|---|---|---|---|
| typeid(obj1) == typeid(p1) | false | typeid(obj1) == typeid(*p1) | true |
| typeid(&obj1) == typeid(p1) | true | typeid(obj1) == typeid(obj2) | false |
| typeid(obj1) == typeid(Base) | true | typeid(*p1) == typeid(Base) | true |
| typeid(p1) == typeid(Base*) | true | typeid(p1) == typeid(Derived*) | false |
表达式typeid(p1) == typeid(Base)和typeid(p1) == typeid(Base)的结果为 true 可以说明:即使将派生类指针 p2 赋值给基类指针 p1,p1 的类型仍然为 Base*。
type_info 类的声明
- 最后我们再来看一下 type_info 类的声明,以进一步了解它所包含的成员函数以及这些函数的访问权限。type_info 类位于typeinfo头文件,声明形式类似于:class type_info {
- public:
- virtual ~type_info();
- int operator==(const type_info& rhs) const;
- int operator!=(const type_info& rhs) const;
- int before(const type_info& rhs) const;
- const char* name() const;
- const char* raw_name() const;
- private:
- void *_m_data;
- char _m_d_name[1];
- type_info(const type_info& rhs);
- type_info& operator=(const type_info& rhs);
- };
它的构造函数是 private 属性的,所以不能在代码中直接实例化,只能由编译器在内部实例化(借助友元)。而且还重载了“=”运算符,也是 private 属性的,所以也不能赋值。
运算符重载:operator
所谓重载,就是赋予新的含义。函数重载(Function Overloading)可以让一个函数名有多种功能,在不同情况下进行不同的操作。运算符重载(Operator Overloading)也是一个道理,同一个运算符可以有不同的功能。
实际上,我们已经在不知不觉中使用了运算符重载。例如,+号可以对不同类型(int、float 等)的数据进行加法操作;<<既是位移运算符,又可以配合 cout 向控制台输出数据。C++ 本身已经对这些运算符进行了重载。
C++ 也允许程序员自己重载运算符,这给我们带来了很大的便利。
- 下面的代码定义了一个复数类,通过运算符重载,可以用+号实现复数的加法运算:#include
- using namespace std;
- class complex{
- public:
- complex();
- complex(double real, double imag);
- public:
- //声明运算符重载
- complex operator+(const complex &A) const;
- void display() const;
- private:
- double m_real; //实部
- double m_imag; //虚部
- };
- complex::complex(): m_real(0.0), m_imag(0.0)
- complex::complex(double real, double imag): m_real(real), m_imag(imag)
- //实现运算符重载
- complex complex::operator+(const complex &A) const{
- complex B;
- B.m_real = this->m_real + A.m_real;
- B.m_imag = this->m_imag + A.m_imag;
- return B;
- }
- void complex::display() const{
- cout<<m_real<<" + "<<m_imag<<"i"<<endl;
- }
- int main(){
- complex c1(4.3, 5.8);
- complex c2(2.4, 3.7);
- complex c3;
- c3 = c1 + c2;
- c3.display();
- return 0;
- }
运行结果:
6.7 + 9.5i
本例中义了一个复数类 complex,m_real 表示实部,m_imag 表示虚部,第 10 行声明了运算符重载,第 21 行进行了实现(定义)。认真观察这两行代码,可以发现运算符重载的形式与函数非常类似。
运算符重载其实就是定义一个函数,在函数体内实现想要的功能,当用到该运算符时,编译器会自动调用这个函数。也就是说,运算符重载是通过函数实现的,它本质上是函数重载。
运算符重载的格式为:返回值类型 operator 运算符名称 (形参表列){
//TODO:
}operator是关键字,专门用于定义重载运算符的函数。我们可以将operator 运算符名称这一部分看做函数名,对于上面的代码,函数名就是operator+。
运算符重载函数除了函数名有特定的格式,其它地方和普通函数并没有区别。
上面的例子中,我们在 complex 类中重载了运算符+,该重载只对 complex 对象有效。当执行c3 = c1 + c2;语句时,编译器检测到+号左边(+号具有左结合性,所以先检测左边)是一个 complex 对象,就会调用成员函数operator+(),也就是转换为下面的形式:c3 = c1.operator+(c2);
c1 是要调用函数的对象,c2 是函数的实参。
- 上面的运算符重载还可以有更加简练的定义形式:complex complex::operator+(const complex &A)const{
- return complex(this->m_real + A.m_real, this->m_imag + A.m_imag);
- }
return 语句中的complex(this->m_real + A.m_real, this->m_imag + A.m_imag)会创建一个临时对象,这个对象没有名称,是一个匿名对象。在创建临时对象过程中调用构造函数,return 语句将该临时对象作为函数返回值。
在全局范围内重载运算符
- 运算符重载函数不仅可以作为类的成员函数,还可以作为全局函数。更改上面的代码,在全局范围内重载+,实现复数的加法运算:#include
- using namespace std;
- class complex{
- public:
- complex();
- complex(double real, double imag);
- public:
- void display() const;
- //声明为友元函数
- friend complex operator+(const complex &A, const complex &B);
- private:
- double m_real;
- double m_imag;
- };
- complex operator+(const complex &A, const complex &B);
- complex::complex(): m_real(0.0), m_imag(0.0)
- complex::complex(double real, double imag): m_real(real), m_imag(imag)
- void complex::display() const{
- cout<<m_real<<" + "<<m_imag<<"i"<<endl;
- }
- //在全局范围内重载+
- complex operator+(const complex &A, const complex &B){
- complex C;
- C.m_real = A.m_real + B.m_real;
- C.m_imag = A.m_imag + B.m_imag;
- return C;
- }
- int main(){
- complex c1(4.3, 5.8);
- complex c2(2.4, 3.7);
- complex c3;
- c3 = c1 + c2;
- c3.display();
- return 0;
- }
运算符重载函数不是 complex 类的成员函数,但是却用到了 complex 类的 private 成员变量,所以必须在 complex 类中将该函数声明为友元函数。
当执行c3 = c1 + c2;语句时,编译器检测到+号两边都是 complex 对象,就会转换为类似下面的函数调用:c3 = operator+(c1, c2);
小结
虽然运算符重载所实现的功能完全可以用函数替代,但运算符重载使得程序的书写更加人性化,易于阅读。运算符被重载后,原有的功能仍然保留,没有丧失或改变。通过运算符重载,扩大了C++已有运算符的功能,使之能用于对象。
函数模板:template
- 在《C++函数重载》一节中,为了交换不同类型的变量的值,我们通过函数重载定义了四个名字相同、参数列表不同的函数,如下所示://交换 int 变量的值
- void Swap(int *a, int *b){
- int temp = *a;
- *a = *b;
- *b = temp;
- }
- //交换 float 变量的值
- void Swap(float *a, float *b){
- float temp = *a;
- *a = *b;
- *b = temp;
- }
- //交换 char 变量的值
- void Swap(char *a, char *b){
- char temp = *a;
- *a = *b;
- *b = temp;
- }
- //交换 bool 变量的值
- void Swap(bool *a, bool *b){
- char temp = *a;
- *a = *b;
- *b = temp;
- }
这些函数虽然在调用时方便了一些,但从本质上说还是定义了三个功能相同、函数体相同的函数,只是数据的类型不同而已,这看起来有点浪费代码,能不能把它们压缩成一个函数呢?
能!可以借助本节讲的函数模板。
我们知道,数据的值可以通过函数参数传递,在函数定义时数据的值是未知的,只有等到函数调用时接收了实参才能确定其值。这就是值的参数化。
在C++中,数据的类型也可以通过参数来传递,在函数定义时可以不指明具体的数据类型,当发生函数调用时,编译器可以根据传入的实参自动推断数据类型。这就是类型的参数化。
值(Value)和类型(Type)是数据的两个主要特征,它们在C++中都可以被参数化。
所谓函数模板,实际上是建立一个通用函数,它所用到的数据的类型(包括返回值类型、形参类型、局部变量类型)可以不具体指定,而是用一个虚拟的类型来代替(实际上是用一个标识符来占位),等发生函数调用时再根据传入的实参来逆推出真正的类型。这个通用函数就称为函数模板(Function Template)。
在函数模板中,数据的值和类型都被参数化了,发生函数调用时编译器会根据传入的实参来推演形参的值和类型。换个角度说,函数模板除了支持值的参数化,还支持类型的参数化。
一但定义了函数模板,就可以将类型参数用于函数定义和函数声明了。说得直白一点,原来使用 int、float、char 等内置类型的地方,都可以用类型参数来代替。
- 下面我们就来实践一下,将上面的四个Swap() 函数压缩为一个函数模板:#include
- using namespace std;
- template<typename T> void Swap(T *a, T *b){
- T temp = *a;
- *a = *b;
- *b = temp;
- }
- int main(){
- //交换 int 变量的值
- int n1 = 100, n2 = 200;
- Swap(&n1, &n2);
- cout<<n1<<", "<<n2<<endl;
- //交换 float 变量的值
- float f1 = 12.5, f2 = 56.93;
- Swap(&f1, &f2);
- cout<<f1<<", "<<f2<<endl;
- //交换 char 变量的值
- char c1 = 'A', c2 = 'B';
- Swap(&c1, &c2);
- cout<<c1<<", "<<c2<<endl;
- //交换 bool 变量的值
- bool b1 = false, b2 = true;
- Swap(&b1, &b2);
- cout<<b1<<", "<<b2<<endl;
- return 0;
- }
运行结果:
200, 100
56.93, 12.5
B, A
1, 0
请读者重点关注第 4 行代码。template是定义函数模板的关键字,它后面紧跟尖括号<>,尖括号包围的是类型参数(也可以说是虚拟的类型,或者说是类型占位符)。typename是另外一个关键字,用来声明具体的类型参数,这里的类型参数就是T。从整体上看,template
模板头中包含的类型参数可以用在函数定义的各个位置,包括返回值、形参列表和函数体;本例我们在形参列表和函数体中使用了类型参数T。
类型参数的命名规则跟其他标识符的命名规则一样,不过使用 T、T1、T2、Type 等已经成为了一种惯例。
定义了函数模板后,就可以像调用普通函数一样来调用它们了。
- 在讲解C++函数重载时我们还没有学到引用(Reference),为了达到交换两个变量的值的目的只能使用指针,而现在我们已经对引用进行了深入讲解,不妨趁此机会来实践一把,使用引用重新实现 Swap() 这个函数模板:#include
- using namespace std;
- template<typename T> void Swap(T &a, T &b){
- T temp = a;
- a = b;
- b = temp;
- }
- int main(){
- //交换 int 变量的值
- int n1 = 100, n2 = 200;
- Swap(n1, n2);
- cout<<n1<<", "<<n2<<endl;
- //交换 float 变量的值
- float f1 = 12.5, f2 = 56.93;
- Swap(f1, f2);
- cout<<f1<<", "<<f2<<endl;
- //交换 char 变量的值
- char c1 = 'A', c2 = 'B';
- Swap(c1, c2);
- cout<<c1<<", "<<c2<<endl;
- //交换 bool 变量的值
- bool b1 = false, b2 = true;
- Swap(b1, b2);
- cout<<b1<<", "<<b2<<endl;
- return 0;
- }
引用不但使得函数定义简洁明了,也使得调用函数方便了很多。整体来看,引用让编码更加漂亮。
下面我们来总结一下定义模板函数的语法:
template <typename 类型参数1 , typename 类型参数2 , ...> 返回值类型 函数名(形参列表){
//在函数体中可以使用类型参数
}类型参数可以有多个,它们之间以逗号,分隔。类型参数列表以< >包围,形式参数列表以( )包围。
typename关键字也可以使用class关键字替代,它们没有任何区别。C++ 早期对模板的支持并不严谨,没有引入新的关键字,而是用 class 来指明类型参数,但是 class 关键字本来已经用在类的定义中了,这样做显得不太友好,所以后来 C++ 又引入了一个新的关键字 typename,专门用来定义类型参数。不过至今仍然有很多代码在使用 class 关键字,包括 C++ 标准库、一些开源程序等。
- 本教程会交替使用 typename 和 class,旨在让读者在别的地方遇到它们时不会感觉陌生。更改上面的 Swap() 函数,使用 class 来指明类型参数:template<class T> void Swap(T &a, T &b){
- T temp = a;
- a = b;
- b = temp;
- }
除了将 typename 替换为 class,其他都是一样的。
- 为了加深对函数模板的理解,我们再来看一个求三个数的最大值的例子:#include
- using namespace std;
- //声明函数模板
- template<typename T> T max(T a, T b, T c);
- int main( ){
- //求三个整数的最大值
- int i1, i2, i3, i_max;
- cin >> i1 >> i2 >> i3;
- i_max = max(i1,i2,i3);
- cout << "i_max=" << i_max << endl;
- //求三个浮点数的最大值
- double d1, d2, d3, d_max;
- cin >> d1 >> d2 >> d3;
- d_max = max(d1,d2,d3);
- cout << "d_max=" << d_max << endl;
- //求三个长整型数的最大值
- long g1, g2, g3, g_max;
- cin >> g1 >> g2 >> g3;
- g_max = max(g1,g2,g3);
- cout << "g_max=" << g_max << endl;
- return 0;
- }
- //定义函数模板
- template<typename T> //模板头,这里不能有分号
- T max(T a, T b, T c){ //函数头
- T max_num = a;
- if(b > max_num) max_num = b;
- if(c > max_num) max_num = c;
- return max_num;
- }
运行结果:
12 34 100↙
i_max=100
73.234 90.2 878.23↙
d_max=878.23
344 900 1000↙
g_max=1000
函数模板也可以提前声明,不过声明时需要带上模板头,并且模板头和函数定义(声明)是一个不可分割的整体,它们可以换行,但中间不能有分号。
类模板
C++ 除了支持函数模板,还支持类模板(Class Template)。函数模板中定义的类型参数可以用在函数声明和函数定义中,类模板中定义的类型参数可以用在类声明和类实现中。类模板的目的同样是将数据的类型参数化。
声明类模板的语法为:template<typename 类型参数1 , typename 类型参数2 , …> class 类名{
//TODO:
};类模板和函数模板都是以 template 开头(当然也可以使用 class,目前来讲它们没有任何区别),后跟类型参数;类型参数不能为空,多个类型参数用逗号隔开。
一但声明了类模板,就可以将类型参数用于类的成员函数和成员变量了。换句话说,原来使用 int、float、char 等内置类型的地方,都可以用类型参数来代替。
- 假如我们现在要定义一个类来表示坐标,要求坐标的数据类型可以是整数、小数和字符串,例如:x = 10、y = 10
- x = 12.88、y = 129.65
- x = "东经180度"、y = "北纬210度"
- 这个时候就可以使用类模板,请看下面的代码:template<typename T1, typename T2> //这里不能有分号
- class Point{
- public:
- Point(T1 x, T2 y): m_x(x), m_y(y)
- public:
- T1 getX() const; //获取x坐标
- void setX(T1 x); //设置x坐标
- T2 getY() const; //获取y坐标
- void setY(T2 y); //设置y坐标
- private:
- T1 m_x; //x坐标
- T2 m_y; //y坐标
- };
x 坐标和 y 坐标的数据类型不确定,借助类模板可以将数据类型参数化,这样就不必定义多个类了。注意:模板头和类头是一个整体,可以换行,但是中间不能有分号。上面的代码仅仅是类的声明,我们还需要在类外定义成员函数。在类外定义成员函数时仍然需要带上模板头,格式为:template<typename 类型参数1 , typename 类型参数2 , …>
返回值类型 类名<类型参数1 , 类型参数2, ...>::函数名(形参列表){
//TODO:
}第一行是模板头,第二行是函数头,它们可以合并到一行,不过为了让代码格式更加清晰,一般是将它们分成两行。
- 下面就对 Point 类的成员函数进行定义:template<typename T1, typename T2> //模板头
- T1 Point<T1, T2>::getX() const /函数头/ {
- return m_x;
- }
- template<typename T1, typename T2>
- void Point<T1, T2>::setX(T1 x){
- m_x = x;
- }
- template<typename T1, typename T2>
- T2 Point<T1, T2>::getY() const{
- return m_y;
- }
- template<typename T1, typename T2>
- void Point<T1, T2>::setY(T2 y){
- m_y = y;
- }
请读者仔细观察代码,除了 template 关键字后面要指明类型参数,类名 Point 后面也要带上类型参数,只是不加 typename 关键字了。另外需要注意的是,在类外定义成员函数时,template 后面的类型参数要和类声明时的一致。
使用类模板创建对象
- 上面的两段代码完成了类的定义,接下来就可以使用该类创建对象了。使用类模板创建对象时,需要指明具体的数据类型。请看下面的代码:Point<int, int> p1(10, 20);
- Point<int, float> p2(10, 15.5);
- Point<float, char*> p3(12.4, "东经180度");
与函数模板不同的是,类模板在实例化时必须显式地指明数据类型,编译器不能根据给定的数据推演出数据类型。
- 除了对象变量,我们也可以使用对象指针的方式来实例化:Point<float, float> *p1 = new Point<float, float>(10.6, 109.3);
- Point<char, char> p = new Point<char, char*>("东经180度", "北纬210度");
需要注意的是,赋值号两边都要指明具体的数据类型,且要保持一致。下面的写法是错误的:
- //赋值号两边的数据类型不一致
- Point<float, float> *p = new Point<float, int>(10.6, 109);
- //赋值号右边没有指明数据类型
- Point<float, float> *p = new Point(10.6, 109);
综合示例
- 【实例1】将上面的类定义和类实例化的代码整合起来,构成一个完整的示例,如下所示:#include
- using namespace std;
- template<class T1, class T2> //这里不能有分号
- class Point{
- public:
- Point(T1 x, T2 y): m_x(x), m_y(y)
- public:
- T1 getX() const; //获取x坐标
- void setX(T1 x); //设置x坐标
- T2 getY() const; //获取y坐标
- void setY(T2 y); //设置y坐标
- private:
- T1 m_x; //x坐标
- T2 m_y; //y坐标
- };
- template<class T1, class T2> //模板头
- T1 Point<T1, T2>::getX() const /函数头/ {
- return m_x;
- }
- template<class T1, class T2>
- void Point<T1, T2>::setX(T1 x){
- m_x = x;
- }
- template<class T1, class T2>
- T2 Point<T1, T2>::getY() const{
- return m_y;
- }
- template<class T1, class T2>
- void Point<T1, T2>::setY(T2 y){
- m_y = y;
- }
- int main(){
- Point<int, int> p1(10, 20);
- cout<<"x="<<p1.getX()<<", y="<<p1.getY()<<endl;
- Point<int, char*> p2(10, "东经180度");
- cout<<"x="<<p2.getX()<<", y="<<p2.getY()<<endl;
- Point<char, char> p3 = new Point<char, char*>("东经180度", "北纬210度");
- cout<<"x="<
getX()<<", y="< getY()<<endl; - return 0;
- }
运行结果:
x=10, y=20
x=10, y=东经180度
x=东经180度, y=北纬210度
在定义类型参数时我们使用了 class,而不是 typename,这样做的目的是让读者对两种写法都熟悉。
【实例2】用类模板实现可变长数组。
-
include
-
include
- using namespace std;
- template <class T>
- class CArray
- {
- int size; //数组元素的个数
- T *ptr; //指向动态分配的数组
- public:
- CArray(int s = 0); //s代表数组元素的个数
- CArray(CArray & a);
- ~CArray();
- void push_back(const T & v); //用于在数组尾部添加一个元素v
- CArray & operator=(const CArray & a); //用于数组对象间的赋值
- T length() { return size; }
- T & operator[](int i)
- {//用以支持根据下标访问数组元素,如a[i] = 4;和n = a[i]这样的语句
- return ptr[i];
- }
- };
- template<class T>
- CArray
::CArray(int s):size(s) - {
- if(s == 0)
- ptr = NULL;
- else
- ptr = new T[s];
- }
- template<class T>
- CArray
::CArray(CArray & a) - {
- if(!a.ptr) {
- ptr = NULL;
- size = 0;
- return;
- }
- ptr = new T[a.size];
- memcpy(ptr, a.ptr, sizeof(T ) * a.size);
- size = a.size;
- }
- template <class T>
- CArray
::~CArray() - {
- if(ptr) delete [] ptr;
- }
- template <class T>
- CArray
& CArray ::operator=(const CArray & a) - { //赋值号的作用是使"="左边对象里存放的数组,大小和内容都和右边的对象一样
- if(this == & a) //防止a=a这样的赋值导致出错
- return * this;
- if(a.ptr == NULL) { //如果a里面的数组是空的
- if( ptr )
- delete [] ptr;
- ptr = NULL;
- size = 0;
- return * this;
- }
- if(size < a.size) { //如果原有空间够大,就不用分配新的空间
- if(ptr)
- delete [] ptr;
- ptr = new T[a.size];
- }
- memcpy(ptr,a.ptr,sizeof(T)*a.size);
- size = a.size;
- return *this;
- }
- template <class T>
- void CArray
::push_back(const T & v) - { //在数组尾部添加一个元素
- if(ptr) {
- T *tmpPtr = new T[size+1]; //重新分配空间
- memcpy(tmpPtr,ptr,sizeof(T)*size); //拷贝原数组内容
- delete []ptr;
- ptr = tmpPtr;
- }
- else //数组本来是空的
- ptr = new T[1];
- ptr[size++] = v; //加入新的数组元素
- }
- int main()
- {
- CArray
a; - for(int i = 0;i < 5;++i)
- a.push_back(i);
- for(int i = 0; i < a.length(); ++i)
- cout << a[i] << " ";
- return 0;
- }
模板编程:泛型
计算机编程语言种类繁多,目前能够查询到的有 600 多种,常用的不超过 20 种,TIOBE 每个月都会发布世界编程语言排行榜,统计前 50 名编程语言的市场份额以及它们的变动趋势。该榜单反映了编程语言的热门程度,程序员可以据此来检查自己的开发技能是否跟得上趋势,公司或机构也可以据此做出战略调整。
这些编程语言根据不同的标准可以分为不同的种类,根据“在定义变量时是否需要显式地指明数据类型”可以分为强类型语言和弱类型语言。
- 强类型语言
强类型语言在定义变量时需要显式地指明数据类型,并且一旦为变量指明了某种数据类型,该变量以后就不能赋予其他类型的数据了,除非经过强制类型转换或隐式类型转换。典型的强类型语言有 C/C++、Java、C# 等。
- 下面的代码演示了如何在 C/C++ 中使用变量:int a = 100; //不转换
- a = 12.34; //隐式转换(直接舍去小数部分,得到12)
- a = (int)"http://c.biancheng.net"; //强制转换(得到字符串的地址)
- 下面的代码演示了如何在 Java 中使用变量:int a = 100; //不转换
- a = (int)12.34; //强制转换(直接舍去小数部分,得到12)
Java 对类型转换的要求比 C/C++ 更为严格,隐式转换只允许由低向高转,由高向低转必须强制转换。
2) 弱类型语言
弱类型语言在定义变量时不需要显式地指明数据类型,编译器(解释器)会根据赋给变量的数据自动推导出类型,并且可以赋给变量不同类型的数据。典型的弱类型语言有 JavaScript、Python、PHP、Ruby、Shell、Perl 等。
- 下面的代码演示了如何在 JavaScript 中使用变量:var a = 100; //赋给整数
- a = 12.34; //赋给小数
- a = "http://c.biancheng.net"; //赋给字符串
- a = new Array("JavaScript","React","JSON"); //赋给数组
var 是 JavaScript 中的一个关键字,表示定义一个新的变量,而不是数据类型。
- 下面的代码演示了如何在 PHP 中使用变量:$a = 100; //赋给整数
- $a = 12.34; //赋给小数
- $a = "http://c.biancheng.net"; //赋给字符串
- $a = array("JavaScript","React","JSON"); //赋给数组
$ 是一个特殊符号,所有的变量名都要以 $ 开头。PHP 中的变量不用特别地定义,变量名首次出现即视为定义。这里的强类型和弱类型是站在变量定义和类型转换的角度讲的,并把 C/C++ 归为强类型语言。另外还有一种说法是站在编译和运行的角度,并把 C/C++ 归为弱类型语言。本节我们只关注第一种说法。类型对于编程语言来说非常重要,不同的类型支持不同的操作,例如class Student类型的变量可以调用 display() 方法,int类型的变量就不行。不管是强类型语言还是弱类型语言,在编译器(解释器)内部都有一个类型系统来维护变量的各种信息。
对于强类型的语言,变量的类型从始至终都是确定的、不变的,编译器在编译期间就能检测某个变量的操作是否正确,这样最终生成的程序中就不用再维护一套类型信息了,从而减少了内存的使用,加快了程序的运行。
不过这种说法也不是绝对的,有些特殊情况还是要等到运行阶段才能确定变量的类型信息。比如 C++ 中的多态,编译器在编译阶段会在对象内存模型中增加虚函数表、type_info 对象等辅助信息,以维护一个完整的继承链,等到程序运行后再执行一段代码才能确定调用哪个函数,这在《C++多态与虚函数》一章中进行了详细讲解。
对于弱类型的语言,变量的类型可以随时改变,赋予它什么类型的数据它就是什么类型,编译器在编译期间不好确定变量的类型,只有等到程序运行后、真的赋给变量一个值了,才能确定变量当前是什么类型,所以传统的编译对弱类型语言意义不大,因为即使编译了也有很多东西确定不下来。
弱类型语言往往是一边执行一边编译,这样可以根据上下文(可以理解为当前的执行环境)推导出很多有用信息,让编译更加高效。我们将这种一边执行一边编译的语言称为解释型语言,而将传统的先编译后执行的语言称为编译型语言。
强类型语言较为严谨,在编译时就能发现很多错误,适合开发大型的、系统级的、工业级的项目;而弱类型语言较为灵活,编码效率高,部署容易,学习成本低,在 Web 开发中大显身手。另外,强类型语言的 IDE 一般都比较强大,代码感知能力好,提示信息丰富;而弱类型语言一般都是在编辑器中直接书写代码。
- 为了展示弱类型语言的灵活,我们以 PHP 为例来实现上节中的 Point 类,让它可以处理整数、小数以及字符串:class Point{
- public function Point($x, $y){ //构造函数
- $this -> m_x = $x;
- $this -> m_y = $y;
- }
- public function getX(){
- return $this -> m_x;
- }
- public function getY(){
- return $this -> m_y;
- }
- public function setX($x){
- $this -> m_x = $x;
- }
- public function setY($y){
- $this -> m_y = $y;
- }
- private $m_x;
- private $m_y;
- }
- $p = new Point(10, 20); //处理整数
- echo $p->getX() . ", " . $p->getY() . "
"; - $p = new Point(24.56, "东京180度"); //处理小数和字符串
- echo $p->getX() . ", " . $p->getY() . "
"; - $p = new Point("东京180度", "北纬210度"); //处理字符串
- echo $p->getX() . ", " . $p->getY() . "
";
运行结果:
10, 20
24.56, 东京180度
东京180度, 北纬210度
看,PHP 不需要使用模板就可以处理多种类型的数据,它天生对类型就不敏感。C++ 就不一样了,它是强类型的,比较“死板”,所以后来 C++ 开始支持模板了,主要就是为了弥补强类型语言“不够灵活”的缺点。
模板所支持的类型是宽泛的,没有限制的,我们可以使用任意类型来替换,这种编程方式称为泛型编程(Generic Programming)。相应地,可以将参数 T 看做是一个泛型,而将 int、float、string 等看做是一种具体的类型。除了 C++,Java、C#、Pascal(Delphi)也都支持泛型编程。
C++ 模板也是被迫推出的,最直接的动力来源于对数据结构的封装。数据结构关注的是数据的存储,以及存储后如何进行增加、删除、修改和查询操作,它是一门基础性的学科,在实际开发中有着非常广泛的应用。C++ 开发者们希望为线性表、链表、图、树等常见的数据结构都定义一个类,并把它们加入到标准库中,这样以后程序员就不用重复造轮子了,直接拿来使用即可。
但是这个时候遇到了一个无法解决的问题,就是数据结构中每份数据的类型无法提前预测。以链表为例,它的每个节点可以用来存储小数、整数、字符串等,也可以用来存储一名学生、教师、司机等,还可以直接存储二进制数据,这些都是可以的,没有任何限制。而 C++ 又是强类型的,数据的种类受到了严格的限制,这种矛盾是无法调和的。
要想解决这个问题,C++ 必须推陈出新,跳出现有规则的限制,开发新的技术,于是模板就诞生了。模板虽然不是 C++ 的首创,但是却在 C++ 中大放异彩,后来也被 Java、C# 等其他强类型语言采用。
C++ 模板有着复杂的语法,可不仅仅是前面两节讲到的那么简单,它的话题可以写一本书。C++ 模板也非常重要,整个标准库几乎都是使用模板来开发的,STL 更是经典之作。STL(Standard Template Library,标准模板库)就是 C++ 对数据结构进行封装后的称呼。
拷贝构造函数(复制构造函数)
拷贝和复制是一个意思,对应的英文单词都是copy。对于计算机来说,拷贝是指用一份原有的、已经存在的数据创建出一份新的数据,最终的结果是多了一份相同的数据。例如,将 Word 文档拷贝到U盘去复印店打印,将 D 盘的图片拷贝到桌面以方便浏览,将重要的文件上传到百度网盘以防止丢失等,都是「创建一份新数据」的意思。
在 C++ 中,拷贝并没有脱离它本来的含义,只是将这个含义进行了“特化”,是指用已经存在的对象创建出一个新的对象。从本质上讲,对象也是一份数据,因为它会占用内存。
- 严格来说,对象的创建包括两个阶段,首先要分配内存空间,然后再进行初始化:分配内存很好理解,就是在堆区、栈区或者全局数据区留出足够多的字节。这个时候的内存还比较“原始”,没有被“教化”,它所包含的数据一般是零值或者随机值,没有实际的意义。
- 初始化就是首次对内存赋值,让它的数据有意义。注意是首次赋值,再次赋值不叫初始化。初始化的时候还可以为对象分配其他的资源(打开文件、连接网络、动态分配内存等),或者提前进行一些计算(根据价格和数量计算出总价、根据长度和宽度计算出矩形的面积等)等。说白了,初始化就是调用构造函数。
很明显,这里所说的拷贝是在初始化阶段进行的,也就是用其它对象的数据来初始化新对象的内存。
- 那么,如何用拷贝的方式来初始化一个对象呢?其实这样的例子比比皆是,string 类就是一个典型的例子。#include
-
include
- using namespace std;
- void func(string str){
- cout<<str<<endl;
- }
- int main(){
- string s1 = "http://c.biancheng.net";
- string s2(s1);
- string s3 = s1;
- string s4 = s1 + " " + s2;
- func(s1);
- cout<<s1<<endl<<s2<<endl<<s3<<endl<<s4<<endl;
- return 0;
- }
运行结果:
http://c.biancheng.net http://c.biancheng.net
s1、s2、s3、s4 以及 func() 的形参 str,都是使用拷贝的方式来初始化的。对于 s1,表面上看起来是将一个字符串直接赋值给了 s1,实际上在内部进行了类型转换,将 const char * 类型转换为 string 类型后才赋值的,这点我们将在《C++转换构造函数》一节中详细讲解。s4 也是类似的道理。对于 s1、s2、s3、s4,都是将其它对象的数据拷贝给当前对象,以完成当前对象的初始化。
对于 func() 的形参 str,其实在定义时就为它分配了内存,但是此时并没有初始化,只有等到调用 func() 时,才会将其它对象的数据拷贝给 str 以完成初始化。
当以拷贝的方式初始化一个对象时,会调用一个特殊的构造函数,就是拷贝构造函数(Copy Constructor)。
- 下面的例子演示了拷贝构造函数的定义和使用:#include
-
include
- using namespace std;
- class Student{
- public:
- Student(string name = "", int age = 0, float score = 0.0f); //普通构造函数
- Student(const Student &stu); //拷贝构造函数(声明)
- public:
- void display();
- private:
- string m_name;
- int m_age;
- float m_score;
- };
- Student::Student(string name, int age, float score): m_name(name), m_age(age), m_score(score)
- //拷贝构造函数(定义)
- Student::Student(const Student &stu){
- this->m_name = stu.m_name;
- this->m_age = stu.m_age;
- this->m_score = stu.m_score;
- cout<<"Copy constructor was called."<<endl;
- }
- void Student::display(){
- cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
- }
- int main(){
- Student stu1("小明", 16, 90.5);
- Student stu2 = stu1; //调用拷贝构造函数
- Student stu3(stu1); //调用拷贝构造函数
- stu1.display();
- stu2.display();
- stu3.display();
- return 0;
- }
运行结果:
Copy constructor was called.
Copy constructor was called.
小明的年龄是16,成绩是90.5
小明的年龄是16,成绩是90.5
小明的年龄是16,成绩是90.5
第 8 行是拷贝构造函数的声明,第 20 行是拷贝构造函数的定义。拷贝构造函数只有一个参数,它的类型是当前类的引用,而且一般都是 const 引用。
- 为什么必须是当前类的引用呢?
如果拷贝构造函数的参数不是当前类的引用,而是当前类的对象,那么在调用拷贝构造函数时,会将另外一个对象直接传递给形参,这本身就是一次拷贝,会再次调用拷贝构造函数,然后又将一个对象直接传递给了形参,将继续调用拷贝构造函数……这个过程会一直持续下去,没有尽头,陷入死循环。
只有当参数是当前类的引用时,才不会导致再次调用拷贝构造函数,这不仅是逻辑上的要求,也是 C++ 语法的要求。 - 为什么是 const 引用呢?
拷贝构造函数的目的是用其它对象的数据来初始化当前对象,并没有期望更改其它对象的数据,添加 const 限制后,这个含义更加明确了。
另外一个原因是,添加 const 限制后,可以将 const 对象和非 const 对象传递给形参了,因为非 const 类型可以转换为 const 类型。如果没有 const 限制,就不能将 const 对象传递给形参,因为 const 类型不能转换为非 const 类型,这就意味着,不能使用 const 对象来初始化当前对象了。
以上面的 Student 类为例,将 const 去掉后,拷贝构造函数的原型变为:Student::Student(Student &stu);
- 此时,下面的代码就会发生错误:const Student stu1("小明", 16, 90.5);
- Student stu2 = stu1;
- Student stu3(stu1);
stu1 是 const 类型,在初始化 stu2、stu3 时,编译器希望调用Student::Student(const Student &stu),但是这个函数却不存在,又不能将 const Student 类型转换为 Student 类型去调用Student::Student(Student &stu),所以最终调用失败了。
当然,你也可以再添加一个参数为 const 引用的拷贝构造函数,这样就不会出错了。换句话说,一个类可以同时存在两个拷贝构造函数,一个函数的参数为 const 引用,另一个函数的参数为非 const 引用。
默认拷贝构造函数
在前面的教程中,我们还没有讲解拷贝构造函数,但是却已经在使用拷贝的方式创建对象了,并且也没有引发什么错误。这是因为,如果程序员没有显式地定义拷贝构造函数,那么编译器会自动生成一个默认的拷贝构造函数。这个默认的拷贝构造函数很简单,就是使用“老对象”的成员变量对“新对象”的成员变量进行一一赋值,和上面 Student 类的拷贝构造函数非常类似。
对于简单的类,默认拷贝构造函数一般是够用的,我们也没有必要再显式地定义一个功能类似的拷贝构造函数。但是当类持有其它资源时,如动态分配的内存、打开的文件、指向其他数据的指针、网络连接等,默认拷贝构造函数就不能拷贝这些资源,我们必须显式地定义拷贝构造函数,以完整地拷贝对象的所有数据
深拷贝和浅拷贝(深复制和浅复制)
- 对于基本类型的数据以及简单的对象,它们之间的拷贝非常简单,就是按位复制内存。例如:class Base{
- public:
- Base(): m_a(0), m_b(0)
- Base(int a, int b): m_a(a), m_b(b)
- private:
- int m_a;
- int m_b;
- };
- int main(){
- int a = 10;
- int b = a; //拷贝
- Base obj1(10, 20);
- Base obj2 = obj1; //拷贝
- return 0;
- }
b 和 obj2 都是以拷贝的方式初始化的,具体来说,就是将 a 和 obj1 所在内存中的数据按照二进制位(Bit)复制到 b 和 obj2 所在的内存,这种默认的拷贝行为就是浅拷贝,这和调用 memcpy() 函数的效果非常类似。
对于简单的类,默认的拷贝构造函数一般就够用了,我们也没有必要再显式地定义一个功能类似的拷贝构造函数。但是当类持有其它资源时,例如动态分配的内存、指向其他数据的指针等,默认的拷贝构造函数就不能拷贝这些资源了,我们必须显式地定义拷贝构造函数,以完整地拷贝对象的所有数据。
- 下面我们通过一个具体的例子来说明显式定义拷贝构造函数的必要性。我们知道,有些较老的编译器不支持变长数组,例如 VC6.0、VS2010 等,这有时候会给编程带来不便,下面我们通过自定义的 Array 类来实现变长数组。#include
-
include
- using namespace std;
- //变长数组类
- class Array{
- public:
- Array(int len);
- Array(const Array &arr); //拷贝构造函数
- ~Array();
- public:
- int operator[](int i) const { return m_p[i]; } //获取元素(读取)
- int &operator[](int i){ return m_p[i]; } //获取元素(写入)
- int length() const { return m_len; }
- private:
- int m_len;
- int *m_p;
- };
- Array::Array(int len): m_len(len){
- m_p = (int*)calloc( len, sizeof(int) );
- }
- Array::Array(const Array &arr){ //拷贝构造函数
- this->m_len = arr.m_len;
- this->m_p = (int*)calloc( this->m_len, sizeof(int) );
- memcpy( this->m_p, arr.m_p, m_len * sizeof(int) );
- }
- Array::~Array()
- //打印数组元素
- void printArray(const Array &arr){
- int len = arr.length();
- for(int i=0; i<len; i++){
- if(i == len-1){
- cout<<arr[i]<<endl;
- }else{
- cout<<arr[i]<<", ";
- }
- }
- }
- int main(){
- Array arr1(10);
- for(int i=0; i<10; i++){
- arr1[i] = i;
- }
- Array arr2 = arr1;
- arr2[5] = 100;
- arr2[3] = 29;
- printArray(arr1);
- printArray(arr2);
- return 0;
- }
运行结果:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
0, 1, 2, 29, 4, 100, 6, 7, 8, 9
本例中我们显式地定义了拷贝构造函数,它除了会将原有对象的所有成员变量拷贝给新对象,还会为新对象再分配一块内存,并将原有对象所持有的内存也拷贝过来。这样做的结果是,原有对象和新对象所持有的动态内存是相互独立的,更改一个对象的数据不会影响另外一个对象,本例中我们更改了 arr2 的数据,就没有影响 arr1。
这种将对象所持有的其它资源一并拷贝的行为叫做深拷贝,我们必须显式地定义拷贝构造函数才能达到深拷贝的目的。
深拷贝的例子比比皆是,除了上面的变长数组类,我们在《C++ throw关键字》一节中使用的动态数组类也需要深拷贝;此外,标准模板库(STL)中的 string、vector、stack、set、map 等也都必须使用深拷贝。
读者如果希望亲眼目睹不使用深拷贝的后果,可以将上例中的拷贝构造函数删除,那么运行结果将变为:0, 1, 2, 29, 4, 100, 6, 7, 8, 9
0, 1, 2, 29, 4, 100, 6, 7, 8, 9可以发现,更改 arr2 的数据也影响到了 arr1。这是因为,在创建 arr2 对象时,默认拷贝构造函数将 arr1.m_p 直接赋值给了 arr2.m_p,导致 arr2.m_p 和 arr1.m_p 指向了同一块内存,所以会相互影响。
另外需要注意的是,printArray() 函数的形参为引用类型,这样做能够避免在传参时调用拷贝构造函数;又因为 printArray() 函数不会修改任何数组元素,所以我们添加了 const 限制,以使得语义更加明确。
到底是浅拷贝还是深拷贝
如果一个类拥有指针类型的成员变量,那么绝大部分情况下就需要深拷贝,因为只有这样,才能将指针指向的内容再复制出一份来,让原有对象和新生对象相互独立,彼此之间不受影响。如果类的成员变量没有指针,一般浅拷贝足以。
- 另外一种需要深拷贝的情况就是在创建对象时进行一些预处理工作,比如统计创建过的对象的数目、记录对象创建的时间等,请看下面的例子:#include
-
include
-
include <windows.h> //在Linux和Mac下要换成 unistd.h 头文件
- using namespace std;
- class Base{
- public:
- Base(int a = 0, int b = 0);
- Base(const Base &obj); //拷贝构造函数
- public:
- int getCount() const { return m_count; }
- time_t getTime() const { return m_time; }
- private:
- int m_a;
- int m_b;
- time_t m_time; //对象创建时间
- static int m_count; //创建过的对象的数目
- };
- int Base::m_count = 0;
- Base::Base(int a, int b): m_a(a), m_b(b){
- m_count++;
- m_time = time((time_t*)NULL);
- }
- Base::Base(const Base &obj){ //拷贝构造函数
- this->m_a = obj.m_a;
- this->m_b = obj.m_b;
- this->m_count++;
- this->m_time = time((time_t*)NULL);
- }
- int main(){
- Base obj1(10, 20);
- cout<<"obj1: count = "<<obj1.getCount()<<", time = "<<obj1.getTime()<<endl;
- Sleep(3000); //在Linux和Mac下要写作 sleep(3);
- Base obj2 = obj1;
- cout<<"obj2: count = "<<obj2.getCount()<<", time = "<<obj2.getTime()<<endl;
- return 0;
- }
运行结果:
obj1: count = 1, time = 1488344372
obj2: count = 2, time = 1488344375
运行程序,先输出第一行结果,等待 3 秒后再输出第二行结果。Base 类中的 m_time 和 m_count 分别记录了对象的创建时间和创建数目,它们在不同的对象中有不同的值,所以需要在初始化对象的时候提前处理一下,这样浅拷贝就不能胜任了,就必须使用深拷贝了。
重载=(赋值运算符)
在《到底什么时候会调用拷贝构造函数?》一节中,我们讲解了初始化和赋值的区别:在定义的同时进行赋值叫做初始化(Initialization),定义完成以后再赋值(不管在定义的时候有没有赋值)就叫做赋值(Assignment)。初始化只能有一次,赋值可以有多次。
当以拷贝的方式初始化一个对象时,会调用拷贝构造函数;当给一个对象赋值时,会调用重载过的赋值运算符。
即使我们没有显式的重载赋值运算符,编译器也会以默认地方式重载它。默认重载的赋值运算符功能很简单,就是将原有对象的所有成员变量一一赋值给新对象,这和默认拷贝构造函数的功能类似。
对于简单的类,默认的赋值运算符一般就够用了,我们也没有必要再显式地重载它。但是当类持有其它资源时,例如动态分配的内存、打开的文件、指向其他数据的指针、网络连接等,默认的赋值运算符就不能处理了,我们必须显式地重载它,这样才能将原有对象的所有数据都赋值给新对象。
- 仍然以上节的 Array 类为例,该类拥有一个指针成员,指向动态分配的内存。为了让 Array 类的对象之间能够正确地赋值,我们必须重载赋值运算符。请看下面的代码:#include
- include
- using namespace std;
- //变长数组类
- class Array{
- public:
- Array(int len);
- Array(const Array &arr); //拷贝构造函数
- ~Array();
- public:
- int operator[](int i) const { return m_p[i]; } //获取元素(读取)
- int &operator[](int i){ return m_p[i]; } //获取元素(写入)
- Array & operator=(const Array &arr); //重载赋值运算符
- int length() const { return m_len; }
- private:
- int m_len;
- int *m_p;
- };
- Array::Array(int len): m_len(len){
- m_p = (int*)calloc( len, sizeof(int) );
- }
- Array::Array(const Array &arr){ //拷贝构造函数
- this->m_len = arr.m_len;
- this->m_p = (int*)calloc( this->m_len, sizeof(int) );
- memcpy( this->m_p, arr.m_p, m_len * sizeof(int) );
- }
- Array::~Array()
- Array &Array::operator=(const Array &arr){ //重载赋值运算符
- if( this != &arr){ //判断是否是给自己赋值
- this->m_len = arr.m_len;
- free(this->m_p); //释放原来的内存
- this->m_p = (int*)calloc( this->m_len, sizeof(int) );
- memcpy( this->m_p, arr.m_p, m_len * sizeof(int) );
- }
- return *this;
- }
- //打印数组元素
- void printArray(const Array &arr){
- int len = arr.length();
- for(int i=0; i<len; i++){
- if(i == len-1){
- cout<<arr[i]<<endl;
- }else{
- cout<<arr[i]<<", ";
- }
- }
- }
- int main(){
- Array arr1(10);
- for(int i=0; i<10; i++){
- arr1[i] = i;
- }
- printArray(arr1);
- Array arr2(5);
- for(int i=0; i<5; i++){
- arr2[i] = i;
- }
- printArray(arr2);
- arr2 = arr1; //调用operator=()
- printArray(arr2);
- arr2[3] = 234; //修改arr1的数据不会影响arr2
- arr2[7] = 920;
- printArray(arr1);
- return 0;
- }
运行结果:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
0, 1, 2, 3, 4
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
将 arr1 赋值给 arr2 后,修改 arr2 的数据不会影响 arr1。如果把 operator=() 注释掉,那么运行结果将变为:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
0, 1, 2, 3, 4
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
0, 1, 2, 234, 4, 5, 6, 920, 8, 9去掉operator=()后,由于 m_p 指向的堆内存会被 free() 两次,所以还会导致内存错误。下面我们就来分析一下重载过的赋值运算符。
- operator=() 的返回值类型为Array &,这样不但能够避免在返回数据时调用拷贝构造函数,还能够达到连续赋值的目的。下面的语句就是连续赋值:arr4 = arr3 = arr2 = arr1;
- if( this != &arr)语句的作用是「判断是否是给同一个对象赋值」:如果是,那就什么也不做;如果不是,那就将原有对象的所有成员变量一一赋值给新对象,并为新对象重新分配内存。下面的语句就是给同一个对象赋值:arr1 = arr1;
arr2 = arr2; - return *this表示返回当前对象(新对象)。
- operator=() 的形参类型为const Array &,这样不但能够避免在传参时调用拷贝构造函数,还能够同时接收 const 类型和非 const 类型的实参,这一点已经在《C++拷贝构造函数》中进行了详细讲解。
- 赋值运算符重载函数除了能有对象引用这样的参数之外,也能有其它参数。但是其它参数必须给出默认值,例如:Array & operator=(const Array &arr, int a = 100);
lambda

explicit关键字
首先, C++中的explicit关键字只能用于修饰只有一个参数的类构造函数, 它的作用是表明该构造函数是显示的, 而非隐式的, 跟它相对应的另一个关键字是implicit, 意思是隐藏的,类构造函数默认情况下即声明为implicit(隐式).
explicit关键字的作用就是防止类构造函数的隐式自动转换.
C++ 信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 Ctrl+C 产生中断。
有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作。这些信号是定义在 C++ 头文件
| 信号 | 描述 |
| SIGABRT | 程序的异常终止,如调用 abort。 |
| SIGFPE | 错误的算术运算,比如除以零或导致溢出的操作。 |
| SIGILL | 检测非法指令。 |
| SIGINT | 程序终止(interrupt)信号。 |
| SIGSEGV | 非法访问内存。 |
| SIGTERM | 发送到程序的终止请求。 |
signal() 函数
C++ 信号处理库提供了 signal 函数,用来捕获突发事件。以下是 signal() 函数的语法:
void (signal (int sig, void (func)(int)))(int); 这个看起来有点费劲,以下语法格式更容易理解:
signal(registered signal, signal handler)这个函数接收两个参数:第一个参数是一个整数,代表了信号的编号;第二个参数是一个指向信号处理函数的指针。
让我们编写一个简单的 C++ 程序,使用 signal() 函数捕获 SIGINT 信号。不管您想在程序中捕获什么信号,您都必须使用 signal 函数来注册信号,并将其与信号处理程序相关联。看看下面的实例:
实例
当上面的代码被编译和执行时,它会产生下列结果:
Going to sleep....Going to sleep....Going to sleep....现在,按 Ctrl+C 来中断程序,您会看到程序捕获信号,程序打印如下内容并退出:
Going to sleep....Going to sleep....Going to sleep....Interrupt signal (2) received.
raise() 函数
您可以使用函数 raise() 生成信号,该函数带有一个整数信号编号作为参数,语法如下:
int raise (signal sig);在这里,sig 是要发送的信号的编号,这些信号包括:SIGINT、SIGABRT、SIGFPE、SIGILL、SIGSEGV、SIGTERM、SIGHUP。以下是我们使用 raise() 函数内部生成信号的实例:
Sleep 函数
功能:执行挂起一段时间,也就是等待一段时间在继续执行
用法:Sleep(时间)
注意:
a. (1)Sleep 是区分大小写的,有的编译器是大写,有的是小写。
b. (2)Sleep 括号里的时间,在 Windows 下是以毫秒为单位,而 Linux 是以秒为单位。
include
include
include <windows.h>
using namespace std;
void signalHandler(int signum)
{
cout << "Interrupt signal (" << signum << ") received.\n";
// 清理并关闭
// 终止程序
exit(signum);
}
int main()
{
int i = 0;
// 注册信号 SIGINT 和信号处理程序
signal(SIGINT, signalHandler);
while (++i) {
cout << "Going to sleep...." << endl;
if (i == 3) {
raise(SIGINT);
}
Sleep(1000);
}
return 0;
}
发布于 2023-04-17 11:10・IP 属地山东C++语法C++ Primer(书籍)赞同添加评论分享喜欢收藏设置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号