TFIDF介绍
任务一:现在有一篇长文《中国的蜜蜂养殖》,用计算机提取它的关键词。
1、词频:如果某个词很重要,它应该在这篇文章中多次出现。我们进行"词频"(Term Frequency,缩写为TF)统计。
2、停用词:结果你肯定猜到了,出现次数最多的词是----"的"、"是"、"在"----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
规则一:如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词
发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多
因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见,"蜜蜂"和"养殖"的重要程度要大于"中国"
3、IDF :最常见的词("的"、"是"、"在")给予最小的权重,
较常见的词("中国")给予较小的权重,
较少见的词("蜜蜂"、"养殖")给予较大的权重。
这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),
它的大小与一个词的常见程度成反比。
4、TF-IDF:"词频"(TF)和"逆文档频率"(IDF)以后,两个值相乘,得到了一个词的TF-IDF值。
某个词对文章的重要性越高,它的TF-IDF值就越大。
所以,排在最前面的几个词,就是这篇文章的关键词。
具体实现:
1、计算词频
词频(TF) = 某个词在文章中的出现次数
文章有长短之分,为了便于不同文章的比较,做"词频"标准化。
词频(TF) = 某个词在文章中的出现次数 / 文章总词数
或者 词频(TF) = 某个词在文章中的出现次数 / 拥有最高词频的词的次数
2、某个词在文章中的出现次数
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
逆文档频率(IDF) = log(语料库的文档总数/包含该词的文档总数+1)
3、计算TF-IDF
TF-IDF = 词频(TF) * 逆文档频率(IDF)
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
所以,自动提取关键词的算法就是计算出文档的每个词的TF-IDF值,
然后按降序排列,取排在最前面的几个词。
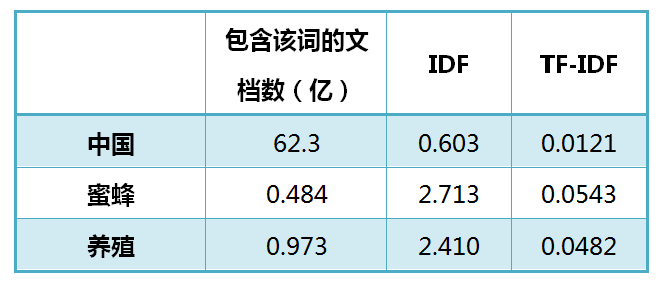
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)
所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
总结:
TF-IDF算法的优点是简单快速,结果比较符合实际情况。
缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。
(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
任务二:TF-IDF与与余弦相似的应用:找相似文章
除了找到关键词,还希望找到与原文章相似的其他文章
需要用到余弦相似性:
句子A:我喜欢看电视,不喜欢看电影
句子B:我不喜欢看电视,也不喜欢看电影
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。
因此,可以从词频入手,计算它们的相似程度。
1、分词
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
2、列出所有值
我,喜欢,看,电视,电影,不,也。
3、计算词频
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1
4、写出词频向量。
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式
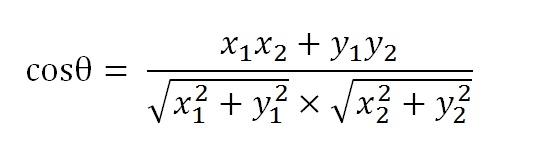
结论:
我们就得到了"找出相似文章"的一种算法:
- 使用TF-IDF算法,找出两篇文章的关键词
- 每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
- 生成两篇文章各自的词频向量
- 计算两个向量的余弦相似度,值越大就表示越相似
计算两个向量的余弦相似度,值越大就表示越相似
任务三:如何通过词频,对文章进行自动摘要
信息都包含在句子中,有些句子包含的信息多,有些句子包含的信息少。
"自动摘要"就是要找出那些包含信息最多的句子。
句子的信息量用"关键词"来衡量。如果包含的关键词越多,就说明这个句子越重要。
Luhn提出用"簇"(cluster)表示关键词的聚集。所谓"簇"就是包含多个关键词的句子片段。
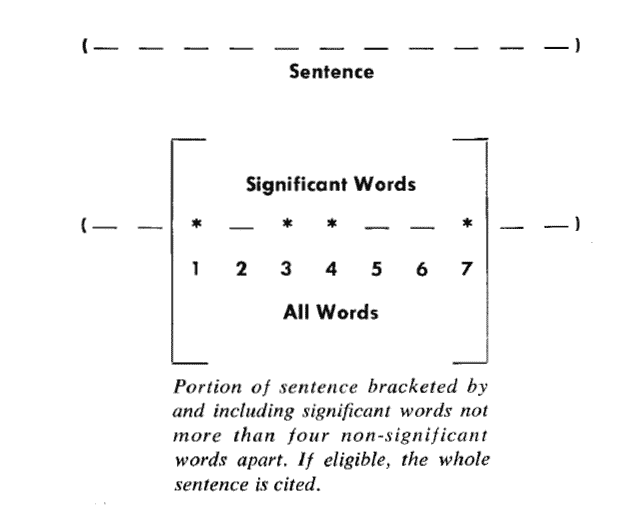
只要关键词之间的距离小于"门槛值",它们就被认为处于同一个簇之中。Luhn建议的门槛值是4或5。
也就是说,如果两个关键词之间有5个以上的其他词,就可以把这两个关键词分在两个簇。
簇的重要性 = (包含的关键词数量)^2 / 簇的长度
其中的簇一共有7个词,其中4个是关键词。因此,它的重要性分值等于 ( 4 x 4 ) / 7 = 2.3。
然后,找出包含分值最高的簇的句子(比如5句),把它们合在一起,就构成了这篇文章的自动摘要


1 Summarizer(originalText, maxSummarySize): 2 // 计算原始文本的词频,生成一个数组,比如[(10,'the'), (3,'language'), (8,'code')...] 3 wordFrequences = getWordCounts(originalText) 4 // 过滤掉停用词,数组变成[(3, 'language'), (8, 'code')...] 5 contentWordFrequences = filtStopWords(wordFrequences) 6 // 按照词频进行排序,数组变成['code', 'language'...] 7 contentWordsSortbyFreq = sortByFreqThenDropFreq(contentWordFrequences) 8 // 将文章分成句子 9 sentences = getSentences(originalText) 10 // 选择关键词首先出现的句子 11 setSummarySentences = {} 12 foreach word in contentWordsSortbyFreq: 13 firstMatchingSentence = search(sentences, word) 14 setSummarySentences.add(firstMatchingSentence) 15 if setSummarySentences.size() = maxSummarySize: 16 break 17 // 将选中的句子按照出现顺序,组成摘要 18 summary = "" 19 foreach sentence in sentences: 20 if sentence in setSummarySentences: 21 summary = summary + " " + sentence 22 return summary

 浙公网安备 33010602011771号
浙公网安备 33010602011771号