zlib 压缩输出缓冲区 overflow 问题
问题
后台服务传包太大时,我们框架可以使用 zlib 库对响应进行压缩;在这次服务调试过程中,使用 zlib compress2 以 Z_BEST_COMPRESSION 模式进行压缩时,报 Z_BUF_ERROR(-5) 错误
分析
bool Codec::ZlibCompress(const std::string& src , std::string& compr_str)
{
int max_size = src.size();
if(max_size == 0)
{
return false;
}
DataBuffer<char> compr(max_size);
memset(compr, 0, max_size);
uLongf compr_len = max_size;
int res = compress2((Bytef*)compr.Get(),&compr_len,(const Bytef*)(src.c_str()),src.size(),9);
if(res != Z_OK)
{
return false;
}
compr_str = Base64Encode((const void*)compr,compr_len);
return true;
}
这里 compress2 的输出缓冲区大小设置成为待压缩原串的长度了,在压缩数据太小或随机性很大等情况下,压缩得到的数据可能会比原来的大,导致 Z_BUF_ERROR;
下面的数据是对随机字符的压缩情况,src_size 为原串大小,compr size 为压缩后长度,说明在字符很随机的情况下,压缩完再使用 Base64Encode(Base64 编码数据会增大 1/3),长度一般都会变大。
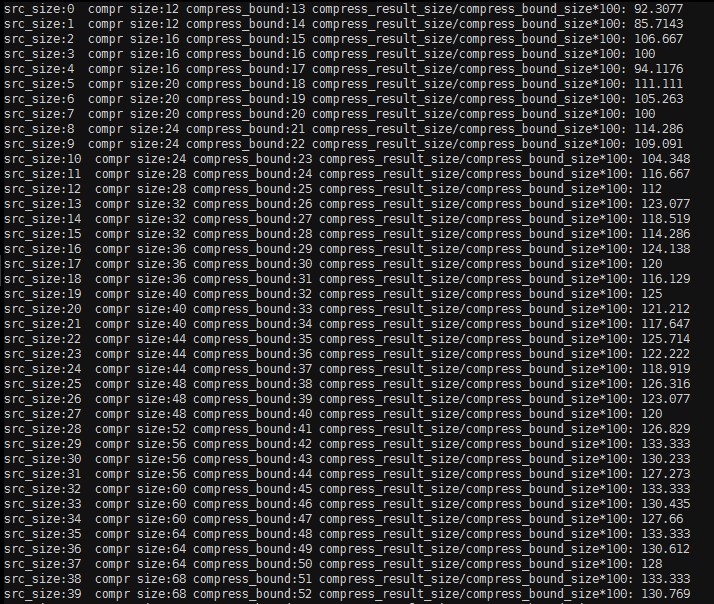
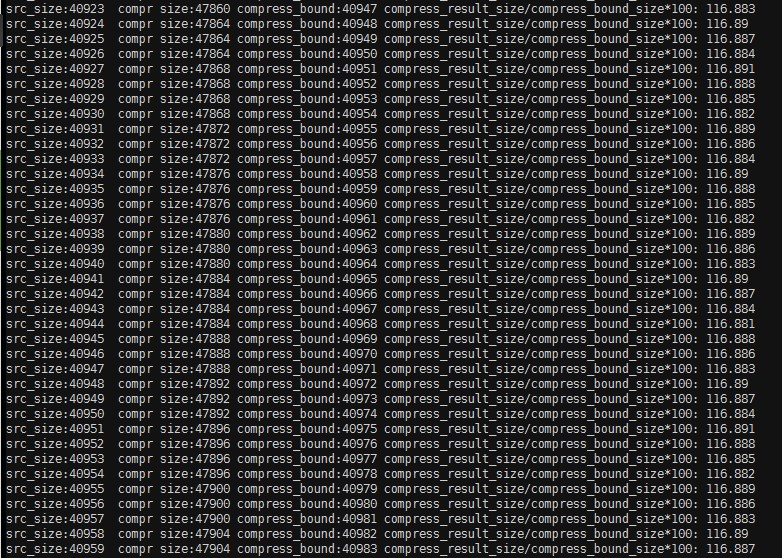
解决
int compressBound(uLong sourceLen);
zlib 提供了一个 compressBound 方法,用于估算调用一次 compress2()/compress(),用于压缩 sourceLen 长度数据所需输出缓冲区的最大大小。
但是框架压缩后,对压缩串进行 Base64 编码(Base64 编码数据会增大 1/3),最终的输出缓冲区大小应该至少设置为 compressBound(sourceLen) * 4 / 3,因此改后的代码为:
bool Codec::ZlibCompress(const std::string& src , std::string& compr_str)
{
int src_size = src.size();
// 原串则不进行压缩,且压缩输出串置空
if(0 == src_size)
{
compr_str = "";
return true;
}
/*
经过测试,在 best_compress(9) 的模式下,由随机字符构成的原串,压缩输出串有可能比原串长度大
由随机字符构成的原串,长度在 0-40k 情况下,output_buffer_size / compressBound() * 100 最大为 133.33(best_compress 和 best_speed 下此值一样)
为保证输出缓冲区足够大,缓冲区大小设置为 compressBound() * 2
*/
int max_size = compressBound(src_size) * 2;
// 如果得到的输出缓冲区大小不大于 0,则返回压缩失败
if(max_size <= 0)
{
return false;
}
DataBuffer<char> compr(max_size);
uLongf compr_len = max_size;
int res = compress2((Bytef*)compr.Get(),&compr_len,(const Bytef*)(src.c_str()),src_size,9);
if(res != Z_OK)
{
return false;
}
compr_str = Base64Encode((const void*)compr,compr_len);
return true;
}
bool Codec::ZlibDecompress(const std::string& base64_src , std::string& decmpr_str)
{
int size = base64_src.size();
if(0 == size)
{
decmpr_str = "";
return true;
}
DataBuffer<char> src(base64_src.size());
int base64_res = Base64Decode((const char*)(base64_src.c_str()),base64_src.size(),(void*)src,&size);
if(base64_res != 0)
{
return false;
}
int max_size = size*30;
DataBuffer<char> decompr(max_size);
uLongf decompr_len = max_size;
uLong src_size = size;
int res = uncompress2((Bytef*)decompr.Get(),&decompr_len,(const Bytef*)src.Get(),&src_size);
if(res != Z_OK)
{
return false;
}
decmpr_str = std::string(decompr , decompr_len);
return true;
}
参考
compressBound
http://refspecs.linuxbase.org/LSB_3.0.0/LSB-PDA/LSB-PDA/zlib-compressbound-1.html
In what situation would compressed data be larger than input?
https://stackoverflow.com/questions/16992754/in-what-situation-would-compressed-data-be-larger-than-input
zlib详细基础教程
https://www.0xaa55.com/thread-442-1-1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号