ElasticSearch学习一 基础概念
一、概述
2.1、逻辑概念
Cluster:集群,由一个或多个Elasticsearch节点组成。
Node:节点,组成Elasticsearch集群的服务单元,同一个集群内节点的名字不能重复。通常在一个节点上分配一个或者多个分片。
Shards:分片,当索引上的数据量太大的时候,我们通常会将一个索引上的数据进行水平拆分,拆分出来的每个数据库叫作一个分片。在一个多分片的索引中写入数据时,通过路由来确定具体写入那一个分片中,所以在创建索引时需要指定分片的数量,并且分片的数量一旦确定就不能更改。分片后的索引带来了规模上(数据水平切分)和性能上(并行执行)的提升。每个分片都是Luence中的一个索引文件,每个分片必须有一个主分片和零到多个副本分片。
Replicas:备份也叫作副本,是指对主分片的备份。主分片和备份分片都可以对外提供查询服务,写操作时先在主分片上完成,然后分发到备份上。当主分片不可用时,会在备份的分片中选举出一个作为主分片,所以备份不仅可以提升系统的高可用性能,还可以提升搜索时的并发性能。但是若副本太多的话,在写操作时会增加数据同步的负担。
Index:索引,由一个和多个分片组成,通过索引的名字在集群内进行唯一标识。
Type:类别,指索引内部的逻辑分区,通过Type的名字在索引内进行唯一标识。在查询时如果没有该值,则表示在整个索引中查询。
Document:文档,索引中的每一条数据叫作一个文档,类似于关系型数据库中的一条数据通过_id在Type内进行唯一标识。
Settings:对集群中索引的定义,比如一个索引默认的分片数、副本数等信息。
Mapping:类似于关系型数据库中的表结构信息,用于定义索引中字段(Field)的存储类型、分词方式、是否存储等信息。Elasticsearch中的mapping是可以动态识别的。如果没有特殊需求,则不需要手动创建mapping,因为Elasticsearch会自动根据数据格式识别它的类型,但是当需要对某些字段添加特殊属性(比如:定义使用其他分词器、是否分词、是否存储等)时,就需要手动设置mapping了。一个索引的mapping一旦创建,若已经存储了数据,就不可修改了。
Analyzer:字段的分词方式的定义。一个analyzer通常由一个tokenizer、零到多个filter组成。比如默认的标准Analyzer包含一个标准的tokenizer和三个filter:Standard Token Filter、Lower Case Token Filter、Stop Token Filter。 Elasticsearch的节点的分类如下:
主节点(Master Node):也叫作主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch中的主节点的工作量相对较轻。用户的请求可以发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而并不需要经过主节点转发。通过在配置文件中设置node.master=true来设置该节点成为候选主节点(但该节点不一定是主节点,主节点是集群在候选节点中选举出来的),在Elasticsearch集群中只有候选节点才有选举权和被选举权。其他节点是不参与选举工作的。
数据节点(Data Node):数据节点,负责数据的存储和相关具体操作,比如索引数据的创建、修改、删除、搜索、聚合。所以,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和I/O的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。通过在配置文件中设置node.data=true来设置该节点成为数据节点。
客户端节点(Client Node):就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等,也就是下面要说到的协调节点的角色。其实任何一个节点都可以完成这样的工作,单独增加这样的节点更多地是为了提高并发性。可在配置文件中设置该节点成为数据节点:
node.master=false
node.data=false-
部落节点(Tribe Node):部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态,它可以读写所有集群节点上的数据,在配置文件中通过如下设置使节点成为部落节点:
tribe:
one:
cluster.name: cluster_one
two:
cluster.name: cluster_two因为Tribe Node要在Elasticsearch 7.0以后移除,所以不建议使用。
协调节点(Coordinating Node):协调节点,是一种角色,而不是真实的Elasticsearch的节点,我们没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询语句分发到其他的节点,然后合并各个节点返回的查询结果,最好返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。由此可见,协调节点会对CPU、Memory和I/O要求比较高。 集群的状态有Green、Yellow和Red三种,如下所述:
Green:绿色,健康。所有的主分片和副本分片都可正常工作,集群100%健康。
Yellow:黄色,预警。所有的主分片都可以正常工作,但至少有一个副本分片是不能正常工作的。此时集群可以正常工作,但是集群的高可用性在某种程度上被弱化。
Red:红色,集群不可正常使用。集群中至少有一个分片的主分片及它的全部副本分片都不可正常工作。这时虽然集群的查询操作还可以进行,但是也只能返回部分数据(其他正常分片的数据可以返回),而分配到这个分片上的写入请求将会报错,最终会导致数据的丢失。
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引 比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
关系型数据库对比
ElasticSearch是面向文档,关系行数据库和ElasticSearch客观对比!一切都是JSON!
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types <慢慢会被弃用!> |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行) ,每个文档中又包含多个字段(列)。1、索引(ElasticSearch):包多个分片 2、字段类型(映射):字段类型映射(字段是整型,还是字符型…) 3、文档
4、分片(Lucene索引,倒排索引)
2.2、物理设计
elasticsearch在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移
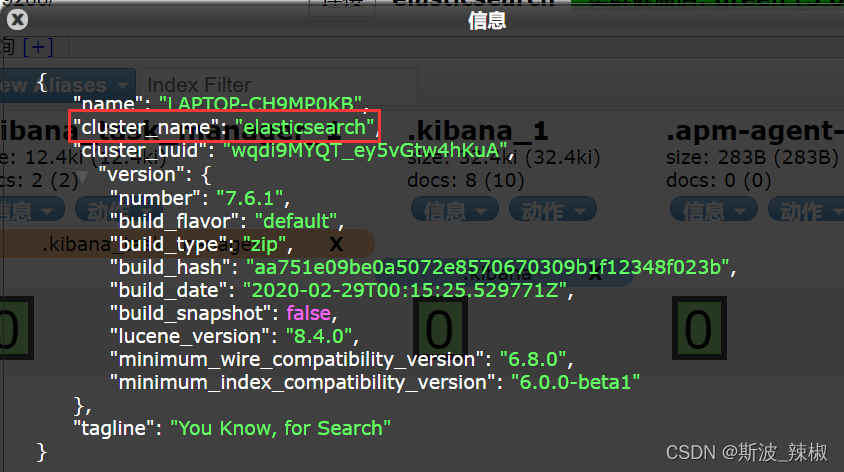
一个分片就是一个集群! ,即启动的ElasticSearch服务,默认就是一个集群,且默认集群名为elasticsearch
2.3、逻辑设计
一个索引类型中,包含多个文档,比如说文档1,文档2。
当我们索引一篇文档时,可以通过这样的顺序找到它:索引 => 类型 => 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
文档(”行“)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档。
elasticsearch中,文档有几个重要属性:
-
自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value !
-
可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象 ! fastjson进行自动转换 !}
-
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
-
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型(“表”)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
类型中对于字段的定义称为映射,比如name映射为字符串类型。
我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引(“库”)
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号