


scrapy获取58同城数据
1. scrapy项目的结构 项目名字 项目名字 spiders文件夹 (存储的是爬虫文件) init 自定义的爬虫文件 核心功能文件 **************** init items 定义数据结构的地方 爬取的数据都包含哪些 middleware 中间件 代理 pipelines 管道 用来处理下载的数据 settings 配置文件 robots协议 ua定义等 2. response的属性和方法 response.text 获取的是响应的字符串
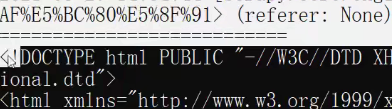
response.body 获取的是二进制数据

response.xpath 可以直接是xpath方法来解析response中的内容
response.extract() 提取seletor对象的data属性值
response.extract_first() 提取的seletor列表的第一个数据
1、创建scrapy项目
> scrapy startproject scrapy_58tc
文件路径scrapy_58tc\scrapy_58tc
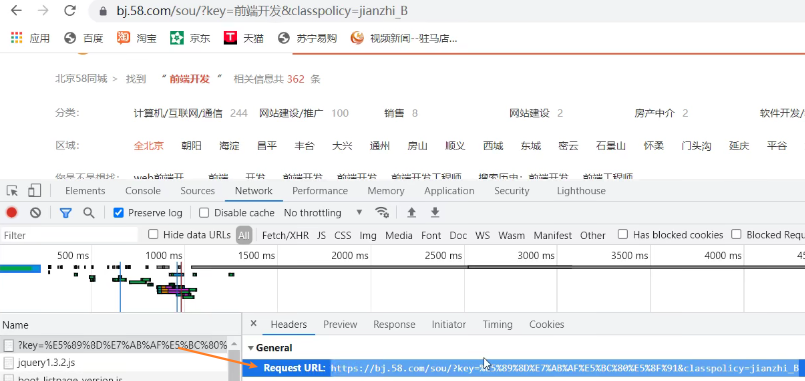
2、找到访问接口
4、创建爬虫文件
scrapy_58tc\scrapy_58tc\spiders> scrapy genspider tc https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=jianzhi_B
文件路径scrapy_58tc\scrapy_58tc\spiders\spiders

提示遵守robots协议

注释spider目录下的settings中的遵守robots协议

ty.py
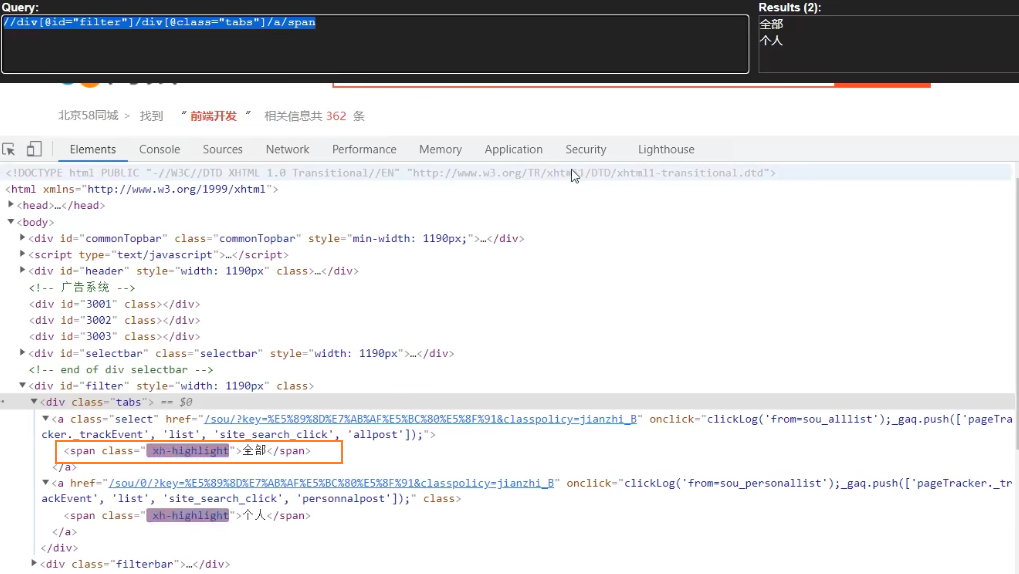
import scrapy class TcSpider(scrapy.Spider): name = 'tc' allowed_domains = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91'] start_urls = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91'] def parse(self, response): # 字符串 # content = response.text # 二进制数据 # content = response.body # print('===========================') # print(content) # 获取列表中的第一元素 span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0] print('=======================')
#获取Seletor对象的data属性值 print(span.extract())
print(span)

运行爬虫文件
scrapy_58tc\scrapy_58tc\spiders> scrapy crawl tc
print(span.extract())


 浙公网安备 33010602011771号
浙公网安备 33010602011771号