import urllib.request
# 请求url
url = 'https://www.starbucks.com.cn/menu/'
# 模拟浏览器发出请求
response = urllib.request.urlopen(url)
# 获取响应数据(read读方法返回字节形式二进制数据.decode解码)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
# 服务器响应的文件生成对象
soup = BeautifulSoup(content,'lxml')
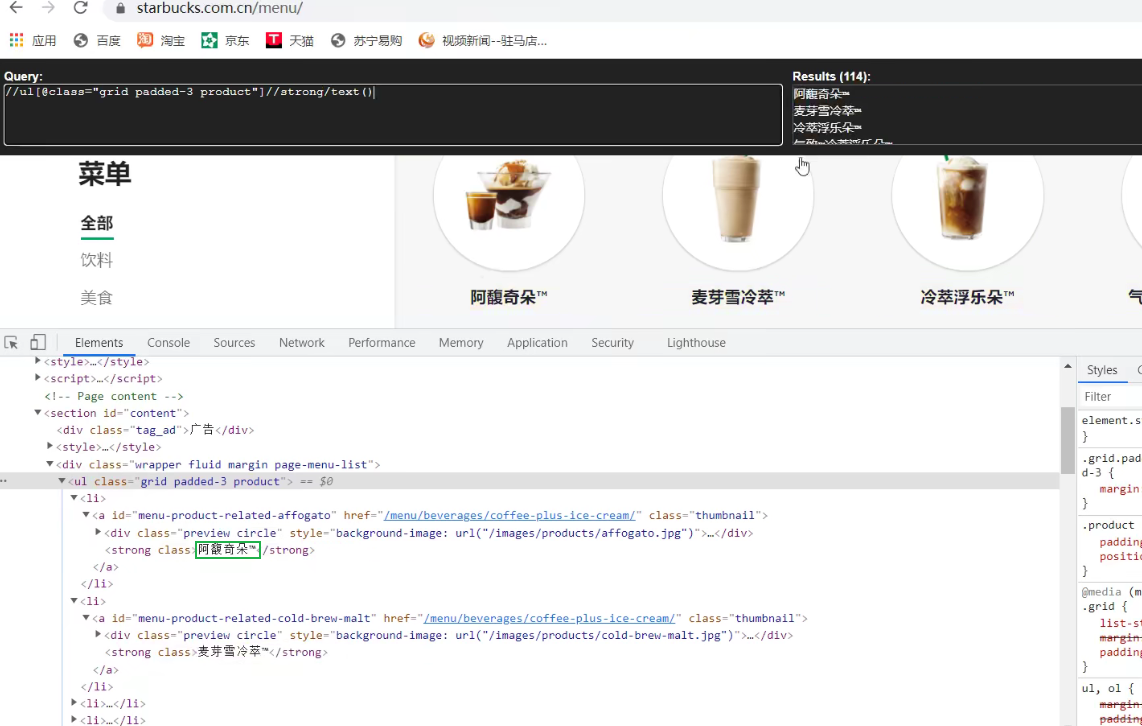
# //ul[@class="grid padded-3 product"]//strong/text()
# 返回一个,ul的class="grid padded-3 product" 的后代 所有strong标签
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())





 浙公网安备 33010602011771号
浙公网安备 33010602011771号