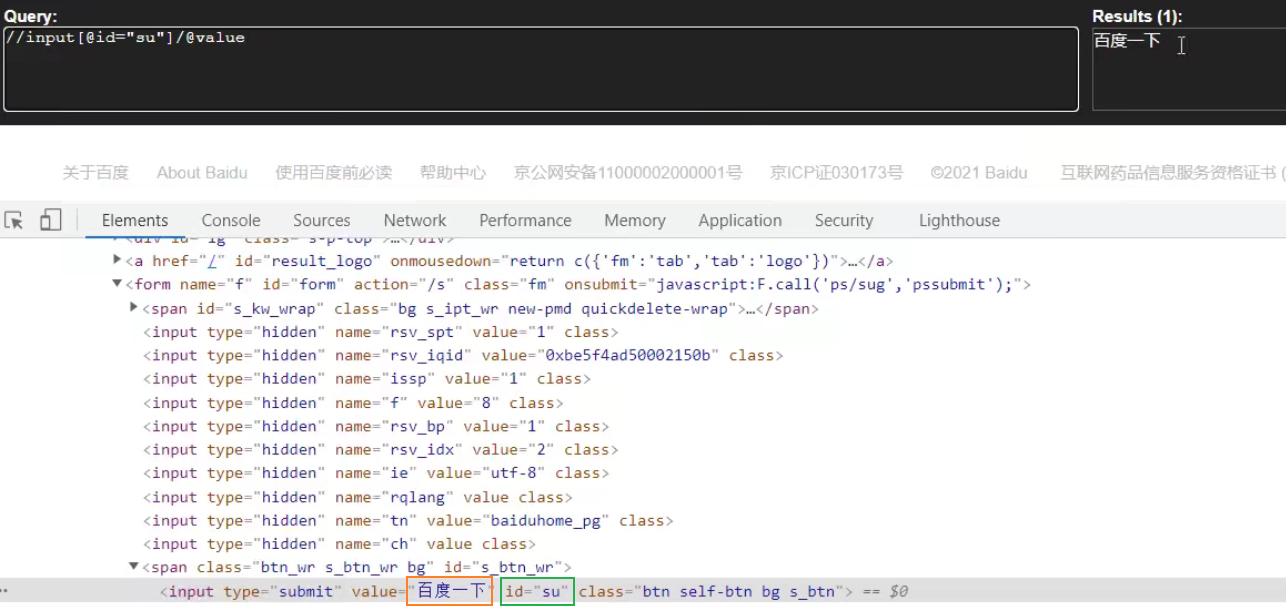
xpath解析案例
xpath解析百度页面的百度一下
# 1)获取网页的源码 # 2)解析的服务器响应的文件 etree.HTML , 用来解析字符串格式的HTML文档对象,将传进去的字符串转变成 element 对象 # 3)打印 import urllib.request # 请求地址 url = 'https://www.baidu.com/' # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } # 请求对象的定制 request = urllib.request.Request(url = url, headers = headers) # 模拟浏览器访问服务器 response = urllib.request.urlopen(request) # 获取网页源码 content = response.read().decode('utf-8') # 解析网页源码 来获取我们想要的数据 from lxml import etree # 解析服务器响应的文件 tree = etree.HTML(content) # 获取想要的数据 xpath的返回值是一个列表类型的数据 result = tree.xpath('//input[@id="su"]/@value')[0] print(result)