shell 学习笔记
linux下查看cpu的个数及核数
查看物理cpu个数
grep 'physical id' /proc/cpuinfo
查看核心数量
grep 'core id' /proc/cpuinfo
在某些情况下,很多指令我想要一次输入去执行,而不想要分次去执行时,就要用到 && || 了。
cmd 1 && cmd2
1,若cmd1执行完毕之后且正确($?=0),则开始执行cmd2。
2,若cmd1执行完毕之后且执行($? not equal 0),则cmd2不执行。
cmd1 || cmd2
1,若cmd1执行完毕之后且正确,则不执行cmd2.
2,若cmd1执行完毕之后错误,则执行cmd2
创建变量
a=1 注意:等号两边不能加空格
a=hello
a="hello world" 字符串中间有空格时,需要用双引号或单引号引用内容
a='hello world'
b="zhangsan"
a="hello $b" 双引号支持转义,$b会被当做变量,而不是字符串
shell中引用未定义的变量,不会报错,但也什么都不会发生
做变量和字符拼接时,需使用${a}包含变量
a=1111
echo ${a}_bbbb // 1111_bbbb
预定义变量(linux系统定义的变量)
$PWD
$USER
$HOME
$PATH
数组变量
ary=(1 2 3 4) //数组变量用()包含,中间用空格分开
ary=('aa' 'bb' ''cc)
echo $ary //获取数组的第一个元素
echo ${ary[@]} //获取数组所有的元素
echo ${ary[*]} //获取数组所有的元素
echo ${#ary[@]} //获取数组的长度
echo ${#ary[*]} //获取数组的长度
echo ${ary[0]} //获取下标为0的元素,shell中数组下表从0开始
定义一个linux命令的变量,需用反引``号引用
a=`pwd`
echo $a //打印当前所在的路径
ary=(`ls`) //相当于吧ls命令执行后的内容放到这个数组中
echo ${ary[@]} //打印当前路径下的所有文件及文件下
shell中对变量进行算数操作
a=5;b=4
echo $((a+b)) //9
echo $((a+1)) //6
((a=a+5)) //将a+5后的值赋值给a
echo $a //10
((a++)); echo $a; //6 数据的自加或自减
shell中数据比较的使用
a=5;b=6
((a<b))
echo $? //?用于判断上一条语句的判断结果,为true返回0,
否则返回非0
数据类型
a="aaa"
b=123
c=true d=false
整数和浮点数
echo $((2/3)) //0
awk 'BEGIN{print 2/3}' //0.66667,返回浮点数
字符串的操作
a="hello from testerhome"
echo ${a:6} //from testerhome;字符串的截取,从第6位开始截取
echo ${a:6:4} //从第6位开始截取,截取4位
echo ${#a} //打印字符串的长度
echo ${a#hello} //对字符串从头开始掐,掐掉hello
echo ${a#*o} //从字符串头开始掐,找到第一个o之前的字符全部掐掉,包括字符o
echo ${a##*o} //贪婪匹配,匹配到最后一个o之前的字符全部掐掉,包括字符o
echo ${a%home} //去尾
echo ${a%h*} //去尾第一个匹配到的字符h,字符h之后的全部去掉,包括h
echo ${a%%h*} //去尾的贪婪匹配
echo ${a/hello/xxx} //将字符穿中hello替换成xxx
判断运算
算术判断
[ 2 -eq 2 ]; //判断2是否等于2(中括号和数字之间必须要有空格)
[ 2 -ne 2 ] //不等于判断
[ 2 -gt 2 ] //大于判断
[ 2 -ge 2 ] //大于等于判断
[ 2 -lt 2 ] //小于判断
[ 2 -le 2 ] //小于等于判断
也可以用算术比较((10>=8))
[ 2 -eq 2 -a 3 -ne 4] //判断2等于2并且3不等于4的表达式结果
[ 2 -eq 2 -o 3 -ne 4] //判断2等于2或3不等于4的表达式结果
[ ! 2 -ge 1] //判断2等于1取反后的表达式结果
逻辑与和逻辑或都有短路情况

[ -e 1.sh ];echo $? //判断单签路径下是否存在文件1.sh
if判断

if [ condition ]; then .....;elif then ....;else .....fi;
for循环

for循环遍历形式
arr=(1 5 6 8 9)
for i in ${arr[@]}; do echo $i; done
while循环

使用read按行读取文件内容
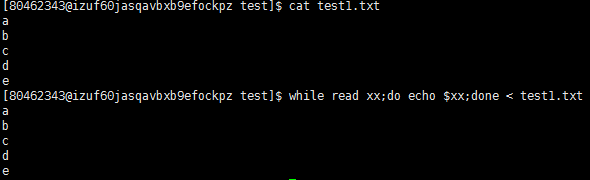
退出循环控制
break;
continue;

jobs 查看后台运行进程的信息
sleep 50 执行当前程序
crtl + z 键将当前程序调至后台且暂停运行
bg 1 后台执行对应程序
fg 1 将后台程序调至当前执行程序
/bin/sh -n 1.sh 检查1.sh是否存在语法错误
/bin/sh -v 1.sh 执行依据打印一句
/bin/sh -x 1.sh
find . -name "*" -mmin +10 查看系统当前路径下10分钟前被修改的文件
find . -name "*" -mmin -10 查看系统当前路径下10分钟内被修改的文件
find . -name "*" -mtime +10 查看当前路径下10天前被修改的文件
find . -type d -exec echo {} \; 吧find查找出来的文件交给后面的命令处理,{}代表find的结果集
xargs用法
find . -type f | xargs -i cp {} ./AAAA/ 查找当前路径下的文件,然后拷贝到AAAA文件夹下
查找grep
grep -i “hello” 不区分大小写的匹配,且是模糊匹配
grep -o "hello" 精确匹配
grep -o "c." //表示匹配c后任意一位字符,如:ca,cb等
grep -o "c.*" //*表示匹配任意多个字符
grep -o "[0-9]*" // 匹配数字的正则
练习:读一个文件,然后循环请求文件中的内容,在查找结果

练习:查找一个网页中是否有死链接
curl -s https://testing-studio.com | grep href | grep -o "http[^\"']*" | while read line;do curl -s -I $line | grep 200 && echo "200 $line" || echo "err $line";done
awk 指定字符串按指定格式切
echo "123|456|789" | awk -F "|" '{print $1}' $0 表示全部字符,$1表示切出来的第一个字符
FS:输入字符分隔符,默认为空格字符
OFS:输出字段分隔符,默认为空格字符
RS:行分隔符,默认按"回车换行"进行分割为一行记录
ORS:输出分隔符,默认按"回车换行"
NF:行的字段个数
NR:行号(从1开始)
FNR:处理多个文件时,各个文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存命令行所给定的参数
练习:使用NR和NF


练习2:FNR分别对每个文件的行号计数

练习:RS行分隔符,让awk遇到空格就分割为新的一行(第四行def 和123是由于我们以空格为换行后,原本的回车换行就被当做是一行记录的原因)
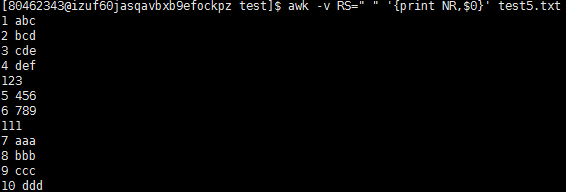
练习:ORS输出分隔符,我们让awk以“---”为输出换行符

练习:ARGV表示一个数组,保存的是命令行所给定的参数

练习:ARGC表示参数的个数(参数个位3,是由于awk本身就是一个参数)

练习:awk中自定义变量
方式一:在awk中创建变量

方式二:调用外部的shell变量

awk 分割后判断某个字段是否满足条件
echo "1+2+5+4" | awk -F '+' '$3~/3/{print $1}' //判断分割后的第三个字段是否是3,如果是3就打印$1
awk 循环统计文件中的所有记录数
awk '{count++;print $0;} END{print "user count is ",count}' /etc/passwd //循环打印每行记录且统计总数
cat /etc/passwd | awk 'BEGIN{count=0}{count+=1;print $0}END{print count}' //循环打印每行记录且统计总数
awk 中使用关系运算符
cat /etc/passwd | awk -F ':' '{if(NR>=20 && NR<=30) print NR}'
awk中使用算术运算符
awk 'BEGIN{a=11;b=12;print a++,b++}'
awk 中使用三目运算符
awk 'BEGIN{a=1;b=2;print a==b?"ok":"err"}'
sed常见命令参数
p==print
d:delete
= 打印匹配行的行号
-n 取消默认的完整输出,只打印需要的行
-e 允许多项编辑
-i 修改文件内容
-r 不需要转义
sed 文本替换
echo "cat dog fish cat" | sed ‘s/cat/wulala/’ //将第一个cat替换成wulala
echo "cat dog fish cat" | sed ‘s/cat/wulala/g’ //将所有的cat替换成wulala
sed 替换文件中的内容
sed -i 's/hello/HELLO/' text.txt // 加上-i 参数会替换掉文件中的内容
sed -i.bak 's/hello/HELLO/' text.txt // 生成一个源文件的备份文件
sed -n ‘2p’ test.txt //只打印第2行的内容
sed -n '$p' test.txt //打印最后一行
sed -n '/80462343/p' test.txt //只打印包含80462343的行
cat /etc/passwd | sed -n '3,9p' //打印3-9行的内容
sed ‘2p’ test.txt //打印第2行的内容
sed '2d' test.txt //删除第2行的内容不展示
sed '$d' test.txt //删除最后一行
sed '1a drink tea' test.txt //在第一行后增加字符串drink tea
sed '1,3a drink tea' test.txt //在第1行到第三行的每行后面增加字符串drink tea
sed '1a drink tea \nor coffee' ab #第一行后增加多行,使用换行符\n

sed '1c xxxxx' test.txt //将第一行替代为xxxxx
sed '1,3c xxxxx' test.txt // 将第一行到第三行的内容替换为一行xxxxx(实际减少了两行)
sed '/^a/c xxxxx' test.txt //替换以a开头的行,替换为xxxxx
sed '2,$s/a/A/g' test5.txt //替换第2行到最后一行中的a为A
sed '/^[0-9]/s/aa/AA/g' test.txt //对所有以数字开头的行,进行替换操作
sed -i '$a bye' test.txt //在文件ab中最后一行直接输入"bye"
sed 'li hello world' test.txt //在一行前加上hello world字符
sed '/a/d' test.txt //删除所有包含字符a的行
seq 10 20 |sed 's/1/xxxx/g' ///sed匹配正则表达式,将全部的1替换为xxxx
seq 10 20 |sed -n '/14/,/18/p' // sed获取一个区间的行(获取数值为14-18区间的行)

sed 使用\1 \2等匹配指定的字段(使用seq 126 135 | sed -E 's/.(.)(.)/\1+\2/g' 匹配第一个和第二个字段)
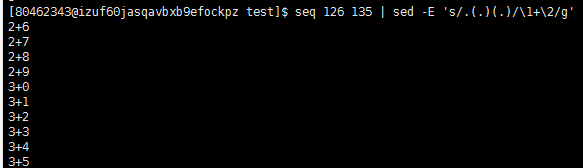
文件参数

${*:1:3} //取第1-3个参数
${*:$#} //取最后一个参数
函数
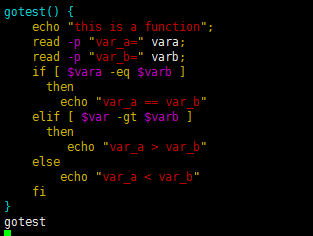
case 语句的用法
case $key in
1)
echo "xxx1";
;; //双分号表示改行选择命令的结束
2)
echo "xxx2";
;;
esac
练习:

cut 截取文本字符串
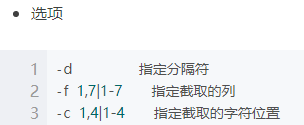
 //截取passwd文件中的第一列
//截取passwd文件中的第一列
sort 对文本进行排序,按字符串的字母顺序表进行排序

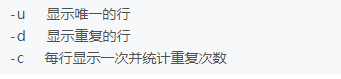
uniq 去重,对重复的字符做相应处理
adb shell
click(){ //封装一个方法,根据名称去点击手机当前屏幕上的按钮
local index=1;
[ -n "$2" ] && index=$2
adb shell input tap \
$(adb shell "uiautomator dump --compressed && cat /sdcard/window_dump.xml" \
| sed "s/<node/^<node/g" \
| awk 'BEGIN{RS="^"}{print $0}'\
| grep "$1" \
| sed -n "$index"p\
| awk 'BEGIN{FS=",|\\[|\\]"}{print ($2+$5)/2,($3+$6)/2}'
)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号