大数据分析复习笔记
data mining
- volume
- veracity
- variety
- velocity
- value
数据挖掘
有效性、可用性、出乎意料、可理解性
Page Rank
spider traps
假设有图:
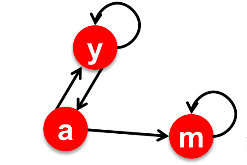
其邻接矩阵 M为:
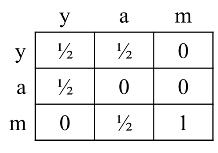
带入公式迭代,结果为: 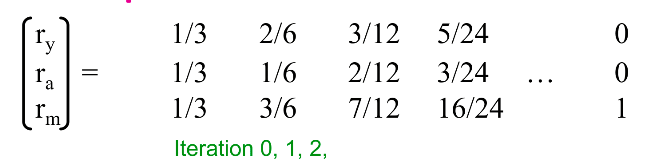
最终,rm=1
而 ry=ra=0 。这从漫步者的角度很好理解,在经过一段时间之后,漫步者到达了 m 节点,然而 m 节点只有指向自己的链接,然后就只能一直停留在 m,所以最后的概率一定是1, 而其他两个节点的概率就变成了0 。
解决方案
随机传送 Random Teleports
Google解决这个问题的办法是:到达某个节点后 * 有 β
的概率随机找一个链接过去 * 剩下 1−β 的概率跳到一个随机的页面 * 一般 β 的值在 0.8 到 0.9
之间
这样就使得漫步者在到达m节点之后有一定的概率跳出去! 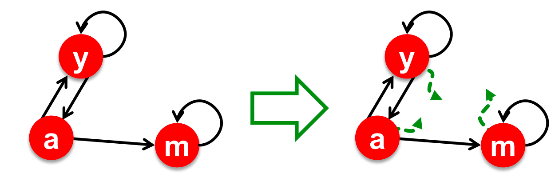
Dead Ends
假设有图:
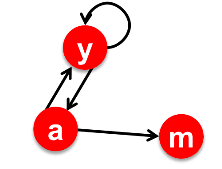
其邻接矩阵为:
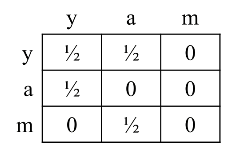
由于m节点没有链接到其他界面,所以m的那一列都等于零。 代入公式迭代,得到结果:
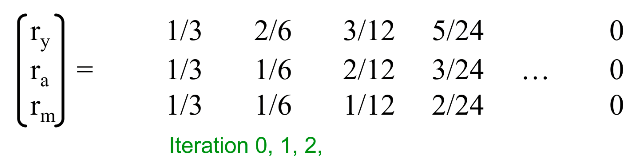
漫步者到达m之后发现是死胡同,无路可走了,然而他也不会在m停留,所以最后出现在三个节点的概率都等于0 。
解决方案
依旧是传送!
当漫步者到达死胡同时,传送的概率变为 1.0 ,随机传送到任意页面,然后图就变成了如下:
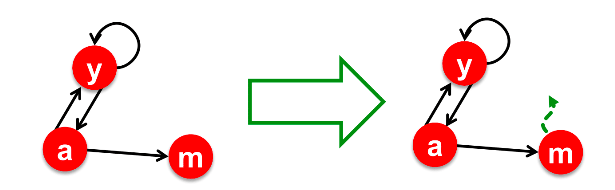 邻接矩阵变为:
邻接矩阵变为:
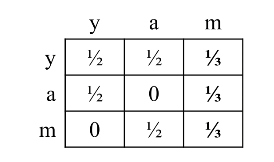
这样问题就解决了,漫步这每次到m之后,发现去所有页面的概率都相同且不为零,相当于随机跳转到一个页面。
SVD
计算流程
分类
贝叶斯定理
计算
ID3算法
信息增益
https://blog.csdn.net/weixin_43216017/article/details/87474045

C4.5算法
改进
https://blog.csdn.net/weixin_43216017/article/details/87609780
ID3算法使用的是信息增益,它偏向于分类较多的变量;
C4.5算法使用的是信息增益比,它偏向于分类较少的变量。
KNN
近朱者赤近墨者黑
聚类
- 硬聚类
- 软聚类
k-means
-
优点:时间效率 O(tkn),t是迭代次数,k集群数,n的对象数
-
缺点:
- k给定
- 难以处理噪声和离群点
- 无法处理非凸形状
-
开始:选k个核
-
结束条件:
- 中心不变
- or设置迭代次数
层次聚类
-
聚合 agglomerative
-
划分 divisive
-
距离计算公式
- complete
- single
- centroid
- average
-
O(n2)
推荐系统
content-based
优点
- 不需要其他用户数据
- 解决了冷启动和稀疏矩阵问题
- 为用户独特口味推荐
- 推荐新的、不热门的商品
- 提供解释
缺点
- 有时候难以找到特征
- 新用户需要建立profile
- 过于具体,总是推荐喜欢的
CF
相似度度量
- Jaccard
- 忽略了分值的作用
- Cosine
- 缺失值影响大
- Pearson
优点
- 适用于各类商品,不需要管商品特征
缺点
- 冷启动问题
- 需要足够的用户
- 稀疏矩阵
- 用户评分矩阵稀疏,难以找到共同评分过的相似用户
- 第一个评分者问题
- 推荐不出没有被评分过的商品
- 大众化
- 难以满足个人独特口味,趋于推荐热门商品
Spark
特点
- 快速
- 易用
- 通用
多种启动方式
- hadoop
- mesos
生态圈
NoSQL
类型
- graph stores
- neo4j(cypher 查询语言)
- document stores
- mongodb
- key-value stores
- wide-column stores
社会计算
(重点)六项任务
- centrality analysis
- 分析社交网络中节点的重要性 PageRank
- community detection
- 聚类
- classification
- 分类,有监督的
- link prediction
- 给定社交网络,预测节点之间的联系 知识图谱补全
- viral marketing
- 病毒营销、outbreak detection
- network modeling
社团发现
依据什么标准可以称为community?

