

浏览器是怎样工作的(一):基础知识
2012-12-13 11:24 臭小子1983 阅读(165) 评论(0) 编辑 收藏 举报译注:
前两天看到一篇不错的英文文章,叫做 How browsers work,该文概要的介绍了浏览器从头到尾的工作机制,包括HTML等的解析,DOM树的生成,节点与CSS的渲染等等,对于想学习浏览器源码的同学来说,实在是很棒的一篇科普文章。尽管对于每部分,该文的描述并不足够深入,但综合来讲,即使没兴趣学浏览器源码,也还是有一些值的学习的思想在里面的,可以权当开拓下视野,有益无害。
于是,我想分节挑重点翻译一下与大家分享。以下为译文:
我们要讨论的浏览器
当今主流浏览器有五类: Internet Explorer, Firefox, Safari, Chrome 以及 Opera。 我会基于开源浏览器 Firefox, Chrome 与 Safari(部分开源)来举例说明。 按照 W3C 浏览器统计, 当今(2009年10月), Firefox, Safari 及 Chrome 的总占有率已接近 60%,这是非常可观的。
浏览器的主要功能
浏览器的主要功能是展示网页资源,也即请求服务器并将结果显示在浏览器窗口中。资源的格式一般是HTML,但也有PDF、图片等其它各种格式。资源的定位由URL来实现。更多细节请参考“网络”一节。
浏览器释与展现HTML文件的方式是参照HTML与CSS规范来的,这些规范由 W3C (World Wide Web Consortium) Web标准化组织来维护。 当前HTML版本是 4 (http://www.w3.org/TR/html401/),HTML5正在进行中。当前CSS版本为2 (http://www.w3.org/TR/CSS2/),同样,版本3进行中。
过去几年里,各版本浏览器有许多各自的扩展,这使网页作者很难写出兼容性好的内容。如今这一严重的兼容性问题已经开始好转,各种浏览器都开始兼容标准规范。
各浏览器的用户接口有很多相同的地方,下面是一些常用的用户接口:
- 用于输入URI的地址栏
- 前进后退按钮
- 书签选项
- 刷新停止按钮,用于控制页面加载
- 主页按钮
很奇怪的是,浏览器的用户接口并没有写进任何规范中,这种极大的相似性只是在多年的实践经验以及浏览器之间的相互借鉴中形成的。HTML5规范没有规定浏览器必须有哪些交互元素,但是列出了一些通用元素,比如地址栏, 状态栏和工具栏。 当然,特定浏览器有自己独有的特性,如Firefox的下载管理器。更多内容请参考用户接口一节。
浏览器的上层结构
浏览器的主要概念如下 (1.1):
- 用户接口 – 包括地址栏,前进后退,书签菜单等窗口上除了网页显示区域以外的部分。
- 浏览器引擎 – 查询与操作渲染引擎的接口。
- 渲染引擎 – 负责显示请求的内容。比如请求到HTML, 它会负责解析HTML 与 CSS 并将结果显示到窗口中。
- 网络 – 用于网络请求, 如HTTP请求。它包括平台无关的接口和各平台独立的实现。
- UI后端 – 绘制基础元件,如组合框与窗口。它提供平台无关的接口,内部使用操作系统的相应实现。
- JavaScript解释器。用于解析执行JavaScript代码。
- 数据存储。这是一个持久层。浏览器需要把所有数据存到硬盘上,如cookies。新的HTML规范 (HTML5) 规定了一个完整(虽然轻量级)的浏览器中的数据库:’web database’。
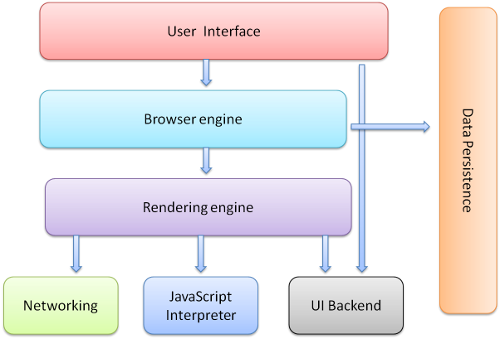
图1: 浏览器的主要概念
需要注意的是,与其它浏览器不同,chrome使用多个渲染引擎实例,每个Tab一个,每个Tab都是一个独立进程。
我会拿出一个章节来介绍每块内容。
组件间的通信
Firefox 与 Chrome 开发了一种特殊的通信架构,这会在一个特殊章节讨论。
本文作者:hfliu 转载请注明来自:携程UED

