10项目实战-交易数据异常检测
(1)conda install scikit-learn
(2) conda install pip
特征压缩,建模。 对amount 进行预处理
信用卡欺诈检测 0 类:正常, 1 类 : 异常
正样本负样本: 进行二分类。异常检测问题。 正样本多,负样本少。
数据部分: x 特征数 y 标签
pd.value_counts(data["Class],sort=True).sort_index(); 获取不同值
样本极度不规则的解决方案: 过采样,下采样。
下采样: 样本不均衡。使得正负样本一样少。
过采样: 样本不均衡。使得正负样本一样多。
sklearn:
from sklearn.preprocessing import StandarfScaler
数据预处理操作。
数据拆分:测试集,训练集。
交叉验证: 验证集在训练集中。 数据分三分: 1 + 2 建模 和 3 验证。 1 + 3 建模和2 验证。
下采样: 保证数据正样本和负样本一样少。
下采样数据建模, 原始数据测试集进行测试。
建模操作:
精度: 真实值和预测值。 真实值和预测的相等数 / 样本总数。
评估模型 : 模型可不可用。精度不准确。 通过recall : 查全率。模型评估。
预测结果: TP FP FN TN

混淆矩阵:
交叉验证: 原始数据切分: KFold() 函数进行数据切分
正则惩罚: 惩罚参数。L2正则化。希望函数的损失值越小越好。
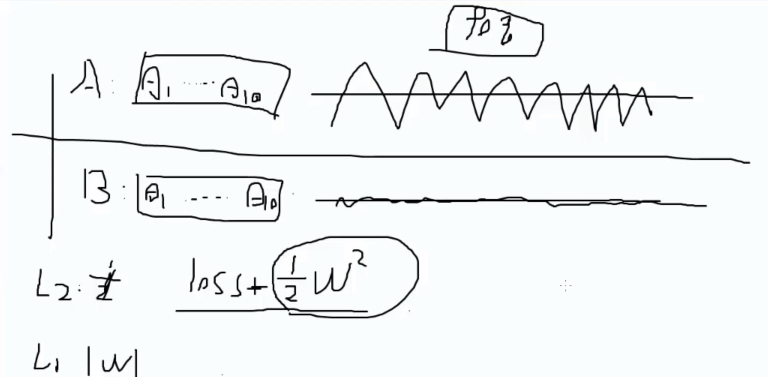
定义惩罚值列表:遍历惩罚列表查找最好的惩罚项值
遍历训练集和测试集数据:
获取交叉验证的值。https://blog.csdn.net/qq_35046314/article/details/88859058
KFold: 获取切分的数据块
参数:
n_splits 表示划分为几块(至少是2)
shuffle 表示是否打乱划分,默认False,即不打乱
random_state 表示是否固定随机起点,Used when shuffle == True.
方法
1,get_n_splits([X, y, groups]) 返回分的块数
2,split(X[,Y,groups]) 返回分类后数据集的index
混淆矩阵: 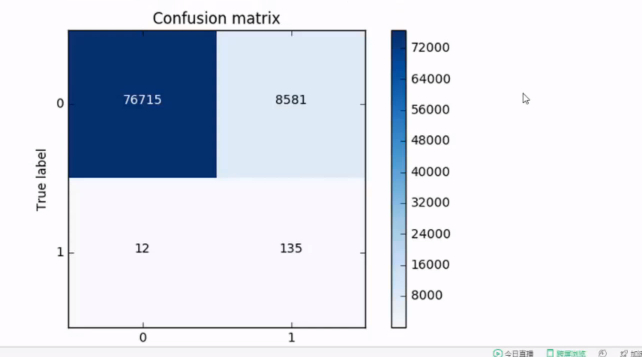
#Recall = TP/(TP+FN) 建模.
逻辑回归:
sigmoid函数: 预测结果大于: 0.6 为1.自定义阈值。
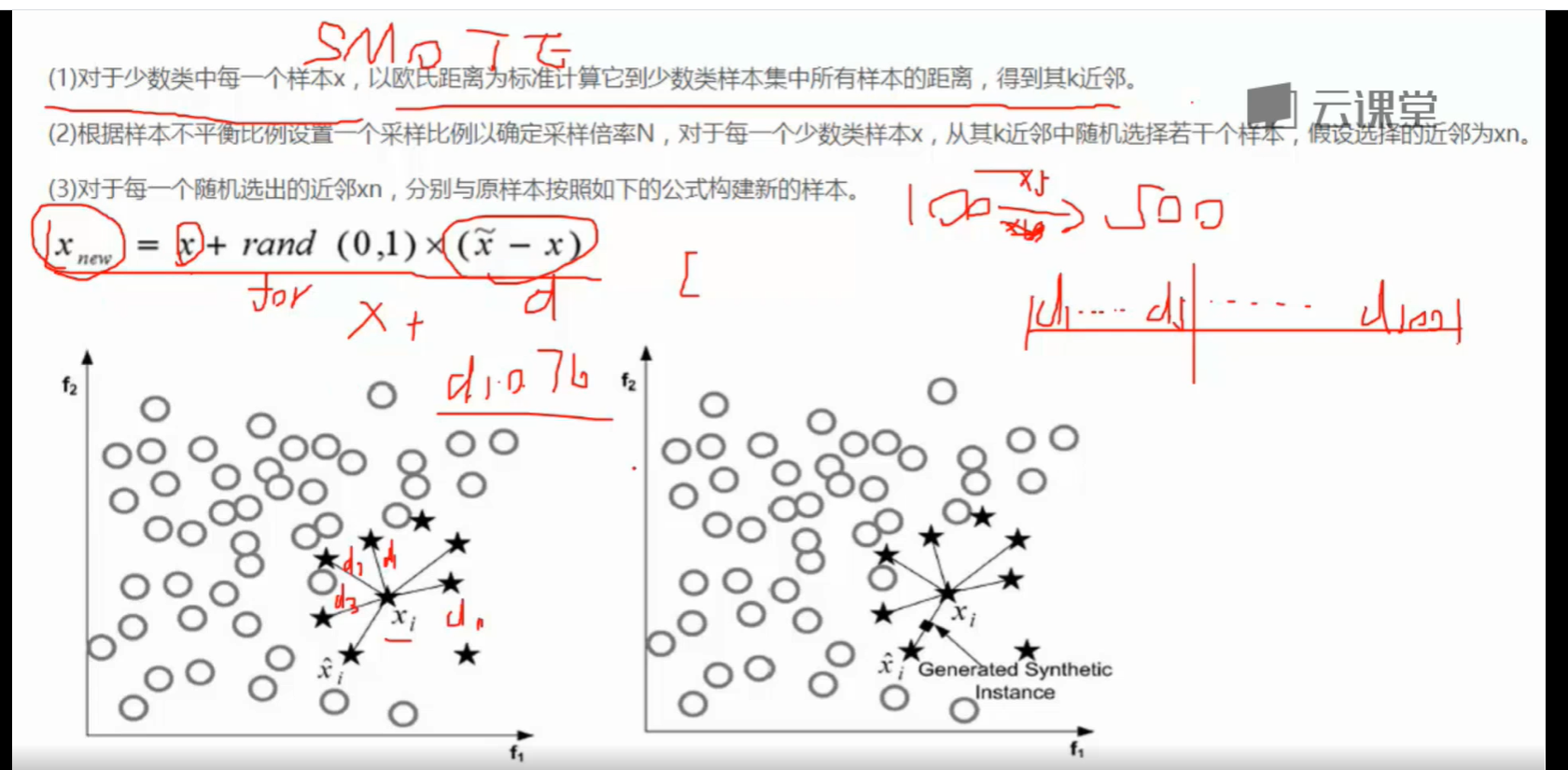
过采样:保证数据同样多。生成的操作。
smote算法:找到少数类样本。计算每个到其他样本的距离。生成倍数。 x(new) = x + rand(0,1) x (x-x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号