DRF完整版
1.restful规范
概述:
1.RESTful是目前最流行的 API 设计规范,用于 Web 数据接口的设计。代表的是一种软件架构风格。它将分布在网络中某个节点的资源通过URL进行标识,客户端应用通过URL来获取资源的表征,获得这些表征致使这些应用转变状态。将一切数据视为资源是REST区别与其他架构风格的最本质属性
RESTFUl API设计
1.使用协议:API与用户的通信协议,总是使用HTTPs协议。
2.使用域名:应该尽量将API部署在专用域名之下,意思就是给API专门做一个服务器。
https://example.org/api/
3.版本提示:网站的API可能一直在更新那么应该将API的版本号放URL。
https://api.example.com/v1/。
4.路径写法:路径又称"终点"(endpoint),表示API的具体网址。在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词
https://api.example.com/v1/zoos
https://api.example.com/v1/animals
https://api.example.com/v1/employees
5.HTTP动词:后端基于请求方式来分发对应的视图函数来进行逻辑处理和数据处理、提取、加工等操作
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性,更新部分资源的意思)。他和put用哪个都可以,没有太大的区别,我们用put方式偏多
DELETE(DELETE):从服务器删除资源。
HEAD:获取资源的元数据。
OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的
6.核心思想:客户端发出的数据操作指令都是"动词 + 宾语"的结构。比如,GET /articles这个命令,GET是动词,/articles是宾语
GET /zoos:列出所有动物园
POST /zoos:新建一个动物园
GET /zoos/ID:获取某个指定动物园的信息
PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
DELETE /zoos/ID:删除某个动物园
GET /zoos/ID/animals:列出某个指定动物园的所有动物
DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
7.动词覆盖:有些客户端只能使用GET和POST这两种方法。服务器必须接受POST模拟其他三个方法(PUT、PATCH、DELETE)。
客户端发出的 HTTP 请求,要加上X-HTTP-Method-Override属性,告诉服务器应该使用哪一个动词,覆盖POST方法。
POST /api/Person/4 HTTP/1.1
X-HTTP-Method-Override: PUT
8.过滤信息(filtering,或称查询参数):如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。除了第一级,其他级别都用查询字符串表达
9.状态码:客户端的每一次请求,服务器都必须给出回应。回应包括 HTTP 状态码和数据两部分。
1xx:相关信息
2xx:操作成功
3xx:重定向
4xx:客户端错误
5xx:服务器错误
10.服务器响应:
1.响应数据格式
API 返回的数据格式,不应该是纯文本,而应该是一个 JSON 对象,因为这样才能返回标准的结构化数据。所以,服务器回应的 HTTP 头的Content-Type属性要设为application/json。
客户端请求时,也要明确告诉服务器,可以接受 JSON 格式,即请求的 HTTP 头的ACCEPT属性也要设成application/json。下面是一个例子。
GET /orders/2 HTTP/1.1
Accept: application/json
2 发生错误时的响应
发生错误时不要响应200状态码,有一种不恰当的做法是,即使发生错误,也返回200状态码,把错误信息放在数据体里面,就像下面这样。
3 响应结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
GET /collection:返回资源对象的列表(数组),一般是[{"id":1,"name":"a",},{"id":2,name:"b"},]这种类型
GET /collection/resource:返回单个资源对象, 一般是查看的单条数据 {"id":1,"name":'a'}
POST /collection:返回新生成的资源对象 , 一般是返回新添加的数据信息, 格式一般是{}
PUT /collection/resource:返回完整的资源对象 一般时返回更新后的数据,{}
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档 一般返回一个空字符串
11.Hypermedia API,提供链接:RESTful API最好做到Hypermedia,即返回结果中提供链接,API 的使用者未必知道,URL 是怎么设计的。一个解决方法就是,在回应中,给出相关链接,便于下一步操作。这样的话,用户只要记住一个 URL,就可以发现其他的 URL。这种方法叫做 HATEOAS.
12.服务器返回的数据格式,应该尽量使用JSON,避免使用XML
2.Django RestFramework(DRF)
1.含义:
Django下的一个app,用于在django上开发接口。
2.安装:
pip install djangorestframework
3.组件:
a.APIView (*****)
b.序列化组件 (*****)
c.试图类(mixin) (*****)
d.认证组件 (*****)
e.权限组件
f.频率组件
g.分页组件
h.解析器组件 (*****)
i.相应其组件
j.url控制器
4.APIView视图组件:把CBV的View换成APIView
1.views.py
import json
from rest_framework.views import APIView
from rest_framework.response import Response
class Book(APIView):
def get(self,request):
data = [{'title':'python','price':100},
{'title':'java宝典','price':200}
]
return Response(data=data)
# return HttpResponse(json.dumps(data,ensure_ascii=False))
def post(self,request):
return
-------------------------------------------------------------------------------
2.settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'rest_framework'
]
-------------------------------------------------------------------------------
5.解析器组件:前端传来的数据解析给python
from rest_framework.parsers import JSONParser,FormParser,MultiPartParser
# JSONParser:解析json数据的额
# FormParser:解析urlencoded数据的
# FileUploadParser:解析文件数据的
class Book(APIView):
'''里面存放我们上面导入的那几个解析器,如果我们里面写了一个JSONParser,
那么解析器只能解析前端发送过来的json数据,
存放到request.data里面.'''
parser_classes = [JSONParser,]
def get(self,request):get
return HttpResponse('get')
def post(self,request):
print(request.data)
return HttpResponse('ok')
6.序列化组件:序列化自定制要返回给前端的数据接口
1.继承序列化类进行序列化
1.mdoels.py
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.IntegerField()
author = models.CharField(max_length=32)
2.创建一个写序列化的serilizerbook.py文件
from rest_framework import serializers
'''这里面也要写对应的字段,
你写了哪些字段,就会对哪些字段的数据进行序列化,
没有被序列化的字段,不会有返回数据'''
class BookSeri(serializers.Serializer):
title = serializers.CharField()
price = serializers.IntegerField()
#source指定models中的字段
zuozhe = serializers.CharField(source='author')
3.views.py
---------------------get请求-------------------------------
def get(self,request):
book_obj = models.Book.objects.all()
books = BookSeri(book_obj,many=True)
return Response(data=books.data)
---------------------post请求-------------------------------
def post(self,request):
#request.data -->[{'title':'css','price':600,'author':'polo'}]
books = BookSeri(data=request.data,many=False)
if books.is_valid():
#数据规范创建数据
models.Book.objects.create(**books.data)
return Response(books.data)
else:
#数据不是规范的
errors = books.errors
return Response(errors)
2.使用ModelSerializer进行序列化
1.serilizerbook.py文件
from rest_framework import serializers
from . import models
class BookSri(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
# 如果直接写all,你拿到的数据是下面这样的,
# [
# {
# "authors": [
# 2,
# 1
# ]
# }
# ]
#通过使用get_字段名弄出数据
authors = serializers.SerializerMethodField()
def get_authors(self,obj):
author_list_values = []
author_dict = {}
author_list = obj.authors.all()
for i in author_list:
author_dict['id'] = i.pk
author_dict['name'] = i.name
author_list_values.append(author_dict)
return author_list_values
#这个数据就会覆盖上面的序列化的authors字段的数据
# 那么前端拿到的数据就这样了
# [
# {
# "authors": [
# {
# "name": "chao",
# "id": 1
# },
# {
# "name": "chao",
# "id": 1
# }
# ],
# }
# ]
2.views.py
----------------------------------------get请求---------------------------------
def get(self,request):
book_obj_list = models.Book.objects.all()
s_books = BookSeri(book_obj_list,many=True)
return Response(s_books.data)
---------------------------------------post请求---------------------------------
def post(self,request):
b_serializer = BookSeri(data=request.data,many=False)
if b_serializer.is_valid():
b_serializer.save() #因为这个序列化器我们用的ModelSerializer,并且在BookSerializers类中我们指定了序列化的哪个表,所以直接save,它就知道我们要将数据保存到哪张表中,其实这句话执行的就是个create操作。
return Response(b_serializer.data) #b_serializer.data这就是个字典数据
else:
return Response(b_serializer.errors)
---------------------------------------put请求---------------------------------
def put(self,request,id):
'''
更新一条数据
:param request:request.data更新提交过来的数据
:param id:
:return:
'''
book_obj = models.Book.objects.get(pk=id)
b_s = BookSeri(data=request.data,instance=book_obj,many=False) #别忘了写instance,由于我们使用的ModelSerializer,所以前端提交过来的数据必须是所有字段的数据,当然id字段不用
if b_s.is_valid():
b_s.save() #翻译成的就是update操作
return Response(b_s.data) #接口规范要求咱们要返回更新后的数据
else:
return Response(b_s.errors)
--------------------------------------delete请求---------------------------------
def delete(self,request,id):
'''
删除一条数据
:param request:
:param id:
:return:
'''
book_obj = models.Book.objects.get(pk=id).delete()
return Response("") #别忘了接口规范说最好返回一个空
属性方法
1.save()
在调用serializer.save()时,会创建或者更新一个Model实例(调用create()或update()创建),具体根据序列化类的实现而定,如:
2.create()、update()
Serializer中的create()和update()方法用于创建生成一个Model实例,在使用Serializer时,如果要保存反序列化后的实例到数据库,则必须要实现这两方法之一,生成的实例则作为save()返回值返回。方法属性validated_data表示校验的传入数据,可以在自己定义的序列化类中重写这两个方法。
3. is_valid()
当反序列化时,在调用Serializer.save()之前必须要使用is_valid()方法进行校验,如果校验成功返回True,失败则返回False,同时会将错误信息保存到serializer.errors属性中。
4.data
serializer.data中保存了序列化后的数据。
5.errors
当serializer.is_valid()进行校验后,如果校验失败,则将错误信息保存到serializer.errors属性中。
Field
1.CharField
对应models.CharField,同时如果指定长度,还会负责校验文本长度。
max_length:最大长度;
min_length:最小长度;
allow_blank=True:表示允许将空串做为有效值,默认False;
2.EmailField
对应models.EmailField,验证是否是有效email地址。
3.IntegerField
对应models.IntegerField,代表整数类型
4.FloatField
对应models.FloatField,代表浮点数类型
5.DateTimeField
对应models.DateTimeField,代表时间和日期类型。
format='YYYY-MM-DD hh:mm':指定datetime输出格式,默认为DATETIME_FORMAT值。
需要注意,如果在 ModelSerializer 和HyperlinkedModelSerializer中如果models.DateTimeField带有auto_now=True或者auto_add_now=True,则对应的serializers.DateTimeField中将默认使用属性read_only=True,如果不想使用此行为,需要显示对该字段进行声明:
class CommentSerializer(serializers.ModelSerializer):
created = serializers.DateTimeField()
class Meta:
model = Comment
6.FileField
对应models.FileField,代表一个文件,负责文件校验。
max_length:文件名最大长度;
allow_empty_file:是否允许为空文件;
7.ImageField
对应models.ImageField,代表一个图片,负责校验图片格式是否正确。
max_length:图片名最大长度;
allow_empty_file:是否允许为空文件;
如果要进行图片处理,推荐安装Pillow: pip install Pillow
8.HiddenField
这是serializers中特有的Field,它不根据用户提交获取值,而是从默认值或可调用的值中获取其值。一种常见的使用场景就是在Model中存在user_id作为外键,在用户提交时,不允许提交user_id,但user_id在定义Model时又是必须字段,这种情况下就可以使用HiddenField提供一个默认值:
class LeavingMessageSerializer(serializers.Serializer):
user = serializers.HiddenField(
default=serializers.CurrentUserDefault()
)
公共参数
所谓公共参数,是指对于所有的serializers.<FieldName>都可以接受的参数。以下是常见的一些公共参数。
1.read_only
read_only=True表示该字段为只读字段,即对应字段只用于序列化时(输出),而在反序列化时(创建对象)不使用该字段。默认值为False。
2.write_only
write_only=True表示该字段为只写字段,和read_only相反,即对应字段只用于更新或创建新的Model时,而在序列化时不使用,即不会输出给用户。默认值为False。
3.required
required=False表示对应字段在反序列化时是非必需的。在正常情况下,如果反序列化时缺少字段,则会抛出异常。默认值为True。
4.default
给字段指定一个默认值。需要注意,如果字段设置了default,则隐式地表示该字段已包含required=False,如果同时指定default和required,则会抛出异常。
5.allow_null
allow_null=True表示在序列化时允许None作为有效值。需要注意,如果没有显式使用default参数,则当指定allow_null=True时,在序列化过程中将会默认default=None,但并不会在反序列化时也默认。
6.validators
一个应用于传入字段的验证函数列表,如果验证失败,会引发验证错误,否则直接是返回,用于验证字段,如:
username = serializers.CharField(max_length=16, required=True, label='用户名',
validators=[validators.UniqueValidator(queryset=User.objects.all(),message='用户已经存在')])
7.error_message
验证时错误码和错误信息的一个dict,可以指定一些验证字段时的错误信息,如:
mobile= serializers.CharField(max_length=4, required=True, write_only=True, min_length=4,
label='电话', error_messages={
'blank': '请输入验证码',
'required': '该字段必填项',
'max_length': '验证码格式错误',
'min_length': '验证码格式错误',
})
7.style
一个键值对,用于控制字段如何渲染,最常用于对密码进行密文输入,如:
password = serializers.CharField(max_length=16, min_length=6, required=True, label='密码',
error_messages={
'blank': '请输入密码',
'required': '该字段必填',
'max_length': '密码长度不超过16',
'min_length': '密码长度不小于6',
},
style={'input_type': 'password'}, write_only=True)
9.label
一个简短的文本字串,用来描述该字段。
10.help_text
一个文本字串,可用作HTML表单字段或其他描述性元素中字段的描述。
11.allow_blank
allow_blank=True 可以为空 设置False则不能为空
12.source
source='user.email'(user表的email字段的值给这值) 设置字段值 类似default 通常这个值有外键关联属性可以用source设置
13.validators
验证该字段跟 单独的validate很像
UniqueValidator 单独唯一
validators=[UniqueValidator(queryset=UserProfile.objects.all())
UniqueTogetherValidator: 多字段联合唯一,这个时候就不能单独作用于某个字段,我们在Meta中设置。
validators = [UniqueTogetherValidator(queryset=UserFav.objects.all(),fields=('user', 'course'),message='已经收藏')]
14.error_messages
错误消息提示
error_messages={
"min_value": "商品数量不能小于一",
"required": "请选择购买数量"
})
7.ModelSerializers
ModelSerializers继承于Serializer,相比其父类,ModelSerializer自动实现了以下三个步骤:
1.根据指定的Model自动检测并生成序列化的字段,不需要提前定义;
2.自动为序列化生成校验器;
3.自动实现了create()方法和update()方法。
使用ModelSerializer方式如下:
class StudentSerializer(serializers.ModelSerializer):
class Meta:
# 指定一个Model,自动检测序列化的字段
model = StudentSerializer
fields = ('id', 'name', 'age', 'birthday')
相比于Serializer,可以说是简单了不少,当然,有时根据项目要求,可能也会在ModelSerializer中显示声明字段,这些在后面总结。
model
该属性指定一个Model类,ModelSerializer会根据提供的Model类自动检测出需要序列化的字段。默认情况下,所有Model类中的字段将会映射到ModelSerializer类中相应的字段。
3.使用mixins模块优化序列化接口
4.使用视图组件Viewset优化
7.逻辑接口认证组件、权限组件、频率组件等
1.认证组件
概述:cookie、session认证机制中,session更安全。但是session的信息都存到咱们的服务器上了,如果用户量很大的话,服务器压力是比较大的,并且django的session存到了django_session表中,不是很好操作,但是一般的场景都是没有啥问题的
说明:数据接口是必须要求用户登陆之后才能获取到数据,所以将来用户登陆完成之后,每次再过来请求,都要带着token来,作为身份认证的依据。
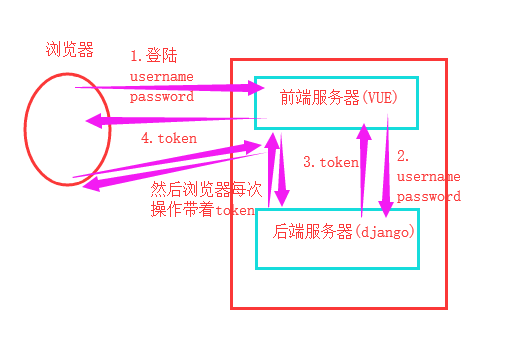
2.准备
1.models.py
class User(models.Model):
username = models.CharField(max_length=32)
password = models.CharField(max_length=32)
class UserToken(models.Model):
user = models.OneToOneField(to=User,on_delete=models.CASCADE)
token = models.CharField(max_length=128)
2.views.py
class Login(APIView):
#从前后端分离的项目来讲,get请求不需要写,
# 因为get就是个要登陆页面的操作,
# vue就搞定了,所以我们这里直接写post请求就可以了
def post(self,request):
user = request.POST['username']
pwd = request.POST['password']
user_obj = models.User.objects.filter(username=user,password=pwd)
if user_obj:
models.UserToken.objects.create(user=user_obj,token=uuid4())
return Response(data={'status':'True'})
return Response(data={"status":'False'})
3.局部认证:对需要的视图做认证
1.创建一个userauth.py文件写认证逻辑
from . import models
from rest_framework.exceptions import AuthenticationFailed
from rest_framework.authentication import BaseAuthentication
class UserAuth(BaseAuthentication):
# 每个认证类,都需要有个authenticate_header方法,
# 继承了BaseAuthentication类之后,这个方法就不用写了
# def authenticate_header(self,request):
# pass
def authenticate(self,request):
token = request.query_params.get('token')
# 用户请求来了之后,我们获取token值,到数据库中验证
usertoken = models.UserToken.objects.filter(token=token).first()
if usertoken:
# 验证成功之后,可以返回两个值,也可以什么都不返回
return usertoken.user,usertoken.token
else:
raise AuthenticationFailed("认证失败")
2.对需要进行认证的视图做配置
from .userauth import UserAuth
class Book(APIView):
authentication_classes = [UserAuth,]
def get(self,request):
return
def post(self,request):
return
4.全局认证:对全部视图认证
settings.py
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.userauth.UserAuth",]
}
2.权限组件
1.创建一个mypermission.py文件
from rest_framework.permissions import BasePermission
class Mypermission(BasePermission):
def has_permission(self, request, view):
if request.user.username == 'Boss':
return True
return False
from .mypermissions import Mypermission
2.对需要做权限的视图进行控制
from .mypermissions import Mypermission
class Book(APIView):
permission_classes = [Mypermission,]
def get(self,request):
return
3.如果全局需要进行控制,在settings.py写入
REST_FRAMEWORK={
"DEFAULT_PERMISSION_CLASSES":["app01.mypermission.Mypermission",]
}
3.频率组件:局部视图throttle,反爬,防攻击
1.创建一个frequencdly.py文件写代码
from rest_framework.throttling import BaseThrottle,SimpleRateThrottle
import time
from rest_framework import exceptions
visit_record = {}
class VisitThrottle(BaseThrottle):
# 限制访问时间
VISIT_TIME = 10
VISIT_COUNT = 3
# 定义方法 方法名和参数不能变
def allow_request(self, request, view):
# 获取登录主机的id
id = request.META.get('REMOTE_ADDR')
self.now = time.time()
if id not in visit_record:
visit_record[id] = []
self.history = visit_record[id]
# 限制访问时间
while self.history and self.now - self.history[-1] > self.VISIT_TIME:
self.history.pop()
# 此时 history中只保存了最近10秒钟的访问记录
if len(self.history) >= self.VISIT_COUNT:
return False
else:
self.history.insert(0, self.now)
return True
def wait(self):
return self.history[-1] + self.VISIT_TIME - self.now
2.在需要使用频率限制的地方使用频率组件
from .frequendly import VisitThrottle
class Book(APIView):
permission_classes = [VisitThrottle,]
def get(self,request):
return
3.如果需要全局使用的话,在settings.py
REST_FRAMEWORK={
,
"DEFAULT_THROTTLE_CLASSES":["app01.frequendly.VisitThrottle",]
}
4.url注册器:使用ModelViewSet序列化组件的数据接口可以使用url注册器。
1.
from django.conf.urls import url,include
from django.contrib import admin
from app01 import views
from rest_framework import routers
router = routers.DefaultRouter()
#自动帮我们生成四个url
router.register(r'authors', views.AuthorView)
router.register(r'books', views.BookView)
urlpatterns = [
# url(r'^books/$', views.BookView.as_view(),), #别忘了$符号结尾
# url(r'api/', include(router.urls)),
url(r'', include(router.urls)), #http://127.0.0.1:8000/books/ 也可以这样写:http://1270.0..1:8000/books.json/
#登陆认证接口
url(r'^login/$', views.LoginView.as_view(),), #别忘了$符号结尾
]
2.
from rest_framework.viewsets import ModelViewSet
class AuthorView(ModelViewSet):
queryset = models.Author.objects.all()
serializer_class = AuthorSerializers
class BookView(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BookSerializers

 浙公网安备 33010602011771号
浙公网安备 33010602011771号