

书生·浦语大模型全链路开源体系+internlm2报告
学习资料来源:
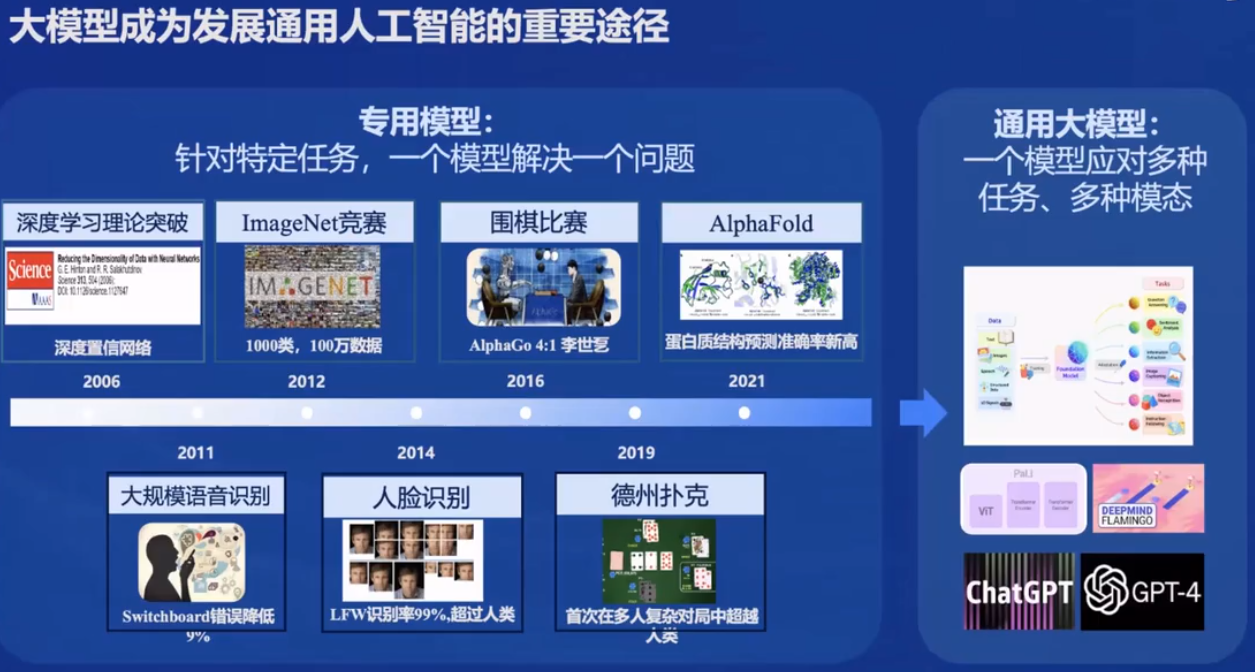
# 模型规格
7b 和 20b
internlm2的三个版本:internlm2质量好,internlm2-base可塑性好,internlm2-chat对话好
建模质量的提升,可以在相同数据的情况下有更好的表现。
# 模型亮点
1. 20w上下文,
2. 推理数学代码能力提升,
3. 结构化创作
4. 工具调用能力
5. 内生计算、代码解释
轻量级和重量级,同级无敌
# 应用案例
带有情感,有共情能力的对话
结构化写作,续写、创作
计算能力、1000以内计算,规划求解
可以给一份数据,让它分析
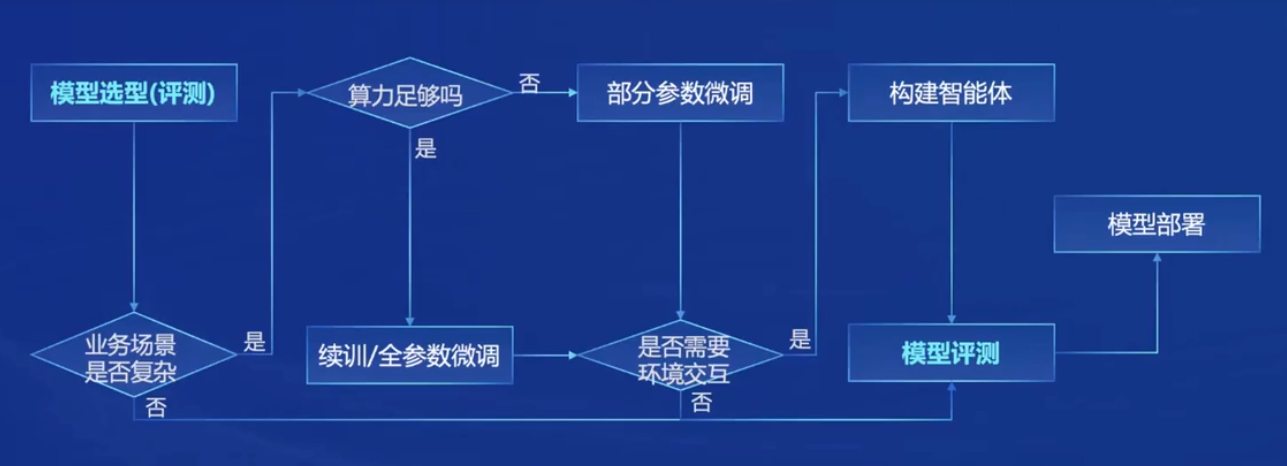
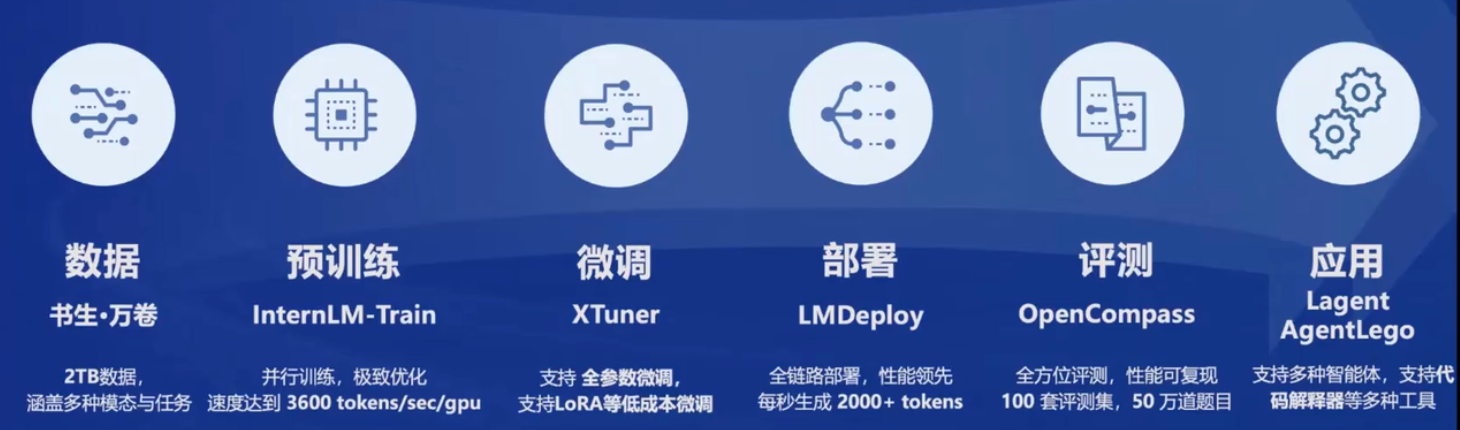
# 评测维度
经常想不到怎么总结大模型的能力,这样就挺好:
语言、知识、推理、数学、代码、智能体
api?怎么调用呢?后面的课程里注意一下

提问?数据集指哪种数据?
书籍、视频课程、文章、数字矩阵?
论文,没有很多读论文的经验。
作为新手,先看看摘要吧,以下是百度翻译的结果。如果感觉不太通顺,可能是ai领域的专有名词?
像ChatGPT和GPT-4这样的大型语言模型(LLM)的发展引发了关于通用人工智能(AGI)出现的讨论。然而,在开源模型中复制这些进步一直是一项挑战。
本文介绍了InternetLM2,这是一种开源LLM,通过创新的预训练和优化技术,在6个维度和30个基准的综合评估、长上下文建模和开放式主观评估方面优于其前身。
InternetLM2的预训练过程非常详细,强调了各种数据类型的准备,包括文本、代码和长上下文数据。
InternetLM2有效地捕获了长期依赖性,最初在4k个词点上进行训练,然后在预训练和微调阶段升级到32k个词点,在200k个“干草堆中的针”测试中表现出非凡的性能。
InternLM2使用 监督微调(SFT)和一种新的 基于人类反馈的条件在线强化学习(COOL-RLHF)策略 进行了进一步调整,该策略解决了人类偏好冲突和奖励黑客攻击。
通过发布不同训练阶段和模型大小的InternetLM2模型,我们为社区提供了对模型演变的见解。
作为初学者,或者门外汉。不得不把整个模型当做一个黑箱。哪怕里面的技术细节都被完整展开,着眼点还是怎么用和用来干嘛的层面。
用来干嘛:
在6个维度和30个基准的综合评估、长上下文建模和开放式主观评估方面。
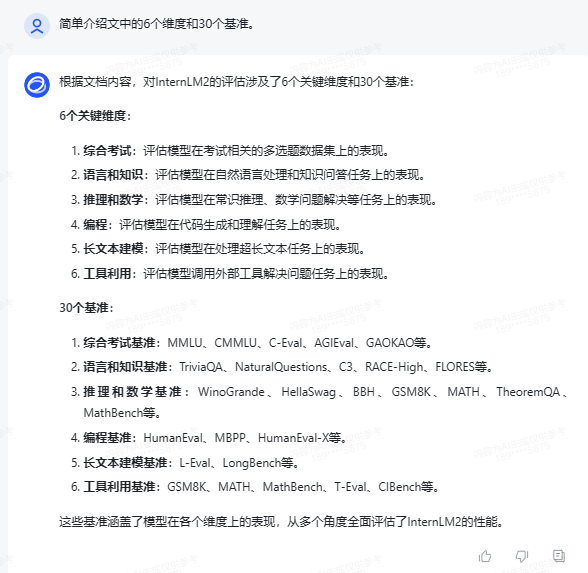
总结的不错,大概能搞清楚黑箱能干嘛。新问题可能还得在实践中思考。
上面提出了一个问题关于训练集,文中给出了答案:

那假如我们普通人要做一份数据集该如何组织呢?假如是纯文本的,100份公司内部公文案例,应该用txt还是doc格式?一份案例一个文件还是全部放在一个文件里?要在每个案例前标注该案例的写作目的吗?
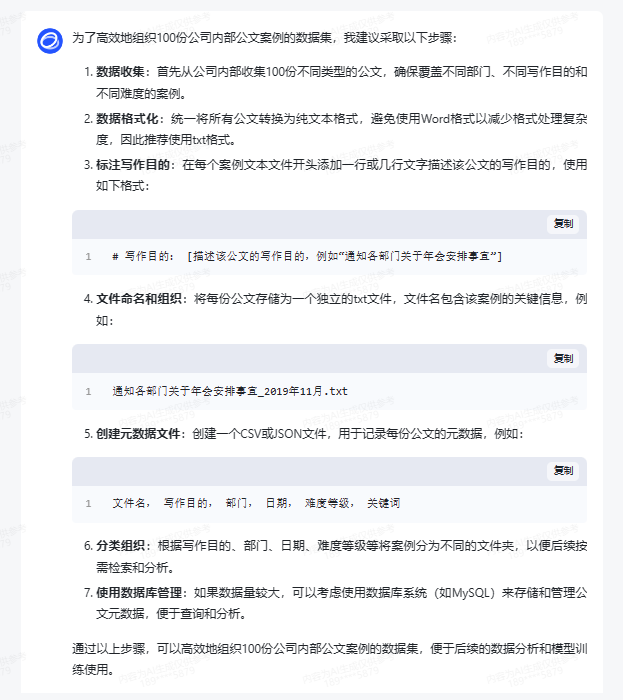
也许可以这样弄?下次试试。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix