书生·浦语大模型全链路开源体系——学习笔记
学习来源:https://www.bilibili.com/video/BV1Rc411b7ns/
资料来源:https://github.com/InternLM/tutorial/discussions/36 (有同学发pdf,还有其他同学的笔记)
俺没啥知识积累,很多信息不太会折叠。姑且做个笔记试试。
引言
大模型,简称通用大模型,能够一个模型解决多种类型的问题。也许可能把人脸识别、打牌下棋、语音识别给学会?
书生·浦语大模型,为社区贡献了很多数据和模型。
模型可以分,轻量,中量,重量,分别是7b,20b,123b。大概是用两个轴来划分,一个是体量、成本、规模限制;另一个是tokens、语境、推理、理解能力。二者不可兼得。
打分,能体现不同模型之间的差距。internLM在开源大模型里吊打同类。
如何应用?
考虑:业务场景复杂度、算力要求、交互要求。最后测评并部署。
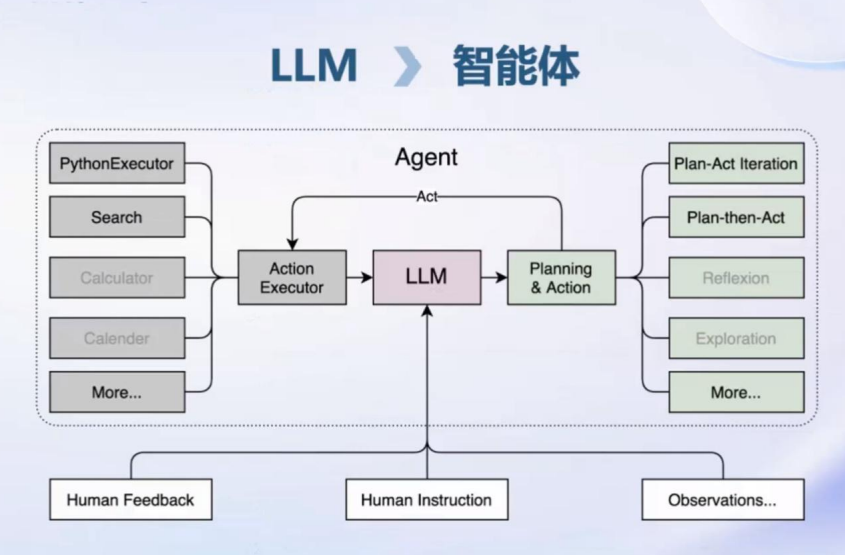
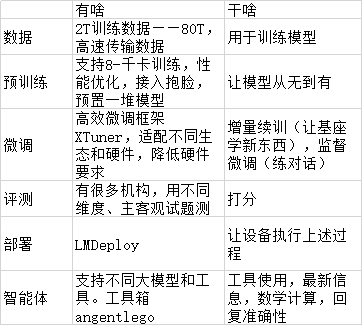
图片比文字要清楚多

浦生提供了大模型的全链条:数据-预训练-微调-部署-评测-应用
接下来介绍每个环节分别有什么和做什么?
产生问题:
不知道从什么小项目着手开始做比较好
备份几张感觉接下来或许能用得上的ppt