

diffuser扩散模型\datawhale组队学习——v6.DDIM和音频
今日学习来源:《扩散模型从原理到实践》学习手册 - 飞书云文档 (feishu.cn) 任务四
学习内容:
1、DDIM(把小猫变成小狗)
2、音频生成。
首先还是熟悉的环境安装环节,会报错,先把unit1的环境安装搬过来。

接下来阅读模型的原理:
总之是一个函数,类似递推函数。加噪很简单,去噪很复杂。
可以看出来,训练函数里是对这个计算式的实现。
但计算式的对错,不知道咋验证。反正结果对就行。
图像反转,需要提供的参数有:

图像,图像的prompt,替换成的prompt,训练参数。
作者很贴心的替我们问了为啥不用图生图。因为新图拿旧图当训练对象,原图被tokenize,被encode,信息基本被解构了;而反转是将原图加噪到混沌,在去噪的过程中调整重现的方向,在此次生图的前半段用到了原图信息,相当于在枯木上重新抽芽,相似度更高。
本期作业:

接下来把它换成小狗:

虽然有点怪,但是成功啦。
代码也很怪。
贴一下看看,此前必要的环境安装和invert、sample函数要写好。
#把小猫放到image2里面
image2=sample(new_prompt, start_latents=inverted_latents[-(start_step+1)][None],
start_step=start_step, num_inference_steps=50)[0]
image2
#将小猫的图片加噪,变成混沌态
prompt2=new_prompt
with torch.no_grad(): latent = pipe.vae.encode(tfms.functional.to_tensor(image2).unsqueeze(0).to(device)*2-1)
l = 0.18215 * latent.latent_dist.sample()
inverted_latents = invert(l, prompt2,num_inference_steps=50)
inverted_latents.shape
#混沌态
with torch.no_grad():
im = pipe.decode_latents(inverted_latents[-1].unsqueeze(0))
pipe.numpy_to_pil(im)[0]
#这里将小猫重新加噪复原
pipe(prompt2, latents=inverted_latents[-1][None], num_inference_steps=50, guidance_scale=3.5).images[0]
#这里将小狗加噪复原
start_step=10
new_prompt2 = prompt2.replace('cat', 'puppy')
sample(new_prompt2, start_latents=inverted_latents[-(start_step+1)][None],
start_step=start_step, num_inference_steps=50)[0]
第二部分是音频生成,这段代码训练时间太长,我挂机的时候colab给我中断了,结果不得不重新训练。刚好第二次,说我今天超时运行gpu。所以谨记,要一气呵成,别让它停下来。
然后恶补了一下音频的相关内容。
采样率,采样点,振幅,相位。
采样率是一秒采样频率,太低会听不到,太高的也会有部分听不到。
采样点,相当于将声音分解的最小单位,应该也算是时间单位吧。
振幅,声音大小。
相位,音色和音调。补一下初中知识:音色受振源影响。
于是它发出了一些声音。相比开头混乱的噪音,这里能听了一些。
原理是真不懂啊。
看看训练参数:
首先是音频参数:采样率,声音参数。(好像是一个范围内的数字)
epochs,训练次数?
lr,学习速度
batch,训练集数,建议4个。
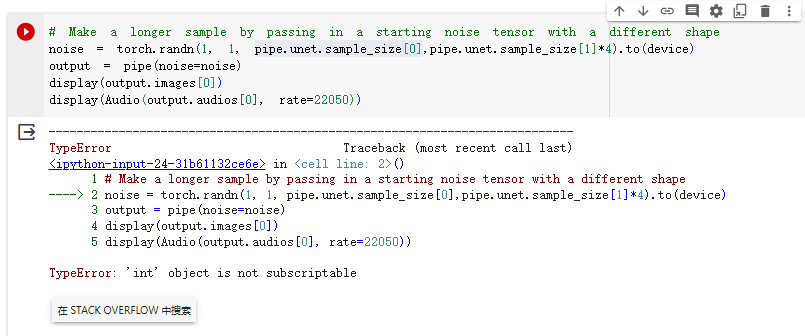
这里不能全都运行,因为上面说,他导入了一个自己的模型,如果运行的话,就引入了他的模型,把我们本来训练好的pipe给顶掉了。
而且他的pipe没有设置好sample_size的参数,我们就报错卡住了。
解决办法可能是重新训练自己的pipe,反正别用他给的了。
还是很奇妙的。
于是引人思考,有没有类似stable diffusion一样的音频生成模型呢?
模型没找到,(hugging face上应该有),找到一个公司,riffusion。
生成的还可以,可以给他歌词,让它唱。
但是没能成功部署到本地。
希望路过的大佬能研究研究
(18 封私信 / 82 条消息) 有没有像stable diffusion一样的ai音频生成开源模型? - 知乎 (zhihu.com)

