Scala集合操作中的几种高阶函数
Scala是函数式编程,这点在集合操作中大量体现。高阶函数,也就是能够接收另外一个函数作为参数的函数。
假如现在有一个需要是将List集合中的每个元素变为原来的两倍,现在来对比Java方式实现和Scala方式实现区别
Java方式实现,先将集合中的每个元素遍历出来,然后再乘以2,塞到另外一个集合中
1 2 3 4 5 6 7 8 9 | ArrayList<Integer> list1 = new ArrayList<Integer>();list1.add(3);list1.add(5);list1.add(7);ArrayList<Integer> list2 = new ArrayList<Integer>();for (Integer elem : list1) { list2.add(elem * 2);}System.out.println(list2); |
Scala方式实现
1 2 3 | val list1 = List(3, 5, 7)val list2 = list1.map(multiple) //map高阶函数,能够接收另外一个函数def multiple(n1: Int): Int = { <br> 2 * n1 <br>}<br>println(list2) |
可以发现相对于Java的实现方式,Scala中更偏向于使用高阶函数来解决问题,并且也简化了很多。
或许你会有些许疑问,这是什么鬼,这没有简化到哪里呀!的确,但是这里只是小小的演示。
Scala中常用的高阶函数有如下几种
1.映射函数(map)
map函数

小注:在Scala中的泛型是表示方法是“[]”,java中的泛型表示方式是“<>”。map函数存在于所有集合类型中,包括在String中。
现在再看前面的实例,它是这样来执行的
- 首先依次遍历list1集合的元素
- 将各个元素传递给Multiple函数,计算并返回
- 将返回结果放到一个新的集合中,并赋给list2
- 输出结果
为了能够更好的理解,尝试编写一个List,来模拟List
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | object Demo_021{ def main(args: Array[String]): Unit = { val myList = MyList() val myList2 = myList.map(multiple) //调用map高阶函数,并传入mutiple函数 println("myList2=" + myList2) println("myList=" + myList.list1) } def multiple(n1: Int): Int = { 2 * n1 }}//伴生类,模拟Listclass MyList { var list1 = List(3, 5, 7) var list2 = List[Int]() //map高阶函数,接收另外一个函数作为参数, // f:Int=>Int : f表示是函数,:Int表示所传入的函数f的参数类型,必须是Int型,=>Int表示所传入函数f的返回值为Int // : List[Int] :表示Map函数的返回值为List[Int] def map(f:Int=>Int): List[Int] = { for (item<-list1) { list2 = list2 :+ f(item) //f(item) 表示调用所传入的函数,每次执行都会将返回写过写入到list2中 } list2 //返回list2,未明确指定返回值,以函数最后一行的执行结果作为返回值 } }//伴生对象 object MyList { //使用apply方式实例化 def apply(): MyList = new MyList() } |
运行结果:

模拟有些拙劣,但是基本能够说明问题,map方法在List底层所实现时,也是逐个遍历并执行所传入的函数,最后返回执行结果集合
下面是List中map函数的源码,实际List集合底层在调用map方法的时候所做的操作和上面类似

使用实例1:将 val names = List("Alice", "Bob", "Nick") 中的所有单词,全部转成字母大写,返回到新的List集合中.
1 2 3 4 5 6 7 8 9 10 | object Demo_022 { def main(args: Array[String]): Unit = { val names = List("Alice", "Bob", "Nick") val names2 = names.map(upper) println("names=" + names2) } def upper(s:String): String = { s.toUpperCase }} |
执行结果:

2.扁平化(flatMap)
flatmap:所谓扁平化,就是将集合中的每个元素的子元素映射到某个函数并返回新的集合。
实例:
1 2 3 4 5 6 7 8 9 10 11 | object Demo_022 { def main(args: Array[String]): Unit = { val names = List("Alice", "Bob", "Nick") //相当于在原来map高阶函数的基础上做了二次循环,将元素进一步打散 val names2 = names.flatMap(upper) println("names=" + names2) } def upper(s:String): String = { s.toUpperCase }} |
运行结果:

3.过滤(filter)
filter:将符合要求的数据(筛选)放置到新的集合中
应用案例:将 val names = List("Alice", "Bob", "Nick") 集合中首字母为'A'的筛选到新的集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 | object Demo_025 { def main(args: Array[String]): Unit = { val names = List("Alice", "Bob", "Nick") def startA(s: String): Boolean = { s.startsWith("A") } val names2 = names.filter(startA) //表示调用filter高阶函数 println("names=" + names2) }} |
运行结果:

还有更为简洁的操作:
1 2 | // val names2: List[String] = names.filter((x:String)=>x.startsWith("A")) val names2: List[String] = names.filter(_.startsWith("A")) |
filter函数在执行过程中,类似于map函数,将符合条件的筛选出来放到一个集合中。
4.化简(reduce、reduceLeft、reduceRight)
化简:将二元函数引用于集合中的函数。有三种类型的函数,reduce、reduceLeft和reduceRight,其中reduce等同于reduceLeft。
reduceLeft(f) 接收的函数需要的形式为 op: (B, A) => B): B,
reduceleft(f) 的运行规则是 从左边开始执行将得到的结果返回给第一个参数,然后继续和下一个元素运行,将得到的结果继续返回给第一个参数,继续.。
reduceRight的运行规则和reduceRight类似,只是从右往左执行
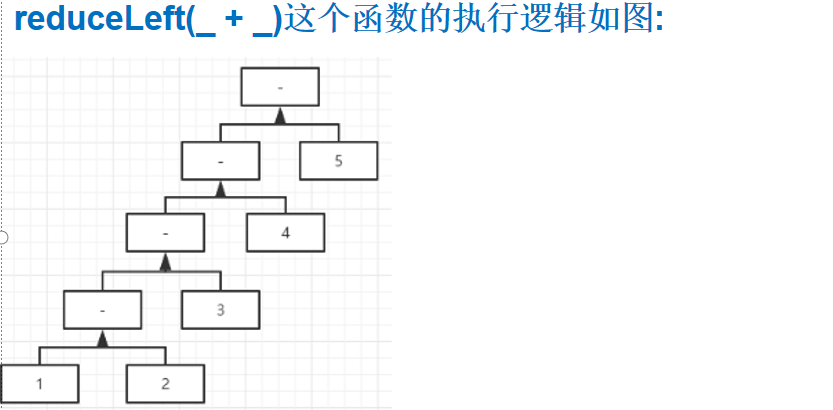
实例1:val list = List(1,2,3,4,5) , 求出list的和
1 2 3 4 5 6 7 8 9 10 | object Demo_026 { def main(args: Array[String]): Unit = { val list = List(1, 2, 3, 4, 5) def sum(n1: Int, n2: Int): Int = { n1 + n2 } val res1 = list.reduceLeft(sum) println("res=" + res1) }} |
输出为60。
实例2:观察reduce、reduceRight和reduceLeft在求List(1, 2, 3, 4 ,5)中元素差值时的表现
1 2 3 4 5 6 7 8 9 10 11 12 | object Demo_027 { def main(args: Array[String]): Unit = { val list = List(1, 2, 3, 4 ,5) def minus( num1 : Int, num2 : Int ): Int = { num1 - num2 } println(list.reduceLeft(minus)) // 输出-13 println(list.reduceRight(minus)) //输出3 println(list.reduce(minus)) //输出-13 }} |
运行结果为

综述:reduce等同于reduceLeft、执行规则从左向右,而reduceRight执行规则是从右向左。
另外,还可以使用化简来求出一个集合的最值
1 2 3 4 5 6 7 8 9 10 11 12 13 | object Demo_027 { def main(args: Array[String]): Unit = { val list = List(1, 2, 3, 4 ,5) def max( num1 : Int, num2 : Int ): Int = { if(num1<num2){ num2 }else{ num1 } } println(list.reduceLeft(max)) // 求list中的最大值 }} |
简化形式是:
1 | val result: Int = list.reduceLeft((num1,num2)=>{if(num1<num2) num2 else num1}) |
5.折叠(foldLeft、foldRight、fold)
fold函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到list中的所有元素被遍历。有三种函数形式:fold、foldLeft和folderRight。
fold函数在使用上基本和reduce函数在使用上基本相同,甚至reduceLeft函数的底层,就是调用foldLeft函数

观察如下实例
1 2 3 4 5 6 7 | object Demo_028 { def main(args: Array[String]): Unit = { val list = List(1, 2, 3, 4) def minus(n1: Int, n2: Int): Int = { n1 - n2 } println(list.foldLeft(5)(minus))<br><br> println(list.foldRight(5)(minus))} } |
输出结果为:

它的执行过程是这样的:


另外foldLeft和foldRight 缩写方式分别是:/:和:\
1 2 3 4 5 6 7 8 9 10 | object Demo_028 { def main(args: Array[String]): Unit = { val list = List(1, 2, 3, 4) def minus(n1: Int, n2: Int): Int = { n1 - n2 } println((5 /: list)(minus)) //等价于list.foldLeft(5)(minus) println((list :\ 5)(minus)) //list.foldRight(5)(minus) }} |
可以使用folderLeft统计字母出现的次数,还可以用来统计文本中单词出现的次数
6.扫描(scanLeft、scanRight)
扫描,即对某个集合的所有元素做fold操作,但是会把产生的所有中间结果放置于一个集合中保存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | object Demo_029 { def main(args: Array[String]): Unit = { def minus( num1 : Int, num2 : Int ) : Int = { num1 - num2 } //5 (1,2,3,4,5) =>(5,4,2,-1,-5,-10) val i8 = (1 to 5).scanLeft(5)(minus) //IndexedSeq[Int] println(i8) def add( num1 : Int, num2 : Int ) : Int = { num1 + num2 } //5 (1,2,3,4,5) =>(5,6,8, 11,15,20) val i9 = (1 to 5).scanLeft(5)(add) //IndexedSeq[Int] println(i9) }} |
输出结果为:

观察另外一个实例
1 2 3 4 5 6 7 8 9 | object Demo_030 { def main(args: Array[String]): Unit = { def test(num1:Int,num2:Int): Int ={ num1 * num2 } var result=(1 to 3).scanLeft(3)(test) println(result) }} |
运行结果

综述,scanLeft执行类似于folderLeft,只是它会将中间结果缓存下来。
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程