
K-Means算法原理
原理
给定样本集,k-means算法得到聚类
,使得下面平方误差最小
其中表示聚类
的中心点。
实现
上式最小化是一个NP难问题,实际上采用EM算法可以求得近似解。算法伪代码如下
输入:,聚类数量k
从D中随机选择k个样本点作为k个聚类的中心
repeat
循环所有样本点,把样本点划分到最近的聚类中:arg min||x - ui||
更新聚类中心:ui = (∑x) / n
util 聚类中心不再变化
输出:
实例
sklearn已经实现上述算法,测试代码如下
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.cluster import k_means
# 1、读取数据文件
df = pd.read_csv("data.csv", header=0)
df.head()
# 2、原始文件画图
X = df['x']
y = df['y']
plt.scatter(X, y)
plt.show()
# 3、k-means分为三类
model = k_means(df, n_clusters=3)
print(model)
# 4、分类后画图
cluster_centers = model[0]
cluster_labels = model[1]
plt.scatter(X, y, c=cluster_labels)
for center in cluster_centers:
plt.scatter(center[0], center[1], marker="p", edgecolors="red")
plt.show()
k_means计算得到的model包含三部分
(1)各个聚类的中心
(2)样本点的类别数组
(3)所有样本点到各自聚类中心的距离平方和
运行结果如下

k值的确定
当我们不知道样本有几类时,可以采用以下两种方式确定最优k值
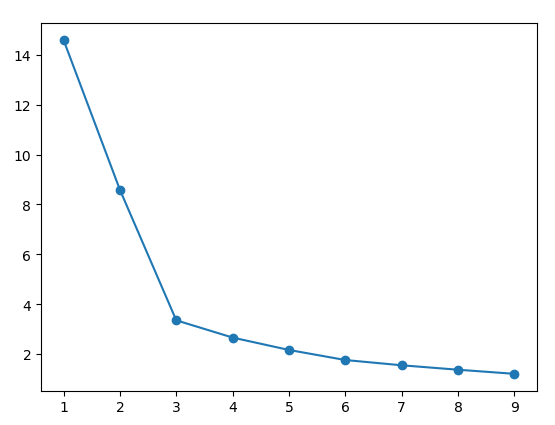
1、肘部法则
对于上面k_means方法返回值得第三部分,样本点到聚类中心点的距离平方和s。很明显,k = m时(m表示样本数量),s = 0,s随着k的增加而减小,s减小幅度随着k增加而减小。我们找到s变化率改变最大时对应的k值(即肘部)作为最优k值。代码如下
# 肘部法则
index = [] # 横坐标数组
inertia = [] # 纵坐标数组
# K 从 1~ 10 聚类
for i in range(9):
model = k_means(df, n_clusters=i + 1)
index.append(i + 1)
inertia.append(model[2])
# 绘制折线图
plt.plot(index, inertia, "-o")
plt.show()
运行结果如下,显然k = 3是最优值
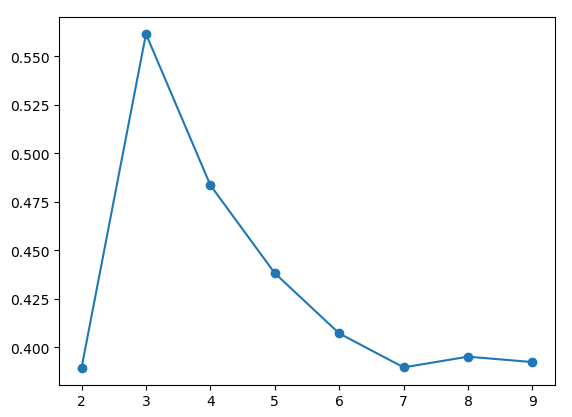
2、轮廓系数
假设我们已经通过一定算法,将待分类数据进行了聚类,得到k个簇 。对于其中的一个点 i 来说:
a(i) = i向量到它所属簇中其它点的距离平均值
b(i) = i向量到所有其他簇的点的平均距离的最小值
那么点i的轮廓系数就为:
![]()
可见轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。将所有点的轮廓系数求平均,就是该聚类结果总的轮廓系数。
代码实现如下
#轮廓系数
from sklearn.metrics import silhouette_score # 导入轮廓系数计算模块
index2 = [] # 横坐标
silhouette = [] # 轮廓系数列表
# K 从 2 ~ 10 聚类
for i in range(8):
model = k_means(df, n_clusters=i + 2)
index2.append(i + 2)
silhouette.append(silhouette_score(df, model[1]))
print(silhouette) # 输出不同聚类下的轮廓系数
# 绘制折线图
plt.plot(index2, silhouette, "-o")
plt.show()
实验结果如下,显然k = 3是最优值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号