
PLSA主题模型
主题模型
主题模型这样理解一篇文章的生成过程:
1、 确定文章的K个主题。
2、 重复选择K个主题之一,按主题-词语概率生成词语。
3、 所有词语组成文章。
这里可以看到,主题模型仅仅考虑词语的数量,不考虑词语的顺序,所以主题模型是词袋模型。
主题模型有两个关键的过程:
1、 doc -> topic
2、 topic -> word
其中topic -> word是定值,doc -> topic是随机值。这是显而易见的,对于不同的文章,它的主题不尽相同,但是对于同一个主题,它的词语概率应该是一致的。好比记者写了一篇科技新闻和一篇金融新闻,两篇新闻的主题分布必然不同,但是这两篇文章都包含数学主题,那么对于数学主题出现的词语应该大致相同。
主题模型的关键就是要计算出topic -> word过程,也就是topic-word概率分布。对于一篇新的文章,我们已知它的词语数量分布,又训练出了topic-word概率分布,则可以使用最优化方法分析出文章对应的K个最大似然主题。
PLSA
PSLA主题模型正是上述思想的直接体现,文章生成过程如下

PLSA主题模型图形化过程如下
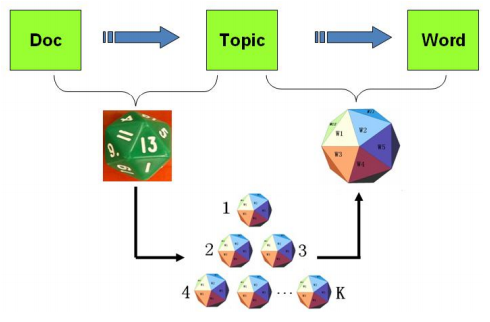
我们考虑第m篇文档的生成过程,其中涉及1个doc-topic骰子,K个topic-word骰子。记第m篇文档为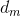 ,第m篇文章出现第z个主题的概率为
,第m篇文章出现第z个主题的概率为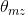 ,第z个主题生成词语w的概率为
,第z个主题生成词语w的概率为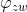 (这里与文档有关系,与文档没有关系)。对于某个词语的生成概率,即投掷一次doc-topic骰子与一次topic-word骰子生成词语w的概率为
(这里与文档有关系,与文档没有关系)。对于某个词语的生成概率,即投掷一次doc-topic骰子与一次topic-word骰子生成词语w的概率为
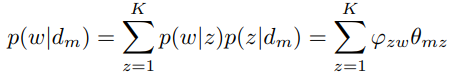
于是第m篇文档的n个词语生成概率为
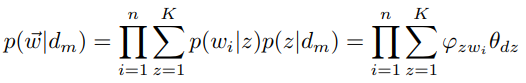
如果我们有M篇文档,考虑到文档之间独立,则所有词语生成的概率为M个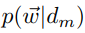 的乘积。
的乘积。
PLSA模型最优化包含两个参数求解,可以使用EM算法计算。读者有兴趣可以参考前面的文章。
参考:《LDA数学八卦》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号