
DNN模型训练词向量原理
转自:https://blog.csdn.net/fendouaini/article/details/79821852
1 词向量
在NLP里,最细的粒度是词语,由词语再组成句子,段落,文章。所以处理NLP问题时,怎么合理的表示词语就成了NLP领域中最先需要解决的问题。
因为语言模型的输入词语必须是数值化的,所以必须想到一种方式将字符串形式的输入词语转变成数值型。由此,人们想到了用一个向量来表示词组。在很久以前,人们常用one-hot对词组进行编码,这种编码的特点是,对于用来表示每个词组的向量长度是一定的,这个长度就是对应的整个词汇表的大小,对应每个具体的词汇表中的词,将该词的对应的位置置为1,向量其他位置置为0。举个例子,假设我们现有5个词组组成的词汇表,词’Queen’对应的序号是2,那么它的词向量就是(0,1,0,0,0)。其他的词也都是一个长度为5的向量,对应位置是1,其余位置为0。
One-hot code非常简单,但是存在很大的问题,当词汇表很大,比如数百万个词组成了词汇表时,每个词的向量都是数百万维,会造成维度灾难。并且,one-hot 编码的向量会过于稀疏,这样的稀疏向量表达一个词效率并不高。
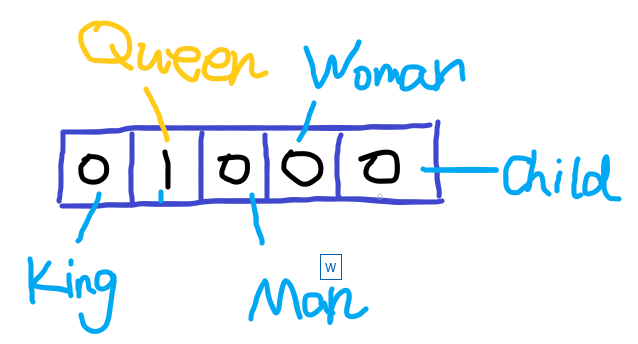
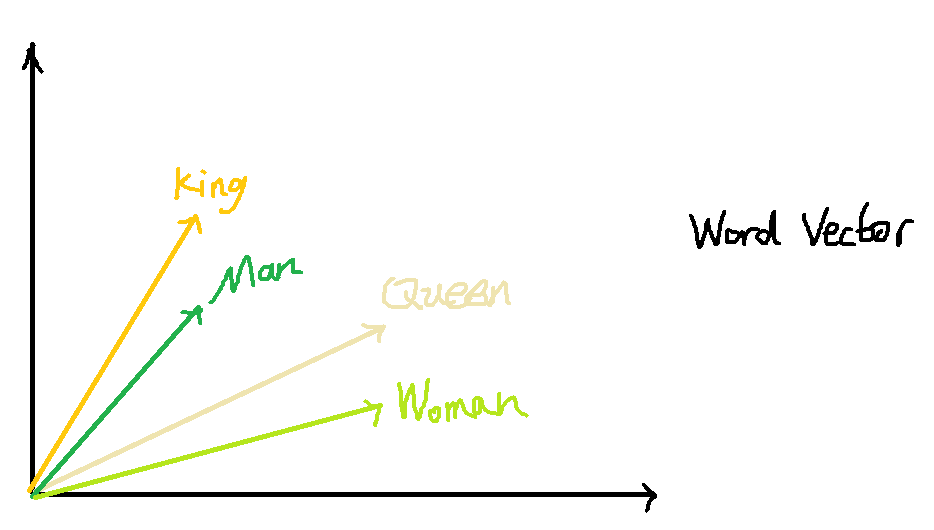
而dristributed representation(通常叫做词向量)可以很好的解决one-hot code的问题,它是通过训练,将每个词都映射到一个较短的词向量上(这样就解决了每个词向量的维度过大问题),所有的词向量构成了词汇表的每个词。并且更重要的是,dristributed representation表示的较短词向量还具有衡量不同词的相似性的作用。比如‘忐’,‘忑’两个字如果作为两个词,那么在dristributed representation表示下,这两个词的向量应该会非常相似。不仅如此,dristributed representation表示的词向量还能表示不同词组间组合的关系,比如假设现在由训练好的词向量,现在拿出King,Queen,Man,Woman四个词的词向量,则:
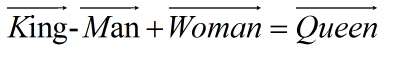
2.DNN训练词向量
词向量怎么得到呢,这里得先说语言模型:
f(x)=y
在NLP中,我们把x看作是一个句子里的一个词,y是这个词的上下文。这里的f就是语言模型,通过它判断(x,y)这个样本,是否符合自然语言的逻辑法则。直白的说,语言模型判断样本(x,y)是不是人话。
而词向量正是从这个训练好的语言模型中的副产物模型参数(也就是神经网络的权重)得来的。这些参数是作为输入x的某种向量化表示,这个向量就叫做词向量。
注意我们训练词向量的逻辑,我们是为了得到一个语言模型的副产物-词向量,去训练这个模型。所以我们的目的不是关注在怎么优化该模型,而是为了获取该模型的参数构造词向量。
在Word2vec出现之前,已经有用神经网络DNN来训练出词向量了。一般采用三层神经网络结构,分为输入层,隐藏层,和输出层(softmax层)。
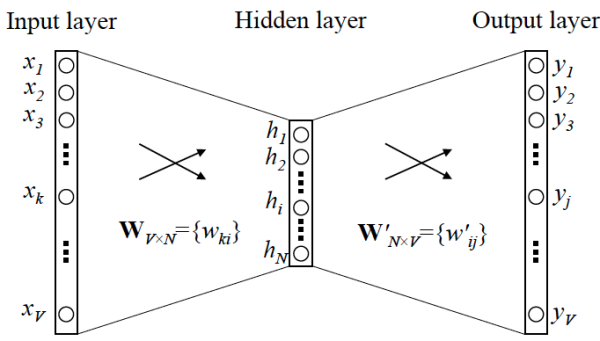
该模型中V代表词汇表的大小,N代表隐藏层神经元个数(即想要的词向量维度)。输入是某个词,一般用one-hot表示该词(长度为词汇表长度),隐藏层有N个神经元,代表我们想要的词向量的维度,输入层与隐藏层全连接。输出层的神经元个数和输入相同,隐藏层再到输出层时最后需要计算每个位置的概率,使用softmax计算,每个位置代表不同的单词。该模型中我们想要的就是经过训练以后,输入层到隐藏层的权重作为词向量。
假设词汇表有10000个,词向量维度设定为300。
输入层:
为词汇表中某一个词,采用one-hot编码 长度为1X10000
隐藏层:
从输入层到隐藏层的权重矩阵W_v*n就是10000行300列的矩阵,其中每一行就代表一个词向量。这样词汇表中所有的词都会从10000维的one-hot code转变成为300维的词向量。
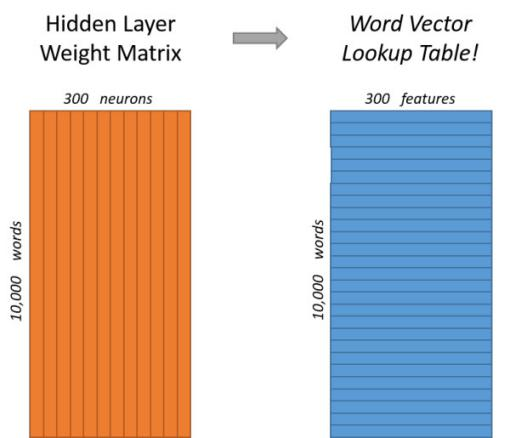
输出层:
经过神经网络隐层的计算,这个输入的词就会变为1X300的向量,再被输入到输出层。输出层就是一个sotfmax回归分类器。它的每个结点将会输出一个0-1的概率,所有结点的值之和为1,我们就会取最大概率位置检测是否为输入样本x对应的y。
在此补充一下,有没有考虑过一个问题,采用one-hot编码时,输入维度是10000,如果我们将1X10000 向量与10000X300的矩阵相乘,它会消耗大量的计算资源。
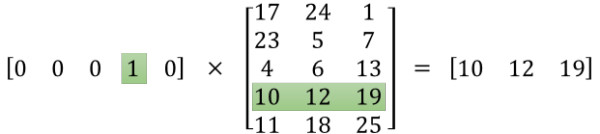
我们发现,one-hot编码时,由于只有一个位置是1,将该向量与隐藏层权重矩阵相乘会发现,one-hot编码向量中对应1的index,词向量中这个下标对应的一行词向量正式输出结果。所以,在真正的从输入到隐藏层的计算中,并不会真正的进行矩阵相乘计算,而是通过one-hot向量1的index取直接查找隐藏层的权重矩阵对应的行,这样极大的简化了计算。
3.CBOW与Skip-gram模型:
该模型更一般情况是使用CBOW(Continuous Bag-of-Words)或Skip-gram两种模型来定义数据的输入和输出。CBOW的训练输入的是某一个特征词的上下文相关的词对应的词向量,输出是这个特定词的词向量。而Skip-gram刚好相反,输入一个特征词,输出是这个特征词。上下文相关的词。
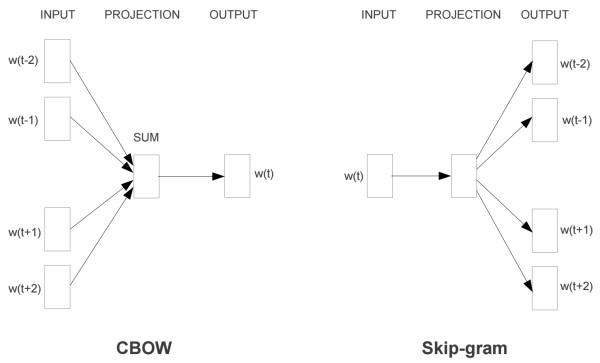
这里我们以CBOW模型为例
假设我们有一句话,people make progress every day。输入的是4个词向量,’people’ , ‘make‘ , ‘every’ , ‘day’, 输出是词汇表中所有词的softmax概率,我们的目标是期望progress词对应的softmax概率最大。

开始时输入层到隐藏层的权重矩阵和隐藏层到输出层的权重矩阵随机初始化,然后one-hot编码四个输入的词向量’people’ ‘make’ ‘every’ ‘day’,并通过各自向量1的位置查询输入到隐藏层的权重矩阵行数,找寻其对应的词向量。将4个词向量与隐藏层到输出层的权重相乘通过激活函数激活后再求平均,最后进行softmax计算输出的每个位置的概率。再通过DNN反向传播算法,我们就可以更新DNN的隐藏层的权重参数,也就得到了更新后词向量。通过不断的训练,我们得到的模型参数就会越来越准确,词向量也会变得越来越好。
通过这样的训练,为什么词向量会具有衡量不同词语义相似性的功能呢?
以CBOW模型为例,这里我们可以看到,通过one-hot编码的输入样本,每次只会在隐藏层中输出与它对应的权重矩阵的行。也就是说在本次训练中,隐藏层只会调用与输入样本相关的某一行的权重参数,然后反向传播后每次都是局部更新隐藏层的权重矩阵。
根据语言学,同义词的上下文很相似,这样在训练模型中,相似输入值都是对应相似的输出值,每次就会更偏向于局部更新对应这些词的词向量的参数,那么久而久之意思有关联且相近的词就会在词向量上很接近。模型的输出只是每个位置一一对应了词向量,本身没有太大的意义。我的理解训练词向量的模型就像在做聚类一样,每次把上下文的词与中心词对应的词向量通过训练关联在一起并彼此影响,这样意思相近的词对应的词向量也会越来越像近。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号