生成式对抗网络
生成式对抗网络
基本概念介绍
我們要講生成這件事情,好那生成有什麼樣特別的地方呢,到目前為止啊大家學到的network都是一個function,你給他一個X就可以輸出一個Y,我們已經學到各式各樣的network架構可以處理不同的X 不同的Y。
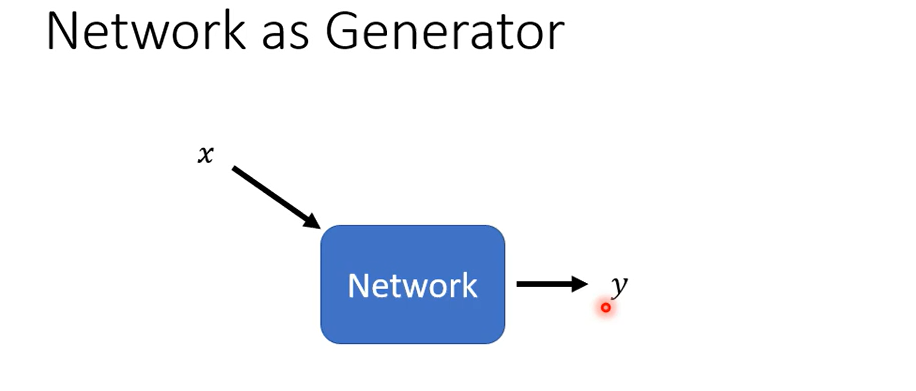
我們已經學到輸入的X如果是一張圖片的時候怎麼辦,我們也學到輸入的X如果是一個sequence的時候怎麼辦,我們也學到輸出的Y可以是一個數值可以是一個類別,也可以是一個sequence,那我們目前有講過的network架構其實應該可以涵括多數你日後會遇到的問題了。
那接下來呢我們要進入一個新的主題這個新的主題,是要把network當做一個generator來用,那把network拿來當作generator使用有什麼樣特別的地方呢

他特別的地方是現在network的輸入會加上一個random的variable,會加上一個Z ,那這個Z呢是從某一個distribution sample出來的,所以現在network它不是只看一個固定的X得到輸出,它是同時看X跟Z得到輸出,那你可能會問說network怎麼同時看X跟Z呢,那這個有很多不同的做法啦,就看你怎樣設計你的network架構。
舉例來說,你可以說X是個向量Z是個向量, 兩個向量直接接起來變成一個比較長的向量,就當作network的input,這樣可以嗎這樣可以,或者是你的X跟Z正好長度一模一樣,把它們相加以後當做network的input,這樣可以嗎 這樣可以。

好那Z特別的地方是 它是不固定的,每一次我們用這個network的時候都會隨機生成一個Z,所以Z每次都不一樣,它是從一個distribution裡面sample出來的,那這個distribution這邊有一個限制,是它必須夠簡單, 什麼叫夠簡單呢,這邊夠簡單的意思是我們知道它的式子長什麼樣子,我們可以從這個distribution去做sample,舉例來說這個distribution可以是一個function distribution,你知道function distribution的式子,你知道怎麼從gaussian distribution做sample,它也可以是uniform distribution那uniform distribution的式子你一定知道,你也知道怎麼從uniform distribution做sample,所以這一個distribution的形狀你自己決定,但你只要記得說它是簡單的你能夠sample它的 就結束了

好所以每次今天有一個X進來的時候,你都從這個distribution裡面做一個sample,然後得到一個output,隨著你sample到的Z不同,Y的輸出也就不一樣,所以這個時候我們的network輸出不再是單一一個固定的東西,而變成了一個複雜的distribution,同樣的X作為輸入我們這邊每sample到不一樣的東西,通過一個複雜的network轉換以後它就會變成一個複雜的分布,你的network的輸出就變成了一個distribution,那這種可以輸出一個distribution的network我們就叫它generator。
接下來我們就是要講,怎麼訓練出這種generator,那在講怎麼訓練出generator之前啊我們第一個想要回答的問題是為什麼我們需要訓練generator,為什麼我們需要generator,輸入X輸出Y這樣固定的輸入跟輸出關係不好嗎,為什麼需要輸出是一個分布呢,所以以下就舉一個例子來跟你說明為什麼輸出有時候需要是一個分布

video prediction,就是給機器一段的影片然後它要預測接下來會發生什麼事情,它要做的事情呢是去預測小精靈這個遊戲接下來的遊戲畫面會長什麼樣子
你就給你的network過去的遊戲畫面,然後它的輸出就是新的遊戲畫面下一秒的下一個時間點的遊戲畫面,要得到這樣的訓練資料一點都不困難,你只要不斷的去錄製有人在玩小精靈的畫面,然後你就可以知道說給定這三個frames接下來會發生什麼事,你的訓練資料裡面有嘛,你有一堆錄製的影片就知道說給定過去的資訊接下來會發生什麼事,你就可以訓練你的network讓它輸出的Y跟我們目標越接近越好就結束了。
有人可能會問說怎麼輸出一張圖片,這個一張圖片就是一個很長的向量啊,所以你只要讓你的network可以輸出一個很長的向量,然後這個向量整理成圖片以後跟你的目標越接近越好 ,
那其實在這個github裡面呢,它不是直接把整個畫面當做輸入,它是從畫面裡面只切一小塊當做輸入,就它把這整個畫面切成很多塊,然後分開來處理,不過我們這邊為了簡化說明就當作network是一次輸入一整個這樣的畫面。
好 但是這樣會有什麼問題呢,如果你用剛才的方法用我們學過的network training的方法Supervise learning train下去,你得到的結果可能會是這個樣子,這個是機器預測出來的結果

所以你看有點模模糊糊的,而且中間還會變換角色神奇的是那個小精靈啊走著走著 居然就分裂了,它走到轉角的時候看它走到轉角的時候就分裂成兩隻了,有時候走著走著還會消失,為什麼小精靈走著走著就分裂了呢

那因為今天呢對這個network而言,在訓練資料裡面同樣的輸入,同樣的轉角有時候小精靈是往左轉,有時候小精靈是往右轉,這樣這兩種可能性同時存在你的訓練資料裡面,所以你的network學到的就是兩面討好,因為它需要得到一個輸出,這個輸出同時距離向左轉最近同時也距離向右轉最近,那怎麼樣同時距離向左轉最近向右轉最近呢,也許就是同時向左也向右轉,所以你的network它就會得到一個錯誤的結果,向左轉是對的 向右轉也是對的,但是同時向左向右轉 反而是不對的
那有什麼樣的可能性可以處理這個問題呢,一個可能性就是讓機器的輸出是有機率的,讓它不再是輸出單一的輸出,讓它輸出一個機率的分佈

當我們給這個network一個distribution的時候,當我們給這個network input加上一個Z的時候,它的輸出就變成了一個distribution,它的輸出就不再是固定的。我們希望訓練一個network,它可以知道說它的輸出的這個分佈包含了向左轉的可能也包含向右轉的可能
舉例來說,假設選擇的Z是一個binary的random variable,它就只有0跟1 ,那可能各佔50%也許你的network就可以學到說Z sample到1的時候就向左轉,Z sample到0的時候就向右轉,這樣子就可以解決
那什麼時候我們會特別需要處理這種問題呢,什麼時候我們會特別需要這種generator的model呢,當我們的任務需要一點創造力的時候。更具體一點的講法就是我們想要找一個function,但是同樣的輸入有多種可能的輸出,而這些不同的輸出都是對的
比如绘画,让不同的人去画一个红眼睛的角色,不同的人可能画出的不同

还有对话机器人

generative的model其中一個非常知名的就是generative adversarial network它的縮寫 是GAN,GAN还有各种变形

你可以在網路上呢找到一個GAN的動物園,那個GAN的動物園裡面呢蒐集了超過五百種以上的GAN,那你知道每次有人發明了一個新的GAN的時候他就會在前面加一個英文的字母,但是你知道英文的字母是有限的,很快的英文的字母就被用盡了,舉例來說在GAN的動物園裡面至少就有六種的SGAN它們都是不同的東西,但它們通通被叫做SGAN,甚至還發生了這樣子的狀況,有一篇paper他提出來的叫做
“Variational auto-encoding GAN”照理說應該所寫成AEGAN或者是AGAN,但是作者呢加了一個註解說哎呀AEGAN被別人用了啦所有的英文字母看起來都被別人用了,我只好叫做α-GAN這樣子,沒有錯 GAN呢實在太多了所以就會發生這種狀況。

那我們現在等一下要舉的例子啊就是要讓機器生成動畫人物的二次元人物的臉,那等一下我們舉的例子呢是Unconditional的generation,什麼叫unconditional generation呢,就是我們這邊先把X拿掉,那之後我們在講到conditional generation的時候我們會再把X加回來。

這邊呢先把X拿掉,所以我們的generator它輸入就是Z,它的輸出就是Y

那輸入的這個Z是什麼呢,我們等一下都假設Z呢是一個normal distribution,Z是從一個normal distribution sample出來的向量,那這個向量呢通常會是一個low-dimensional的向量,它的維度其實是你自訂的啦,你自己決定的啦那通常你就訂個50啦100啊這樣子的大小,它是你自己決定的,你從這邊Z,你從這個normal distribution裡面呢sample一個向量以後丟到generator裡面,Generator就給你一個對應的輸出,那我們希望對應的輸出,就是一個二次元人物的臉

那到底generator要輸出怎麼樣的東西才會變成一個二次元人物的人臉呢,其實這個問題沒有你想像的那麼困難,一張圖片就是一個非常高維的向量,所以generator實際上做的事情就是產生一個非常高維的向量。

舉例來說 假設這是一個64X64然後彩色的圖片那你的generator輸出就是64X64X3那麼長的向量 把那個向量整理一下就變成一張二次元人物這個就是generator要做的事情

當你輸入的向量不同的時候你的輸出就會跟著改變,所以你從這個normal distribution裡面Sample Z出來, Sample到不同的Z,那你輸出來的Y都不一樣。那我們希望說不管你這邊sample到什麼Z,輸出來的都是動畫人物的臉
那講到這邊可能有同學會問說這邊為什麼是normal distribution呢,不能是別的嗎 , 可以是別的,那我的經驗是不同的distribution之間的差異可能並沒有真的非常大,不過你還是可以找到一些文獻試著去探討不同的distribution之間有沒有差異
但是這邊其實你只要選一個夠簡單的distribution就行,因為你的generator會想辦法把這個簡單的distribution對應到一個複雜的distribution。

那在GAN裡面一個特別的地方就是除了generator以外,我們要多訓練一個東西,這個東西呢叫做discriminator。這個discriminator它的作用是,它會拿一張圖片作為輸入,那它的輸出是什麼呢,它的輸出是一個數值,它輸出就是一個scalar,這個scalar越大就代表說現在輸入的這張圖片越像是真實的二次元人物的圖像。
那至於discriminator的neural network的架構啊,這也完全是你自己設計的,所以generator它是個neural network ,Discriminator也是個neural network,他們的架構長什麼樣子,你完全可以自己設計,你可以用CNN 你可以用transformer 都可以,只要你能夠產生出你要的輸入輸出就可以了。
那在這個例子裡面像discriminator因為輸入是一張圖片,你很顯然會選擇CNN對不對,CNN在處理影像上有非常大的優勢,那你的discriminator很有可能裡面會有大量的CNN的架構,那至於實際上要用什麼樣的架構,這完全是問你自己完全可以自己決定。
好那GAN的基礎的概念是什麼呢,為什麼要多一個discriminator呢,這邊呢就講一個故事,這個故事呢跟演化是有關的

那枯葉蝶呢長得跟枯葉非常像,它可以躲避天敵,那枯葉蝶的祖先呢其實也不是長得像枯葉一樣,也許他們原來也是五彩斑斕。但是它的也是會演化的,所以天敌為了要吃到這些枯葉蝶,偽裝成枯葉的枯葉蝶呢,所以它也進化了。
那現在我們generator要做的事情是畫出二次元的人物,那generator怎麼學習畫出二次元的人物呢,它學習的過程是這樣子,第一代的generator它的參數幾乎完全是隨機的,所以它根本就不知道要怎麼畫二次元的人物

所以它畫出來的東西就是一些莫名其妙的雜訊,那discriminator接下來呢它學習的目標是要分辨generator的輸出跟真正的圖片的不同,那在這個例子裡面可能非常的容易,對discriminator來說它只要看說圖片裡面有沒有兩個黑黑的圓球,就是眼睛有眼睛就是真正的二次元人物,沒有眼睛就是generator產生出來的東西,接下來generator就調整它的裡面的參數,Generator就進化了,它調整它裡面的參數 它調整的目標是為了要騙過discriminator,假設discriminator判斷一張圖片是不是真實的依據看的是有沒有眼睛,那generator就產生眼睛出來給discriminator看,所以generator產生眼睛出來然後他可以騙過第一代的

但是discriminator也是會進化的,所以第一代的discriminator就變成第二代的discriminator,第二代的discriminator會試圖分辨這一組圖片跟真實圖片之間的差異,舉例來說generator生成的都沒有頭髮也沒有嘴巴,real image是有頭髮的也有嘴巴,接下來第三代的generator就會想辦法去騙過第二代的discriminator,既然第二代的discriminator是看有沒有嘴巴來判斷是不是真正的二次元人物,那第三代的generator就會把嘴巴加上去。

那discriminator也會逐漸的進步,它會越來越嚴苛,然後期待Generator產生出來的圖片就可以越來越像二次元的人物,那因為這邊有一個generator,有一個discriminator,它們彼此之間是會互動
GAN的paper呢是發表在14年的arvix,那最早在這個GAN的原始的paper裡面呢把generator跟discriminator當作是敵人,如果你有看很多網路文章的話,它都會舉例說啊generator是假鈔,然後discriminator是警察,警察要抓做假鈔的人,假鈔就會越來越像,警察就會越來越厲害等等,因為覺得generator跟discriminator中間有一個對抗的關係,所以就用了一個adversarial這個字眼,Adversarial就是對抗的意思,但是至於generator跟discriminator他們是不是真的在對抗呢,這只是一個擬人化的說法而已

那你也可以說他們其實是亦敵亦友的合作關係

generator跟discriminator他們就是兩個network,那network在訓練前你要先初始化它的參數,所以我們這邊就假設說generator跟discriminator它們的參數 都已經被初始化了, 初始化完以後接下來訓練的第一步是
定住你的generator只train你的discriminator,那因為一開始你的generator的參數是隨機初始化的,那如果你又固定住你的generator那它根本就什麼事都沒有做啊,它的參數都是隨機的,所以你丟一堆向量給它,它的輸出都是亂七八糟的圖片,那其實如果generator參數是初始化的話,你連上面图片這樣子的結果都產生不出來,產生出來的就很像是電視機壞掉的那一種雜訊
那你從這個gaussian distribution裡面呢去random sample一堆vector,把這些vector丟到generator裡面,它就吐出一些圖片 一開始這些圖片會跟正常的二次元人物非常的不像
那你會有一個database,這個database裡面有很多二次元人物的頭像,這個去網路上爬個圖庫就有了,這個不難蒐集,那你從這個圖庫裡面呢去sample一些二次元人物的頭像出來,接下來你就拿真正的二次元人物頭像跟generator產生出來的結果去訓練你的discriminator
那discriminator它訓練的目標是什麼呢,它訓練的目標是要分辨真正的二次元人物跟generator產生出來的二次元人物它們之間的差異,講得更具體一點,你實際上的操作是這個樣子,你可能會把這些真正的人物都標1,Generator產生出來的圖片都標0,接下來對於discriminator來說這就是一個分類的問題,或者是regression的問題,如果是分類的問題你就把真正的人臉當作類別1,Generator產生出來的這些圖片當作類別2,然後訓練一個classifier就結束了,或者是有人會把它當作regression的問題那你就教你的discriminator說看到這些圖片你就輸出1,看到這些圖片你就輸出0,都可以 ,總之discriminator就學著去分辨這個real的image跟產生出來的image之間的差異, 但是實際上怎麼做你可以當作分類的問題來做,也可以當作regression的問題來做。
那第二步我們訓練完discriminator以後,接下來定住discriminator改成訓練generator

怎麼訓練generator呢,比叫擬人化的講法是我們就讓generator想辦法去騙過discriminator,因為剛才discriminator已經學會分辨真圖跟假圖的差異,Generator如果可以騙過discriminator它可以產生一些圖片Discriminator覺得是真正的圖片的話,那generator產生出來的圖片可能就可以以假亂真
那實際上這個欺騙這件事情是怎麼操作的呢,它實際上的操作方法是這樣子,你有一個generator,generator吃一個向量作為輸入,從gaussian distribution sample出來的向量作為輸入,然後產生一個圖片接下來我們把這個圖片丟到Discriminator裡面Discriminator會給這個圖片一個分數
那generator它訓練的目標就,Discriminator參數是固定的,我們只會調整generator的參數,Generator訓練的目標是要Discriminator的輸出值越大越好

講得更具體一點實際上你的操作是這個樣子Generator是一個network裡面有好幾層,然後呢 Discriminator也是一個network裡面有好幾層,我們把generator跟Discriminator直接接起來當做一個比較大的network來看待,舉例來說generator如果是五層的network,Discriminator如果是五層的network,把它們接起來我們就把它當作是一個十層的network來看待,而這個十層的network裡面其中某一層啊某一個hidden layer它的輸出很寬,它的輸出的這個dimension呢就跟圖片裡面pixel的數目乘三是一樣的,你把這個hidden layer的輸出呢做一下整理以後 就會變成一張圖片,所以這整個大的network裡面其中某一層的輸出就是代表一張圖片。
那我們要做的事情是什麼呢,我們要做的事情是整個巨大的network啊,它會吃一個向量作為輸入,然後他會輸出一個分數,那我們希望調整這個network讓輸出的分數越大越好,但是要注意一下 我們不會去調對應到Discriminator的部分,我們不會去調這個巨大network的最後幾層,為什麼不調最後幾層呢,你可以想想看假設調最後幾層的話,這整個遊戲就被hack了,因為假設你要輸出的分數越大越好,我直接調最後output layer那個neural bias把它設成一千萬那不是輸出就很大了嗎,所以Discriminator這邊的參數是不能動的,我們只調generator的參數,好那這邊呢至於怎麼調Generator的參數呢,這個訓練的方法啊跟我們之前訓練一般的network是沒有什麼不同的。
我們之前說訓練network的時候就是訂一個loss啊 然後你用gradient descent讓loss越小越好那這邊呢 ,你也有一個目標只是這個目標呢,不是越小越好而是越大越好,那當然你也可以把這個目標Discriminator output成一個負號就當作loss嘛 對不對你可以把Discriminator output乘一個負號,當作loss,然後generator訓練的目標就是讓loss越小越好,或者你也可以說我們就是要讓Discriminator output的值越大越好,然後我們用gradient ascent不是gradient descent,gradient descent是讓loss越小越好gradient ascent會讓你的目標函數越大越好,我們會用gradient ascent去調generator讓Discriminator的輸出越大越好。這是同一件事,這邊訓練generator的方法也是用gradient descent base的方法,跟我們之前在訓練一個一般network的時候是沒有什麼差異的,
所以現在講了兩個步驟第一個步驟 固定generator訓練discriminator,第二個步驟固定discriminator訓練generator,接下來呢 接下來就是反覆的訓練

要做動畫人物的人臉生成,那你可能會問說到底可以做到什麼樣的程度呢,以下的結果是我在17年的時候做的我自己試著train了一下GAN看看GAN是不是真的可以產生二次元的人物,好那我訓練了我把那個generator呢Update了一百次以後,所謂generator update 一百次的意思是說,就是discriminator train一下generator train一下discriminator train一下generator train一下這樣往返一百次以後得到的結果

是這樣子 嗯 不知道在做些什麼,但我接下來呢就再等了一下Train 一千次,discriminator 跟generator各自訓練這樣反覆一千次以後機器就產生了眼睛

訓練到兩千次的時候,你發現嘴巴就出來了

訓練到五千次的時候,已經開始有一點人臉的樣子了,而且你發現說機器學到說動畫人物啊就是要有那個水汪汪的大眼睛,所以他每個人的眼睛呢都塗得非常的大,塗有反白 代表說反光是水汪汪的大眼睛

好 這個是訓練一萬次以後的結果,有發現形狀已經有出來了,只是有點模糊,很多地方有點暈開的感覺好像是水彩畫的樣子

接下來這個是update兩萬次的結果

這個是update五萬次的結果,我後來就停在五萬次的地方

那其實你在作業裡面是有機會做得比這個結果更好的,那如果是最好可能可以做到這個樣子

那你會發現說這些人物呢都還不錯,只是有一些比較還是會有偶爾會有一些崩壞啦,但乍看之下呢可能比一些作畫畫風會崩壞的動畫公司,比如說一些妹非妹做的還要好一些了,那其實啊 如果你有好的資料庫的話,那當然我們提供給大家的資料是做不到這個地步的,如果你有真的非常好的資料的話,也許你可以做出真的很好的結果

找到了一個這樣子的結果,這個是用StyleGAN做的,那用StyleGAN做起來可以做到這個樣子。
那除了產生動畫人物以外當然也可以產生真實的人臉,有一個技術叫做progressive GAN,它可以產生非常高清的人臉

你觉得上面人脸图像,哪一排是机器产生的?实际都是机器产生的。
GAN你可以產生你沒有看過的人臉,舉例來說用GAN你可以做到這樣子的事情,我們剛才說GAN這種generator就是輸入一個向量 輸出一張圖片,那你不只可以輸入一個向量輸出一張圖片

你還可以把輸入的向量做內插, 做interpolation,把輸入的向量做內插以後會發生什麼事呢,你就會看到兩張圖片之間連續的變化,舉例來說你輸入一個向量這邊產生一個看起來非常嚴肅的男人,你輸入一個向量這邊產生一個笑口常開的女人,那你輸入這兩個向量中間的interpolation,它的內插,你就看到這個男人逐漸的笑了起來

你輸入一個向量這邊產生一個往左看的人(从下往上第二排最左边),你輸入一個向量,這邊產生一個往右看的人(从下往上第二排最右边),你把往左看的人跟往右看的人做interpolation會發生什麼事呢,機器並不是傻傻地把兩張圖片疊在一起變成一個雙面人,而是機器知道說往左看的人臉跟往右看的人臉介於他們中間的就是往正面看,你在訓練的時候其實並沒有真的告訴機器這件事 ,但機器可以自己學到說把這兩張臉做內插應該會得到一個往正面看的人臉

GAN是Ian Goodfellow在14年的時候提出來的

今天比如說你用BigGAN產生出來的圖片可以做到像這個樣子

這些圖片都是機器生成的,當然仔細看一下還是可以發現一些破綻,舉例來說這隻狗 牠多了一個腳啊。那有時候機器
也會產生一些幻想中的角色,舉例來說機器就產生了一個網球狗啊

理论介绍与WGAN
那接下來呢我們要講一點理論的部分,告訴你說實際上為什麼 GAN 的這一番操作,為什麼這個 Generator 跟 Discriminator 的互動可以讓我們的 Generator產生像是真正的人臉的圖片,那這背後的互動在做的到底是什麼樣的事情

那我們先來弄清楚我們今天的訓練的目標到底是什麼,你知道我們在訓練 Network 的時候,你就是要定一個 Loss Function,定完以後用 Gradient Descent 去調你的參數,去 Minimize 那個 Loss Function 就結束了
那在這個 Generation 的問題裡面到底我們要 Minimize 的或者是我們要 Maximize 的到底是什麼樣的東西呢,我們要把這些事弄清楚才能夠做接下來的事情, 那在 Generator 裡面我們到底想要 Minimize或者是 Maximize 什麼樣的東西呢
我們想要 Minimize 的東西是這個樣子的,我們有一個 Generator,給它一大堆的 Vector,給它從 Normal Distribution Sample 出來的東西,丟進這個 Generator 以後會產生一個比較複雜的 Distribution,這個複雜 Distribution我們叫它 \(P_G\),真正的 Data 也形成了另外一個 Distribution叫做 \(P_{data}\),我們期待$ P_G$ 跟 \(P_{data}\) 越接近越好
那如果你一下子沒有辦法想像這個 PG Pdata 是怎麼一回事的話那我們用一維的狀況來跟大家說明

输入通過這個 Generator通過一個 Network ,裡面很複雜,不知道做了什麼事情以後,那可能本來大家都集中在中間,通過這個 Generator,通過一個 Network 裡面很複雜不知道做了什麼事情以後,這些點就分成兩邊。Divergence 這邊指的意思就是這兩個,你可以想成是這兩個 Distribution 之間的某種距離,如果這個 Divergence 越大就代表這兩個 Distribution 越不像,Divergence 越小就代表這兩個 Distribution 越相近
然後呢 我們現在的目標找一組 Generator 裡面的參數,就 Generator 也是一個 Network,裡面有一大堆的 Weight 跟 Bias,找一組 Generator 的參數,它可以讓我們產生出來的 PG 跟 Pdata之間的 Divergence 越小越好,我要找的就是這樣子的 Generator這邊把它寫作 G*
所以我們這邊要做的事情跟一般 Train Network 其實非常地像,我們第一堂課就告訴你說我們定義了 Loss Function,找一組參數 Minimize Loss Function,我們現在其實也定義了我們的 Loss Function,在 Generation 這個問題裡面我們的 Loss Function就是 PG 跟 Pdata 的 Divergence,就是它們兩個之間的距離,它們兩個越近那就代表這個產生出來的 PG 跟 Pdata 越像

我們這邊遇到一個困難的問題,這個 Loss我們是可以算的,但是這個 Divergence 是要怎麼樣算呢,那你可能知道一些 Divergence 的式子,比如說 KL Divergence比如說 JS Divergence這些, Divergence 用在這種 Continues 的Distribution 上面你要做一個很複雜的在實作上你幾乎不知道要怎麼算的積分,那我們根本就無法把這個 Divergence 算出來
我們算不出這個 Divergence,我們又要如何去找一個 G去 Minimize 這個 Divergence 呢,這個就是 GAN 所遇到的問題

而 GAN 呢是一個很神奇的做法,它可以突破我們不知道怎麼計算 Divergence 的限制,所以我現在遇到的問題就是不知道怎麼計算 Divergence,而 GAN 告訴我們就是GAN 告訴我們的就是只要你知道怎麼從 PG 和 Pdata這兩個 Distributions Sample 東西出來,就有辦法算 Divergence,你不需要知道 PG 跟 Pdata它們實際上的 Formulation 長什麼樣子,你只要能夠 Sample,就能夠算 Divergence

好 那這個就是要靠 Discriminator 的力量。那我們剛才講過說 Discriminator是怎麼訓練出來的呢,它的訓練的目標是看到 Real Data就給它比較高的分數,看到這個 Generative 的 Data就給它比較低的分數
你也可以把它寫成式子,把它當做是一個 Optimization 的問題,這個 Optimization 的問題是這樣子的,我們要訓練一個 Discriminator,這個 Discriminator 可以去 Maximize某一個 Function,我們這邊叫做 Objective Function,就我們要 Maximize 的東西我們會叫 Objective Function,如果 Minimize 我們就叫它 Loss Function。
我們現在要找一個 D它可以 Maximize 這個 Objective Function,這個 Objective Function 長什麼樣子呢,這個 Objective Function 長這個樣子,我們有一堆 Y它是從 Pdata 裡面 Sample 出來的,也就是它們是真正的 Image,而我們把這個真正的 Image 丟到 D 裡面得到一個分數,再去弄那另外一方面,我們有一堆 Y它是從 PG 從 Generator 所產生出來的,把這些圖片也丟到 Discriminator 裡面得到一個分數再取 Log 1 - D (Y),那我們希望這個 Objective Function V越大越好。

那這個 Discriminator其實可以當做是一個 Classifier,它做的事情就是把藍色這些點從 Pdata Sample 出來的真實的 Image當作 Class 1,把從 PG Sample出來的這些假的 Image當作 Class 2,有兩個 Class 的 Data訓練一個 Binary 的 Classifier,訓練完就等同於是解了這一個 Optimization 的問題
那這邊最神奇的地方是以下這句話,這一個式子這個紅框框裡面的數值,它跟 JS Divergence 有關,那事實上有趣的事情是我覺得最原始的 GAN 的 Paper它的發想可能真的是從 Binary Classifier 來的一開始是把 Discriminator寫成 Binary 的 Classifier,然後有了這樣的 Objective Function,然後再經過一番推導以後這個 Objective Function它的 Maximum就是你找到一個 D可以讓這個 Objective Function它的值最大的時候,這個最大的值跟 JS Divergence 是有關的,它們沒有完全一模一樣。那至於實際上的推導過程
你可以參見原始 Ian J. Goodfellow 寫的文章

但是我們還是可以從直觀上來理解一下,為什麼這個 Objective Function 的值會跟 Divergence 有關呢,那這個直觀的理解並沒有很困難,因為你可以想想看,假設 PG 跟 Pdata它的 Divergence 很小,也就 PG 跟 Pdata 很像它們差距沒有很大,它們很像 PG 跟 Pdata Sample 出來的藍色的星星跟紅色的星星它們是混在一起的。那個時候對 Discriminator 來說Discriminator 就是在 Train 一個Binary 的 Classifier,對 Discriminator 來說既然這兩堆資料是混在一起的,那就很難分開這個問題,所以既然這個問題很難,你在解這個 Optimization Problem 的時候你就沒有辦法讓這個 Objective 的值非常地大,所以這個 Objective 這個 V 的Maximum 的值就比較小
你的兩組 Data 很不像它們的 Divergence 很大,那對 Discriminator 而言就可以輕易地把它分開,當 Discriminator 可以輕易把它分開的時這個 Objective Function 就可以衝得很大,那所以當你有大的 Divergence 的時候,這個 Objective Function 的 Maximum 的值就可以很大。
當然這邊是用直觀的方法來跟你講,那詳細的證明請參見 GAN 原始的 Paper。
我們本來的目標是要找一個 Generator去 Minimize PG 跟 Pdata 的 Divergence,但我們卡在不知道怎麼計算 Divergence,那我們現在知道我們只要訓練一個 Discriminator訓練完以後這個 Objective Function 的最大值就是這個 Divergence,就跟這個 Divergence 有關

那我們何不就把紅框框裡面這一項跟 Divergence 做替換呢,我們何不就把 Divergence替換成紅框框裡面這一項呢,所以我們就有了這樣一個 Objective Function,這個 Objective Function 乍看之下有點複雜

我們是要找一個 Generator去 Minimize 紅色框框裡面這件事。但是紅框框裡面這件事又是另外一個 Optimization Problem,它是在給定 Generator 的情況下去找一個 Discriminator,這個 Discriminator可以讓 V 這個 Objective Function 越大越好。然後我們要找一個 G
讓紅框框裡面的值最小,這個 G 就是我們要的 Generator

而剛才我們講的這個 Generator 跟 Discriminator互動啊, 互相欺騙這個過程其實就是想解這一個有 Minimize又有 Maximize 這個 Min Max 的問題。那至於實際上為什麼下面這個 Argument 可以解這個問題,你也可以參見原始 GAN 的 Paper
那講到這邊也許你就會問說為什麼是 JS Divergence而且還不是真的 JS Divergence,是跟 JS Divergence 相關而已怎麼不用真正的 JS Divergence,或不用別的比如說 KL Divergence,你完全可以這麼做,你只要改了那個 Objective Function,你就可以量各式各樣的 Divergence。

那至於怎麼樣設計 Objective Function得到不同的 Divergence,那有一篇叫做 F GAN 的 Paper 裡面有非常詳細的證明,它有很多的 Table 告訴你說不同的 Divergence要怎麼設計它的 Objective Function
GAN 是以不好 Train 而聞名的,所以接下來我們就要講一些GAN 訓練的小技巧,而 GAN 有什麼樣訓練的小技巧呢,而其中的最其實它 GAN 訓練的小技巧非常非常多,
最知名的就是很多人都聽過的 WGAN,那這個 WGAN 是什麼呢,在講 WGAN 之前我們先講 JS Divergence 有什麼樣的問題
好 在想 JS Divergence 的問題之前我們先看一下 PG 跟 Pdata 有什麼樣的特性,那 PG 跟 Pdata 有一個非常關鍵的特性是PG 跟 Pdata 它們重疊的部分往往非常少。

怎麼說呢這邊有兩個理由,第一個理由是來自於 Data 本身的特性,因為你想 PG 跟 Pdata它們都是要產生圖片的,那圖片其實是高維空間裡面的一個低維的 Manifold。怎麼知道圖片是高維空間裡面低維的 Manifold 呢,因為你想想看你在高維空間裡面隨便 Sample 一個點,它通常都沒有辦法構成一個二次元人物的頭像。
或者是如果是以二維空間來想的話,那圖片的分布可能就是二維空間的一條線,二維空間中多數的點都不是圖片,就高維空間中隨便 Sample 一個點都不是圖片,只有非常小的範圍Sample 出來它會是圖片,所以從這個角度來看從,資料本身的特性來看PG 跟 Pdata它們都是 Low Dimensional 的 Manifold,用二維空間來講PG 跟 Pdata 都是二維空間中的兩條直線,而二維空間中的兩條直線除非它剛好重合不然它們相交的範圍幾乎是可以忽略的,這是第一個理由
第二個理由是我們是從來都不知道 PG 跟 Pdata 長什麼樣子,我們對 PG 跟 Pdata它的分布的理解其實來自於 Sample,所以也許 PG 跟 Pdata它們是有非常大的 Overlap 的範圍。但是我們實際上在了解這個 PG 跟 Pdata在計算它們的 Divergence 的時候,我們是從 Pdata 裡面 Sample 一些點出來,從 PG 裡面 Sample 一些點出來,如果你 Sample 的點不夠多,你 Sample 的點不夠密,那就算是這兩個 Divergence 實際上這兩個 Distribution 實際上有重疊,但是假設你 Sample 的點不夠多,對 Discriminator 來說它也是沒有重疊的

所以以上給你兩個理由試圖說服你說 PG 跟 Pdata 這兩個分布它們重疊的範圍是非常小的,而幾乎沒有重疊這件事情對於 JS Divergence 會造成什麼問題呢。JS Divergence 有個特性是兩個沒有重疊的分布JS Divergence 算出來就永遠都是 Log2,不管這兩個分布長什麼樣所以兩個分布只要沒有重疊算出來就一定是 Log2

除非你的 PG 跟 Pdata 有重合,不然這個 PG 跟 Pdata 只要它們是兩條直線,它們這兩條直線沒有相交,那算出來就是 Log2

中間這個 Generator明明就比左邊這個 Generator 好,但是你不知道,明明藍色的線就跟紅色的線比較近,但是從 JS Divergence 上面看不出這樣子的現象,那既然從 JS Divergence 上看不出這樣的現象,你在 Training 的時候你根本就沒有辦法把左边的 Generator Update 參數變成中间的 Generator,因為對你的 Loss 來說對你的目標來說這兩個 Generator 是一樣好,或者是一樣糟。
那以上是從比較理論的方向來說明,如果我們從更直觀的實際操作的角度來說明,你會發現當你是用 JS Divergence 的時候,你就假設你今天在 Train 一個Binary 的 Classifier去分辨 Real 的 Image跟 Generated Image,你會發現實際上你通常 Train 完以後正確率幾乎都是 100%。為什麼因為你 Sample 的圖片根本就沒幾張,對你的 Discriminator 來說,你 Sample 256 張 Real 的圖片,256 張 Fake 的圖片,它直接用硬背的都可以把這兩組圖片分開,知道說誰是 Real 誰是 Fake

所以實際上如果你有自己 Train 過 GAN 的話,你會發現如果你用 Binary 的 Classifier Train 下去,你會發現你幾乎每次 Train 完你的 Classifier 以後,也就你 Train 完你的 Discriminator 以後,正確率都是 100%,我們本來會期待說這個 Discriminator 的 Loss也許代表了某些事情,代表我們的 Generated Data跟 Real 的 Data 越來越接近,但實際上你在實際操作的時候你根本觀察不到這個現象,這個 Binary Classifier 訓練完的 Loss根本沒有什麼意義,因為它總是可以讓它的正確率變到 100%,兩組 Image 都是 Sample 出來的它硬背都可以得到 100% 的正確率,你根本就沒有辦法看出你的 Generator有沒有越來越好,所以過去尤其是在還沒有 WGAN 這樣的技術在我們還用 Binary Classifier當作 Discriminator 的時候,Train GAN 真的就很像巫術 黑魔法你根本就不知道你 Train 的時候有沒有越來越好,所以怎麼辦呢,那時候做法就是你每次 Update 幾次 Generator 以後,你就要把你的圖片 Print 出來看。
用人眼守在電腦前面看,發現結果不好 咔掉,重新用一組 Hyperparameter重新調一下 Network加工重做,所以過去訓練 GAN 是有點辛苦的,那既然是 JS Divergence 的問題,於是有人就想說那會不會換一個衡量兩個 Distribution 的相似程度的方式,換一種 Divergence就可以解決這個問題了呢。
於是就有了這個 Wasserstein,或使用 Wasserstein Distance 的想法

那這個 Wasserstein Distance是怎麼計算的呢,Wasserstein Distance 的想法是這個樣子,假設你有兩個 Distribution,一個 Distribution 我們叫它 P,另外一個 Distribution 我們叫它 Q,Wasserstein Distance 它計算的方法就是想像你在開一台推土機,推土機的英文叫做 Earth Move,想像你在開一台推土機,那你把 P 想成是一堆土,把 Q 想成是你要把土堆放的目的地,那這個推土機把 P 這邊的土挪到 Q 所移動的平均距就是 Wasserstein Distance,在這個例子裡面我們假設 P 都集中在這個點(蓝色),Q 都集中在這個點,對推土機而言假設它要把 P 這邊的土挪到 Q 這邊那它要平均走的距離就是 D。
所以在這個例子裡面,假設 P 集中在一個點,Q 集中在一個點,這兩個點之間的距離是 D 的話,那 P 跟 Q 的 Wasserstein Distance就是 D。所以其實 Wasserstein Distance又叫 Earth Mover Distance,但是如果是更複雜的 Distribution,你要算 Wasserstein Distance就有點困難了。

假設這是你的 P(棕色),假設這是你的 Q(深绿色),假設你開了一個推土機想要把 P 把它重新塑造一下形狀,讓 P 的形狀跟 Q 比較接近一點,那有什麼樣的做法呢,你會發現說你可能的 Moving Plans,就是你把 Q 把 P重新塑造成 Q 的方法有無窮多種

你有各式各樣不同的 Moiving Plan,用不同的 Moving Plan你算出來的距離,你推土機平均走的距離就不一樣,在左邊這個例子裡面推土機平均走的距離比較少,在右邊這個例子裡面因為捨近求遠推土機平均走的距離比較大,那難道這個 P 跟 Q 它們之間的Wasserstein Distance會根據你的不同的方法,不同的這個推土機行進的方法就算出不同的值嗎。

為了讓 Wasserstein Distance 只有一個值,所以這邊 Wasserstein Distance 的定義是窮舉所有的 Moving Plans,然後看哪一個推土的方法,哪一個 Moving 的計畫,哪一個推土的計畫可以讓平均的距離最小,那個最小的值才是 Wasserstein Distance,所以會窮舉所有把 P 變成 Q 的方法,然後看哪一個推土的平均距離最短,那選最短的那個距離當作是 Wasserstein Distance。
所以其實要計算 Wasserstein Distance是挺麻煩的,你會發現說光我只是要計算一個 Distance,我居然還要解一個 Optimization 的問題,解出這個 Optimization 的問題才能算 Wasserstein Distance。
好 那我們先不講怎麼計算 Wasserstein Distance 這件事,我們先來講假設我們能夠計算Wasserstein Distance 的話它可以帶給我們什麼樣的好處呢

對 Discriminator 而言這邊每一個 Case 算出來的 JS Divergence都是一樣都是一樣好,或一樣差,但是如果換成 Wasserstein Distance,由左向右的時候我們會知道說我們的 Discriminator 做我們的 Generator 做得越來越好,所以我們換一個計算 Divergence 的方式我們就可以解決 JS Divergence有可能帶來的問題。
這讓我想到什麼呢,這又讓我想到一個演化的例子,這是眼睛的生成

而我覺得對於當你使用 WGAN,當你使用這個 Wasserstein Distance來衡量你的 Divergence 的時候,其實就製造了類似的效果,本來 \(P_{G0}\) 跟 Pdata 非常地遙遠,你要它一步從這裡(最左边)跑到這裡(最右边),讓這個 PG0 跟 Pdata直接 Align 在一起是不可能的,可能非常地困難,對 JS Divergence 而言它需要做到直接從這一步(最左)跳到這一步(最右),它的 JS Divergence 的 Loss 才會有差異,但是對 W Distance 而言,你只要每次有稍微把 PG 往 Pdata 挪近一點,W Distance 就會有變化,W Distance 有變化你才有辦法 Train 你的 Generator去 Minimize W Distance,所以這就是為什麼當我們從 JS Divergence換成 Wasserstein Distance 的時候可以帶來的好處。
那 WGAN 實際上就是用當你用 Wasserstein Distance來取代 JS Divergence 的時候,這個 GAN 就叫做 WGAN,那接下來你會遇到的問題就是Wasserstein Distance 是要怎麼算呢,Wasserstein Distance是一個非常複雜的東西,我光要算個 Wasserstein Distance還要解一個 Optimization 的問題,實際上要怎麼計算,那這邊就不講過程,直接告訴你結果,解下面這個 Opimilazion 的 Problem,解出來以後你得到的值就是 Wasserstein Distance,就是 Pdata 跟 PG 的 Wasserstein Distance

我們就觀察一下這個式,所以如果你要 Maximum這個 Objective Function,你會達成什麼樣的效果,你會達成如果 y是從 Pdata Sample 出來的Dy就 Discriminator 的 Output 要越大越好,如果 y是從 PG從 Generator Sample 出來的那 Dy,也就 Discriminator 的 Output應該要越小越好。

但是這邊還有另外一個限制,它不是光叫你把大括號裡面的值變大就好,還有一個限制是D 不能夠是一個隨便的 Function,D必須要是一個 1-Lipschitz 的 Function,可能會問說1-Lipschitz 是什麼東西呢,如果你不知道是什麼的話也沒有關係,我們這邊你就想成D 必須要是一個足夠平滑的 Function,它不可以是變動很劇烈的 Function,它必須要是一個足夠平滑的 Function

那為什麼足夠平滑這件事情是非常重要的呢,我們可以從直觀來理解,它假設蓝色是真正的資料的分布,绿色是 Generated 的資料的分布,如果我們沒有這個限制,只看大括號裡面的值的話,大括號裡面的目標是要這些真正的值它的 Dx 越大越好,那要讓 Generated 的值它的 Dx 越小越好,如果你沒有做任何限制,只單純要這邊的值越大越好這邊的值越小越好,在藍色的點跟綠色的點也就是真正的 Image跟 Generated 的 Image沒有任何重疊的情況下,你的 Discriminator 會做什麼,它會給 Real 的 Image 無限大的正值,給 Generated 的 Image 無限大的負值,所以你這個 Training 根本就沒有辦法收斂,而且你會發現說只要這兩堆 Data 沒有重疊,你算出來的值都是無限大,你算出來的這個 Maximum 值都是無限大,這顯然不是我們要的這不就跟 JS Divergence 的問題一模一樣嗎,所以這邊你需要加上這個限制。
因為這個限制是要求 Discriminator不可以太變化劇烈,它必須要夠平滑,那今天如果你要求你的 Discriminator 夠平滑的時候,假設 Real Data 跟 Generated Data它們距離比較近,那你就沒有辦法讓 Real 的 Data 值非常大,然後 Generated 的值非常小。因為如果你讓 Real 的值非常大,Generated 的值非常小,它們中間的差距很大,那這一個 Discriminator 變化就很劇烈,它就不平滑了,它就不是 1-Lipschitz。
如果 Real 跟generated 的 Data 差距離很遠,那它們的值就可以差很多,這邊算出來的值就會比較大,你的 Wasserstein Distance 就比較大,如果 Real 跟 Generated 很近,就算它們沒有重合,因為有了這一個限制,你就發現說它們其實不會真的都跑到無限大,它們的距離因為有 1-Lipschitz Function 的限制所以 Real Data 的值跟 Generated Data 的值就沒有辦法差很多,那你算出來的 Wasserstein Distance就會比較小。
怎麼確保 Discriminator一定符合 1-Lipschitz Function 的限制呢

最早剛提出 WGAN 的時候其實沒有什麼好想法,只知道寫出了這個式子,那要怎麼真的解這個式子呢,有點困難,所以最早的一篇 WGAN 的 Paper,最早使用 Wasserstein 的那一篇 Paper,它說了它做了一個比較 Rough,比較粗糙的處理的方法,它是說我就 Train Network的時候如果我 Training 的那個參數,我就要求它放得在 C 跟 -C 之間,如果超過 C用 Gradient Descent Update 以後超過 C就設為 C,Gradient Descent Update 以後小於 -C就直接設為 -C,那其實這個方法並不一定真的能夠讓 Discriminator變成 1-Lipschitz Function。

所以接下來就有其它的想法,有一個想法叫做 Gradient Penalty。那今天其實你有一個方法,真的把 D 限制,讓它是 1-Lipschitz Function這個叫做 Spectral Normalization,那我就把它的論文放在這邊給大家參考,那如果你要 Train 真的非常好的 GAN你可能會需要用到 Spectral Normalizaion。也就是SNGAN。
生成器效能评估和条件式生成

雖然說已經有 WGAN,但其實並不代表說GAN 就一定特別好 Train,GAN 仍然是以很難把它 Train 起來而聞名的。 Generator 跟 Discriminator它們是互相砥礪才能互相成長的,只要其中一者發生什麼問題停止訓練,另外一個人就會跟著停下訓練就會跟著變差。

假設你在 Train Discriminator 的時候一下子沒有 Train 好,你的 Discriminator 沒有辦法分辨真的跟產生出來的圖片的差異,那 Generator它就失去了可以進步的目標,Generator 就沒有辦法再進步了,Discriminator 也會跟著停下來的。
大家已經 Train 過了很多次的 Network,你有辦法保證說你 Train 下去它的 Loss 就一定會下降嗎,不一定對不對。你要讓 Network Train 起來往往你需要調一下 Hyperparameter,才有可能把它 Train 起來,那今天這個 Discriminator 跟 Generator它們互動的過程是自動的,因為我們不會在中間每一次 Train Discriminator 的時候你都換 Hyperparameter,所以只能祈禱說每次 Train Discriminator 的時候它的Loss 都是有下降的,那如果有一次沒有下降,那整個 Training很有可能就會變就會慘掉。
你可以在網路上找到滿坑滿谷的GAN 的 Tips,那這些有沒有用呢,不好說 ,就是把一些相關的跟 Train GAN 的訣竅有關的文獻,還有連結列在這邊其實就給大家自己參考。

那 Train GAN 最難的其實是要拿 GAN 來生成文字,就如果你要拿 GAN 生成一段文字,這個會是最困難的,為什麼用 GAN 生成一段文字會是最困難的呢

這邊的難點在於你如果要用 Gradient Descent去 Train 你的 Decoder,去讓 Discriminator Output 分數越大越好,你會發現你做不到,為什麼你做不到呢,大家知道說在計算這個微分的時候,所謂的 Gradient所謂的微分其實就是某一個參數,它有變化的時候
對你的目標造成了多大的影響,我們現在來想想看假設我們改變了 Decoder 的參數,我們這個 Generator,也就是 Decoder 的參數,有一點小小的變化的時候,到底對 Discriminator 的輸出有什麼樣的影響,好 Decoder 的參數如果有一點小小的變化,那它現在輸出的這個 Distribution也會有小小的變化,那因為這個變化很小,所以它不會影響最大的那一個 Token 是什麼東西。
我知道說 Token可能對於各位同學來說你可能會覺得有點抽象,那如果你要想得更具體一點,Token 就是你現在在處理這個問題,處理產生這個 Sequence 的單位,那 Token 呢是人訂的了,所以假設我們今天在產生一個中文的句子的時候,我們是每次產生一個 Character,一個方塊字,那方塊字就是我們的 Token,那假設你在處理英文的時候,你每次產生一個英文的字母,那字母就是你的 Token,假設你一次是產生一個英文的詞,英文的詞和詞之間是以空白分開的,那就是詞就是你的 Token,好 所以 Token 的定義是你自己決定的,看你要拿什麼樣的東西當做你產生一個句子的單位。
好 那今天呢這個 Distribution 只有小小的變化,在取 Max 的時候,在找分數最大那個 Token 的時候,你會發現分數最大的那個 Token是沒有改變,你 Distribution 只有小小的變化,所以分數最大的那個 Token 是同一個,那對 Discriminator 來說它輸出的分數,它輸出是一模一樣的,這樣輸出的分數就沒有改變
所以你會發現說當 Decoder 的參數有一點變化的時候,Discriminator 輸出是沒有改變的,所以你根本就沒有辦法算微分,你根本就沒有辦法做 Gradient Descent。
有同學可能會說欸 這個 這邊不是因為 Max 造成不能做 Gradient Descent 嗎,那那個 CNN 裡面不是有那個 Max Pooling 嗎,那怎麼還可以做 Gradient Descent,這個問題就留給你自己深思一下,為什麼在這個地方有 Max 不能做 Gradient Descent,而在CNN有 Max Pooling卻可以做 Gradient Descent。

但是就算是不能做 Gradient Descent你也不用害怕,記不記得我們上週有講說遇到不能用 Gradient Descent Train 的問題就當做 Reinforcement Learning 的問題,硬做一下就結束了,所以你確實可以用 Reinforcement Learning來 Train 你的 Generator。

在你要產生一個 Sequence 的時候你可以用 Reinforcement Learning來 Train 你的 Generator,但這會發生什麼問題呢,Reinforcement Learning 是以難 Train 而聞名,GAN 也是以難 Train 而聞名,這樣的東西加在一起就大炸裂,這樣 Train 不起來非常非常地難訓練,所以要用 GAN 產生一段文字過去一直被認為是一個非常大的難題。
所以有很長一段時間沒有人可以成功地把 Generator 訓練起來,沒有人成功的可以訓練一個 Generator,用 GAN 的方式訓練一個 Generator 產生文字,通常你需要先做 Pretrain。

那 Pretrain 這件事情其實我們等一下馬上就會提到,如果你現在還不知道 Pretrain 是什麼的話也沒有關係,總之過去你沒有辦法用正常的方法讓 GAN 產生一段文字,直到有一篇 Paper 叫做 ScrachGAN,它的 Title 就開宗明義跟你炫耀說它可以 Train Language GANs Form Scrach,Form Scrach 就是不用 Pretrain 的意思, 所以它可以用它可以直接從隨機的初始化參數開始Train 它的 Generator,然後讓 Generator 可以產生文字。
那它怎麼做到的呢,最關鍵的就是爆調 Hyperparameter,跟一大堆的 Tips,那你可以想像這就是 Google 的 Paper,它爆收了參數以後,然後再加上了這邊就講了很多的 Tips,比如說呢這個橫軸是它們的 Major,這個叫做 FED那這個是用在文字上的,我們今天就不講這,不重要總之這個值越低越好,一開始要有一個叫做 SeqGAN-Step 的技術,沒這個完全 Train 不起來,然後接下來有一個很大的 Batch Size,多大呢通常就是上千,你自己在家沒辦法這麼做的,Discriminator 加 Regularization Embedding 要 Pretrain改一下 Reinforcement Learning 的 Argument,最後就有 ScratchGAN就可以從真的把 GAN Train起來,然後讓它來產生 Sequence,好 那今天有關 GAN 的部分我們只是講了一個大概,那如果你想要學最完整的內容,我在這邊留下一個連結給大家參考

那其實有關 Generative 的 Model不是只有 GAN 而已,還有其他的,比如說 VAE,比如說 FLOW-Based Model,那我在這邊也列了兩個影片的連結給大家參考

也許有同學會想說為什麼我們要特別用一些提出一些新的做法來做 Generative 這件事,如果我們今天的目標就是輸入一個 Gaussian 的 Random 的 Variable,輸入一個 從 Gaussian 的這個 Random Variable Sample 出來的 Vector,把它變成一張圖片,那我們能不能夠用Supervised Learning 的方法來做呢

也就說我有一堆圖片,我把這些圖片拿出來,每一個圖片都去配一個 Vector,都去配一個從 Gaussian Distribution Sample 出來的 Vector,那接下來呢接下來就當做 Supervised Learning 的方法硬做就結束了,這樣子大家懂嗎
就是 Train 一個 Network,輸入一個 Vector,輸出就是它對應的圖片,把對應的圖片當做你訓練的目標訓練下去就結束了,能不能這麼做呢,能這麼做,真的有這樣子的生成式的模型
那難的點是說,如果這邊(图片对应的vector)純粹放隨機的向量Train 起來結果會很差,你可能根本連 Train 都 Train 不起來,所以怎麼辦你需要有一些特殊的方法。具体可以看上面图片下方的论文。
那接下來我們要講的就是 GAN 的評量。

完全用人來看顯然有很多的問題,比如說不客觀不穩定等等諸多的問題,所以有沒有比較客觀而且自動的方法來想辦法量一個 Generator 的好壞呢。如果針對特定的一些任務是有辦法設計一些方法的,舉例來說在作業 6 裡面我們就是要叫大家生成二次元人物的頭像,那在作業裡面一個評估的標準就是我們跑一個動畫人物人臉偵測的系統,然後看說你提供的那些圖片裡面抓到幾個動畫人物的人臉,那如果你提供 1000 張圖片裡面抓到 900 個人臉跟提供 1000 張圖片抓到 300 個人臉,那顯然 900 個人臉的那一個 Generator它做出來的結果是比較好的。但是這是針對作業 6 的設計,那如果是更一般的 Case 呢

那有一個方法呢是一樣跑一個影像的分類系統,把你的 GAN 產生出來的圖片丟到一個的影像的分類系統裡面,看它產生什麼樣的結果,影像分類系統輸入是一張圖片我們這邊叫做 y,輸出呢是一個機率分布,我們這邊叫它 P ( c│y ),P ( c│y ) 是一個機率的分布,然後接下來我們就看說這個機率的分布,如果越集中,就代表說現在產生的圖片可能越好,雖然我們不知道這邊產生的圖片裡面有什麼東西,不知道它是貓還是狗還是斑馬,我們不知道它是什麼,但是如果丟到了一個影像分類系統以後,它輸出來的結果它輸出來的這個分布非常集中,代表影像分類系統它非常肯定它現在看到什麼樣的東西,它非常肯定它看到了狗,它非常肯定它看到了斑馬,然後代表說你產生出來的圖片也許是比較接近真實的圖片,所以影像辨識系統才辨識得出來,如果你產生出來的圖片是一個四不像,根本看不出是什麼動物,那影像辨識系統就會非常地困惑,它產生出來的這個機率分布就會非常地平坦非常地平均分布,那如果是平均分布的話那就代表說你的 GAN產生出來的圖片可能是比較奇怪的,所以影像辨識系統才會辨識不出來。
這是一個可能的做法,但是光用這個做法是不夠的,光用這個做法會有什麼問題呢,這個 Evaluation 的方法評估的方法會被一個叫做 Mode Collapse 的問題騙過去,什麼叫 Mode Collapse 呢

Mode Collapse 是說你在 Train GAN 的時候,你有時候 Train 著 Train 著就會遇到一個狀況,是假設這些藍色的星星是真正的資料的分布,紅色的星星是你的 GAN你的 Generative 的 Model它的分布,你會發現說 Generative Model它輸出來的圖片來來去去就是那幾張,可能單一張拿出來你覺得好像還做得不錯,但讓它多產生幾張就露出馬腳,原來產生出來就只有那幾張圖片而已,那下图右边是一個 Mode Collapse 的例子啦,讓它產生二次元的人物,那 Train 著 Train 著 Train 到最後,我就發現變成這樣的一個狀況,這一張臉(红框中的)越來越多越來越多,而且它還有不同的髮色,這個髮色比較偏紅,這個髮色比較偏黃,越來越多最後就通通都是這張臉,那這就是一種 Mode Collapse 的現象

那為什麼會有 Mode Collapse這種現象發生呢,就直覺上你還是比較容易理解,你可以想成說這個地方就是 Discriminator 的一個盲點,當 Generator 學會產生這種圖片以後,它就永遠都可以騙過 Discriminator,Discriminator 沒辦法看出說這樣子的圖片是假的,那這是一個 Discriminator 的盲點,Generator 抓到這個盲點就硬打一發就發生 Mode Collapse 的狀況。
那可是到底要怎麼避免Mode Collapse 的狀況呢,我認為今天其實還沒有一個非常好的解答。
BGAN 那邊 Paper 怎麼解決這個問題呢,其實很簡單,Model 在 Generator 在訓練的時候一路上都會把那個 Train Point 存下來,在 Mode Collapse 之前把 Training 停下來,就 Train 到 Mode Collapse,然後就把之前的 Model 拿出來用就結束了這樣。
不過 Mode Collapse 這種問題你至少你知道有這個問題,你可以看得出有這個問題,你的 Generator 總是產生這張臉的時候,你不會說你的 Generator是個好的 Generator,你知道說發生了一些狀況,你的 Generator 不是特別地好,但是有另外一種跟 Mode Collapse 還是有點像但是更難被偵測到的問題叫做 Mode Dropping。

Mode Dropping 的意思是說你的真實的資料分布可能是這個樣子(上图蓝色星星),但是你的產生出來的資料只有真實資料的一部分,單純看產生出來的資料你可能會覺得還不錯,而且分布它的這個多樣性也夠,但你不知道說真實的資料它的多樣性的分布其實是更大的。
一個真實的例子,有個同學他 Train 了這個人臉生成的 GAN,那它在某一個 Iteration 的時候它的 Generator 產生出這些人臉,你會覺得說沒有問題,而且人臉的多樣性也夠,有男有女,有向左看有向右看,各式各樣的人臉都有,好 這個是第 T 個 Iteration 的時候 Generator你也不覺得它的多樣性有問題。但如果你再看下一個 Iteration Generator 產生出來的圖片是這樣子的

你有沒有發現問題,它的膚色有問題啊,所以它之前你看有男有女沒有問題,但是它膚色偏白啊,這邊膚色偏黃啊,你沒弄好人家都覺得你的 Generator 有種族歧視,所以在這種 Mode Dropping 的問題是不太容易被偵測出來的。
所以今天也許 Mode Dropping 的問題都還沒有獲得本質上的解決,但是我們會需要去量說現在我們的 Generator它產生出來的圖片到底多樣性夠不夠,所以怎麼做呢,過去有一個做法一樣是藉助我們的 Image Classify,你就把一堆圖片,你的 Generator 產生 1000 張圖片把這 1000 張圖片裡都丟到 Image Classify 裡面,看它被判斷成哪一個 Class

每張圖片都會給我們一個 Distribution,你把所有的 Distribution 平均起來,接下來看看平均的 Distribution 長什麼樣子,如果平均的 Distribution 非常集中,就代表現在多樣性不夠,如果什麼圖片丟進去你的影像分類系統都說是看到 Class 2,,那代表說每一張圖片也許都蠻像的,你的多樣性是不夠的。

那如果另外一個 Case,不同張圖片丟進去,不同張你的 Generator 產生出來的圖片丟到 Image Classifier 的時候,它產生出來的輸出的分布都非常地不同,你平均完以後發現平均完後的結果是非常平坦的,那這個時候代表什麼這個時候代表說也許你的多樣性是足夠的。
那你會發現說在評估的標準上,當我們用這個 Image 的 Classifier來做評估的時候,Diversity 跟 Quality 好像是有點互斥的,因為我們剛才在講 Quality 的時候,我們說越集中代表 Quality 越高,但是 Diversity 是越平坦, 分布越平均代表 Diversity 越大。
不過我要強調一下這個 Quality 跟 Diversity它們評估的範圍不一樣,Quality 是只看一張圖片,一張圖片丟到 Classifier 的時候分布有沒有非常地集中,而 Diversity 看的是一堆圖片,它分布的平均,一堆圖片你的 Image Classifier 輸出的平均,如果輸出的平均越平均那就代表說現在的 Diversity 越大。
那過去有一個非常常被使用的分數叫做 Inception Score,那它的縮寫呢 是 IS,那這個 Inception Score 呢是怎麼訂出來的呢你就量一下用 Inception Network 量一下 Quality,如果 Quality 高那個 Diversity 又大,那 Inception Score 就會比較大。
不過在作業裡面我們並不會用 Inception Score,為什麼我們不用 Inception Score 呢,你想想看假設把你產生出來的二次元人物丟到 Inception Net 裡面,它的輸出可能就是都看到人臉嘛,你可能 Diversity 很大,產生不同的髮色,產生不同眼睛顏色的人物,但是對 Inception Network 來說它都是人臉啊,所以你可能算出來 Diversity 其實是小的。
所以 Inception Score 在我們這個作業中可能是不適用的那在我們的作業中會採取另外一個 Evaluation 的 Measure叫 Fréchet 的 Inception Distance

這個東西是什麼呢,它的縮寫叫做 FID,你先把你產生出來的二次元的人物啊丟到 Inception Net 裡面,那如果你把這個二次元人物一路丟丟丟丟,到最後讓那個 Inception Network 輸出它的類別,那你得到的可能就是人臉,那每一張二次元的人物看起來都是人臉,那我們不要拿那個類別,我們拿進入 Softmax 之前的 Hidden Layer 的輸出,進入 Softmax 之前你的 Network 不是會產生一個向量嗎,那可能是上千維長度,是上千維的一個向量,把那個向量拿出來代表這張圖,片那如果我們拿出來的是一個向量而不是最後的類別,那雖然最後分類的類別可能是一樣的,但是在決定最後的類別之前,這個向量就算都是人臉可能還是不一樣的,可能會隨著膚色 髮型這個向量還是會有所改變的,所以我們就不取最後的類別,只取這個 Inception Network 最後一層的這個 Hidden Layer 的輸出來代表一張圖片。

那在這個投影片上啊,所有紅色的點代表你把真正的圖片丟到 Inception Network 以後拿出來的向量,那這個向量其實非常高維度,是上千維的,那我們就把它假設我們可以把它畫在二維的平面上, 那這個藍色的點呢,藍色的點是你自己的 GAN你自己的 Generator產生出來的圖片,它丟到 Inception Network 以後進入 Softmax 之前的向量,把它畫出來假設是長這個樣子,接下來呢你就假設這兩組資料,假設真實的圖片跟產生出來的圖片它們都是 Gaussians 的 Distribution,然後去計算這兩個 Gaussians Distribution 之間的Fréchet 的 Distance就結束了,那至於 Fréchet 的 Distance 是什麼,你有興趣再自己看一下文獻。它是一個 Distance,所以這個值就是越小越好嘛,距離就是越小越好,距離越小代表這兩組圖片越接近,那當然就是產生出來的品質越高。

但這邊你一定心裡還是有很多問號,第一個問號就是當做 Gaussians Distribution 沒問題嗎,這個應該不是 Gaussians Distribution吧,嗯 會有問題 ,就這樣子然後另外一個問題就是如果你要準確的得到你的 Network 它的分布那你可能需要產生大量的 Sample 才能做到,那這需要一點運算量,那這個也是要做 FID 不可避免的問題,所以其實我們在作業裡面我們不會只看 FID,只看 FID其實結果會怪怪的,因為你你假設你的這個輸出的分布一定是 Gaussians 嘛,那它實際上不是 Gaussians,硬假設它是 Gaussians,沒有怪怪的嗎,會怪怪的,所以我們是同時看 FID跟動畫人物人臉的這個偵測出來的人臉的數目這兩個指標,我會同時看這兩個指標,那這樣可以得到比較合理而精確的結果。

那 FID 算是今天比較常用的一種 Measure,那有一篇 Paper 叫做Are GANs Created EqualA Large Scale Study,那你可以想見說這個也是 Google 做的啦,那就是爆做了各式各樣不同的 GAN,它就列舉了好多不同的各式各樣的 GAN,那每一個 GAN當然它的這個訓練的這個 Objective訓練的那個 Loss 有點不太一樣,我這邊就不細講各式各樣的 GAN,每一種 GAN它都用不同的 Random Seed去跑過很多次以後看看結果怎麼樣,那以上面這個圖呢就是在四個不同的資料庫上面得到的結果,那橫軸這邊代表的是不同的 GAN那這邊的值就是FID,是越小越好。
那你會發現說這邊每一個方法呢它都不是只得到一個數值,它都得到一個分布,為什麼它得到是一個分布呢,因為你要用那個不同的 Random Seed 去跑啊,用不同 Random Seed 去跑每次跑出來的結果都不太一樣
那其實剛才那些 Measure 也完全也並沒有完全解決 GAN 的Evaluation 問題,還有什麼 Evaluation 的問題呢,你想想看以下的狀況

假設這是你的真實資料,你不知道怎麼回事訓練了一個 Generator,它產生出來的 Data跟你的真實資料一模一樣,所以如果你不知道真實資料長什麼樣子,你光看這個 Generator 的輸出,你會覺得太棒了它做得很棒,那 FID 算出來一定是非常小的,但問題是這個是你要的嗎,如果它產生出來的圖片都跟資料庫裡面的訓練資料的一模一樣,訓練資料就在你手上,直接從訓練資料裡面Sample 一些 Image 出來不是更好,幹嘛要 Train Generator,我們 Train Generator 其實是希望它產生新的圖片,資料集裡面,訓練資料裡面沒有的人臉啊。
那像這種問題就不是我們作業的 Measure 可以偵測的,但是它是一個問題,那怎麼解呢,你可能會說那我們就把我們 Generator 產生出來的圖片跟真實資料比個相似度吧,看看是不是一樣嘛,如果很多張都一樣,就代表說Generator 只是把那個訓練資料背起來而已它沒有很厲害。
但是那如果我問另外一個問題,假設你的 Generator 學到的是把所有訓練資料裡面的圖片都左右反轉呢

那它也是什麼事都沒有做啊,假設它學到就是把訓練資料裡面所有的圖片都左右翻轉,它實際上也是什麼事都沒有做,但問題是你比相似度的時候又比不出來。
所以 GAN 的 Evaluation是非常地困難的,甚至 光要如何評估一個 Generator 做得好不好這件事情都是一個可以研究的題目,如果你真的很有興趣的話,這邊放了一篇相關的文章啦,裡面就列舉了二十幾種GAN Generator 的評估的方式

那接下來呢我們要講 Conditional 的 Generation,那什麼是 Conditional 的 Generation 呢,到目前為止我們講的 Generator它輸入都是一個隨機的分布而已,那這個不見得非常有用。我們現在想要更進一步的是我們可以操控 Generator 的輸出,我們給它一個 Condition x讓它根據 x 跟 z 來產生 y,那這樣的 Conditional Generation有什麼樣的應用呢

比如說你可以做文字對圖片的生成,它其實是一個 Supervised Learning 的問題,你需要一些 Label 的 Data,你需要去蒐集一些圖片,蒐集一些人臉,然後這些人臉都要有文字的描述,

告訴我們說這個是紅眼睛這個是黑頭髮這個是黃頭髮這個是有黑眼圈等等,告訴我們這樣子,我們要這樣的 Label 的資料才能夠訓練這種 Conditional 的 Generation。

所以在 Text To Image 這樣的任務裡面,我們的 x 就是一段文字,那你可能問說一段文字怎麼輸入給 Generator 呢,那就要問你自己了,你要怎麼做都可以,以前會用 RNN 把它讀過去然後得到一個向量再丟到 Generator,今天也許你可以把它丟到一個Transformer 的 Encoder 裡面去,把 Encoder Output 這些向量通通平均起來丟到 Generator 裡面去,怎麼樣都可以 反正你用什麼方法都可以

那你期待說你輸入 Red Eyes,然後呢機器就可以畫一個紅眼睛的角色,但每次畫出來的角色都不一樣,那這個畫出來什麼樣的角色取決於什麼呢,取決於你 Sample 到什麼樣的 z ,Sample 到不一樣的 z畫出來的角色就不同,但是通通都是紅眼睛的,這個就是 Text To Image 想要做的事情。

那要怎麼做 Conditional 的 GAN 呢

我們現在的 Generator 有兩個輸入,一個是從 Normal Distribution Sample 出來的 z,另外一個是 x,也就是一段文字,那我們的 Generator 會產生一張圖片 y,那我們需要一個 Discriminator,那如果按照我們過去所學過的東西,Discriminator它就是吃一張圖片 y 當作輸入,輸出一個數值,這個數值代表輸入的圖片多像真實的圖片。但這樣的方法 沒辦法真的解 Conditional GAN 的問題

因為如果我們只有 Train 這個 Discriminator,這個 Discriminator 只會看 y 當做輸入的話,那 Generator 會學到的是它會產生可以騙過 Discriminator 的非常清晰的圖片,它會產生清晰的圖片,但是跟輸入完全沒有任何關係,因為對 Generator 來說,它只要產生清晰的圖片就可以騙過 Discriminator 了,它何必要去管 Input 文字敘述是什麼呢。你的 Discriminator 又不看文字的敘述,所以它根本就不需要文字的敘述,你不管輸入什麼文字,就無視這個 x,反正就是產生一個圖片可以騙過 Discriminator 就結束了。
所以在 Conditional GAN 裡面你要做有點不一樣的設計,你的 Discriminator 不是只吃圖片 y,它還要吃 Condition x

所以你的 Discriminator它有 y 作為輸入,有 x 作為輸入,然後產生一個數值,那這個數值不只是看 y 好不好,光圖片好沒有用,光圖片好,Discriminator 還是不會給高分,什麼樣的情況下 Discriminator 才會給高分呢,一方面圖片要好,另外一方面圖片跟 x,就是文字的敘述它們必須要配得上,這個圖片跟文字的敘述必須要是相配的,Discriminator 才會給高分。
那怎麼樣訓練這樣的 Discriminator 呢,那你需要文字跟影像成對的資料

所以 Conditional GAN一般的訓練是需要這個 Pair 的 Data ,是需要有標註的資料的,有這些成對資料那你就告訴你的 Discriminator 說看到這些真正的成對的資料就給它一分,看到 Red Eyes但是搭配其他乱七八糟的就是0分

然後訓練下去就可以產生,就可以做到 Conditional GAN。那其實在實作上啊光是這樣子,拿這樣子的 Positive Sample還有 Negative Sample來訓練這樣的 Discriminator,其實你得到的結果往往不夠好。你還需要加上一種不好的狀況是已經產生好的圖片但是文字敘述配不上的狀況。

所以你通常會把你的訓練資料拿出來,然後故意把文字跟圖片亂配,故意配一些錯的,然後告訴你的 Discriminator 說看到這種狀況你也要說是不好的,用這樣子的資料你才有辦法把 Discriminator 訓練好,然後 Generator 跟 Discriminator反覆的訓練你最後才會得到好的結果。
那 Conditional GAN 的應用不只看一段文字產生圖片啦,也可以看一張圖片產生圖片

那看一張圖片產生圖片也有很多的應用,比如說給它房屋的設計圖,然後讓你的 Generator 直接把房屋產生出來,給它黑白的圖片然後讓它把顏色著上,給它這個素描的圖讓它把它變成實景 實物,那給它這個白天的圖片讓它變成晚上的圖片,有時候你會給它比如說起霧的圖片讓它變成沒有霧的圖片,把霧去掉。
所以 Conditional GAN除了輸入文字 產生影像以外,也可以輸入影像 產生影像,那像這樣子的應用啊叫做 Image 的 Translation,那有人又叫做 Pix2pix,這個 Pix 就是 Pixel就是像素的縮寫啦,所以叫做 Pix2pix。
那怎麼做呢跟,剛才講的從文字產生影像沒有什麼不同,現在只是從影像產生影像,把文字的部分用影像取代掉而已,那當然同樣的做法同樣要產生這樣的 Generator

你當然可以用 Supervised Learning的方法,那在文獻上你會發現說如果你用 Supervised Learning 的方法,你得不到非常好的結果,那你會發現說它非常地模糊。
為什麼它非常地模糊呢,你可以直覺想成說,因為同樣的輸入可能對應到不一樣的輸出,就好像我們在講 GAN 剛開始的開場的時候講的那個例子,今天在同一個轉角那個小精靈可能左轉也可能右轉,最後學到的就是同時左轉跟右轉,那對於 Image To Image 的 Case也是一樣的,輸入一張圖片輸出有不同的可能,機器學到的Generator 學到的就是把不同的可能平均起來結果變成一個模糊的結果。

所以這個時候我們需要用 GAN 來 Train,你需要加一個 Discriminator,Discriminator 它是輸入一張圖片還有輸入 Condition,然後它會同時看這個圖片跟這個 Condition有沒有匹配來決定它的輸出。
那你會發現說如果單純用 GAN 的話它有一個小問題,它產生出來的圖片呢比較真實,但是它的問題是它的創造力呢想像力過度豐富,它會產生一些輸入沒有的東西,舉例來說這是一個房子左上角明明沒有其他東西,這邊它卻在屋頂上加了一個不知道是煙囪還是窗戶的東西,那文獻上如果你要做到最好啊往往就是 GAN 跟 Supervised Learning同時使用啦。
那所謂同時使用的意思就是,Generator 在訓練的時候,一方面它要去騙過 Discriminator,這是它的一個目標,但同時它又想要產生一張圖片跟標準答案越像越好,它同時去做這兩件事,那往往產生出來的結果是最好的。
那 Conditional GAN 還有很多應用啦,這邊給大家看一個莫名其妙的應用

就是給 GAN 呢聽一段聲音,然後呢它產生一個對應的圖片,什麼意思呢,比如說給它聽一段狗叫聲,看它能不能夠畫出一隻狗, 那我剛才講說 Conditional GAN 需要這個Label 的資料,需要成對的資料,那這個聲音跟影像成對的資料其實並沒有那麼難蒐集,因為你可以爬到大量的影片,那影片裡面有影像 有畫面也有聲音訊號,那你就知道說這一幀的圖片對應到這一小段聲音,把這些資料蒐集起來你就可以 Train 一個 Conditional GAN,聽一段聲音讓它想像它聽到的場景是什麼樣子的。

那這個是我們實驗室有個同學做的,然後這個是一個真正的 Demo。這個會不會機器並沒有真的學到聲音跟圖片之間的關係,會不會它只是把它在訓練資料裡面有看過的圖片存起來而已,所以我決定把聲音調大,你聽看看結果會怎樣,所以我們把聲音調大,你就發現說這個溪流裡面的水花就越來越多,從一條小溪變成尼加拉瓜瀑布。
不過我要承認這個其實是稍微 Cherry Pick 的結果,就稍微挑過的結果,很多時候覺得 Generator 產生出來的東西就是這個樣子啦,

不知所云,這樣這就給它一個鋼琴聲然後它好像想畫一個鋼琴但又沒有很清楚,這個是給它聽狗叫聲啦好像想畫一個動物但又不知道要畫些什麼。
那我看到最近最驚人的Conditional GAN 的應用啊,是有人用 Conditional GAN 產生會動的圖片。給它一張圖片,比如說蒙娜麗莎的畫像,然後就可以讓蒙娜麗莎開始講話,這個是 Conditional GAN 的其中一個應用

Cycle GAN
好那有關GAN的最後一段,我們要講一個GAN的神奇應用, ,這個是把GAN用在這個unsupervised Learning上
我們講的幾乎都是Supervised Learning,我們要訓練一個Network,Network的輸入叫做X,輸出叫做Y,我們需要成對的資料才有辦法訓練這樣子的Network,但是你可能會遇到一個狀況是我們有一堆X我們有一堆Y,但X跟Y是不成對的,

在這種狀況下我們有沒有辦法拿這樣的資料來訓練Network呢。像這種沒有成對的資料,我們就叫做unlabeled的資料,至於怎麼使用這些沒有標註的資料呢

其實在作業三跟作業五裡面都提供給你兩個例子,我們就把這個怎麼用沒有標註的資料怎麼做Semi-supervised Learning這件事情放在作業裡面,如果你有興致的話就可以來體驗一下semi-supervised Learning到底可以帶多大的幫助,但是不管是作業三的pseudo labeling還是作業五的back translation這些方法或多或少都還是需要一些成對的資料,在作業三裡面你得先訓練出一個模型這個模型可以幫你提供pseudo label,如果你一開始根本就沒有太多有標註的資料你的模型很差你根本就沒有辦法產生比較好的pseudo label,或是back translation你也得有一個back translation 的model你才辦法做back translation,所以不管是作業三還是作業五的方法還是都需要一些成對的資料,但是假設我們遇到一個更艱鉅的狀況是我們一點成對的資料都沒有,那要什麼怎麼辦呢
什麼時候會完全沒有成對的資料呢,我們這邊舉一個例子,舉例來說, 影像風格轉換,假設今天我要訓練一個Deep Network,它要做的事情是把X domain的圖(我們假設是真人的照片),Y domain的圖是二次元人物的頭像,真人的頭像轉成二次元人物的頭像,這個叫做影像風格轉換

真人的頭像是X domain二次元頭像是Y domain,把X domain的東西轉成Y domain的東西,這個是影像風格轉換,在這個例子裡面我們可能就沒有任何的成對的資料 對不對,如果你想要成對的資料,那你得先,比如說這是新垣結衣,幫新垣結衣拍一個照片,然後在把新垣結衣二次元的版本畫出來,你才有辦法訓練Network,這個顯然實在是太昂貴了
在這種狀況下還有沒有辦法訓練一個Network,輸入一個X產生一個Y呢,這個就是GAN可以幫我們做的事情,那接下來我們就是看看怎麼用GAN在這種完全沒有成對資料的情況下進行學習,

這個是我們之前在講unconditional的generation的時候,你看到的generator的架構,輸入是一個Gaussian的分佈,輸出可能是一個複雜的分佈

現在我們在稍微轉換一下我們的想法,輸入我們不說它是Gaussian的分佈,我們說它是X domain的圖片的分佈,那輸出我們說是Y domain圖片的分佈,我們有沒有可能訓練這樣的generator

輸入是X domain圖片的分佈,輸出是Y domain圖片的分佈呢,如果可以做到的話其實就結束了

乍聽之下好像沒有很難,你完全可以套用原來的GAN的想法,在原來的GAN裡面,我們說我們從Gaussian sample一個向量丟到Generator裡面,那我們一開始也說其實不一定要從Gaussian sample,只要那一個distribution是有辦法被sample的就行了,我們選Gaussian只是因為Gaussian的formulation我們知道,我們可以從Gaussian sample,那我們現在如果輸入是X domain的distribution,我們只要改成可以從X domain sample就結束了,那你有沒有辦法從X domain sample呢,可以, 你就從人臉的照片裡面真實的人臉裡面隨便挑一張出來然後就結束了。
讓它產生另外一張圖片,產生另外一個distribution,裡面的圖片怎麼讓它變成是Y domain的distribution呢,那就要一個discriminator
,那這個discriminator給它看過很多Y軸 domain的圖,所以它能夠分辨Y domain的圖跟不是Y domain的圖的差異,看到Y domain的圖就給它高分,看到不是Y domain的圖,不是二次元人物就給它低分,那就這樣結束了。
你說這個跟原來的GAN的訓練有什麼不同,沒什麼不同 ,如果你想要自己在那個作業裡面做一下的話,就記得說本來在作業裡面Gaussian generator的input裡的sample是從Gaussian distribution sample出來,現在記得換一個sample的方法,從真人的人臉裡面sample一張圖片出來這樣就結束了。
但是你再仔細想想看,光是套用原來的GAN訓練generator跟discriminator好像是不夠的 ,因為我們現在的discriminator
它要做的事情是要讓這個generator輸出一張Y domain的圖,那generator它可能真的可以學到輸出Y domain的圖,但是它輸出的Y domain的圖一定要跟輸入有關係嗎,

你沒有任何的限制要求,你的generator做這件事,你的generator也許就把這張圖片當作一個Gaussian的noise,然後反正它就是看到不管你輸入什麼它都無視它,反正它就輸出一個像是二次元人物的圖片,discriminator覺得它做得很好
那怎麼辦呢 怎麼解決這個問題,怎麼強化輸入與輸出的關係呢。這個generator完全無視輸入這件事,你會發現說我們在conditional GAN的時候是不是也看過一模一樣的問題呢,在講conditional GAN的時候我有特別提到說假設你的discriminator只看Y那它可能會無視generator的輸入,那產生出來的結果不是我們要的。
但是這邊啊,如果我們要從unpaired的data學習,我們也沒有辦法直接套用conditional GAN的想法,因為在剛才講的conditional GAN裡面我們是有成對的資料,我們可以用這些成對的資料來訓練的discriminator,但今天現在我們沒有成對的資料,我們根本沒有辦法拿出成對的資料來告訴discriminator說怎麼樣的X跟Y的組合才是對的

我們沒有這種資料 怎麼辦呢,那邊就用了一個這邊這個想法叫做Cycle GAN,在Cycle GAN裡面我們會train兩個generator,第一個generator它的工作是把X domain的圖變成Y domain的圖,第二個generator它的工作是看到一張Y domain的圖把它還原回X domain的圖,在訓練的時候我們今天增加了一個額外的目標,就是我們希望輸入一張圖片從X domain轉成Y domain以後要從Y domain轉回原來一模一樣的X domain的圖,經過兩次轉換以後輸入跟輸出要越接近越好。
你說怎麼讓兩張圖片越接近越好呢,這個很簡單,一個圖片其實就是一個向量對不對,兩張圖片就是這兩個向量之間的距離,你就是讓這兩個向量它們之間的距離越接近越好。
因為這邊有一個循環,從X到Y 在從Y回到X它是一個cycle,所以叫做Cycle GAN

那加入了這個橙色的從Y到X的generator以後會有什麼樣不一樣的地方呢,對於前面這個藍色的generator來說,它就再也不能夠隨便亂做了,它就不能夠隨便產生亂七八糟跟輸入沒有關係的人臉了,這邊假設輸入一個人脸,這邊假設輸出的是輝夜,然後對第二個generator來說它就是視這張輝夜作為輸入,它根本無法想像說要把輝夜還原回输入的人脸。
對第一個generator來說為了要讓第二個generator能夠成功的還原原來的圖片,它產生出來的圖片就不能跟輸入差太多

所以如果你加Cycle GAN,你至少可以強迫你的generator它輸出的Y domain的圖片至少跟輸入的X domain的圖片有一些關係,但講到這邊你可能會有的一個問題,就是你這邊只保證有一些關係啊,你怎麼知道這個關係是我們要的呢。
機器有沒有可能學到很奇怪的轉換,輸入一個戴眼鏡的人然後這個generator學到的是看到眼鏡就把眼鏡抹掉然後把它變成一顆痣,然後第二個generator橙色的學到的就是看到痣就還原回眼鏡,這樣還是可以滿足cycle consistency,還是可以把輸入的圖片變成輸出的圖片。我舉一個更極端的例子假設第一個generator學到的就是把圖片反轉, 左右翻轉,第二個generator它也只要學到把圖片左右翻轉,你就可以還原了,所以今天如果我們做Cycle GAN用cycle consistency似乎沒有辦法保證我們輸入跟輸出的人臉看起來真的很像,因為也許機器會學到很奇怪的轉換,反正只要第二個generator可以轉得回來就好了,那會不會有這樣的問題發生呢。
確實有可能有這樣的問題發生,那有什麼要特別好的解法呢,目前沒有什麼特別好的解法,但我可以告訴你說實際上你要使用Cycle GAN的時候,這樣子的狀況沒有那麼容易出現,如果你實際上使用Cycle GAN你會發現輸入跟輸出往往真的就會看起來非常像,而且甚至在實作上在實作的經驗上你就算沒有第二個generator,你不用cycle GAN,拿一般的GAN來做這種圖片風格轉換的任務,你往往也做得起來,因為在實作上你會發現Network其實非常懶惰,它輸入一個圖片它往往就想輸出by default,就是想輸出很像的東西,它不太想把輸入的圖片做太複雜的轉換,像是什麼眼鏡變成一顆痣這種狀況,它不愛這麼麻煩的東西,有眼鏡就輸出眼鏡可能對它來說是比較容易的抉擇。
所以在真的實作上這個問題沒有很大,輸入跟輸出會是像,但是理論上好像沒有什麼保證說輸入跟輸出的圖片一定要很像,就算你加了cycle consistency,所以這個是實作與理論上你可能會遇到的差異,總之雖然Cycle GAN沒有保證說輸入跟輸出一定很像,但實際上你會發現輸入跟輸出往往非常像,你只是改變了風格而已。

那這個Cycle GAN可以是雙向的,什麼意思呢,我們剛才有一個generator,我們是先把X domain的圖片轉成Y在把Y轉回X,在訓練cycle GAN的時候,你可以同時做另外一個方向的訓練,也就是你把這個橙色的generator拿來,給它Y domain的圖片讓它產生X domain的圖片,然後在把藍色的generator拿來,把X domain的圖片還原回原來Y domain的圖片,那你依然要讓輸入跟輸出越接近越好。那你一樣要訓練一個discriminator,這個discriminator是X domain的discriminator,它是要看一張圖片像不像是真實人臉的,discriminator要去看說這一個橙色的generator的輸出像不像是真實的人臉,這個橙色的generator它要去騙過這個Dx(這個綠色的左邊這一個discriminator),這個合起來就是Cycle GAN。
那除了Cycle GAN以外你可能也聽過很多其他的可以做風格轉換的GAN

比如說Disco GAN ,比如說Dual GAN,他們跟Cycle GAN有什麼不同呢,就是沒有半毛錢的不同,你可以發現Disco GAN Dual GAN跟Cycle GAN其實是一樣的東西,他們是一樣的想法,神奇的事情是完全不同的團隊在幾乎一樣的時間提出了幾乎一模一樣的想法。
除了Cycle GAN以外還有另外一個更進階的,可以做影像風格轉換的版本叫做StarGAN

Cycle GAN只能在兩種風格間做轉換,那StarGAN 它厲害的地方是它可以在多種風格間做轉換,不過這個就不是我們接下來
想要細講的重點。

這個真實的人臉轉二次元的任務實際上能不能做呢,實際上可以做,右上角這邊放了一個連結,這個應該是一個韓國團隊他們做了一個網站,你可以上傳一張圖片它可以幫你變成二次元的人物,他們實際上用的不是Cycle GAN啦,他們用的也是GAN的技術,但是是一個進階版的東西。
那同樣的技術不是只能用在影像上,也可以用在文字上,你也可以做文字風格的轉換,比如說把一句負面的句子轉成正面的句子。當然如果你要做一個模型,輸入一個句子輸出一个句子,這個模型就是要能夠吃一個sequence 輸出一個sequence,所以它等於是一個sequence to sequence的model,你可能就會用到Transformer的架構來做這個文字風格轉換的問題。

怎麼做文字的風格轉換呢,跟Cycle GAN是一模一樣的,首先你要有訓練資料,收集一大堆負面的句子收集一大堆正面的句子。
假設你要把負面的句子轉成正面的句子,它的風格轉換問題就是把負面的句子轉成正面的句子,收集一堆負面的句子收集一堆正面的句子,這個其實沒有那麼難收集,你可以就是網路上爬一爬,然後只要是推文就當作是正面的,噓文就當作是負面的,

就有一大堆正面的句子跟負面的句子,只是成對的資料沒有而已,你不知道這句推文要怎麼轉成這句噓文,這些噓文要怎麼轉成這句推文,你沒有這種資料,但是一堆推文一堆噓文的資料你總是可以找得到的,那接下來呢完全套用Cycle GAN的方法
這個sequence to sequence model輸出是文字,可是剛才不是有講說如果輸出是文字接到discriminator會有問題嗎,對 會有問題, 這邊你就要用RL硬做,那做出來的結果怎麼樣呢,這個是真正的demo啦

但是因為這個訓練是完全unsupervised,就是給它正面的句子跟負面的句子,在有時候會犯非常奇怪的錯誤,比如說我跟它說 我肚子痛得厲害,它就說 我生日快樂厲害 ,這樣那你會發現說 機器雖然犯錯但是錯的是有固定的規則的,你發現胃疼跟肚子痛只要是腹部有毛病它轉過來都是生日快樂,不知道為什麼機器覺得說腹部有毛病的相反就是生日快樂。
還有很多其他的應用,不是只有正面句子轉負面句子

舉例來說 假設我有很多長的文章,我有另外一堆摘要,這些摘要不是這些長的文章的摘要,是不同的來源,一堆長的文章 一堆摘要讓機器學習文字風格的轉換,你可以讓機器學會把長的文章變成簡短的摘要,讓它學會怎麼精簡的寫作,讓它學會把長的文章變成短的句子。
甚至還有更狂的同樣的想法,可以做unsupervised的翻譯,什麼叫做unsupervised的翻譯呢,收集一堆英文的句子,收集一堆中文的句子,沒有任何成對的資料,成對的資料嘛你有知道說這句英文對到這句中文,但是unsupervised翻譯就是完全不用任何成對的資料,網路上爬一堆中文,網路上爬一堆英文,用剛才那個Cycle GAN的做法硬做,機器就可以學會把中文翻成英文了,你可以自己看一下文獻看看說機器做得怎麼樣。
到目前為止我們說的兩種風格都還是文字,可不可以兩種風格,甚至是不同類型的資料呢,有可能做,這是我們實驗室是最早做的,我們試圖去做非督導式的語音辨識,也就是讓機器聽一堆語音,語音辨識就是你需要收集成對的資料,你需要收集一大堆的聲音訊號然後找工讀生幫你把這些聲音訊號標註,機器才能夠學會某個語言的語音辨識,但是要標註資料所費不貲,所以我們想要挑戰非督導式的語音辨識,也就是機器只聽了一堆聲音,這些聲音沒有對應的文字,機器上網爬一堆文字,這些文字沒有對應的聲音,然後用Cycle GAN硬做,看看機器有沒有辦法把聲音轉成文字,看看它的正確率可以做到什麼樣的地步,至於正確率可以做到什麼樣的地步呢,那我把文獻留在這邊給大家參考。那以上就是有關GAN的部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号