Fast Rcnn
物体检测Faster Rcnn系列
目标检测概论
之前我们在机器学习了解过各种分类和回归算法
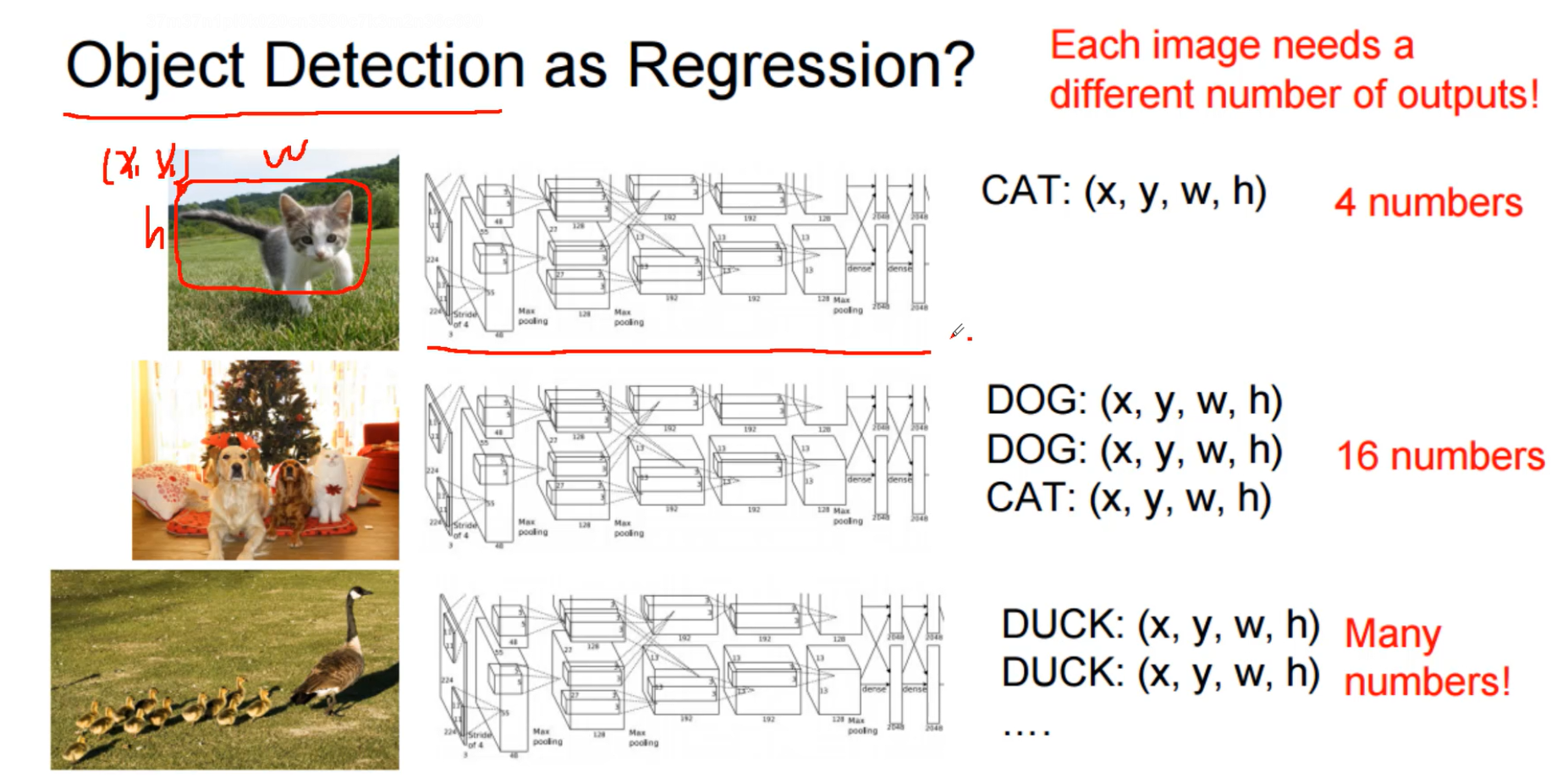
目标检测需要检测物体的位置,那么把目标检测看成回归任务?好像不太合适,因为一张图像可能有多个目标
那么看做分类问题呢

看成分类问题,用的是滑动窗口
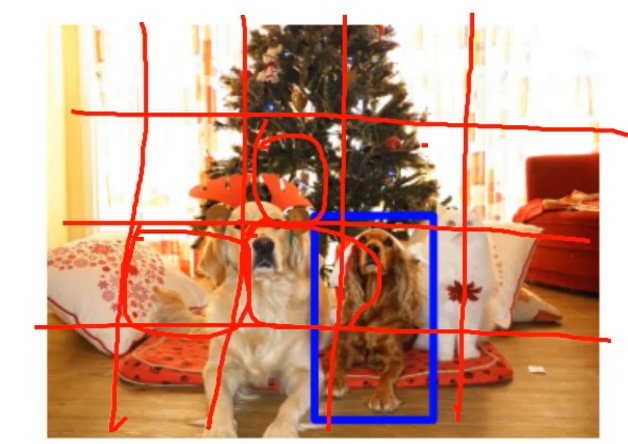
把图片划分为几个区域,然后一个个预测是不是dog ,但是速度太慢了。 看成分类不太行,看成回归也不行,哪有没有一种更好的方法。
之前有一种做法是Select Search算法,先筛选出一些可能是物体的候选框

先看几种经典的目标检测算法
经典目标检测算法
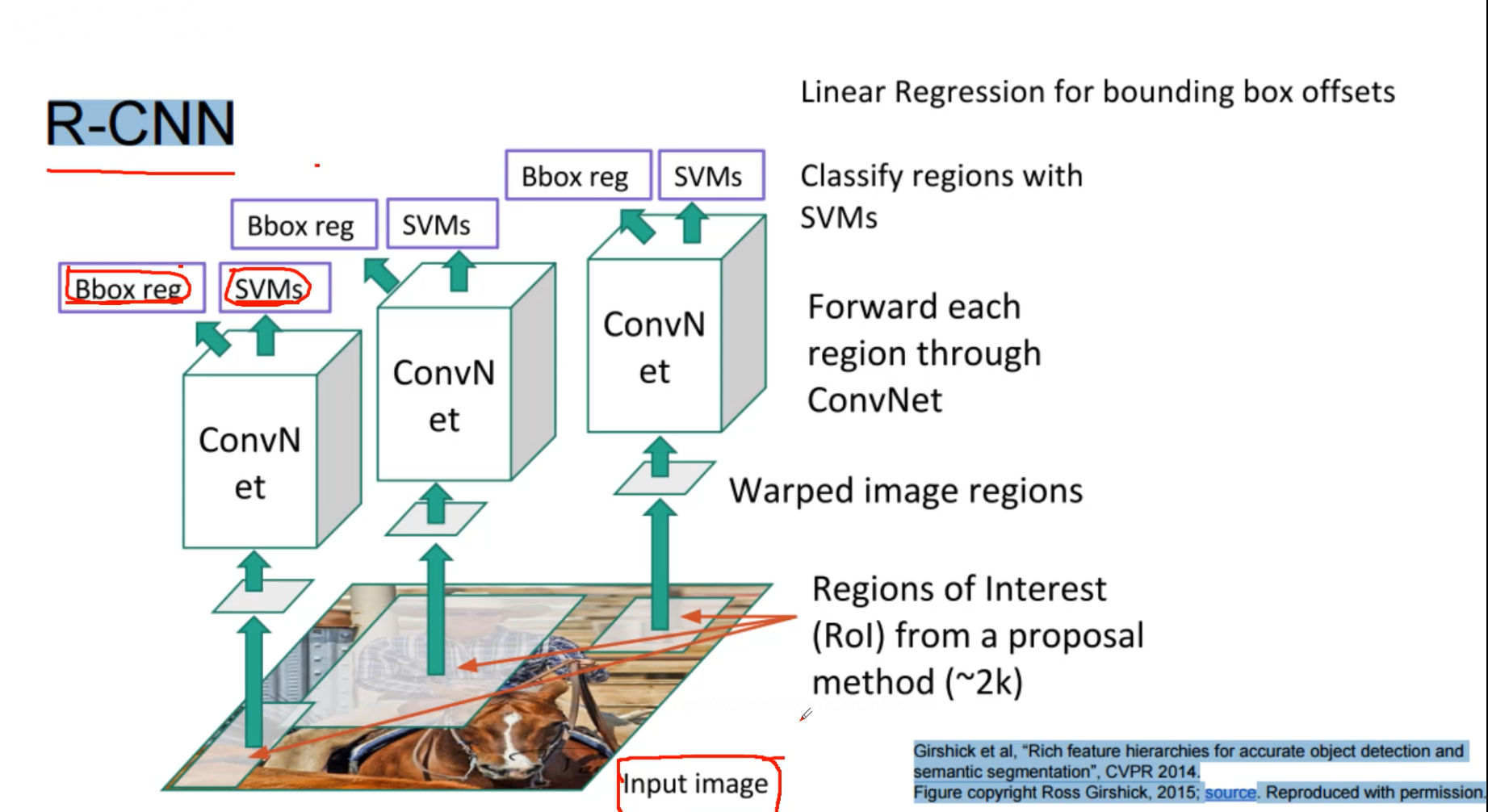
R-CNN这个算法比较老了,就不做过多的介绍了。 既做分类也做回归,SVMs典型的分离器,Bbox reg 典型的回归。
首先Select Search找到输入图像的候选框 (2K个左右)分别进行卷积
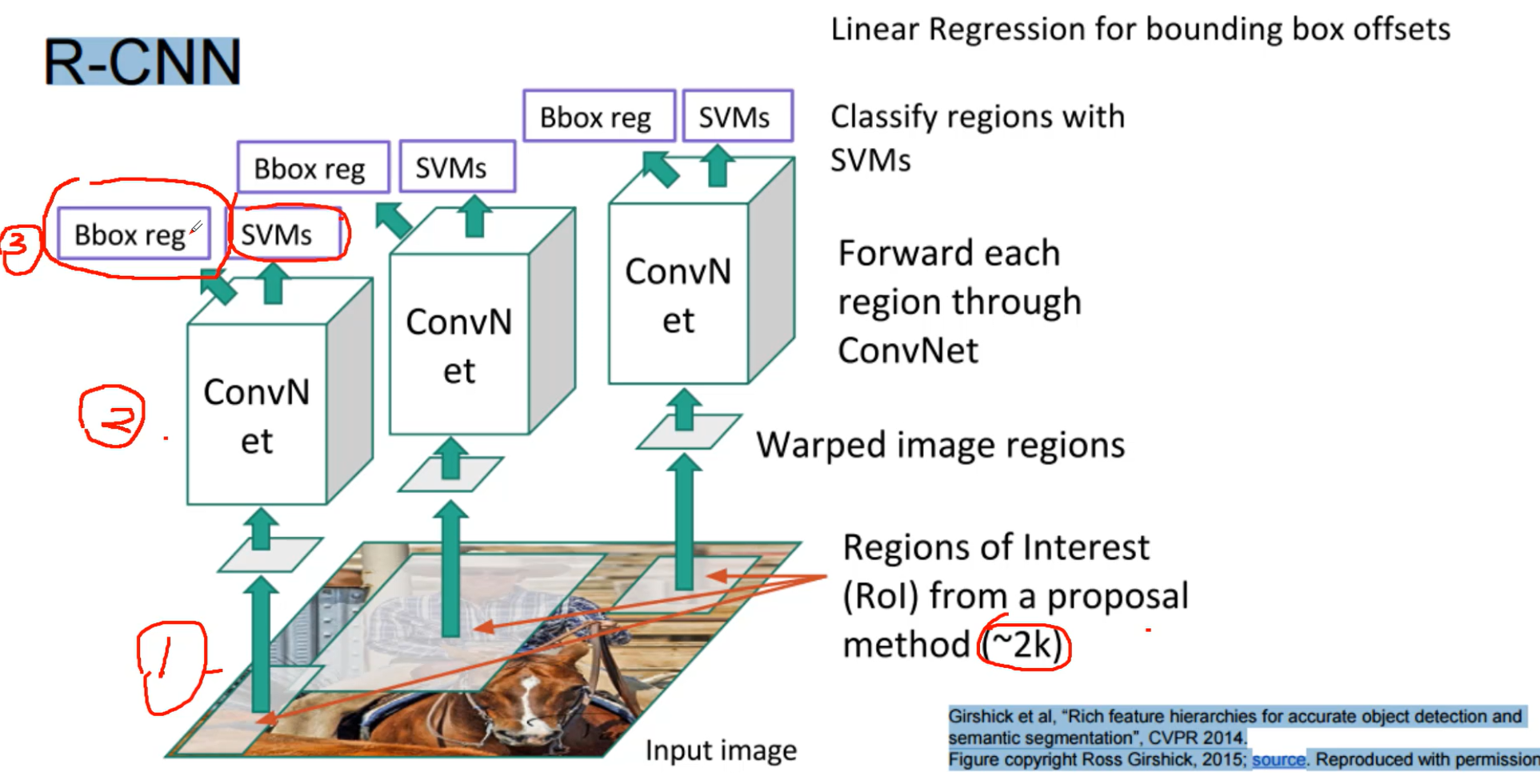
这个过程就慢了,首先选候选框,然后用卷积提取特征,再把提取到的特征输入,svm和回归模型进行预测。14年的一个算法

R-CNN的问题,候选框没有共享卷积网络。卷积网络对输入图像大小没有限制,但是全连接层限制了神经网络,因为全连接层要保持一致,由于Select Search生成的框大小不一样 ,所以就用了不同的卷积网络。那么怎么样能共享卷积,共享卷积就要最终连接的全连接层上左边的权重是一致的,但是输入图像大小又不一样
而且一个检测分类一个回归,训练太慢了,检测一张图片47s
用SPP-net进行改进,输入图像大小不一样,最终得到的特征图大小也不一样
在普通的CNN机构中,输入图像的尺寸往往是固定的(比如224*224像素),通过裁剪或者放缩使输入大小一样,输出则是一个固定维数的向量。SPP Net在普通的CNN结构中加入了ROI池化层(ROI Pooling),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。

通过金宇塔层,对特征图中每一个候选区进行划分,得到固定大小的特征向量。
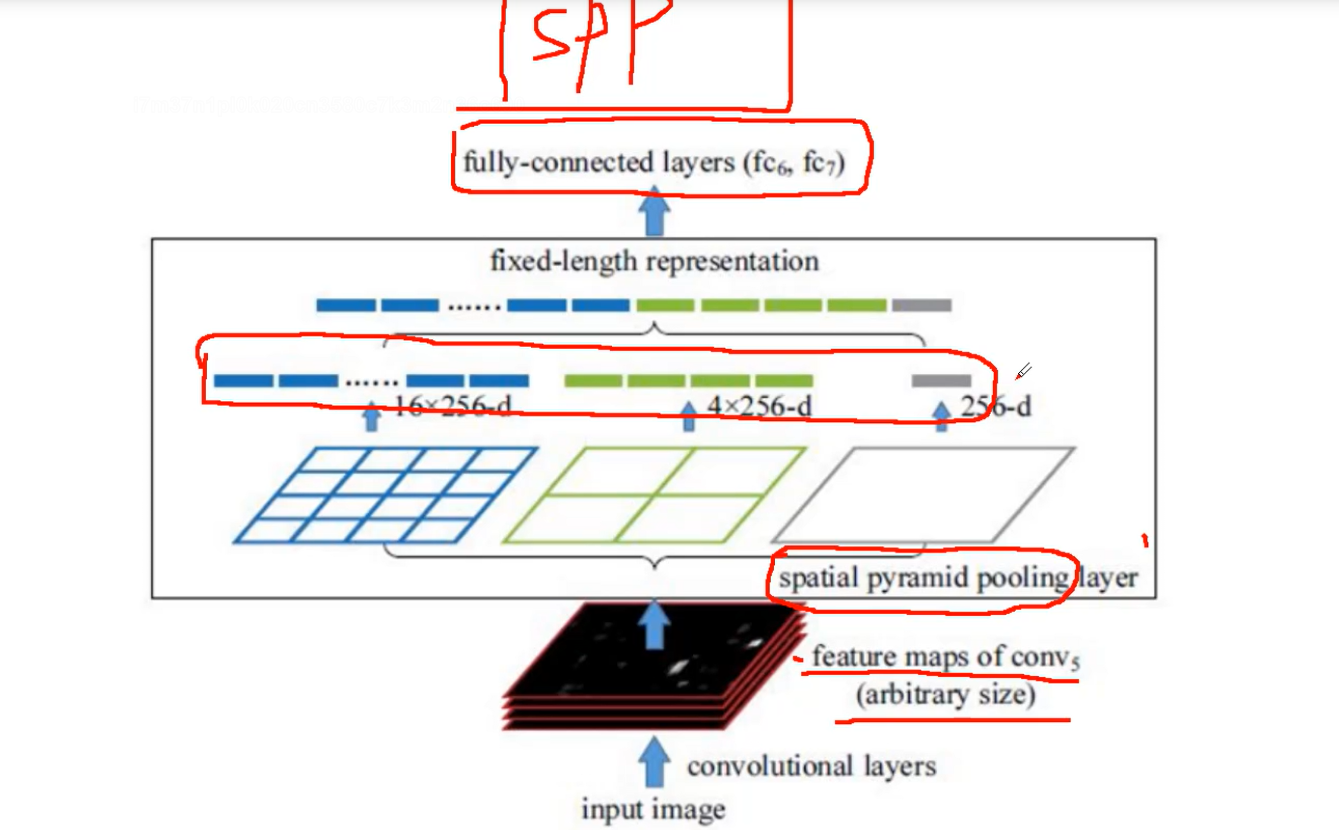
对于任意大小的特征图(如B×C×H×W),Spatial Pyramid Pooling首先分别将特征图划分为若干数量的子块,然后对这些子块计算最大池化,将计算结果进行拼接即可得到固定大小的输出。
上图采用了三个分支,分别将特征图划分1×1、2×2、4×4大小的子块,然后对每个子块进行最大池化,即将不同大小的子块都转化为一个值,将池化之后的结果进行拼接即可得到一个大小固定为21维的输出。如此一来,无论输入特征图的尺寸发生如何变化,Spatial Pyramid Pooling均可将其转化为固定大小的尺寸进行输出。
详细看这篇文章
经过第一代R-CNN,作者又提出第二代算法,fast R-CNN
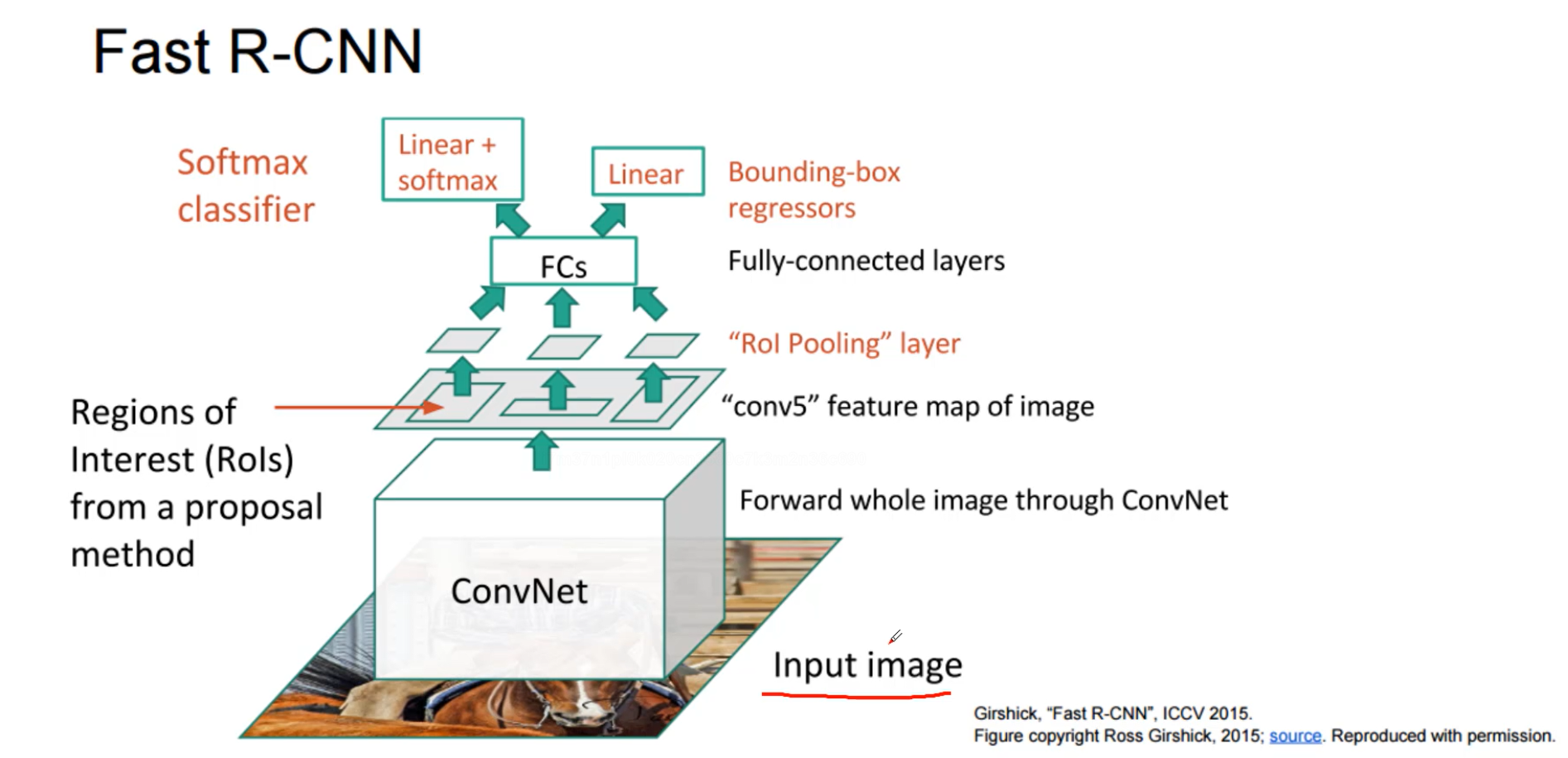
之前是先找候选框,现在是先卷积得到特征图,然后在找特征图对应的候选框,特征图上一块区域对应原始图像的区域(感受野)。但是需要ROl,
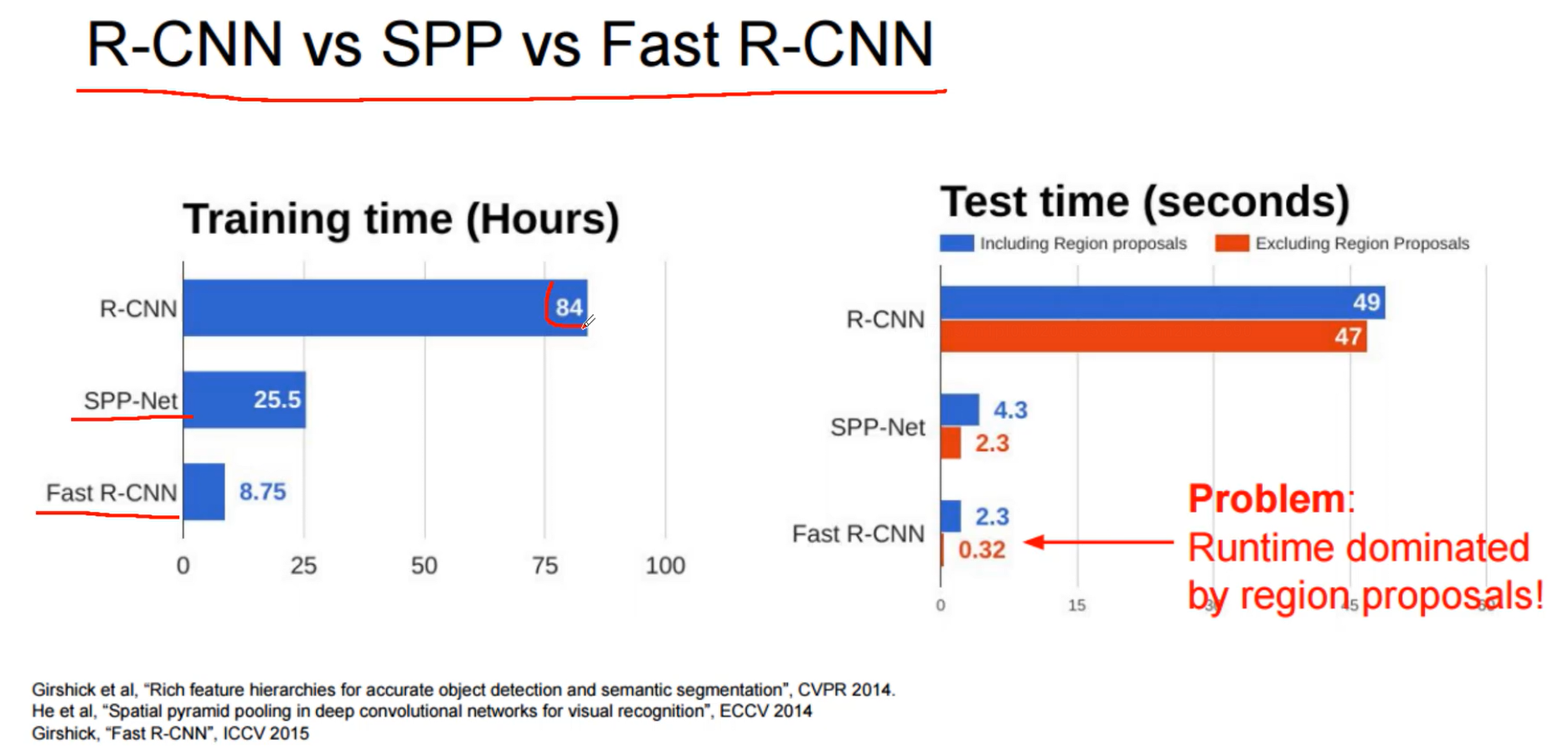
可以看出fast rcnn主要时间都花费在候选框上(Region proposal),而且Select Search只能在cpu上运行
如何解决这个问题
faster R-CNN
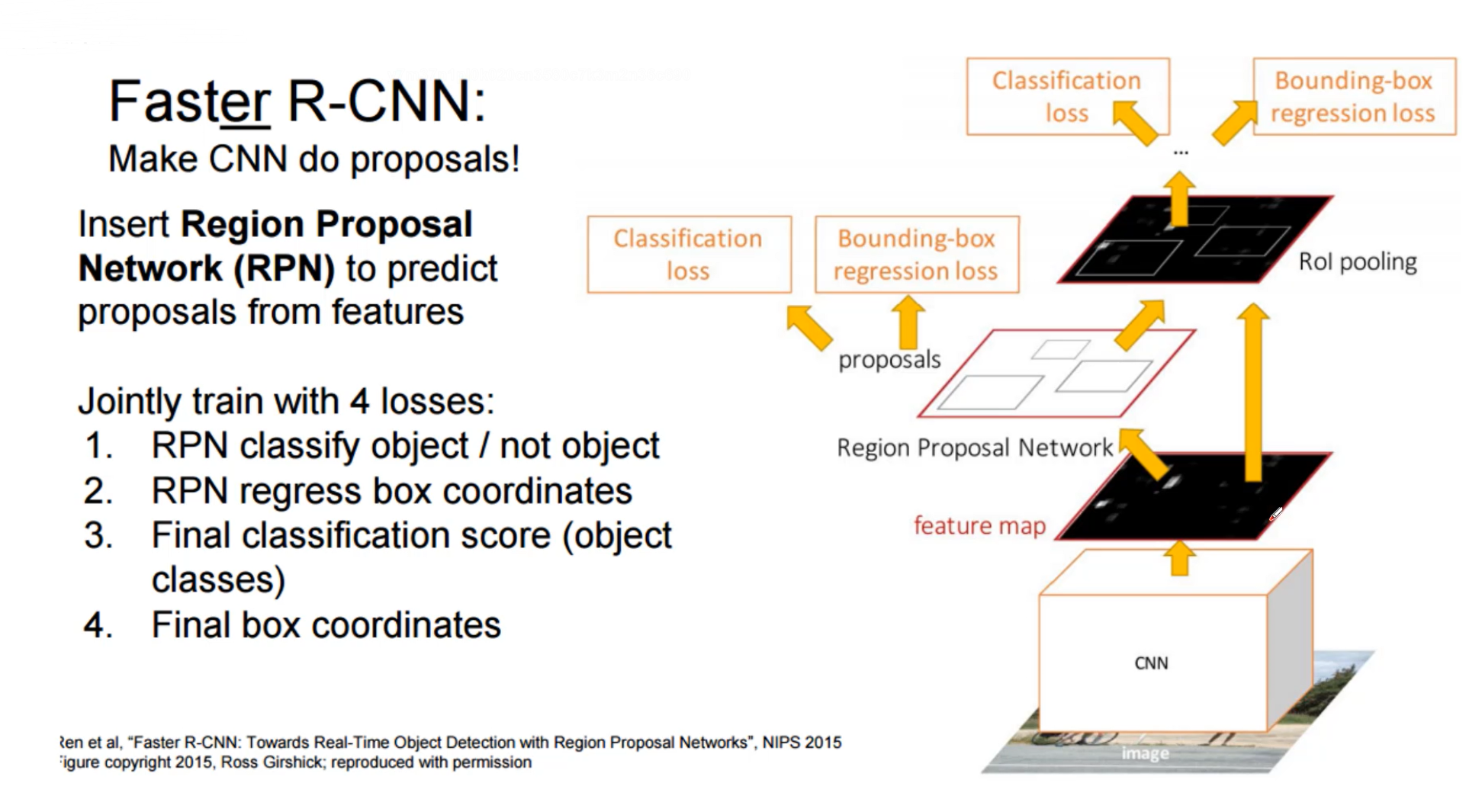
R-CNN(第一代),Fast R-CNN(第二代) , Faster R-CNN(第三代),第三代的主要改变就是增加了RPN层
RPN对特征图产生的候选框进行二分类,是不是一个物体,是物体后进行微调(bouding-box)产生的候选框和它最近的GT(Ground Truth)
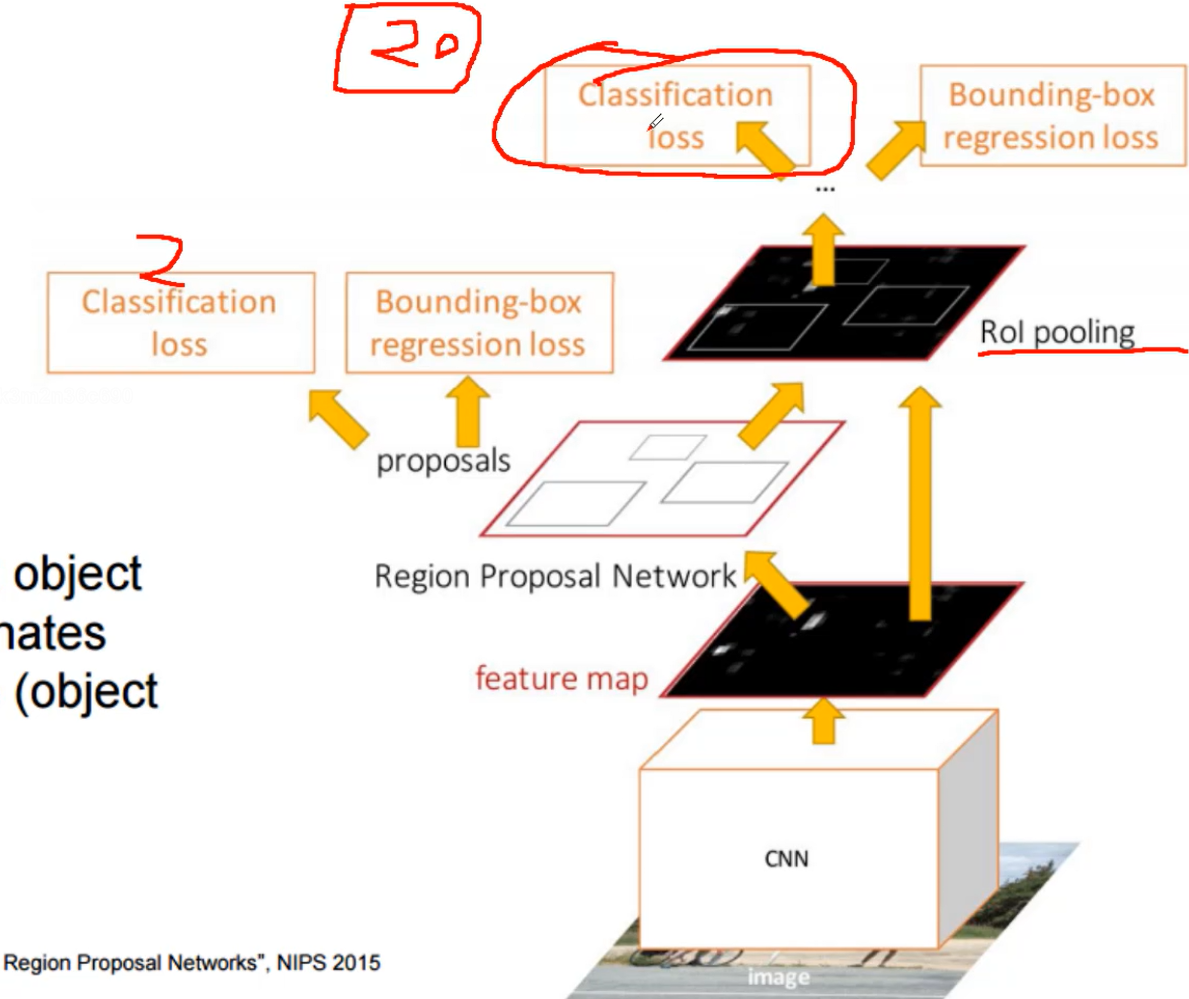
接下来做的才是20分类,之前的2分类只是判断是不是物体,后面的分类才是判断具体是什么
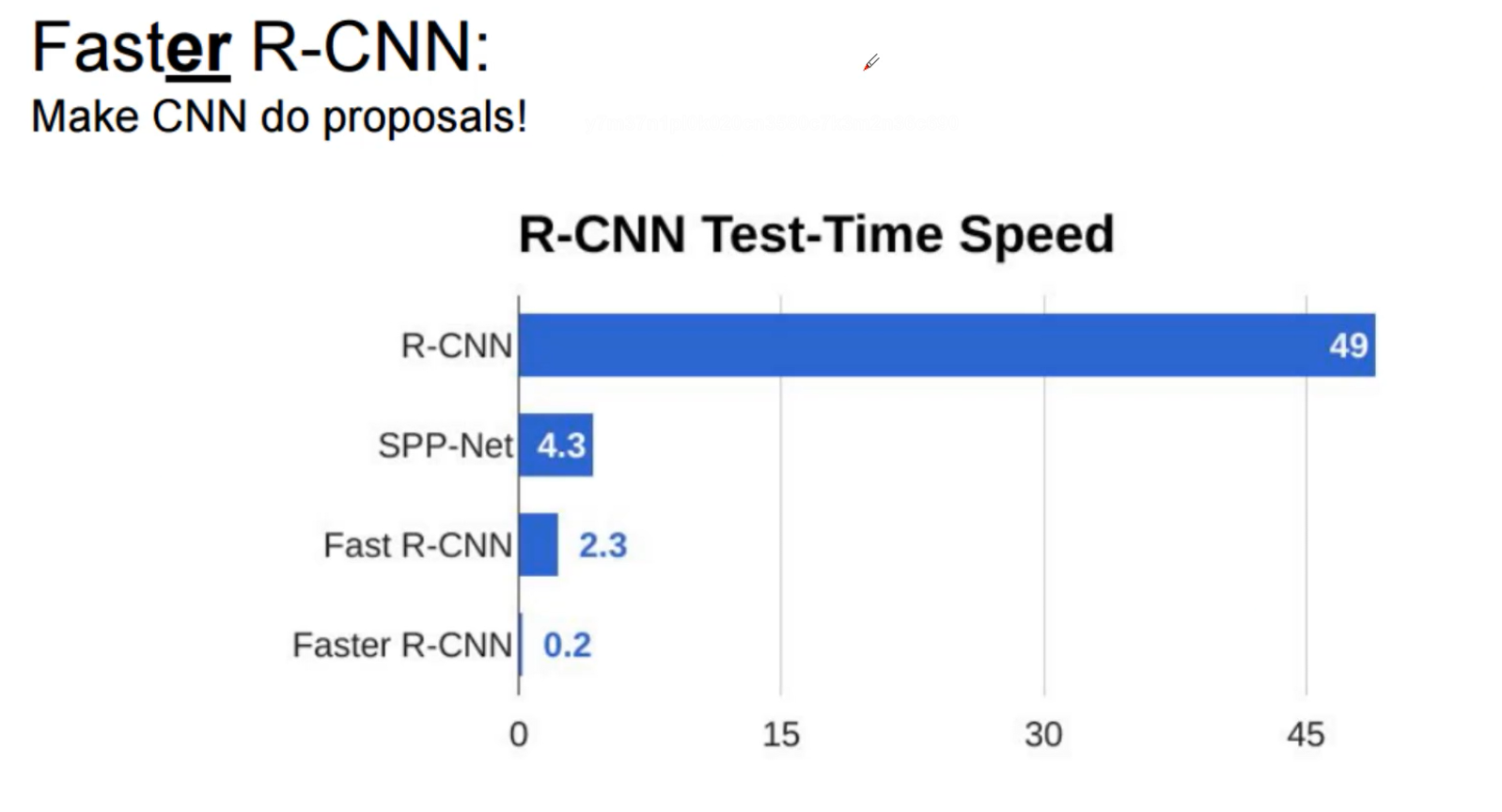
Faster R-CNN已经可以做到1秒5张图片,效果展示

论文整体概述

全卷积,一秒5帧
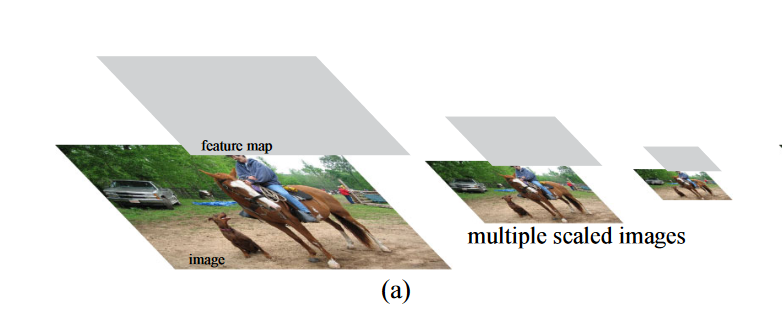
为了同时检测大目标和小目标,一种比较常见的方式就是图像金字塔,把图像resize成不同的大小,虽然这样可以找到大物体和小物体,但是由于输入图像变多,速度会非常的慢
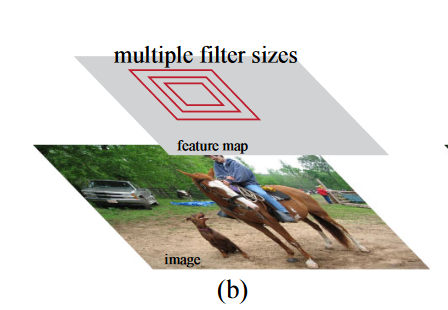
还有一种做法是对filter size做多种变换
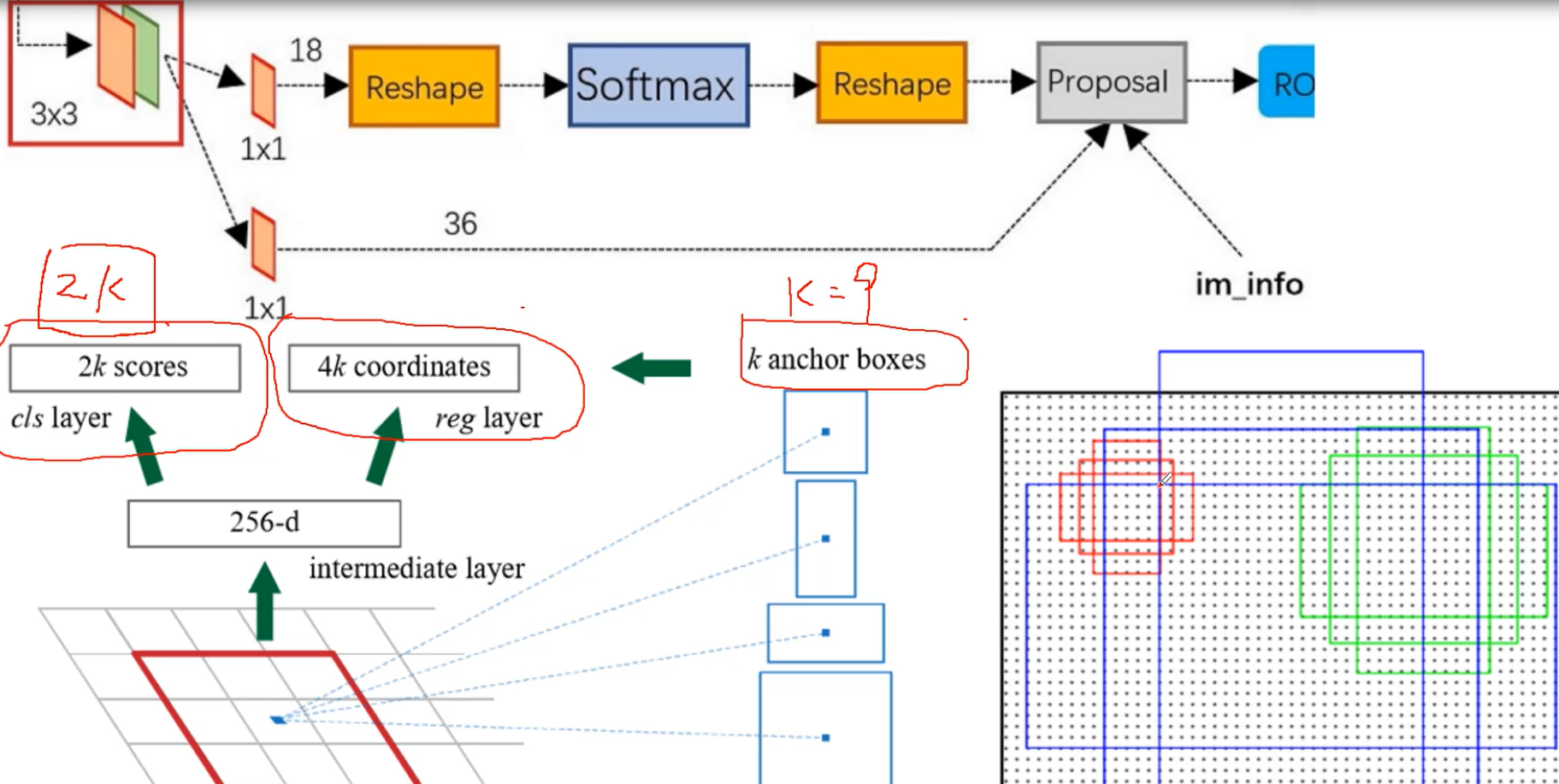
2k表示,对于k个候选框,每个框是前景和背景的概率,k=9的话,就是18个结果;4k是每个框预测的x,y,w,h
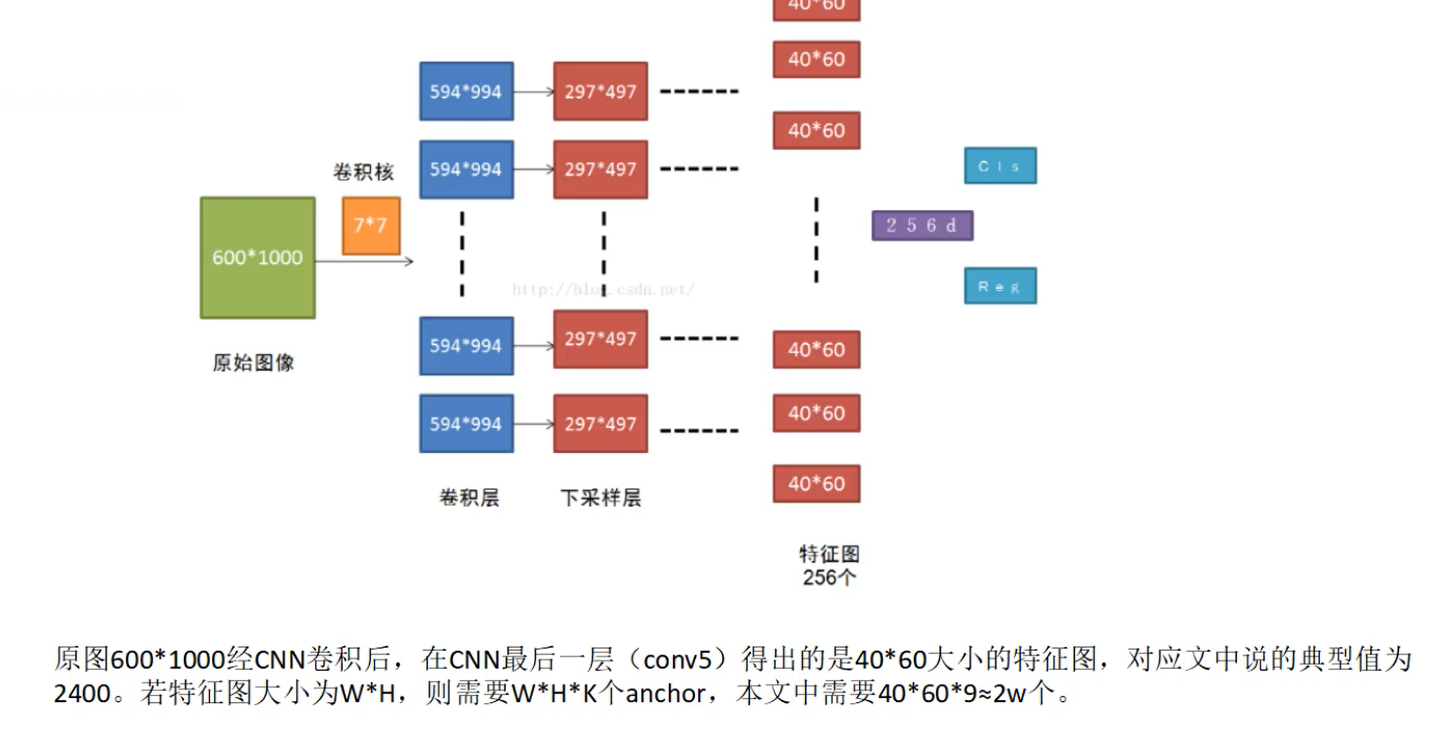
还有一步过滤的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号