机器学习----逻辑回归
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。例如肿瘤预测等是与否分类的问题
Logistic 分布是一种连续型的概率分布,其分布函数和密度函数分别为:
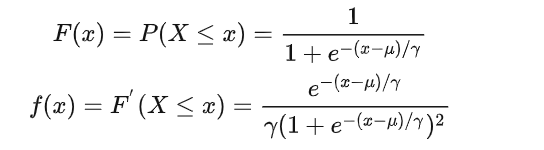
决策边界可以表示为 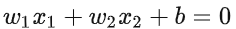 假设某个样本点
假设某个样本点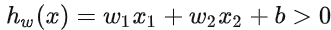 那么可以判断它的类别为 1,
那么可以判断它的类别为 1,
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, confusion_matrix # 加载数据集 data = load_breast_cancer() X = data.data y = data.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建逻辑回归模型 model = LogisticRegression() # 用训练集训练模型 model.fit(X_train, y_train) y_pred = model.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print('Accuracy: ', accuracy) # 计算混淆矩阵 confusion_mat = confusion_matrix(y_test, y_pred) print('Confusion Matrix: \n', confusion_mat)
在二分类问题中,精确率(Precision)、召回率(Recall)和F1分数是常用的性能指标。这些指标基于混淆矩阵中的四个基本元素:真阳性(True Positive, TP)、真阴性(True Negative, TN)、假阳性(False Positive, FP)和假阴性(False Negative, FN)。给定这些值,可以计算出精确率、召回率和F1分数。
计算方式:
精确率 (Precision):
Precision = TP / (TP + FP)召回率 (Recall) 或 灵敏度 (Sensitivity):
Recall = TP / (TP + FN)F1分数 (F1 Score):
F1 Score = 2 * Precision * Recall / (Precision + Recall)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号