【实验】语音识别
语音识别
题目及相关要求在here.
数据预处理
大致步骤:
-
获取原始音频
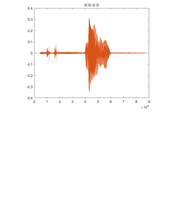
-
检测
-
分帧
-
加窗
-
特征提取
端点检测
| 端点检测参数指标 | 相对值 |
|---|---|
| 初始短时能量高门限 | 50 |
| 初始短时能量低门限 | 10 |
| 初始短时过零率高门限 | 10 |
| 初始短时过零率低门限 | 2 |
| 最大静音长度 | 8ms |
| 语音最小长度 | 20ms |
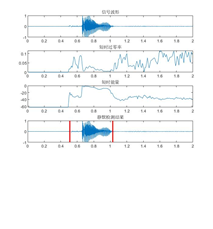
这里我们进行的是基于阈值的VAD,通过提取时域(短时能量、短期过零率等)或频域(MFCC、频谱等)特征,通过合理的设置门限,达到区分语音和非语音的目的。
我们的端点检测初始特征阙值如右表所示,通过这样的指标,我们检测出来的音频信息可以过滤掉大部分的噪音。
部分数字与名字信号的双端检测结果如下所示:
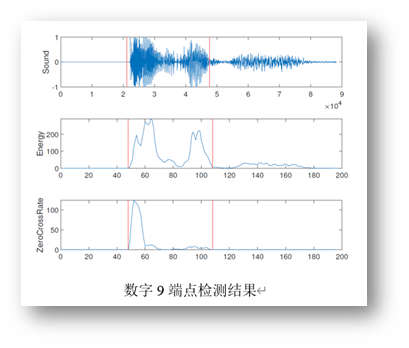
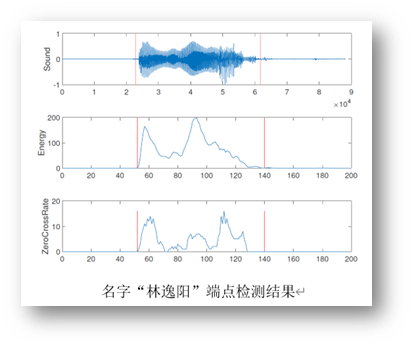
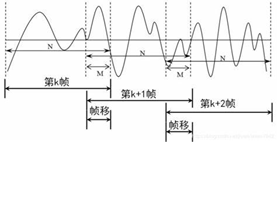
分帧
由于语音信号具有短时的平稳时不变的特性,因此对其在时域上进行短时间的分帧进行分析。
实验中使用的30ms的窗口长度和10ms的帧移,有比较好的效果。
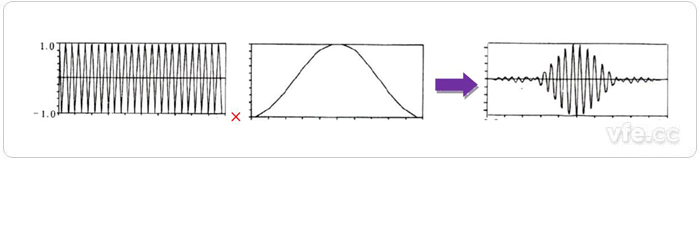
加窗
通过不同的窗处理滞后得到的图形有区别,其中矩形窗的变化比较剧烈,汉宁窗、海明窗的变换较为平稳。
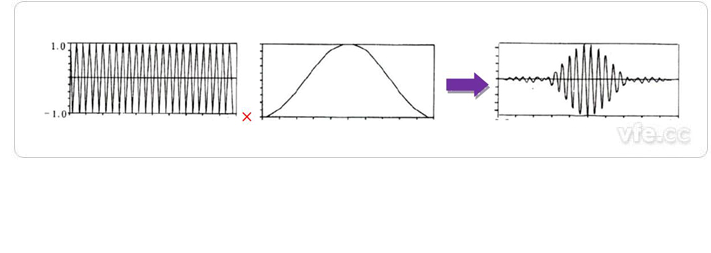
- 矩形窗处理后的时域信号
- 汉明窗处理后的时域信号
- 海宁窗处理后的时域信号
时域语音识别
提取语音特征
将处理之后的数据进行归一化处理,并计算出每一帧的特征值,以帧数作为特征向量的维数,得到用于分类的特征向量。特征向量是由过零率、能量和幅值组成的。
使用的分类器
-
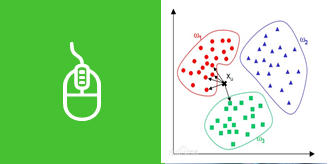
如果一个样本在特征空间中的K个最邻近的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别样本的特性。
-
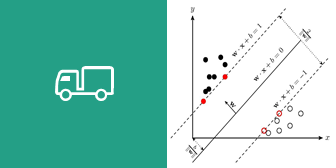
基本模型是定义在特征空间上的间隔最大的线性分类器,利用超平面,对数据集进行最大间隔划分,得到该超平面的表达式。
-
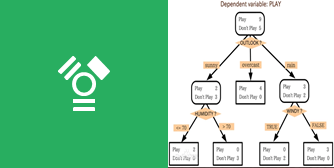
在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于0的概率,评价项目风险,判断其可行性的决策分析方法。
-
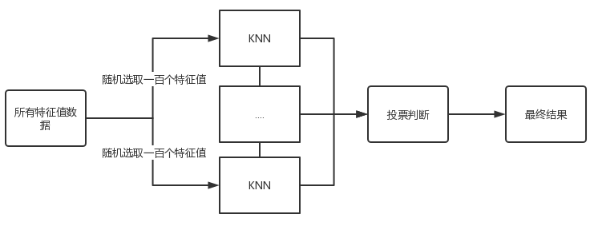
集成学习Based on KNN
-
集成学习算法是通过构建并结合多个分类器来完成学习任务,通常拥有较高的准确率,其不足之处是模型比较复杂。
-
实现过程
-
随机对原始数据的特征值进行随机采样。
-
将采样数据送入若干个KNN学习器中进行决策判断。
-
将所有结果进行投票处理。
-
-
时域语音分析
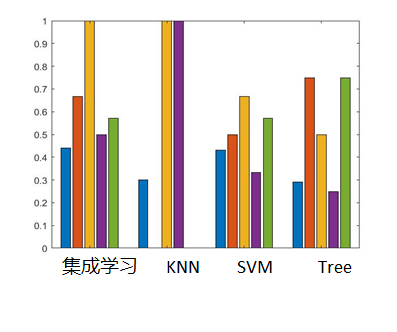
下面分别是KNN、SVM、决策树、集成学习KNN分类器得到的判别矩阵和AUC曲线。

结果如下表:
| 分类器 | 准确率 | 查准率 | 第一类错误率 | 第二类错误率 | F-score |
|---|---|---|---|---|---|
| KNN | 0.32 | 0.33 | 1.00 | 0.80 | 0.25 |
| SVM | 0.42 | 1.00 | 0.00 | 0.67 | 0.50 |
| Tree | 0.37 | 0.50 | 0.25 | 0.50 | 0.50 |
| 集成学习KNN | 0.44 | 0.60 | 0.67 | 0.25 | 0.67 |
不同加窗方式的效果比较
| 窗口种类 | 准确率 | 查准率 | 第一类错误率 | 第二类错误率 | F-score |
|---|---|---|---|---|---|
| 矩形窗 | 0.44 | 0.6 | 0.67 | 0.25 | 0.67 |
| 汉明窗 | 0.39 | 1 | 0 | 0..50 | 0.67 |
| 海宁窗 | 0.45 | 0.67 | 1 | 0.6 | 0.5 |
F-score表现:矩形窗=汉明窗>海宁窗
矩形窗处理后的语音信号识别效果更好
频域语音识别
实验流程
-
通过电脑录制音频。
-
将得到的音频数据进行预处理,经过端点检测得到理想的音频数据。
-
提取音频数据的MFCC特征。
-
进行DTW算法搜索。
-
将得到的结果进行总结归纳。
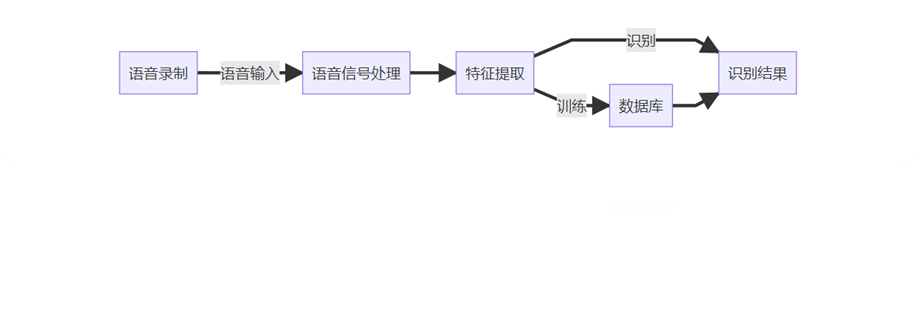
MFCC特征提取
-
分帧
-
FFT:对每一帧语音进行256点快速傅里叶变换。
-
三角带通滤波器
-
离散余弦转换:离散余弦转换(DCT)系数是用来将能量集中在前面几项中,达到在减少判别参数提高运算速度的同时又不失其准确性的目的。
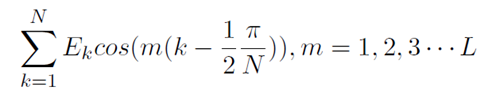
-
差量倒谱参数:一阶差分MFCC参数,体现相邻两帧之间的联系,所以我们合并mfcc参数和一阶差分mfcc参数形成MFCC参数,并且去除首尾两帧,以增加MFCC参数的准确性,增强实验的预测能力。

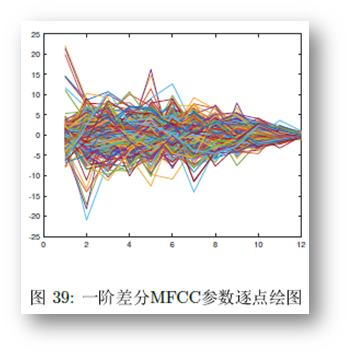
-
DTW
时域语音分析
我们使用交叉验证的方法,训练集与测试集的比例为9:1,在进行1000次的重复试验后,得到的数字识别与名字识别在不同的窗函数下得到的准确率如下。其中x轴为测试次数,y轴为准确率。
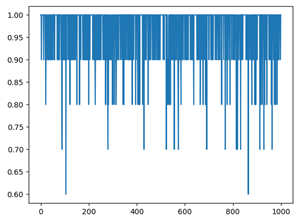
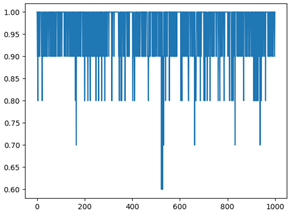
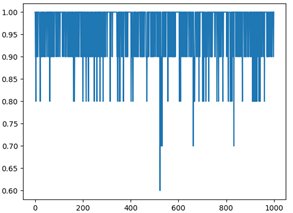
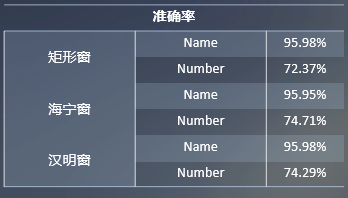
由上表各矩形窗的准确率所示,在矩形窗下数字识别整体准确率最低,而在汉明窗和海宁窗下的数字识别准确率相差不大。但是名字准确率在三个窗下的准确率波动不大。
相关视频:
我们可以发现在名字识别的时候端点检测只能检测到名字中的第一个字,这个是因为端点检测的参数没有进行调整。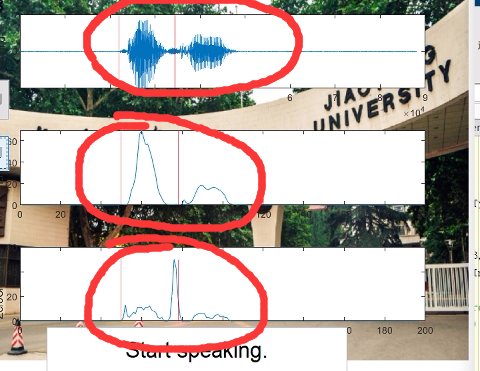
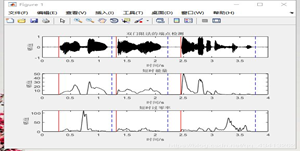
进行二次调参后: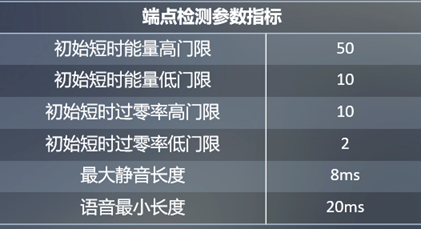
基于GMM模型的声纹识别
GMM
高斯混合模型(GMM)是声纹识别中最常用的模型之一,因为在声纹识别中,如何将语音特征很好地进行总结及测试语音如何与训练语音进行匹配都是非常复杂难解决的问题,而GMM将这些问题转为对于模型的操作及概率计算等问题,并进行解决。高斯混合模型可以逼近任何一个连续的概率分布,因此它可以看做是连续型概率分布的万能逼近器。GMM模型是一个有监督的训练过程。它的基本思想就是利用已知的样本结果来反推最有可能(也就是最大概率)导致该个结果的参数值,在这个原则之下,GMM通常采用最大期望算法(EM)模型进行迭代直到收敛来确定参数。
我们的工作
实验流程如下:
首先通过分帧,加窗等方法,对语音信号预处理,得到有效语音信号后,提取语音信号MFCC特征,并将其作为GMM模型的输入,对GMM模型进行训练,最后通过测试集对GMM模型进行测试。
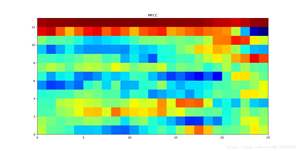
将提取到的语音MFCC特征,通过fitgmdist函数进行GMM模型训练,得到每个人的语音特征
说话人识别结果
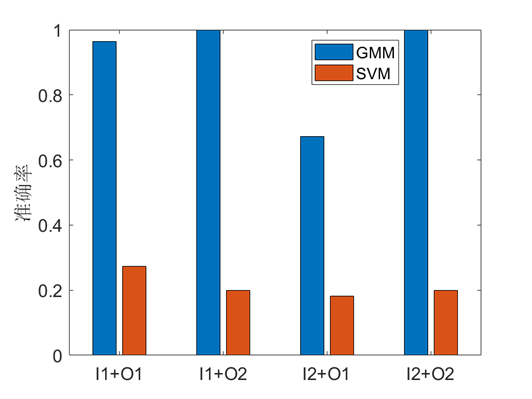
我们将每个同学念名字的语音信号和每个同学念数字的语音信号分别放入GMM模型和SVM分别进行训练和测试,对比两种模型优劣。
记放入训练的数字语音为I1,放入训练的名字语音为I2,用于测试的数字语音为O1,用于测试的名字语音为O2,我们分别用I1,I2作为训练集进行训练,并对每种情况下分别用O1和O2测试准确率。结果如图,可以看出当说话人语音为名字时,识别效果较好,为数字时较差。此外GMM模型效果优于SVM,SVM训练集准确率为1,而测试集准确率较低,模型泛化能力差,GMM泛化能力更好。
写在后面
对应的代码在Copy2000/DSP_experiment: 学校实验 (github.com),写的很乱,就这样,然后视频由于是放在github的服务器,可能会很慢。
还有两篇小论文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号