Python爬虫:使用正则表达式爬取网站电影信息
以爬取电影天堂喜剧片前5页信息为例,代码如下:
1 # coding:UTF-8 2 3 import requests 4 import re 5 6 def mov(): 7 headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 8 'Host':'www.dy2018.com'} 9 #url=('https://www.dy2018.com/1/') 10 r = requests.get(url,headers=headers) 11 data = r.text.encode("latin1").decode("gbk").replace(u'\u3000', u'') 12 pattern = re.compile('<a.*?class=ulink.*?</a>.*?<a.*?href="(.*?)" class="ulink".*?title=.*?>(.*?)</a>.*?</td>.*?<td.*?style="padding-left.*?>.*?<font.*?>.*?日期:(.*?)</font>.*?<font\scolor=.*?◎评分:\s(.*?)\s.*?</font>.*?<td.*?colspan="2".*?style=.*?<p>◎片名:(.*?)\s.*?◎别名:(.*?)\s.*?导演:(.*?)\s.*?</p>.*?<p>\s.*?类型:(.*?)\s.*?<p>.*?主演:(.*?)</p>',re.S) 13 #pattern = re.compile('<font\scolor=":(.*?)</font>.*?<td\scolspan="2".*?<p>(.*?) </p>.*?<p>(.*?)</p>.*?<p>(.*?)</p>.*?</td>.*?</tr>',re.S) 14 items = re.findall(pattern,data) 15 for item in items: 16 yield{ 17 'href':item[0], 18 '标题':item[1], 19 '日期':item[2], 20 '评分':item[3], 21 '片名':item[4], 22 '别名':item[5], 23 '导演':item[6], 24 '类型':item[7], 25 '主演':item[8] 26 } 27 28 def save_file(d): 29 with open('t1.html','a',encoding='utf-8') as f: 30 f.write('\n第'+str(i)+'页\n') 31 for m in d: 32 f.write(str(m)+'\n') 33 34 35 for i in range(1,6): 36 d=mov() 37 if i==1: 38 url='https://www.dy2018.com/1/' 39 save_file(d) 40 print('第 1 页爬取完成!') 41 else: 42 url = ('https://www.dy2018.com/1/index_' + str(i) + '.html') 43 save_file(d) 44 print('第',i,'页爬取完成!')
电影信息爬取效果:
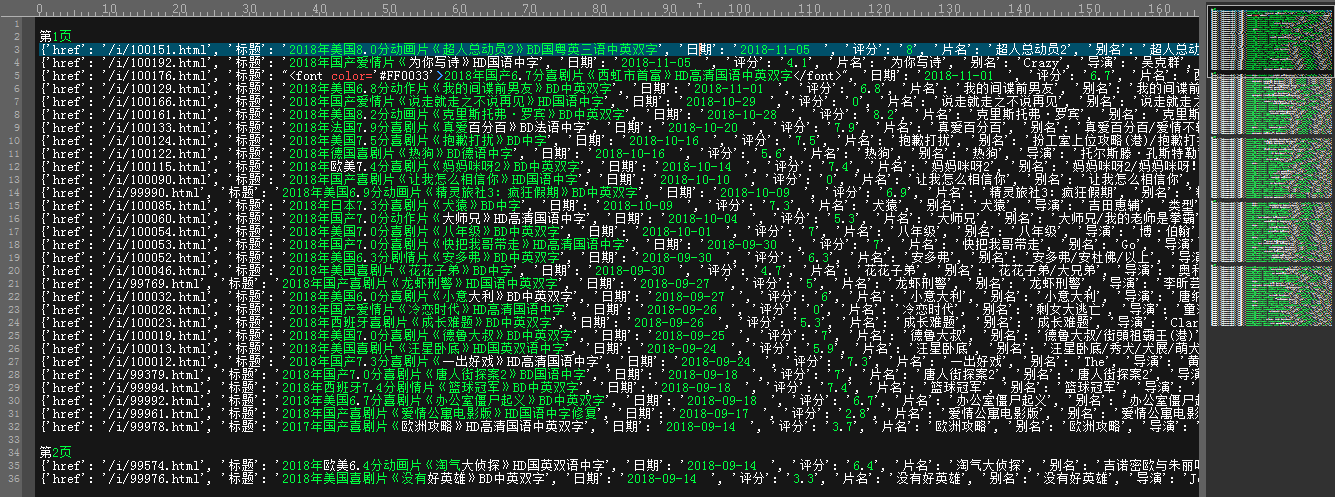
爬取下载地址代码如下:
1 # coding:UTF-8 2 3 import requests 4 import re 5 6 def hrefs(): 7 headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 8 'Host':'www.dy2018.com'} 9 #url=('https://www.dy2018.com/1/') 10 r = requests.get(url,headers=headers) 11 pattern = re.compile('<a.*?class=ulink.*?</a>.*?<a.*?href="(.*?)" class="ulink"',re.S) 12 href = re.findall(pattern,r.text) 13 return href 14 15 def inf(link): 16 for h in link: 17 durl= ('https://www.dy2018.com'+ h) 18 headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 19 'Host':'www.dy2018.com'} 20 dr = requests.get(durl,headers=headers) 21 ddata = dr.text.encode("latin1").decode("gbk").replace(u'\u3000', u'') 22 pattern = re.compile('alt=.*?译.*?名(.*?)</p>.*?片.*?名(.*?)</p>.*?style="margin.*?href="(.*?)">.*?',re.S) 23 info = re.findall(pattern,ddata) 24 for item in info: 25 yield{ 26 #'译名':item[0], 27 '片名':item[1], 28 '下载地址':item[2] 29 } 30 31 def save_file(link): 32 with open('t2.html','a',encoding='utf-8') as f: 33 #link=hrefs() 34 f.write('\n第'+str(i)+'页\n') 35 for ins in inf(link): 36 f.write(str(ins)+'\n') 37 38 39 for i in range(1,6): 40 if i==1: 41 url='https://www.dy2018.com/1/' 42 link=hrefs() 43 save_file(link) 44 print('第 1 页爬取完成!') 45 else: 46 url = ('https://www.dy2018.com/1/index_' + str(i) + '.html') 47 link=hrefs() 48 save_file(link) 49 print('第',i,'页爬取完成!')
爬取下载地址效果如下:
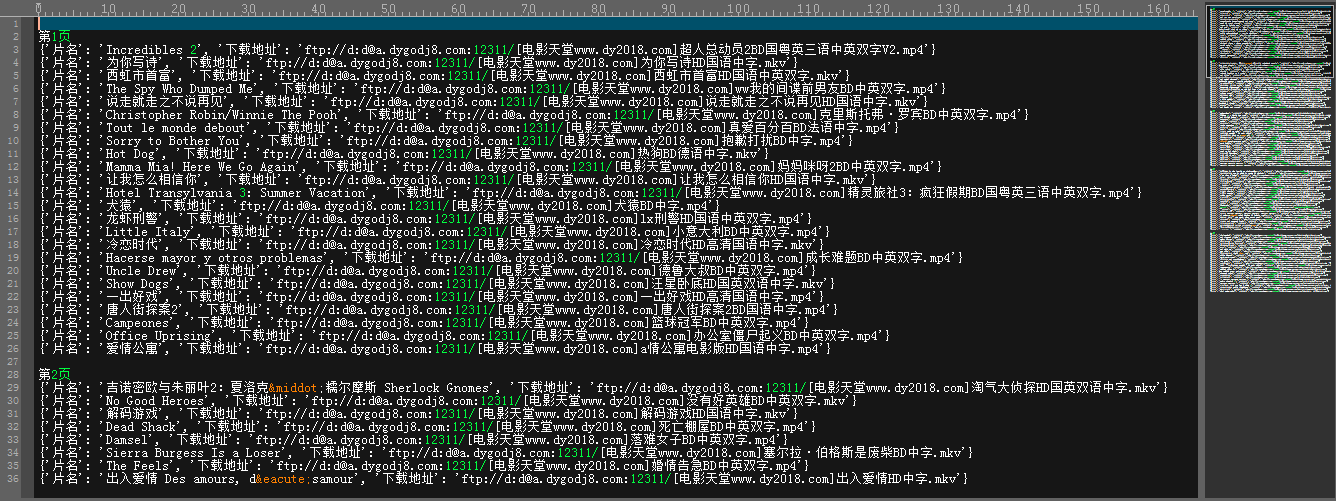


 浙公网安备 33010602011771号
浙公网安备 33010602011771号