一、集合框架概览
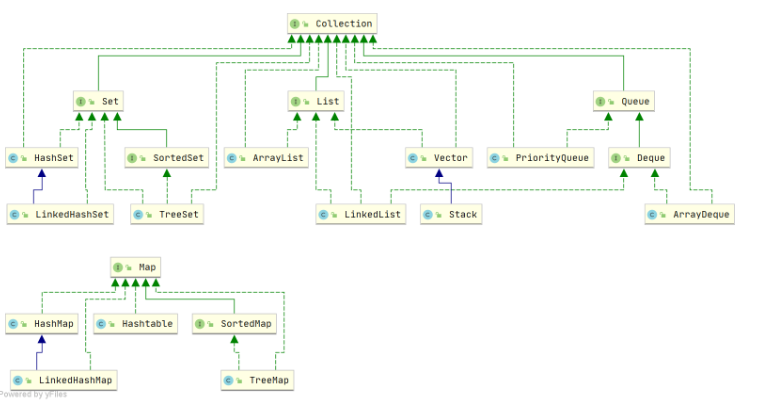
Java集合也叫做容器,由两大接口派生而来,一个是collection接口,主要用于存放单一元素,另一个是map接口,用于存放键值对。collection有三个子接口:list、set、queue。
相较于数组,Java 集合的优势在于它们的大小可变、支持泛型、具有内建算法,比如add(),remove()等。
list、set、queue、map区别?
- list:存放的元素是有序、可重复的
- set:存放的元素是无序、不可重复的
- queue:存放的元素是有序、可重复的,可按特定的排序规则来确定先后顺序
- map:存放的是键值对,键key是无序、不可重复的,value是无序、可重复的
二、LIst
主要有ArrayList、vector、linkedlist
1、ArrayList:底层数据结构是object数组,线程不安全。
与数组不同的是ArrayList 内部基于动态数组实现,比 Array(静态数组) 使用起来更加灵活:
1、ArrayList会动态扩容,而数组被创建后大小不能变了
2、ArrayList使用泛型来确保类型安全,数组则不能使用泛型
3、ArrayList只能存储对象,而数组既可以存储基本数据类型也可以存储对象
4、ArrayList具有丰富的内建算法,比如
add()、remove()等。数组只能按照下标访问其中的元素
2、vector:底层是object数组,线程安全
3、linkedlist:底层是双向链表,线程不安全。与ArrayList的区别是:
1、插入删除的复杂度linkedlist是O(1),ArrayList是O(n)
2、linkedlist不支持随机元素访问,而ArrayList支持
自定义排序:
Comparable 接口和 Comparator 接口都是 Java 中用于排序的接口,它们在实现类对象之间比较大小、排序等方面发挥了重要作用:
Comparable接口实际上是出自java.lang包 它有一个compareTo(Object obj)方法用来排序Comparator接口实际上是出自java.util包它有一个compare(Object obj1, Object obj2)方法用来排序


1 // person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列 2 // 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他 3 // 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了 4 public class Person implements Comparable<Person> { 5 private String name; 6 private int age; 7 8 public Person(String name, int age) { 9 super(); 10 this.name = name; 11 this.age = age; 12 } 13 14 public String getName() { 15 return name; 16 } 17 18 public void setName(String name) { 19 this.name = name; 20 } 21 22 public int getAge() { 23 return age; 24 } 25 26 public void setAge(int age) { 27 this.age = age; 28 } 29 30 /** 31 * T重写compareTo方法实现按年龄来排序 32 */ 33 @Override 34 public int compareTo(Person o) { 35 if (this.age > o.getAge()) { 36 return 1; 37 } 38 if (this.age < o.getAge()) { 39 return -1; 40 } 41 return 0; 42 } 43 }
三、set
1、hashset:底层是hashmap,存储的元素具有无序性和不可重复性,实现不可重复性需要重写equals()和hashcode()方法
2、linkedhashset:底层是linkedhashmap。存储的元素是有序的、不可重复的
3、treeset(有序,唯一),底层是红黑树
四、queue
1、priorityqueue:obiect数组来实现二叉堆
2、arrayqueue:object数组+双指针
3、bolckingqueue:阻塞队列,当队列没有元素时一直阻塞,直到有元素;如果队列已满则阻塞,直到可以放入新的元素。线程安全。
BlockingQueue 常用于生产者-消费者模型中,生产者线程会向队列中添加数据,而消费者线程会从队列中取出数据进行处理,代码如下:

1 import java.util.concurrent.BlockingQueue; 2 import java.util.concurrent.ArrayBlockingQueue; 3 4 class Producer implements Runnable { 5 private final BlockingQueue<Integer> queue; 6 private final int maxItems; 7 8 public Producer(BlockingQueue<Integer> queue, int maxItems) { 9 this.queue = queue; 10 this.maxItems = maxItems; 11 } 12 13 @Override 14 public void run() { 15 try { 16 for (int i = 1; i <= maxItems; i++) { 17 queue.put(i); // 将项目放入队列 18 System.out.println("生产者生产: " + i); 19 Thread.sleep(1000); // 模拟生产过程耗时 20 } 21 } catch (InterruptedException e) { 22 Thread.currentThread().interrupt(); 23 } 24 } 25 } 26 27 class Consumer implements Runnable { 28 private final BlockingQueue<Integer> queue; 29 30 public Consumer(BlockingQueue<Integer> queue) { 31 this.queue = queue; 32 } 33 34 @Override 35 public void run() { 36 try { 37 while (true) { 38 int item = queue.take(); // 从队列中获取项目(如果队列为空,则阻塞) 39 System.out.println("消费者消费: " + item); 40 Thread.sleep(2000); // 模拟消费过程耗时 41 } 42 } catch (InterruptedException e) { 43 Thread.currentThread().interrupt(); 44 } 45 } 46 } 47 48 public class ProducerConsumerExample { 49 public static void main(String[] args) { 50 final int capacity = 5; // 队列的最大容量 51 BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(capacity); 52 53 // 创建生产者和消费者线程 54 Thread producerThread = new Thread(new Producer(queue, 10)); 55 Thread consumerThread = new Thread(new Consumer(queue)); 56 57 // 启动线程 58 producerThread.start(); 59 consumerThread.start(); 60 } 61 }
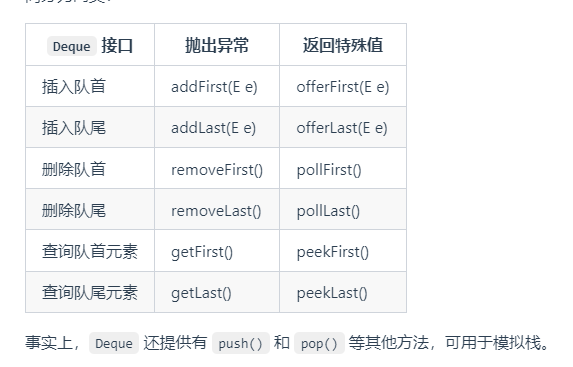
queue和deque的区别:
1、queue是单端队列,只能从一端插入元素,另一端删除元素,遵循先进先出原则
2、deque是双端队列,在队列的两端均可以插入和删除元素,可以模拟栈
五、map
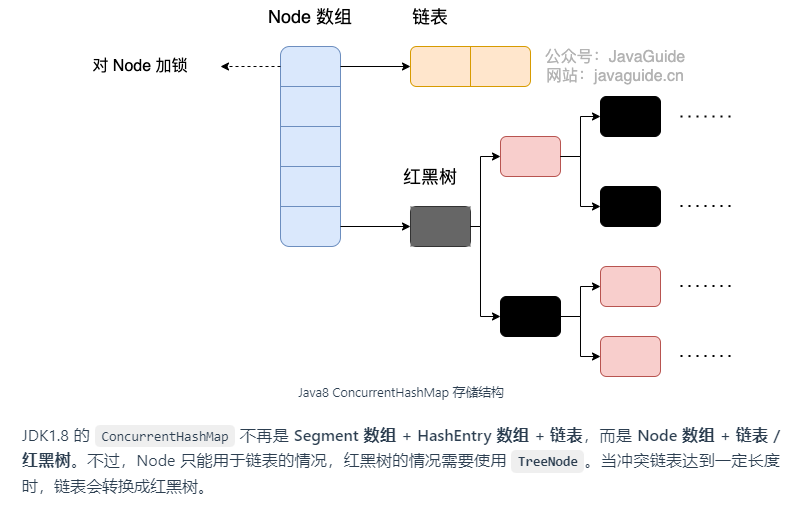
1、hashmap:底层是数组+链表(或者红黑树),主题是数组,链表是为了解决哈希冲突,当链表长度大于8,数组容量大于64时会转换为红黑树,以减少搜索时间。线程不安全。
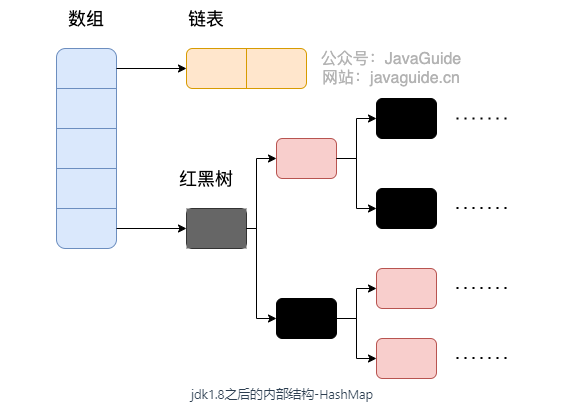
2、linkedhashmap:在hashmap的基础上增加了链表来保证有序性
3、hashtable:底层和hashmap一样,不同的是方法都是用sychronized修饰,因此是线程安全的;而且hashtablr不允许存储null值null键;初始容量是11,hashmap初始容量是16
4、treemap:底层是红黑树;与hashmap不同的是,TreeMap 有了对集合中的元素根据键排序的能力。
5、ConcurrentHashMap:线程安全
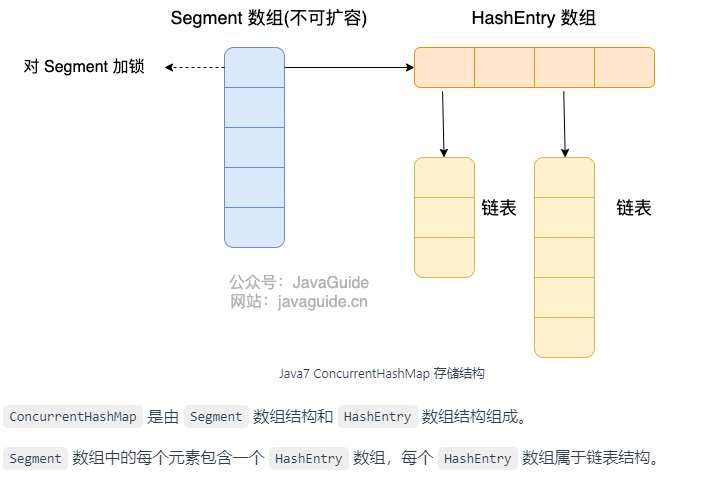
JDK1.7 的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。
与hashtabled的区别:
hashtable是:使用 synchronized 来保证线程安全,效率非常低下。
JDK1.7时,concurrenthashmap使用的是分段锁;JDK1.8 时是对node加锁,使用synchronized 和 CAS 来保证线程安全。锁的粒度更细了,synchronized 只锁定当前链表或红黑二叉树的首节点。