docker elasticsearch+kibana的部署使用 laravel安装使用elasticsearch
- elasticsearch简介
- elasticsearch安装配置
1. elasticsearch简介
elasticsearch介绍
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
应用场景
- 维基百科,类似百度百科
- The Guardian(国外新闻网站)
- Stack Overflow(国外的程序异常讨论论坛)
- GitHub(开源代码管理)
- 电商网站
- 日志数据分析
- 商品价格监控网站
- BI系统,商业智能
- 站内搜索(电商,招聘,门户,等等),
- IT系统搜索(OA,CRM,ERP,等等),
- 数据分析(ES热门的一个使用场景)
es的功能
- 分布式的搜索引擎和数据分析引擎
- 全文检索,结构化检索,数据分析
- 对海量数据进行近实时的处理
es的特点
- 大型分布式集群
- 功能强大
- 部署简单
- 能够替代数据库的不足之处
2. elasticsearch的安装配置
- docker获取es的镜像
docker pull elasticsearch:7.12.1
- 创建es文件目录以及创建配置文件
mkdir /docker/es
mkdir /docker/es/conf
mkdir /docker/es/data
mkdir /docker/es/plugins
touch /docker/es/conf/elasticsearch.yml
cluster.name: my-application #集群名称
node.name: node-1 #节点名称
#数据和日志的存储目录
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
###设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
http.port: 9200 #端口
###设置在集群中的所有节点名称,这个节点名称就是之前所修改的,当然你也可以采用默认的也行,目前 是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]
### 设置密码
#xpack.security.enabled: true
#xpack.license.self_generated.type: basic
#xpack.security.transport.ssl.enabled: true
# 配置X-Pack
http.cors.allow-origin: "*"
#http.cors.allow-headers: Authorization
- 构建容器
docker run -p 9200:9200 -d --name es -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -v /docker/es/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /docker/es/data:/usr/share/elasticsearch/data -v /docker/es/plugins:/usr/share/elasticsearch/plugins --privileged=true elasticsearch:7.12.1
出现异常:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决:
1. 修改配置sysctl.conf
vi /etc/sysctl.conf
2. 在尾行添加以下内容
vm.max_map_count=655300
3. 执行命令
sysctl -p

- 拉取kibana镜像
docker pull kibana:7.12.1
- kibana的配置文件
mkdir /docker/kibana
mkdir /docker/kibana/conf
touch /docker/kibana/conf/kibana.yml
文件内容:
server.name: kibana
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://你的es地址:9200"]
xpack.monitoring.ui.container.elasticsearch.enabled: true
- 构建kibana的容器
docker run -p 5601:5601 -d --name -v /docker/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.yml --privileged=true kibana:7.12.1
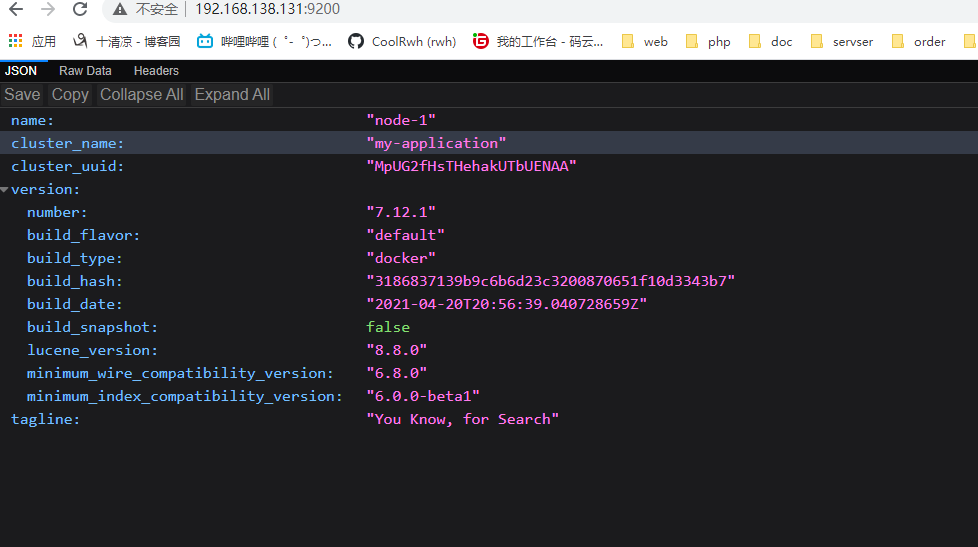
访问192.168.138.131:9200与192.168.138.131:5601
kibana:
elasticsearch:
3. laravel使用elasticsearch
composer安装elasticsearch扩展包
composer require elasticsearch/elasticsearch "7.12.x" --ignore-platform-reqs
配置es
config/database.php
.
.
.
'elasticsearch' => [
'hosts' => explode(',',env('ES_HOSTS')),
]
.env
.
.
.
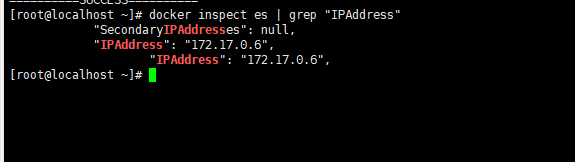
ES_HOSTS=172.17.0.6
查看ES在docker中的地址
docker inspect es | grep "IPAddress"
初始化elasticsearch对象
初始化 Elasticsearch 对象,并注入到 Laravel 容器中:
App/Providers/AppServiceProvider.php
<?php
namespace App\Providers;
use Illuminate\Support\ServiceProvider;
use Elasticsearch\ClientBuilder as ESClientBuilder;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
$this->app->singleton('es',function (){
$builder = ESClientBuilder::create()->setHosts(config('database.elasticsearch.hosts'));
if (app()->environment()==='local'){
$builder->setLogger(app('log')->driver());
}
return $builder->build();
});
}
/**
* Bootstrap any application services.
*
* @return void
*/
public function boot()
{
//
}
}
?>
代码解释:
在laravel容器中自定义一个名为es的服务对象,通过ESClientBuilder以及配置文件中的信息连接到es,我们可以通过app('es')->info()查看连接之后的es对象信息。
注册完成后,进行测试
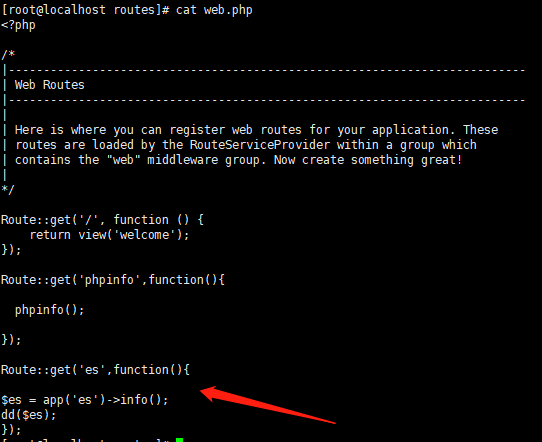
结果如下:
简单的集群管理
(1)快速检查集群的健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488006741 15:12:21 elasticsearch green 1 1 1 1 0 0 1 0 - 50.0%
如何快速了解集群的健康状况?green、yellow、red?
- green:每个索引的primary shard和replica shard都是active状态的
- yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
- red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
为什么现在会处于一个yellow状态?
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
做一个小实验:此时只要启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
(2)快速查看集群中有哪些索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_7.12.1_001 3GfeQjYiRIGo2i5uz3C1EA 1 0 47 8 4.2mb 4.2mb
yellow open skus nhDegXL5QZGbTahireBDzA 1 1 0 0 208b 208b
green open .apm-custom-link C3ESAyxoQLiw6fwdRySnww 1 0 0 0 208b 208b
green open .apm-agent-configuration -v2Yf0EGQ8uzZMWTmmxOgw 1 0 0 0 208b 208b
yellow open attributes Syb9orT-Svymgsaof_Gihg 1 1 0 0 208b 208b
green open .kibana_task_manager_7.12.1_001 usPc24-TRs20skx0LFU1wg 1 0 9 3964 462.1kb 462.1kb
green open .kibana-event-log-7.12.1-000001 wPefdI7DT3-Gmzc7mSG7Ng 1 0 4 0 21.8kb 21.8kb
green open .tasks 347aYjZSQLebyclocAbpqw 1 0 4 0 27.2kb 27.2kb
yellow open products 6vOvnp7XRAeQxgTIfB2zJg 1 1 0 0 208b 208b
商品的CRUD操作
PUT新增数据:
PUT /prodcuts/_doc/1
{
"name":"HUAWEI Mate Book 14",
"desc":"diannao",
"price":9999.00,
"tags":["bangong","dayouxi"]
}
返回结果:
{
"_index" : "prodcuts", --索引名称
"_type" : "_doc", --类型
"_id" : "1", --id
"_version" : 1, --数据版本
"result" : "created", --什么样的操作,有:创建,修改,删除
"_shards" : { --分片
"total" : 2, --分片数
"successful" : 1, --1个成功
"failed" : 0 --0个失败
},
"_seq_no" : 0, --文档更新一次后都会+1
"_primary_term" : 1 --文档所在主分片的编号
}
PUT /prodcuts/_doc/2
{
"name":"HUAWEI Mate Book 15",
"desc":"diannao",
"price":10000.00,
"tags":["bangong","dayouxi"]
}
PUT /prodcuts/_doc/3
{
"name":"HUAWEI Mate Book 16",
"desc":"diannao",
"price":8888.00,
"tags":["bangong","dayouxi"]
}
GET查询数据:
GET /prodcuts/_doc/1
返回结果:
{
"_index" : "prodcuts", --索引名称
"_type" : "_doc", --类型
"_id" : "1", --id
"_version" : 1, --数据版本
"_seq_no" : 0, --文档更新一次后都会+1
"_primary_term" : 1, --文档所在主分片的编号
"found" : true, --查询结果为true
"_source" : { --查询数据结果
"name" : "HUAWEI Mate Book 14",
"desc" : "diannao",
"price" : 9999.0,
"tags" : [
"bangong",
"dayouxi"
]
}
}
GET /prodcuts/_doc/2
POST修改数据:
PUT /prodcuts/_doc/1
{
"name":"HUAWEI Mate Book 14",
"desc":"diannao",
"price":11000.00,
"tags":["bangong","dayouxi"]
}
返回结果:
{
"_index" : "prodcuts",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
PUT /prodcuts/_doc/1
{
"name":"18"
}
返回结果:
{
"_index" : "prodcuts",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
POST /prodcuts/_doc/2/_update
{
"doc":{
"name":"11111111"
}
}
返回结果:
{
"_index" : "prodcuts",
"_type" : "_doc",
"_id" : "2",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
id为1的数据与id为2的数据对比:
GET /prodcuts/_doc/1
返回结果:
{
"_index" : "prodcuts",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "18"
}
}
GET /prodcuts/_doc/2
返回结果:
{
"_index" : "prodcuts",
"_type" : "_doc",
"_id" : "2",
"_version" : 2,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "11111111",
"desc" : "diannao",
"price" : 10000.0,
"tags" : [
"bangong",
"dayouxi"
]
}
}
id为1的数据我们使用的是put方式在进行修改,但是查询会发现,不带入所有的字段是没有单个字段的修改效果,它会将没有写入的字段数据删除,post相对而灵活性更好一些,在之后的修改操作中推荐大家使用post来进行修改操作。
DELETE数据:
DELETE /prodcuts/_doc/1
返回结果:
{
"_index" : "prodcuts",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号