深度学习——目标检测[12]
目录
- 目标定位/对象检测
- 特征点检测
- 基于滑动窗口的对象检测
- YOLO算法
- 其它算法
一、目标定位/对象检测
图像分类:一般图像中只有一个对象,判断图像属于哪一类
分类定位问题:找出图像中的对象并识别出对象属于哪一类(一个边界框来表示在图像中的位置)
对象检测:一般有多个对象,找出图像中的对象(一个边界框来表示在图像中的位置)
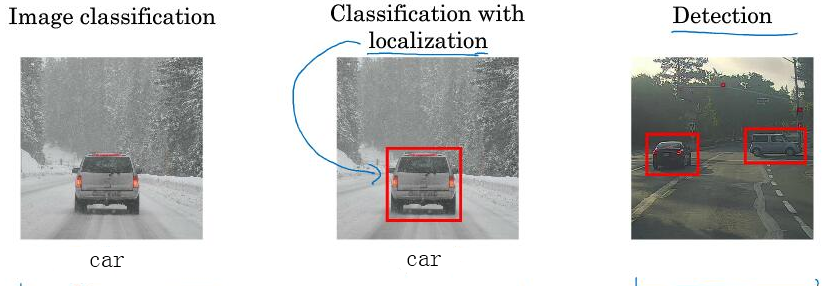
- 分类定位实例
识别图中的对象:判断属于哪一类(pedestrian, car, motorcycle, background)。background表示没有任何对象
定位对象的位置:$b_x$, $b_y$是对象所在位置的中心点,$b_w$,$b_h$是对象的大小
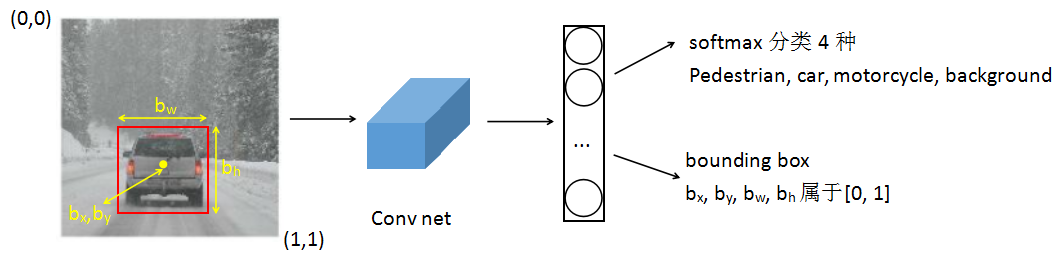
输出的label y:假设要识别的类别有3种,则label中的元素如下
| $p_c$ | $b_x$ | $b_y$ | $b_w$ | $b_h$ | $c_1$ | $c_2$ | $c_3$ |
|
是否有对象,1表示有 0表示没有(只有背景) 如果只有背景,则其他就不用关注了 |
对象中心点的x位置 | 对象中心的y位置 | 对象的宽度 | 对象的高度 | 对象属于类1的概率 | 对象属于类2的概率 | 对象属于类3的概率 |
定义loss函数: $L(\widehat{y}, y) = \sum(\widehat{y}_i, y_i)^2$
对8个结果分别求差平方和(也可以每个参数用不同函数来进行误差估计)
当pc=0时(也就是没有对象时),只关注pc的结果是否正确,其它结果不重要,loss也就只计算pc的结果
二、特征点检测landmark
通过让神经网络输出一些关键点(landmark)位置来识别一个对象。下面是一些例子
注:关键点label的表示在每张图上要一致,比如图2中总是用$l1$来表示左侧的眼角
 |
 |
 |
| $b_x, b_y, b_w, b_h$ | $l_{1x}, l_{1y}\\l_{2x}, l_{2y}\\...\\l_{64x}, l_{64y}$ | $l_{1x}, l_{1y}\\l_{2x}, l_{2y}\\...\\l_{32x}, l_{32y}$ |
三、基于滑动窗口的对象检测
例:汽车检测
训练集:对图像进行适当裁剪,把裁剪后的部分作为输入,判断是否包含车

滑动窗口检测sliding windows detection:用一个框(窗口),移动遍历图像的各区域,把框内的图像作为ConV网络的输入进行计算

滑动窗口检测问题:计算的代价太大
解决计算量大的问题:利用卷积计算共享窗口公共部分的结果以减少计算量
具体实现方式
- 把conv net中的全连接层转换为卷积层:5x5x16全连接得到400个元素—>(5x5x16)*(5x5x16)400卷积结果为1x1x400。最后输出为包含4个元素的向量,则可以看作1x1x4
- 训练数据为16x16x3,滑动窗口大小为14x14x3,步长为2
- 若单独计算,需要裁剪并依次输入网络中计算4次,而且4个窗口中的公共部分在每次计算时都会重新计算一遍(X)
- 直接对整张图进行卷积计算,最后输出的4个色块与输入的四个色块是对应的,也就是每个窗口的结果(√)
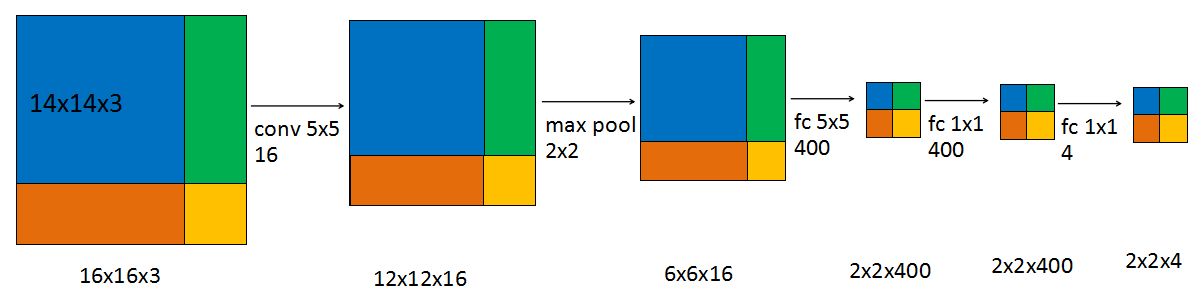
[Sermanet et al., 2014. OverFeat: Integrated recognition, localization and detection using convolutional networks]
四、YOLO算法you only look once
[Redmon et al., 2015, You Only Look Once: Unified real-time object detection]
利用卷积实现滑动窗口检测的缺点:窗口的大小位置并不一定那么准确,无法获得精确的边界
- 基本思想
把图片分成3x3(或更多)个格子,接着对每个格子执行图像分类和定位方法,每个格子有一个输出label(8个值)
-
- label中标记一个物体属于一个格子:以物体的中心点为准,中心点在哪个格子,它就属于哪个格子。如果一个格子中不包含物体的中心点,即使有很多部分落在其中,也认为该格子不包含物体
- 一个格子包含多个物体?:就是格子中有多个物体的中心点。实际中使用19x19的划分得更精细,这种情况就会更少一些
- 每个格子都要执行一次?:利用卷积,只要单次卷积即可完成。YOLO的执行速度很快,甚至可以达到实时检测
- 如何定义物体位置
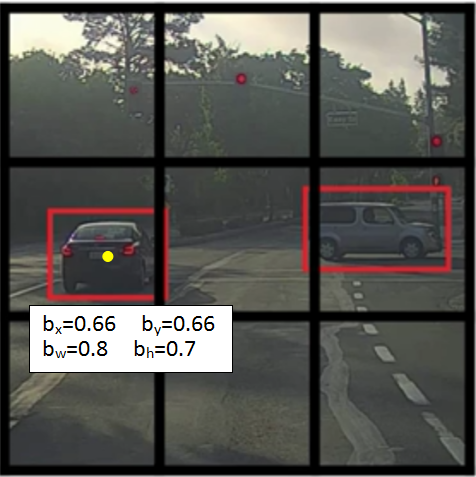 |
物体的位置是相对于它所在的格子来说,而不是整个图像。中心点的值在(0, 1),而宽高取值可以大于1 |
- 如何评价物体检测算法是否正确
交并比IoU:intersection over union,就是两个区域交集与并集的比,一般规定0.5以上就说明结果是正确的,也可以定得更高
 |
IoU=实际大小的黄色区域/检测出来的绿色区域大小 |
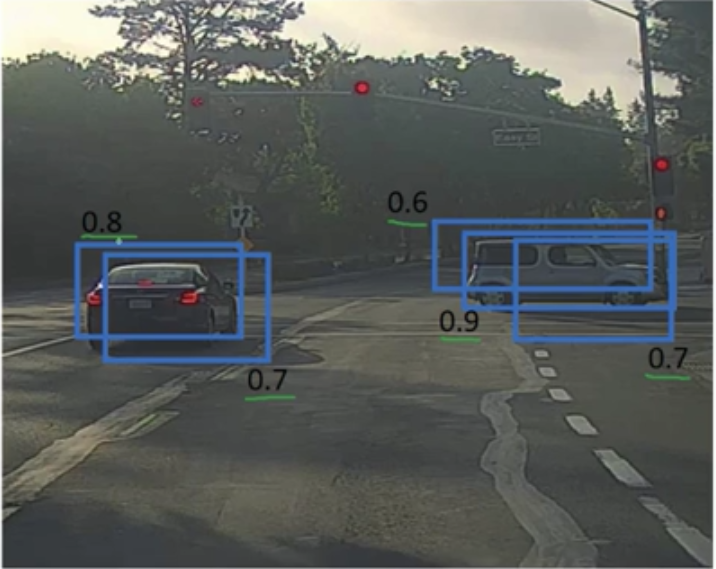
- 一个物体被多个格子检测的问题
问题:如果对一个图像划分19x19格,每个格子都有可能说自己包含了一个对象(如车子),也就是一个车子被多个格子检测
non-max suppersion:非最大抑制算法
|
|
(如果有多种物体则每种执行一次non-max) 执行算法得到结果:[$p_c$ $b_x$ $b_y$ $b_h$ $b_w$] 剔除所有$p_c<threshold$,也就是包含物体的概率小于限值的格子 while 还有格子没有判断过 找出$p_c$最大的格子 抑制与上一步格子$IoU \geqslant 0.5$的格子 |
- 一个格子包含多个物体的中心点的问题
基本思想:定义多种anchor box形状,在输出标签中包括了这些anchor box,检测到一个物体的话,既要看它的中心点位置,还要看它和哪个anchor box的IoU最高来决定
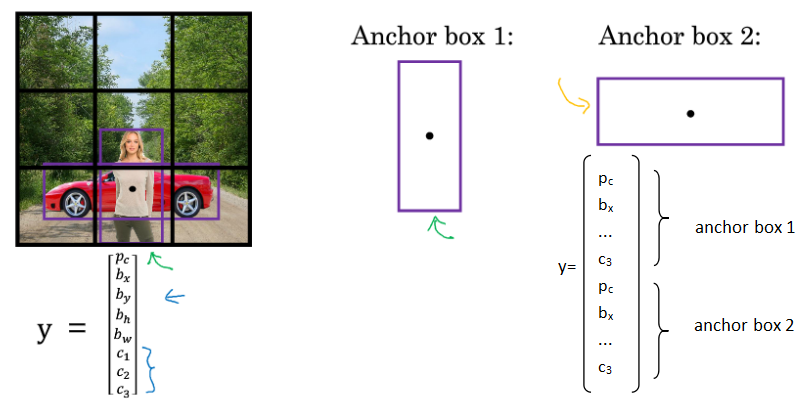
问题:如何选择anchor box的类型; 如果给了两个anchor box,但是有三种形状的话,算法效果不好;事实上,如果格子多一些,一个格子有多个物体的问题就会少一些
五、其它算法
R-CNN:region with CNN
思想:对图像进行分割,接着从中选取候选区域再执行算法,而不是对整个图像所有区域计算(因为有些区域没有必要检测,如左下角位置不可能存在物体)
在计算机视觉领域用的比较多
[Girshik et.al, 2013, Rich feature hierarchies for accurate object detection and semantic segmentation]

Fast R-CNN:利用滑动窗口的卷积实现来区分预设的区域
[Girshik, 2015, Fast R-CNN]
Faster R-CNN:用卷积网络来找出预设的区域
[Ren et. al, 2016. Faster R-CNN: Towards real-time object detection with region proposal networks]

