深度学习——优化算法[6]
目录
- mini-batch
- 指数加权平均
- 优化梯度下降法:momentum、RMSprop、Adam
- 学习率衰减
- 局部最优问题
一、mini-batch
mini-batch:把训练集划分成小点的子集
| 表示法 | $x^{\{1\}}$ | $x^{(1)}$ | $x^{[1]}$ |
| 意义 | 第一个mini-batch | 第一个样本 | 第一层的输入 |
- 为什么用mini-batch:当数据集样本数较多时,需要对整个数据计算完成后才能进行梯度下降,速度较慢
- epoch:一代,表示遍历了整个数据集(而不是一个子集)
- 使用mini-batch的梯度下降方法过程:每次以当前的一个mini-batch作为输入数据
|
for $t = 1,...,5000$ //forward prop on 第t个minibatch,输入为$X^{\{t\}}$ for $i=1...l$ //正向计算,共l层 $Z^{[i]}=W^iA^{[i-1]}+b^{[i]}$ $A^{[i]}=g^{[i]}(Z^{[i]}$ //$A^{l}$为最后的输出结果 计算该mini-batch的cost $J^{\{t\}}=\frac{1}{1000}\sum \mathcal{L}(\widehat{y}^{j},y^{j})$ 反向计算求导$J^{\{t\}}$ 更新参数$W$$b$,$W^{[l]}:=W^{[l]}-\alpha dW^{[l]}$ $b^{[l]}:=b^{[l]}-\alpha db^{[l]}$ |
- 使用mini-batch的成本函数变化趋势:并不是每一次都下降,但是整体趋势是下降
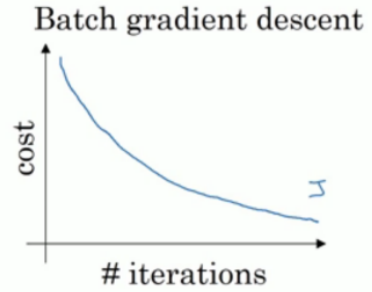
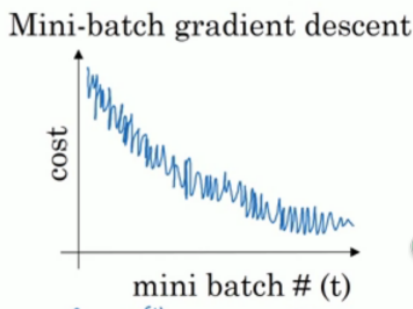
- 选择min-batch的大小
太大的话每次迭代耗时太长,太小的话每次只处理少量效率低(失去了向量加速的优势)
当数据集比较小(小于2000)时,可以直接使用batch
当数据集比较大时,一般可以用的mini-batch大小:64,128,256, 512...(与CPU/GPU内存相匹配)
二、指数加权平均(指数加权移动平均)exponentially weighted average
例:伦敦的温度变化
|
$\theta_{1}=40^{\circ}F$ $\theta_{2}=49^{\circ}F$ $\theta_{3}=45^{\circ}F$ ... |
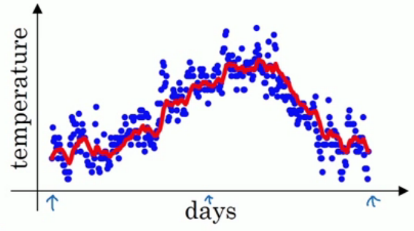 |
求解$v_{t}$:前$t$天的温度加权平均值。虽然$v_{t}$包含1~$t$天的温度,但是越接近第$t$天的权重会更大一点,而较前的就会接近0
|
$v_{0}=0$ $v_{1}=\beta v_{0} + (1-\beta )\theta_{1}$ $v_{2}=\beta v_{1} + (1-\beta )\theta_{2}$ ... $v_{t}=\beta v_{t-1} + (1-\beta )\theta_{t}$ $=\beta^{t}\theta_{0}+\beta^{t-1}(1-\beta)\theta_{1}$ $+\beta^{t-2}(1-\beta)\theta_{2}+...+(1-\beta)\theta_{t}$ |
蓝色点为原始数据,其它为不同的$\beta$取值时,加权平均结果 |
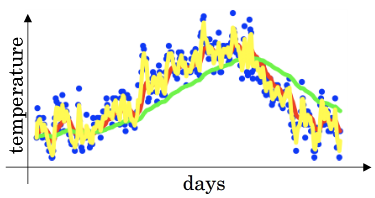
- 应该平均多少天的温度?当某天温度的权重很低时就不用再考虑
$y=(1-\varepsilon)^{\frac{1}{\varepsilon}}$单调递减。当$\varepsilon=0.9$时,$y \approx \frac{1}{e}$。所以,当计算到第$\frac{1}{e}\approx 0.3$天时,温度会下降到当天的1/3以下,可忽略。因此,可以认为$v_{t}$是$\frac{1}{1-\beta}$天的温度加权平均值
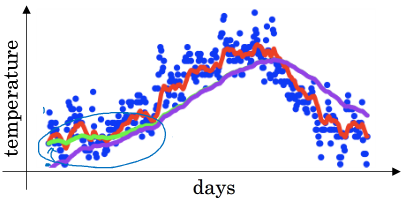
- 做偏差修正bias correct
为什么需要:开始的时候设置$v_0=0$,容易导致前期的预测会比较实际的小很多,估计不准确
修正方法:$v'_{t}=\frac{v_{t}}{1-\beta^{t}}$,用$v'_{t}$来代替$v_{t}$。前期的值可以变大一些,而后期时$t$较大时,$\beta^{t}$趋于0,$v'_{t}$也就趋于$v_{t}$
下图中紫线为$v_{t}$,绿色为$v'_{t}$
三、优化梯度下降算法
- 标准梯度下降的问题(下图蓝线效果):从一个随机的点开始进行梯度下降,可能会像蓝色部分波动比较大,下降速度慢;无法使用更大的学习率,因为可能会偏离函数范围

-
- 优化手段:减少纵向的浮动,加快横向的移动,以及增大学习率
- 动量梯度下降法momentum
- 优化:利用对梯度求指数加权平均的方法以加快训练的速度(上图红线效果)
通过求平均,可以把纵向的浮动抵消,而横向的变化依旧,从而加快下降速度
- 具体实现:用加权平均值来代替当前的求导结果;实际中一般不用做偏差修正,大概10次迭代就过了初始期,不再是有偏差的结果;$\beta$取值为0.9
for $t = 1...,$
计算当前mini-batch的$dW, db$
$v_{dW}=\beta v_{dW}+(1-\beta)dW$
$v_{db}=\beta v_{db}+(1-\beta)db$$W:=W-\alpha v_{dW}$, $b:=b-\alpha v_{db}$
- 优化:利用对梯度求指数加权平均的方法以加快训练的速度(上图红线效果)
- RMSprop : root mean square prop
- 均方根:先对$dW$求平方,更新时又除以它的根方
- 为什么有效果
假设$W$和$b$分别表示横向和纵向变化。
如果要让纵向也就是$b$的变化慢一点(浮动小一些),也就是更新时减去的值小一些。可以发现原来纵向的变化较大($db$较大),所以$\frac{1}{\sqrt{S_{db}}}$会小一点,由此可让$db$变化慢点
-
- 具体实现:为了避免除数为0,一般可以加上$\varepsilon=10^{-8}$
|
for $t = 1,...$ 计算当前mini-batch的$dW,db$ $S_{dW}=\beta_{2}S_{dW}+(1-\beta_{2})dW^{2}$ $S_{db}=\beta_{2}S_{db}+(1-\beta_{2})db^{2}$ $W:=W-\alpha \frac{dW}{\sqrt{S_{dW}}+\varepsilon}$, $b:=b-\alpha \frac{db}{\sqrt{S_{db}}+\varepsilon}$ |
- Adam算法 :momentum与RMSprop的结合,常用的方法
- 具体实现
|
$for t = 1,...$ 计算当前mini-batch人$dW,db$ //momentum部分 $v_{dW}=\beta_{1} v_{dW}+(1-\beta_{1})dW$, $v_{db}=\beta_{1} v_{db}+(1-\beta_{1})db$ //RMSprop部分 $S_{dW}=\beta_{2}S_{dW}+(1-\beta_{2})dW^{2}$, $S_{db}=\beta_{2}S_{db}+(1-\beta_{2})db^{2}$ //偏差修正 $v^{corrected}_{dW}=\frac{v_{dW}}{1-\beta_{1}^{t}}$,$v^{corrected}_{db}=\frac{v_{db}}{1-\beta_{1}^{t}}$ $S^{corrected}_{dW}=\frac{S_{dW}}{1-\beta_{2}^{t}}$, $S^{corrected}_{db}=\frac{S_{db}}{1-\beta_{2}^{t}}$ //更新 $W:=W-\alpha \frac{v_{dW}^{corrected}}{\sqrt{S_{dw}{corrected}}+\varepsilon}$, $b:=W-\alpha \frac{v_{db}^{corrected}}{\sqrt{S_{db}{corrected}}+\varepsilon}$ |
-
- 超参数选择
| $\alpha$学习率 | $\beta_{1}$用于momentum | $\beta_{2}$用于RMSprop | $\varepsilon$ |
| 需要调 | 0.9 | 0.999 | $10^{-8}$ |
四、学习率衰减:随时间逐渐减少学习率
为什么:如果一直用比较大的学习率,当靠近最小值时,结果可能会在较大范围内进行浮动(不易收敛),而不是在很接近最小值的小范围内变化
重要性:不是最开始的重点,可以先设置一个固定的,先调整其它的,后期再进行调整
学习率衰减的方式
- $\alpha = \frac{1}{1+decay-rate*epoch-num}\alpha_{0}$
- $\alpha=0.95^{epoch-num}\alpha_{0}$ 指数衰减
- $\alpha=\frac{k}{\sqrt{epoch-num}}\alpha_{0}$
- 每过一段时间,对学习率减半(离散下降discrete staircase)
五、局部最优问题
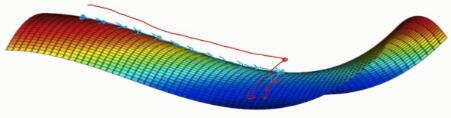
- 局部最优问题:在做梯度下降时,会不会最后是趋于局部最优的解,而非最优解?
- 答:这不是一个大问题,要找到一个局部最优点,需要它在各个维度都是最优的(比如都是凹/凸)。当维度比较大时,这种情况很难遇到。不过,鞍点还是比较容易遇到的
- 鞍点:在某个位置,各维导数均为0,但是凹凸性不是完全一致的。如下图右侧
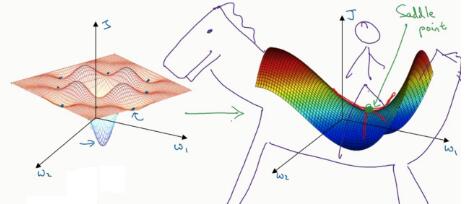
- 应该考虑的问题:存在平滑导致梯度下降变化慢的问题
- 解决方法:利用上面提到的几种优化方法来加快