Demystifying C++20 Coroutines
许久未在这儿写文章了,从公众号搬几篇原创过来,感兴趣的可以去关注一波。
0. 前言(Introduction)
这篇文章构思了许久。
初时不知从何写起,协程的背后是整个并发,所涉知识极多,对于标准C++来说,也算是一个新概念。
思忖良久,欲以几篇而述之,便先起手了此「概念篇」。
了解C++的会发现自C++11开始,很多更新都集中在并发支持上。
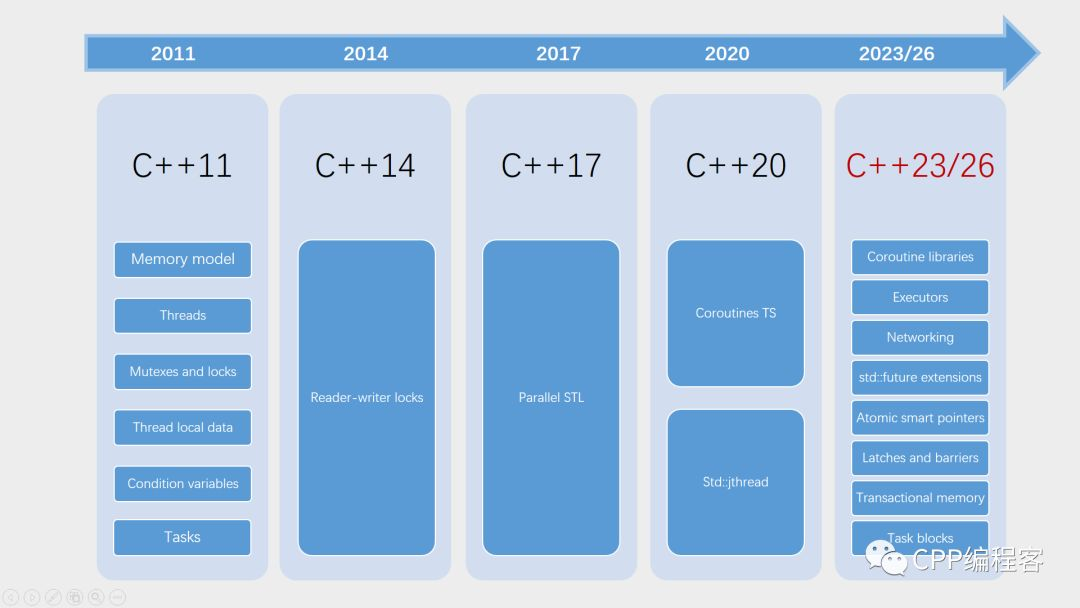
从最初的线程基础支持,到如今的协程,C++已经日趋完善。
协程便是线程之后的又一利器,若论年龄,协程倒比线程要大。由于早期的线程主要在单CPU上运行,仅是模拟多线程,故又称“伪线程”。伪线程和协程的思路颇有相似之处,以致难以旌别。
其实线程和协程之间不分轩轾,各有其应用场景。具体辨别,见本文第1,2节。
可能有人只想知其用法,不愿细琢概念。但所谓“勿在浮沙筑高楼”,概念不清,必会偏见多疑,难为准的。唯有纤悉洞了,小大靡遗,开扩来学,臻乎无惑,尚能步步衔进,独览众山。
本篇将回答下列问题:
- 什么是协程?
- 协程与进程和线程有何区别?
- 什么是并发,和并行有何区别
- 协程和函数有何区别?
- 什么是有栈协程,无栈协程?
- 协程的使用场景有哪些?
- Coroutines TS是什么?
本篇旨在明析概念,所以不会出现太多代码。概念清晰后,下篇将有大量代码来解析协程。
1. 并发与并行(Concurrency versus Parallelism)
要理清协程的定位,须得先能够旌别并发与并行。
可以先来看看百科的定义:
并行是指“并排行走”或“同时实行或实施”。
在操作系统中是指,一组程序按独立异步的速度执行,无论从微观还是宏观,程序都是一起执行的。
对比地,并发是指:在同一个时间段内,两个或多个程序执行,有时间上的重叠(宏观上是同时,微观上仍是顺序执行)。
这里用了两个词:宏观和微观。宏观指从大的角度来看,微观指从小的角度来说。
通俗地说,宏观指的是能够通过眼睛看到的,微观则是眼睛看不到的。
并发在宏观上同时,微观上为顺序执行。这就是伪线程的实现思路,通过迅速地在各个模块之间切换执行,以迷惑视觉,使得看起来像是同时执行的,其实底层依旧是顺序执行的。
线程在早期并非必须,因为都是命令窗口,就是从上往下依次执行的。而Windows拥有界面,在执行任务之时可以随意进行别的操作,因此界面常常会卡死。
ms便搞了个模拟同步运行的机制,便是线程。了解过CPU发展历史的会知道,早期CPU频率步步直升,人们都以为这种趋势能够持续下去。这意味着你写的程序不用更新也能随着CPU的增强而自动增强性能。
所以早期都是单核CPU。随着物理瓶颈到来,频率提升之路越来越艰难,生产厂商便转变策略,通过将多个核心置于一起,产生多核CPU来提升性能。这便是性能不够,数量来凑。
也因此,真正的多线程得以实现。
真线程的执行便为并行执行。由于每个核心都是独立的,因此可以同时执行。此时,无论是视觉上,还是底层实现上,都是真正的同时执行。
既然有并发与并行两种形式,那么我们对其进行排列组合,便能得出4种结果。
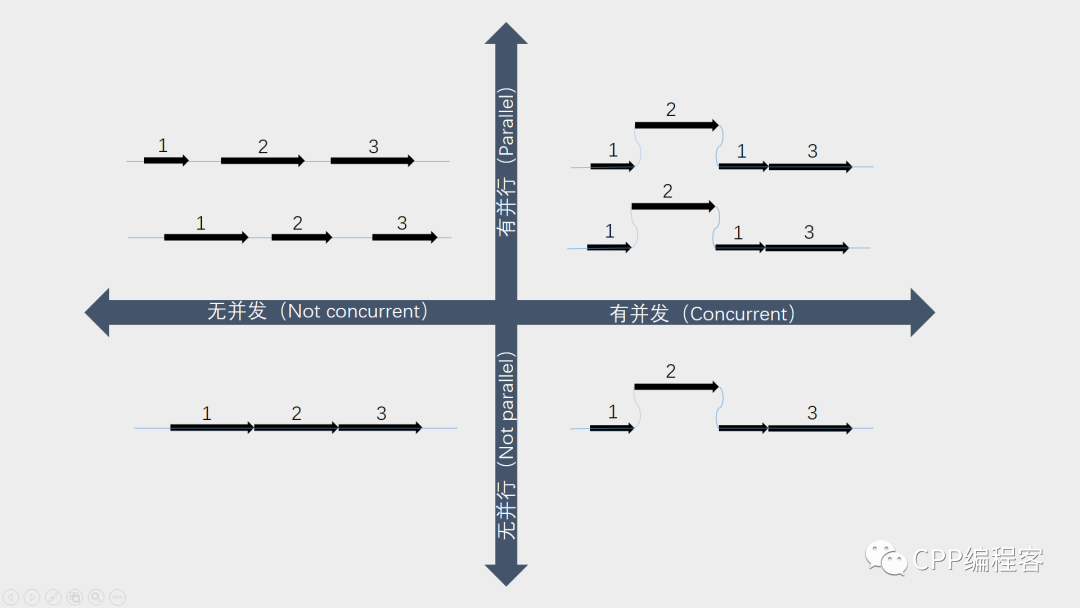
一个既无并行,也无并发的程序处于并发的能力最弱,只能顺序执行每条任务,这一般是一个很小的程序。
当有并发,无并行时,能够充分发挥单核CPU的性能,伪线程与协程便属此列。
而无并发,有并行时,也就是说是多核CPU,但一个核心上只开了一个线程,此时的确是并发。但和有并发无并行时所达到的效果是一样的,真线程便属此列。
也正因如此,线程和协程的效果只用眼睛是无法分辨的。有很多人便说有了多线程了为啥还要加入协程呢?其实线程和协程分工并不同,一个是并发,一个是并行,不过伪线程也属于并发罢了。
那现在你可能又要改变问题了,既然伪线程也是并行,那么请问协程和伪线程又如何区分?
这个问题才是关键,起初听说协程时,我便疑惑既然和伪线程一样,为啥还要协程呢?其实主要区别是调度问题,本文第3节将详论。
只有并发,或只有并行,都无法处理高并发需求,所以二者呈互补之势,共同发挥CPU的最大性能。
下面再以一个例子来谈谈并发与并行。
假设有一个迷宫,
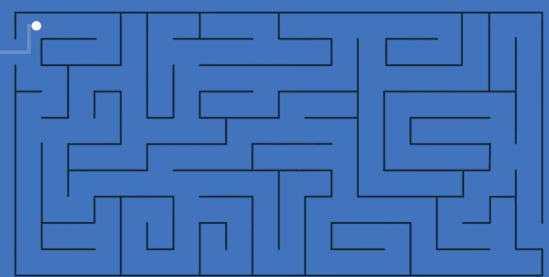
现欲寻得迷宫出口,便有四种方式。
在无并发无并行的情况下,只能暴力式的遍历每条路径。因此,在发现一条路不通时,需要原路返回到分岔路口,以接着尝试另一条路径。这意味着很多条路径都要走两次,效率可想而知。
在无并发有并行的情况下,便意味着有多人在同时寻找出口,即使其中一个人走的是死角,其他人亦可继续自己的任务。
如此一来,每条路便只需走一遍。当然,这也意味着所耗费的资源也更多,此处对应的便是人力,在计算机中,对应的便是CPU核心数。
核心数无法持续增加,所以此处便有些是理想状态了,实际情况可能得一人负责多条路径。也就是说一个核上分成多个线程,此时便是真伪线程混合,并发与并行混合了。
那么只有并发是什么情况呢?
这时的情况是这样的:一个人先走一部分,接着其他人再走,因为是并行执行,所以这些人无法同时行走。其中一个人走一会儿,停下来,其他人才能接着走。
这样的好处是什么呢?
好处是即使一个人走入死胡同,也无需再原路返回。
什么意思呢?简单地说,当每个人停止行走时,都需要转到其他人那里去执行。他怎么瞬间跑到其他人那里去呢?其实每个人在跳转之前,都会在原地插一个眼做标记,当需要跳转时,便可直接传送过去。
所以在一个人步入死角时,便会放弃这条路,传送到其他人那里继续执行。最后留下的一个人,便是正确的迷宫出口。
和并行不同,并发所需的资源要少,可以开启上亿个协程行动,他们之间互相协作,无论多大的迷宫,也能很快找到出口。
最后,并行与并发结合,无疑会指数级提升性能,因为并发说到底同时还是只有一个人能行动,而并发能同时多人行动,两者互补,才能发挥出最大效率。
2. 量子计算(Quantum computation)
上述所说的统一称为「经典计算」。既然谈到了并行,便不得不再说下「量子计算」了。
通过上面介绍,可知「经典计算」要增加计算能力,先是尝试提高处理器频率,无奈达到了物理瓶颈。于是便增加物理资源,用数量来凑。
然而,这样的方法来增加计算能力同样是不可持续的,而且增加核心要消耗更多的物理资源。
第一个分岔路口需要2个人,第二个便要4个人,接着便要8个,16个,32个……
这个数字是呈指数增长的,要不了多久,便成了天文数字。
这也是现如今许多密码学加密技术的依赖,通常数字都会非常大,计算机跑几十年可能都跑不出来。这就是经典计算的瓶颈,理论上不可达。
经典计算的算力只能线性增加,而问题规模却是指数增长的,所以经典计算根本追不上。
而量子计算则不同,随着量子比特的增大,其信息容量也会呈线性增长。
像上面的迷宫,若是由量子计算来遍历会如何做呢?
比如其有10个人,那么便能同时分出1024个分身,这样所有的路径都能被搜索到,只需走一次,就能找出迷宫出口。这被称为量子叠加态的并行演化。
同时,量子还有另一个特性——纠缠性,可以解决我们在开发并行程序时需要格外观注的数据竞争问题,通常都需要通过锁或原子量来同步数据。
而量子纠缠天生就带有同步性,一个数据被改变了,不论别处还有多少个数据,瞬间全部都会改变。比如有一个分身死了,那么1024个分身便全死了。
所以面对暴力计算,量子计算都只表示笑笑不说话。不过量子计算还在继续发展,现在,我们只能使用经典计算来写并发程序。
3. 协程(Coroutines)
注:本节介绍的协程不具体指某一语言中的,示例亦为伪码,C++20的协程将于第6节介绍。
弄清楚了并发概念,便可以开始讲协程了,先来看看wiki上的定义:
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing execution to be suspended and resumed. Coroutines are well-suited for implementing familiar program components such as cooperative tasks, exceptions, event loops, iterators, infinite lists and pipes.
简言之,协程,用于实现协作式多任务,属于同一个进程的多个协程,在同一时刻只有一个处于运行状态。
协程属于并发形式的一种创建方式。
协程由两部分组成的:
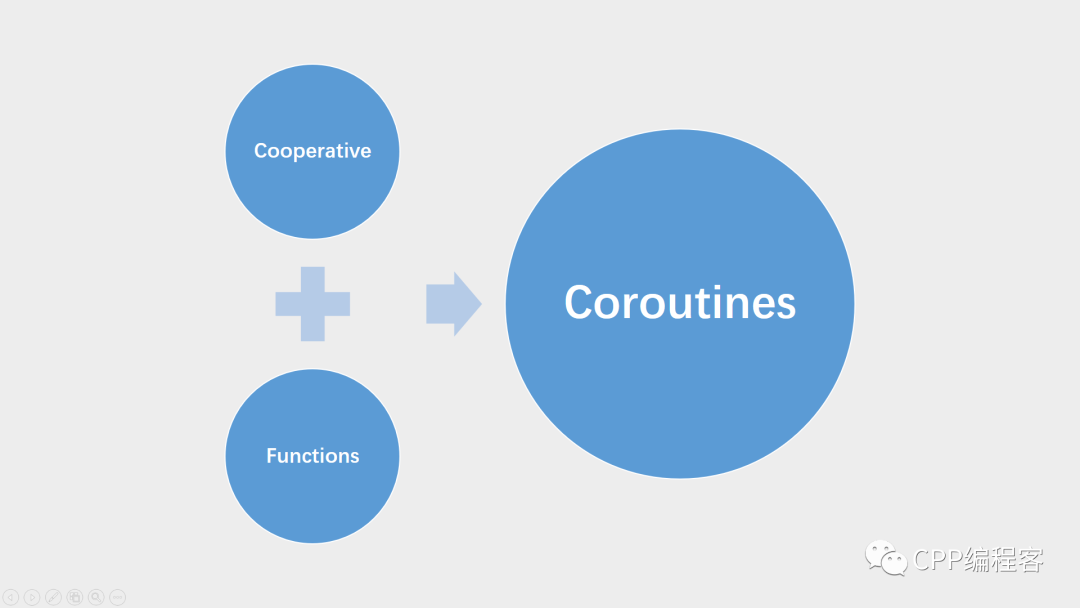
可以说,函数(Functions)之间拥有了协作(Cooperative)的能力,便称之为协程(Coroutines)。
比如,现有一个普通的函数:
auto happy()
{
return ": )"; // 在此处传值并退出函数
}
auto emoji = happy(); // 在此处调用函数
此函数返回一个字符串,可以直接进行输出。当调用函数时,只能等到函数执行结束才算结束调用。
现在对表情进行扩展,
void emoji()
{
vector<string> emoji { ": )", ": (", "^-^", "@_@", "=^=" };
for(auto p = emoji.begin(); p != emoji.end(); ++p)
{
cout << *p << " ";
}
cout << endl;
}
现在,我们想在不改变该函数的情况下进入如下输出:
1. : )
2. : (
3. ^-^
4. @_@
5. =^=
于是需要引出另一个函数:
void add_lines()
{
for(int i = 1;; ++i)
{
cout << i << ": ";
cout << endl;
}
}
可是,即使如此,依旧无法得到想要的输出。此时,只有这两个函数互相协作才能完成任务。

注意这两个函数的执行顺序,他们是交叉执行的,而非像普通函数那样调用后执行完直接返回。
这里有几个关键点,
第一,被调用函数(emoji)需要知道调用函数(add_lines)的返回地址,这样才能在输出后再跳回到调用方继续执行。
第二,调用方和被调用方需要记住先前局部变量的值,用于在下一次执行时恢复现场。
第三,被调用方可以主动让出控制流,以让调用方恢复执行。
实际上,协程本质上就是对控制流的主动让出和恢复机制,这也是其与函数之间的区别。
协程是函数的增强版,函数是协程的弱化版。
函数只能启动(start)和终止(finish)执行,而协程在此基础上,增加了挂起(suspend)和恢复(resume)能力。
那么如何完成上述流程呢?
可以来增加挂起和恢复机制:
// 伪码表示,仅作说明之用
struct coro_frame {
using iter_type = vector::iter;
iter_type iter;
int index;
resume() {
switch(index) {
case 0:
goto flag_r0; // 从flag_r0恢复执行
default:
goto flag_default;
}
}
};
coro_frame* emoji()
{
void* handle = CORO_BEGIN(malloc); // 分配状态所需的空间
coro_frame* frame = (coro_frame*)handle; // 转换为frame
vector<string> emoji { ": )", ": (", "^-^", "@_@", "=^=" };
for(frame->iter = emoji.begin(); frame->iter != emoji.end(); ++frame->iter)
{
frame.index = 0; // 记录暂停点
CORO_SUSPEND(handle); // 暂停执行,挂起协程
RETURN_OBJECT(frame); // 返回控制句柄,以便从外部恢复
flag_r0:
print(frame->iter);
}
println();
CORO_END(hdl, free); // 协程结束,销毁申请的空间
}
void add_lines()
{
auto frame = await emoji();
for(int i = 1;; ++i)
{
println(i);
frame.resume();
println();
}
}
可以看到我们对原有代码添加了许多额外代码来满足挂起恢复的能力,实际上编译器在生成协程时也会有这样的操作,不过那是一个非常完善的机制了。
相信通过上述内容,大家已经对协程有了大致的印象,那么本节的任务也就完成了。
3.1 有栈协程(Stackful Coroutines) and 无栈协程(Stackless Coroutine)
函数在调用之前会将所需的参数压入栈中以供使用,局部的数据也都保留在栈中,这一系列所需的数据称为状态(state),需要在调用方和被调用方之间来保存这些状态,才能完成函数的调用和返回动作。
协程也需要保存一些状态,而且因为要支持挂起和恢复功能,所以要保存的状态也要比函数多。协程需要保存如下状态:
- Promise对象
- 各个形参
- 当前挂起点的位置,以便恢复时跳转
- 局部变量和临时量
此时,便会有不同方式来保存这些状态。主流的两种,一种是有栈协程,另一种是无栈协程。
有栈协程,如其名,将数据保存在栈中;而无栈协程,会将主要数据采用堆来动态分配,只有少量状态存放在栈上,此时只能挂起处于停层的函数。
有栈协程的生命期和它们的栈一样长,无栈协程的生命期和它们的对象一样长。
有栈协程的数据在被调用方分配,而无栈协程的数据在调用方分配。
关于此二者的区别,已经有文章详细地描述了,所以我便不再重复写了。大家可以参考这篇文章:https://blog.panicsoftware.com/coroutines-introduction/
其实现在了解与否并无关紧要,只需记往C++20的协程是无栈协程便好了。
4. 进程、线程和协程的区别(Distinguish between process, thread and coroutine)
关于进程线程,过去已经写过一些文章了,我便不再详细介绍。
关键是需要弄清楚并发和并行的区别,这也在文章开始详细介绍了。
现在,只需下表的对比,就能清晰地了解这三者之间的关系与差别。
| 进程 | 线程 | 协程 | |
|---|---|---|---|
| 切换者 | 操作系统 | 操作系统 | 用户(编程者/应用程序) |
| 切换时机 | 根据操作系统自己的切换策略,用户不感知 | 根据操作系统自己的切换策略,用户不感知 | 用户自己(的程序)决定 |
| 切换内容 | 页全局目录 内存栈 硬件上下文 |
内核栈 硬件上下文 |
硬件上下文 |
| 切换内容的保存 | 保存于内核栈中 | 保存于内核栈中 | 保存于用户自己的变量(用户栈或者堆) |
| 切换过程 | 用户态-内核态-用户态 | 用户态-内核态-用户态 | 用户态(没有陷入内核态) |
| 切换效率 | 低 | 中 | 高 |
正是因为进程和线程的上下文切换效率低,所以才加入了协程来提高并发的能力。
5. C++20 Coroutines TS
5.1 初识C++协程
由前所述,我们知道协程是一个分步执行,遇到条件会挂起,直到满足条件才会被唤醒以继续执行后面代码的并行方式。
C++准备了许久,终于在今年加入了协程。
不过C++20的协程标准仍处于「原理层」,只包含了编译器需要实现的底层功能,是专门给库开发者使用的,并没有提供属于「应用层」的高级库给普通程序员使用。
这意味着要想使用协程,要么自己从原理层学起,自己封装所需的功能,要么等待C++23的标准协程库或第三方库。
我们自然选择前者,因此要学习的东西就比较多了,本篇就是先带大家入协程的门,后面再层层深入。
C++20提供了三个新的关键字来支持协程,
- co_await
- co_yield
- co_return
co_await可以挂起和恢复函数的执行,是主要需要学习的一个关键字。
co_yield可以在不结束协程的情况下从协程返回一些值。因此,可以用它来编写无终止条件的生成器函数。
co_return允许从协程返回一些值,不过这需要我们稍加定制。
只要一个函数中包含了上面三个关键字中的任意一个,那么这个函数就是一个协程。
比如一个生成器函数:
generator<int> generate_numbers(int begin, int inc = 1)
{
for(int i = begin;; i += inc)
co_yield i;
}
因为generate_numbers函数中包含了co_yield关键字,所以它就是一个协程。
你也许已经看到,该协程没有结束条件,因此它可以无限地产生值。
但就此一点代码可还无法完成工作,稍后再来完善它,在此之前,还需了解几个重要的组件。
5.2 Custom Coroutine Functor and Custom Promise
我们已经知道可通过co_yield来挂起协程,但是挂起之后又该如何恢复呢?
因此,需要有一种方式可以和协程进行沟通,当协程挂起的时候,可以通过这种方式来进行恢复。
这种方式便是Custom Coroutine Functor(定制协程函数/仿函数),前面所写生成器的返回类型generator便是我们对于生成器所定义的Coroutine Functor。
注:前面使用了协程关键字的generate_numbers也叫协程函数,为避免和此处的Coroutine Functor翻译混淆,本文中所有协程函数都指前者,Coroutine Functor均以英文出现。
现在,来定义它:
template <typename T> class generator
{
public:
// 恢复协程
bool resume();
};
在该Coroutine Functor中,声明了用于恢复协程的resume函数。
现在,进行编译程序,可以获取如下错误:

编译器告诉我们,promise_type不是generator的成员,因此,在Coroutine Functor中需要遵循一些规范。
我们需要在成员中加入promise_type,这个东西称为Promise对象,需要定义以下接口:
- get_return_object
- initial_suspend
- final_suspend
- return_void
- un_handled_exception
当使用协程函数
auto nums = generate_numbers(1);
时,首先会挂起当前执行点,此时便会调用initial_suspend。
接着,通过get_return_object将Coroutine Functor返回给调用方,因此在稍后才能进行恢复。
当遇到未处理的异常时,便会调用un_handled_exception,可以在此进行捕获。
结束时,会调用用return_void,来到final_suspend,协程结束,Coroutine Functor析构。
由这些接口可知,协程通过Promise对象来提交结果或返回异常。
现在来实现这些接口,
template <typename T> class generator
{
public:
struct promise_type {
using coro_handle = std::experimental::coroutine_handle<promise_type>;
auto get_return_object() {
return coro_handle::from_promise(*this);
}
auto initial_suspend() { return std::experimental::suspend_always{}; }
auto final_suspend() { return std::experimental::suspend_always{}; }
auto return_void() {}
void un_handled_exception() { std::terminate(); }
};
bool resume();
};
现在,接口俱以实现。我们又发现其中又有几个新东西:
- coroutine_handle
- suspend_always
进行下一步之前,需要先了解其概念。
5.3 Coroutine handle
Promise对象从协程内部操纵,用于提交结果和异常。
而Coroutine handle(协程句柄)则从协程外部操纵,专门用于管理协程上下文,可以恢复或销毁协程。
和Promise对象不同,Coroutine handle在标准文件已经定义,
template <>
struct coroutine_handle<void>; // no promise access
template <typename _PromiseT>
struct coroutine_handle : coroutine_handle<>; // general form
可以看到,有两个形式,一个void特化版和一个通用形式。
Coroutine handle主要包含了以下几个重要成员:
- static coroutine_handle from_address(void*)
- void* address()
- void operator()()
- explicit operator bool()
- void resume()
- void destroy()
- bool done()
Coroutine Functor的恢复操作其实就是通过Coroutine handle的resume函数进行恢复协程的,拥有了它,也就拥有了控制协程的能力。
既然Coroutine Functor这么重要,那么如何为我们的Coroutine Functor配备上呢?
首先,编译器如何把Coroutine Functor给我们?
想要就得主动点,因此要在promise_type中自己先定义一个co_handle类型:
struct promise_type {
using coro_handle = std::experimental::coroutine_handle<promise_type>;
auto get_return_object() {
return coro_handle::from_promise(*this);
}
...
由此,我们的就给promise_type配上了Coroutine handle,通过from_promise函数,可以从promise来创建Coroutine handle。也可直接使用return generator{};。
之后,调用get_return_object函数便能得到匹配的Coroutine handle。
前面说过,Promise对象是从协程内部操纵的,因此get_return_object函数其实是给编译器调用的。
那么搞了半天,我们要怎么用呢?
当协程首次挂起时,编译器便会使用operator new分配空间,保存当前作用域内的各种信息,以在恢复时使用。
之后便会调用get_return_object(),并将此结果返回给调用方,也就是Coroutine Functor。
因此,我们需要在那时进行保存。
template <typename T> class generator
{
public:
struct promise_type {
...
};
using coro_handle = std::experimental::coroutine_handle<promise_type>;
generator(coro_handle handle) : handle_(handle) { assert(handle_); }
generator(const generator&) = delete;
generator(generator&& other) : handle_(other.handle_) { other.handle_ = nullptr; };
~generator() { handle_.destroy(); }
bool resume() {
if (!handle_.done())
handle_.resume();
return !handle_.done();
}
private:
coro_handle handle_;
};
可以看到,编译器实际上调用了我们的构造函数,因此,必须提供Coroutine handle类型的构造函数。
之后,便可对协程进行操控。可以看到,经可以使用resume()函数来恢复协程了。
5.4 Awaitable object
Awaitable object叫作可等待的对象,或者应该说是拥有等待属性的对象。
何时挂起,何时恢复,一定根据一个条件来决定。比如,当服务器接收数据时,在等待数据的时候便挂起,去执行别的逻辑。待数据到来,便恢复接收数据的操作。
这个对于条件的抽象便是Awaitable object,需要满足三个接口:
- bool await_ready()
- void await_suspend(coroutine_handle<>)
- auto await_resume()
每次调用co_await时,便会调用await_ready()来查看是否已满足条件,满足则表示万事俱备,则编译器会调用await_resume()恢复协程;若条件尚未完成,则会调用await_suspend()挂起协程,将控制权返还给调用者。
标准中提供了两个trival Awaitable object,
suspend_never
{
bool await_ready() { return true; }
void await_suspend(coroutine_handle<>) {}
auto await_resume() {}
};
suspend_always
{
bool await_ready() { return false; }
void await_suspend(coroutine_handle<>) {}
auto await_resume() {}
};
suspend_always的await_ready()总是返回false,suspend_never的await_ready()总是返回true。
通常情况这两个已经可以满足需求了,但也有很多情况需要自己编写特定版本,这些放到下篇专门来介绍。
5.5 Coroutine traits
回到生成器的协程函数:
generator<int> generate_numbers(int begin, int inc = 1)
{
for(int i = begin;; i += inc)
co_yield i;
}
编译器需要从返回类型generator
所以我们的协程函数的Promise类型将被推导为:
std::coroutine_traits<generator<int>, int, int>::promise_type
5.6 co_yield && co_await && co_return
到此为止,大家基本上已经了解这三个关键字的概念了。
接下来将继续完成co_yield所完成的生成器并介绍co_return,co_await是协程的关键角色,放到下篇专门来论。
因为要使用co_yield,所以还需给Promise增加一个yield_value接口:
template <typename T> class generator
{
public:
struct promise_type {
...
T value_;
auto yield_value(T value) {
value_ = value;
return std::experimental::suspend_always{};
}
};
};
yield_value用于保存数据到Promise中,取出操作也得自己定义:
template <typename T> class generator
{
public:
struct promise_type {
...
T value_;
// 保存生成的值
auto yield_value(T value) {
value_ = value;
return std::experimental::suspend_always{};
}
};
...
// 获取生成的值
const T get_generated_value() {
return handle_.promise().value_;
}
private:
coro_handle handle_;
};
与yield_value不同的是,get_generated_value是我们自定义的,名字可以随意起。
现在,便可以使用我们的协程了:
int main()
{
auto nums = generate_numbers(1);
for (;;)
{
nums.resume();
std::cout << nums.get_generated_value() << " ";
if (nums.get_generated_value() > 20) break;
}
return 0;
}
此处,使用生成器从1开始,依次以递增1的趋势生成数字,现在的结束条件完全在调用方这边。因此,所有流程,都可由调用方进行控制。
输出如下:
最后,简单地介绍下co_return。
co_return用于协程的返回,就像return一样,不过是专门针对协程的。
例如:
std::future<int> a()
{
co_return 42;
}
当协程没有结束条件时,就像上述定义的生成器,则需要定义return_void()或return_value()函数,若无定义,当协程结束时会遇到未定义的行为(一般没定义会直接编译不过)。
如果通过co_return返回void,则会调用return_void();通过co_return返回一些值时,则会调用return_value()。这两个函数不能同时定义。
本节到此便已结束,相信大家对C++的协程也有了初步的认识,后面便能再写一些稍微有难度的文章来继续分享了。
本节完整的协程代码如下:
#include <iostream>
#include <cassert>
#include <experimental/coroutine>
template <typename T> class generator
{
public:
struct promise_type {
using coro_handle = std::experimental::coroutine_handle<promise_type>;
auto get_return_object() {
return coro_handle::from_promise(*this);
}
auto initial_suspend() { return std::experimental::suspend_always{}; }
auto final_suspend() { return std::experimental::suspend_always{}; }
auto return_void() {}
void un_handled_exception() { std::terminate(); }
T value_;
auto yield_value(T value) {
value_ = value;
return std::experimental::suspend_always{};
}
};
using coro_handle = std::experimental::coroutine_handle<promise_type>;
generator(coro_handle handle) : handle_(handle) { assert(handle_); }
generator(const generator&) = delete;
generator(generator&& other) : handle_(other.handle_) { other.handle_ = nullptr; };
~generator() { handle_.destroy(); }
bool resume() {
if (!handle_.done())
handle_.resume();
return !handle_.done();
}
const T get_generated_value() {
return handle_.promise().value_;
}
private:
coro_handle handle_;
};
generator<int> generate_numbers(int begin, int inc = 1)
{
for (int i = begin;; i += inc)
co_yield i;
}
int main()
{
auto nums = generate_numbers(1);
for (;;)
{
nums.resume();
std::cout << nums.get_generated_value() << " ";
if (nums.get_generated_value() > 20) break;
}
return 0;
}
6. 使用场景(Coroutines use cases)
- generators
- 异步IO
- lazy computations
- 事件驱动程序
- 协作式多任务
- 无限列表
- ...
7. 总结(Summary)
本篇介绍了C++20协程的大多数概念,理解之后便算是协程入门了。
关于文章开头的那些问题,想必大家心中也已有了答案。
但这些介绍仍只是其冰山一角,C++的协程还有非常多的知识需要学习,待日后再慢慢道来。
8. References
- https://en.cppreference.com/w/cpp/language/coroutines
- https://en.m.wikipedia.org/wiki/Coroutine
- https://baike.baidu.com/item/并行/5806759#viewPageContent
- https://blog.panicsoftware.com/coroutines-introduction/
- https://blog.panicsoftware.com/your-first-coroutine/
- http://www.davespace.co.uk/arm/introduction-to-arm/registers.html
- https://owent.net/2019/1904.html
- CppCon2014
- C++ Coroutines CppCon2015
- C++ Coroutines-under the covers CppCon2016
- Coroutines in C++17
- N4024 Distinguishing coroutines and fibers
- N4680 C++ Extensions for Coroutines
- N4760 Working draft, c++ coroutines for coroutines
- Concurrency with modern c++
- C++20 Coroutines - Milosz Warzecha

 浙公网安备 33010602011771号
浙公网安备 33010602011771号