【译】go内存模型
Go内存模型制定了一套规则:针对同一个变量,一个goroutine的读操作如何才能保证(guarantee)观察到(observe)另一个goroutine的写操作。
翻译翻译,什么叫观察到?
有如下代码
查看代码
package main import ( "fmt" "runtime" "sync" ) var v string var done bool var wg sync.WaitGroup func write() { v = "hello world" done = true if done { fmt.Println("wrote,", len(v)) } wg.Done() } func read() { for !done { runtime.Gosched() } fmt.Println("read,", v) wg.Done() } func main() { wg.Add(2) go write() go read() wg.Wait() }如果编译器没有重排,输出结果是:
// write 先行于 read执行 wrote, 11 read, hello worldread读取到了write后的值,这就是说read观察到了其他goroutine对变量v的写,符合我们的预期。
然蛾,假设编译器在后台对write进行重排,如下:
func write() { done = true v = "hello world" if done { fmt.Println("wrote,", len(v)) } wg.Done() }done与v的顺序重排了,此时可能的输出结果有:
// 预期情况:write 先行于 read执行 wrote, 11 read, hello world // 非预期情况:write赋值done后放出cpu -> read调度执行完 -> write调度执行剩下的write v read, wrote, 11read没有读取到write后的值,这就是说read没有观察到其他goroutine对变量v的写,不符合我们的预期。
那要怎么搞?自己写的代码,编译器还来插一手,插一手就算了,还插的不对?有什么好办法,引出建议。

如果修改数据的同时,有多个goroutine访问这个数据,那必须要串行化访问。
要实现串行化访问,用channel或者sync、async/atomic包里的同步原语。
如果你必须得读文档剩下的内容才能理解你自己写的代码,那你就太水了。
做人不要这么水。
func write() { v = "hello world" if done { v = "hello reorder" } done = true if done { fmt.Println("wrote,", len(v)) } wg.Done() }这种情况就不能重排v和done,一旦重排,v的值就变了,就会影响这个goroutine的执行结果。
happens before -- 内存操作上的局部顺序。如果事件e1发生在事件e2之前(happens before),那们也可以说e2发生在e1之后(happens after)。如果e1既不发生在e2之前,也不发生在e2之后,那我们就说,e1、e2
在单个goroutine内,happens before顺序就是代码展现的顺序。
v,只有同时满足以下两个条件,读 操作r才被允许观察到写操作w
- 不发生在
w之前. - 不存在其他的的
w'发生在w之后、不在r
关键词:允许(allowed)。
允许,相当于拿到一张抽奖券,至于能不能中奖,后面再说。反正没有这张券,是必然不能中奖的。
r包含的指令集,每一条都是原子指令:{ read x1; read x2; read v; } w包含的指令集,每一条都是原子指令: { write x1; write x2; write v; }既然如此,为什么不直接把1定义为『r发生在w之后』呢?我的理解是,如果直接定义,就相当于直接中奖了,不符合允许这一词的特性,所以才定义的比较软。
1的定义有一个漏洞,r是发生在w之后了,但在在w发生后,以可能会有w1、w2、w3等别的写操作。我要的是r只针对特定的w,不能被其他wx覆盖。所以增加了2。
w' tovthat happens after w but before r简化一下就是:There is no other write that is not before r.不存在别的写操作,什么样的写操作?不在r之前的写操作。没有其他的写,不在r之前。有其他的写,在r之前。所以2的意思是:其他的写操作发生在w之前 or w同时,并且发生在r之前。同样的,对于同时发生的情况,指令集的情况,其他的wx可能会覆盖w的write。
发生在r之前;
2. 其他的w'发生在w之前,或者r
初始化操作是在单个goroutine内运行,但这个goroutine可能会创建其他的goroutine,导致并发运行。
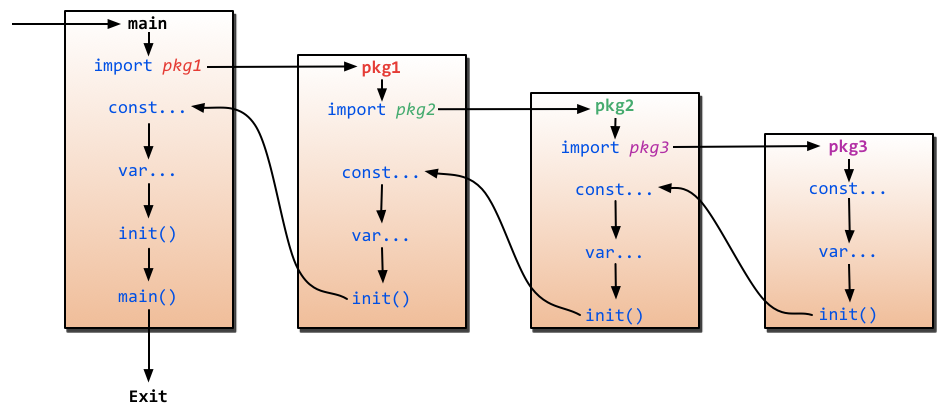
如果p包 import q包,q包的init函数 happens before 包的起始代码。
main.main函数 happens after 所有的init函数完成。
这其实规定了导入包时,包变量、包init的执行顺序。借用beego上的一张图
var a string
func f() {
print(a)
}
func hello() {
a = "hello, world"
go f()
}hello后,在将来某个时间点(也许是在hello退出后)会打印出"hello, world"
var a string
func hello() {
go func() { a = "hello" }()
print(a)
}
var c = make(chan int, 10)
var a string
func f() {
a = "hello, world"
c <- 0 // 发送, 不重排
}
func main() {
go f()
<-c // 接收
print(a)
}
var c = make(chan int)
var a string
func f() {
a = "hello, world"
<-c
}
func main() {
go f()
c <- 0
print(a)
}
发送端不重排;因为在讲上一个情况时,没有特意说明channel是缓冲还是不缓冲;
package main import ( "fmt" ) var c = make(chan int, 1) var a string func f() { a = "hello, world" <-c } func main() { go f() c <- 0 fmt.Println(a) }改成带缓冲的,首先,channel是带缓冲,不适合上面的12总结。
要分析的话,得用到下一条规则,总结3:
channel带缓冲,发送端与接收端不在同一位置,发送 happens before 接收;
这就有可能产生非预期情况,打印空字符串。
var limit = make(chan int, 3)
func main() {
for _, w := range work {
go func(w func()) {
limit <- 1
w()
<-limit
}(w)
}
select{}
}
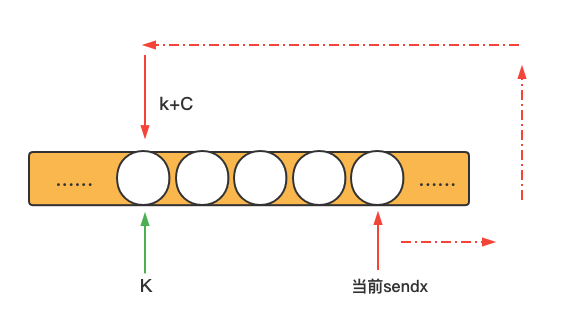
接收位置是K,K+C就是发了一圈回到原来K的位置。
如果此时在位置K上,有goroutine阻塞于接收,那么接收 happens before 发送完成。
所以,前面对于channel的分情况总结,还需要完善,完整的总结应该是这样:
channel无缓冲,接收端的goroutine不重排,接收 happens before 发送;(这点没改变)
channel带缓冲,发送端与接收端在同一位置,接收 happens before 发送;(补充)
var l sync.Mutex
var a string
func f() {
a = "hello, world"
l.Unlock()
}
func main() {
l.Lock()
go f()
l.Lock()
print(a)
}
Unlock不重排;
Lock与Unlock分开计数;
这,不用翻译,应该都能懂。

var a string
var once sync.Once
func setup() {
a = "hello, world"
}
func doprint() {
once.Do(setup)
print(a)
}
func twoprint() {
go doprint()
go doprint()
}
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func doprint() {
if !done {
once.Do(setup)
}
print(a)
}
func twoprint() {
go doprint()
go doprint()
}
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
type T struct {
msg string
}
var g *T
func setup() {
t := new(T)
t.msg = "hello, world"
g = t
}
func main() {
go setup()
for g == nil {
}
print(g.msg)
}
t := new(T) g = t t.msg = "hello, world"


 浙公网安备 33010602011771号
浙公网安备 33010602011771号