
读asyncio模块源码时的知识补漏
硬着头皮看了一周的asyncio模块代码,了解了大概的执行流程,引用太多,成尤其是对象间函数的引用。
光是这么一段简单的代码:
# coding: utf8
import asyncio
import random
# 这个装饰器没做什么,对于生成器来说,只是为函数加个属性 _is_coroutine = True
@asyncio.coroutine
def smart_fib(n):
index = 0
a = 0
b = 1
while index < n:
sleep_secs = random.uniform(0, 0.2)
yield from asyncio.sleep(5)
print('Smart one think {} secs to get {}'.format(sleep_secs, b))
a, b = b, a + b
index += 1
if __name__ == '__main__':
loop = asyncio.get_event_loop()
tasks = [
# async返回一个Task实例
# Task实例化时, task内部的_step函数包裹了传入的coroutine, 调用loop的call_soon方法, 传入_step函数
# call_soon方法以传入的_step函数创建一个Handle实例, 再在self._ready队列中加入这个Handle实例
asyncio.async(smart_fib(2)),
]
loop.run_until_complete(asyncio.wait(tasks))
print('All fib finished.')
loop.close()
后面牵扯出的类就在这么多个:
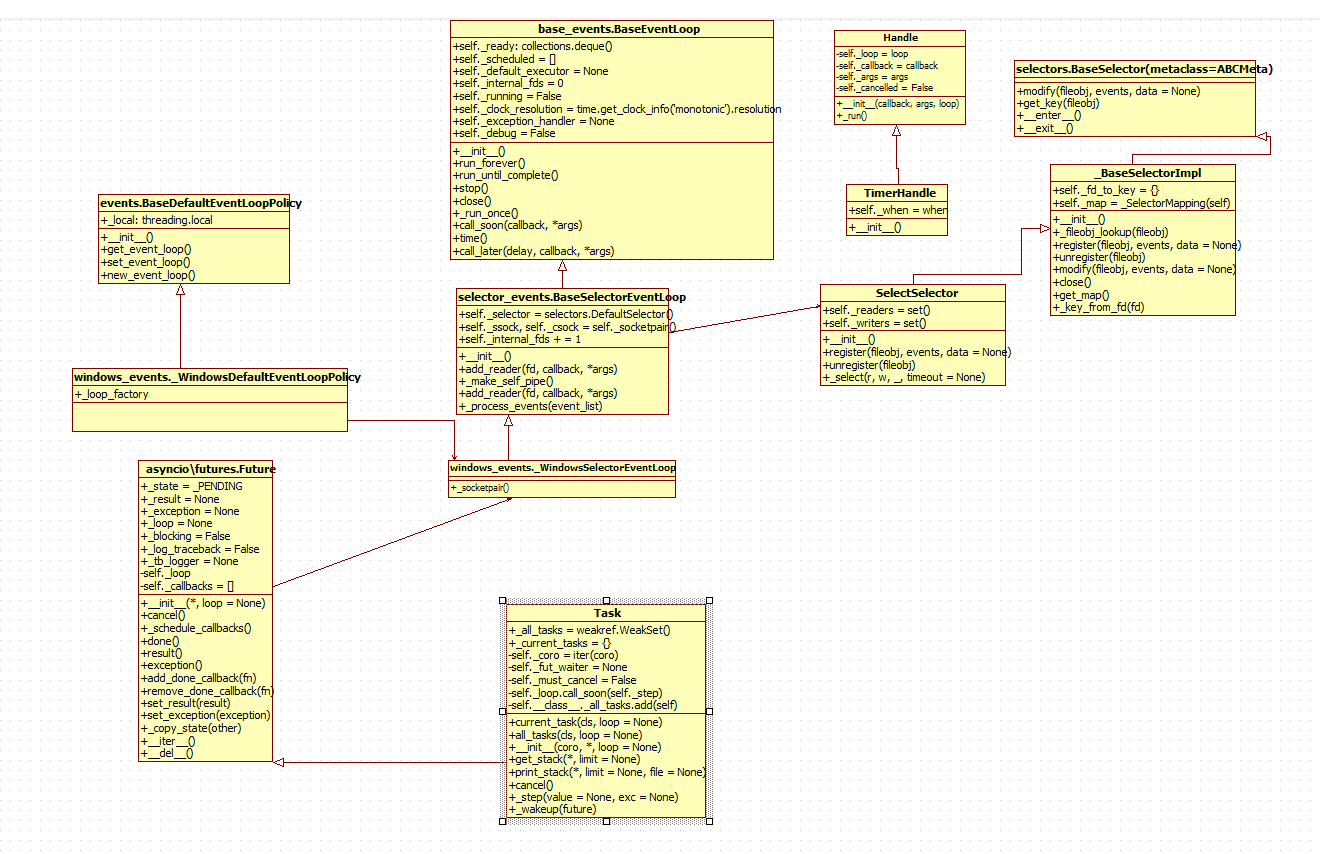
Task包裹generator,Handle又包裹Task里的_step方法,loop的队列又包含Handle对象,loop的堆里又包含TimerHandle对象,还要把堆里的弹出,放入队列,然后又开始一轮新的select事件循环。
整个时序图画起来复杂,还是捡点小鱼虾来得实在。
以下都是在Python3.4下的
socketpair
def _socketpair(self):
return socket.socketpair()
socketpair会创建两个网络文件系统的描述符socket[0]、socket[1] ,保存在一个二元数组中。用于双向的数据传输。.类似于一根双向的管道,socket[0]、socket[1] 都可读写:
—— 在socket[0]写入,只能在socket[1]读出
—— 也可在
socket[0] 读取 socket[1] 写入的数据
接收如下:
self._ssock, self._csock = self._socketpair()
self._ssock.setblocking(False)
self._csock.setblocking(False)
ABCMeta
class BaseSelector(metaclass=ABCMeta):
@abstractmethod
def register(self, fileobj, events, data=None):
pass
实现抽象的类,继承的时候要覆盖这个方法
判断是否是函数:
def isfunction(object):
"""Return true if the object is a user-defined function."""
return isinstance(object, types.FunctionType)
在Lib/inspect.py模块里
判断是否方法是一个实例方法:
def ismethod(object):
"""Return true if the object is an instance method."""
return isinstance(object, types.MethodType)
判断是否是一个生成器(generator function):
def isgeneratorfunction(object):
"""Return true if the object is a user-defined generator function."""
return bool((isfunction(object) or ismethod(object)) and
object.__code__.co_flags & 0x20)
使用iter方法:
>>> i = iter('abc')
>>> i.next()
'a'
>>> i.next()
'b'
>>> i.next()
'c'
>>> i.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
理解了yield,和yield from的用法
select模型
select有阻塞与非阻塞两种方式:如果提供了timeout时间数,则会最多阻塞timeout秒,如果在这timeout秒内监听到文件描述符有变动,则立即返回;否则一直阻塞直到timeout秒。
非阻塞:轮询,间隔询问。select.select(self.inputs, self.outputs, self.inputs, 1)
阻塞:阻塞等待返回。select.select(self.inputs, self.outputs, self.inputs)
缺点:因为要监听的是文件描述符,所以存在最大描述符限制。默认情况下,单个进程最大能监视1024个文件描述符;
采用的是轮询的方式扫描文件描述符,数量越多,性能越差;
select返回的是整个句柄的数组,需要遍历整个数组,不对针对某个特定句柄。
Poll模型
简单来说,poll是使用链表保存文件描述符,因此没有了监视文件数量的限制。但select的其他缺点,poll也有。
Epoll模型
根据每个fd上的callback函数来实现,只有活跃的socket才会主动调用callback,不再轮询。
monotonic time
在初始化BaseEventLoop时,有这么一句时间语句:
self._clock_resolution = time.get_clock_info('monotonic').resolution
monotonic time字面意思是单调时间,实际上它指的是系统启动以后流逝的时间,这是由变量jiffies来记录的。系统每次启动时jiffies初始化为0,每来一个timer interrupt,jiffies加1,也就是说它代表系统启动后流逝的tick数。jiffies一定是单调递增的,不能人为减小,除非重新启动!
(参考资料: http://blog.csdn.net/tangchenchan/article/details/47989473 )
同时,有下列几种时间:
clock': time.clock()
'monotonic': time.monotonic()
'perf_counter': time.perf_counter()
'process_time': time.process_time()
'time': time.time()
例子:
#python 3.4
import time
print(time.get_clock_info('clock'))
结果输出如下:
namespace(adjustable=False, implementation='QueryPerformanceCounter()', monotonic=True, resolution=3.20731678764131e-07)
(参考资料: http://blog.csdn.net/caimouse/article/details/51750982 )
所以 time.get_clock_info('monotonic').resolution 就是获取系统启动后,此时的时间值。
random.uniform函数:
sleep_secs = random.uniform(0, 0.2)
uniform() 方法将随机生成下一个实数,它在 [x, y) 范围内。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
print "uniform(5, 10) 的随机数为 : ", random.uniform(5, 10)
print "uniform(7, 14) 的随机数为 : ", random.uniform(7, 14)
以上实例运行后输出结果为:
uniform(5, 10) 的随机数为 : 6.98774810047
uniform(7, 14) 的随机数为 : 12.2243345905
堆
堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
也就是说,堆顶总是最大值或者最小值。
python的heapq模块提供了堆操作:
heap = [] #创建了一个空堆 heappush(heap,item) #往堆中插入一条新的值
finally不管错误有没有抛出,都会执行:
try:
raise Exception('hahah')
finally:
print("finally")
print("end")
输出:finally
异常
__str__和__repr__的区别
print a时,优先使用__str__方法,没有__str__方法时,才会调用__repr__方法;
在命令行模式下,直接>>a 调用的是__repr方法
输出引用方法时:
B类里引用了A类的一个方法,在B类的输出A类的方法,会调用A的__repr__方法,这就解释了为什么在loop._shedule里,输出TimerHandle时,会跳到Future的__repr__方法。
下面这个例子很好的说明了这种情况:
class Test: def __init__(self, callback): self.a = 11 self._callback = callback def __repr__(self): res = 'TimerHandle({}, {})'.format(self.a, self._callback) return res class Test2: def __init__(self): self.a = 1
def aa(self): return 'shit' def __repr__(self): res = 'what the shit' return res def __str__(self): return "test2" a = Test2() t = Test(a.aa) print(t)
输出如下:
>>>
TimerHandle(11, <bound method Test2.aa of what the shit>)
>>>
raise语句会向上抛出异常,异常不会被同一作用域的except捕获, 因为raise语句本身没有报错。下面的例子要以看出:
class _StopError(BaseException):
pass
class T:
def run(self):
try:
raise _StopError
except Exception as exc:
print("hahahah")
class B:
def run_once(self, t):
t.run()
def run_forever(self, t):
try:
self.run_once(t)
except _StopError:
print("xixixxixi")
t = T()
b = B()
b.run_forever(t)
输出:xixixixixi
判断python的版本:
_PY34 = sys.version_info >= (3, 4)


