
第六章实验
实验1
assume cs:code, ds:data, ss:stack
data segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h
data ends
stack segment
dw 0, 0, 0, 0, 0, 0, 0, 0
stack ends
code segment
start: mov ax,stack
mov ss, ax
mov sp,16
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end
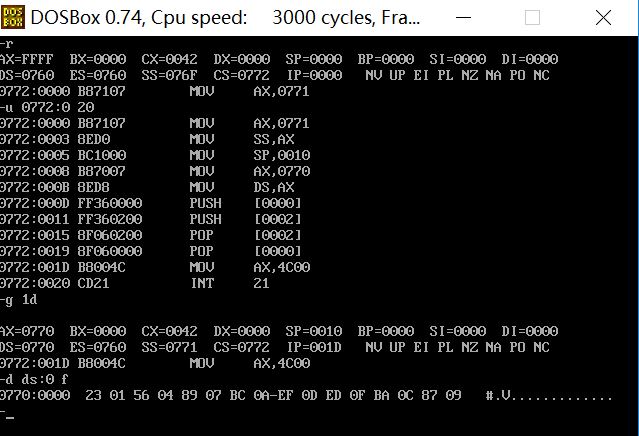
(1)CPU执行程序,程序返回前,data段中的数据为多少?
23 01 56 04 89 07 BC 0A EF 0D ED 0F BA 0C 87 09
(2)CPU执行程序,程序返回前,cs=0772 ,ss= 0771 ,ds= 0770
(3)设程序加载后,code段的地址为X,则data段地址为 X-2,stack段的段地址为 X-1
实验2
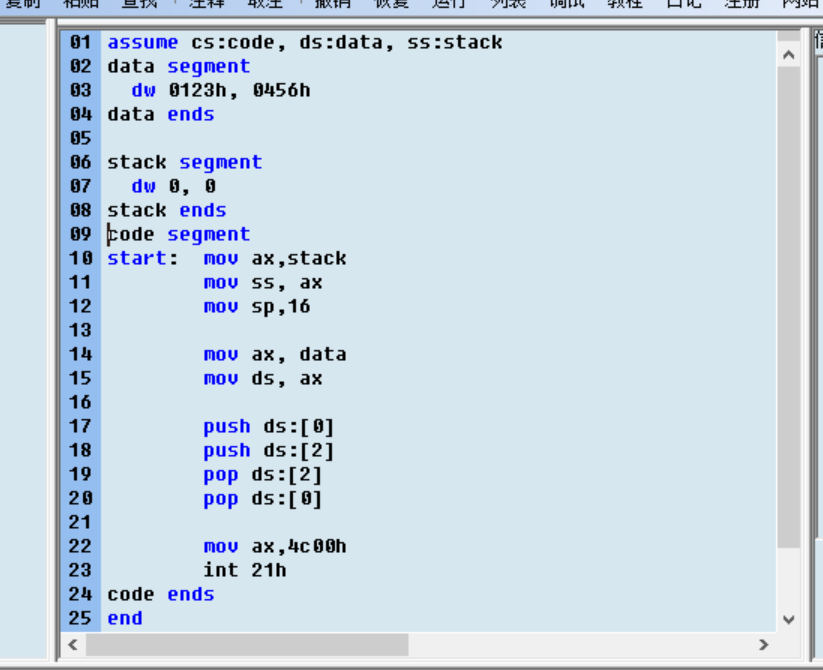
调试
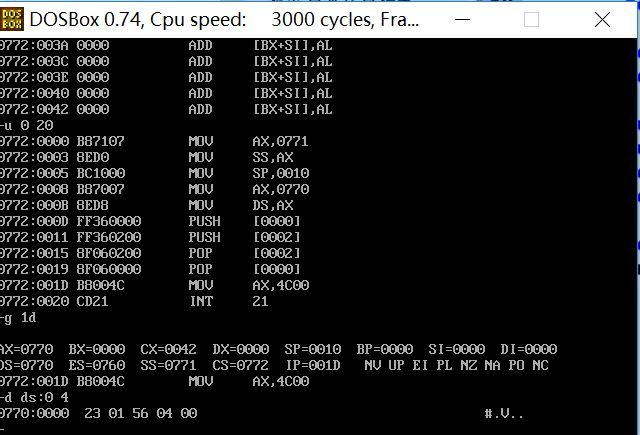
(1)CPU执行程序,程序返回前,data段中的数据为多少?
23 01 56 04
(2)CPU执行程序,程序返回前,cs=0772 ,ss= 0771 ,ds= 0770
(3)设程序加载后,code段的地址为X,则data段地址为 X-2,stack段的段地址为 X-1
(4)对于定义的段
如果段中的数据占N个字节,则程序加载后,该段实际占有的空间为(N/16+1)*16
实验3
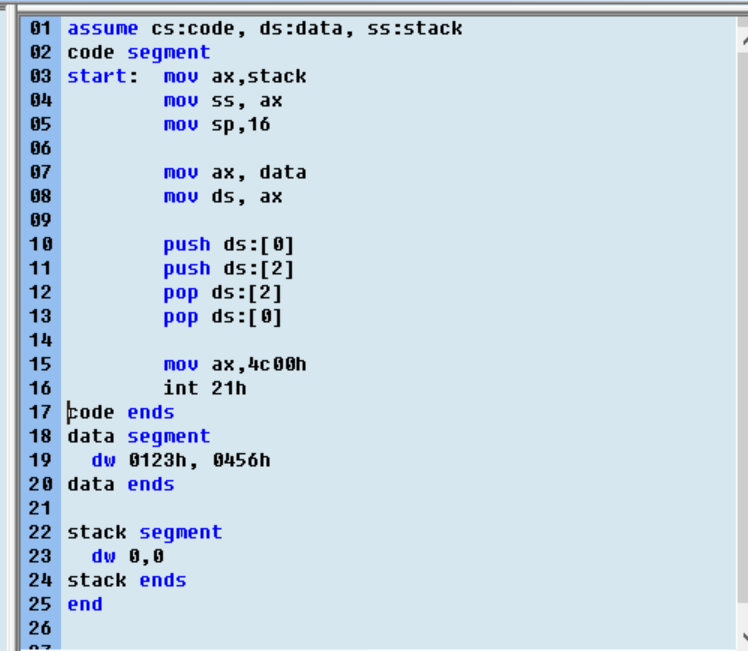
调试
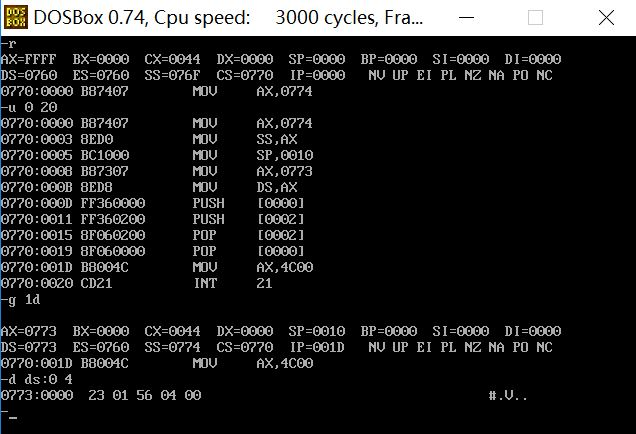
(1)CPU执行程序,程序返回前,data段中的数据为多少?
23 01 56 04
(2)CPU执行程序,程序返回前,cs=0770 ,ss= 0774 ,ds= 0773
(3)设程序加载后,code段的地址为X,则data段地址为 X+3,stack段的段地址为 X+4
实验4
调试结果
(1)
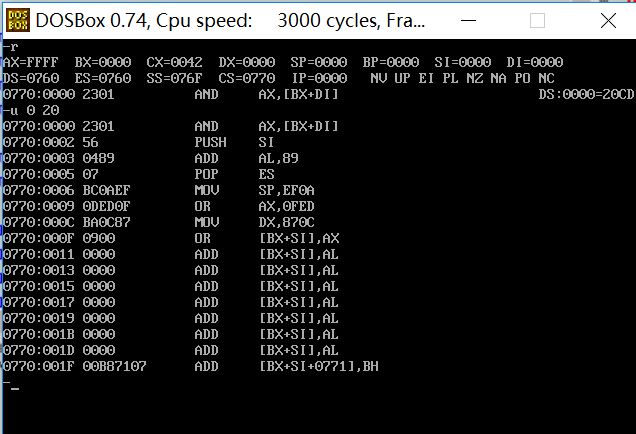
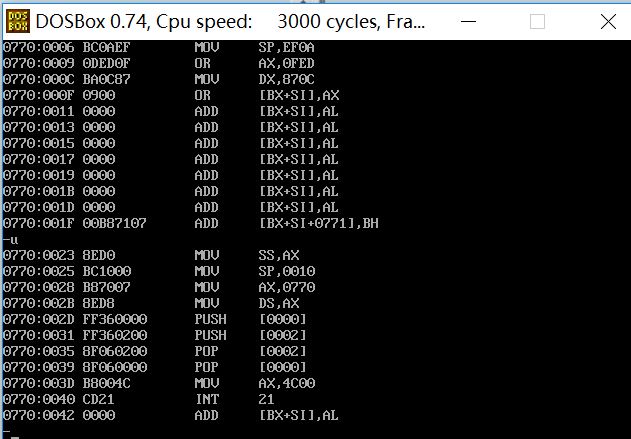
(2)
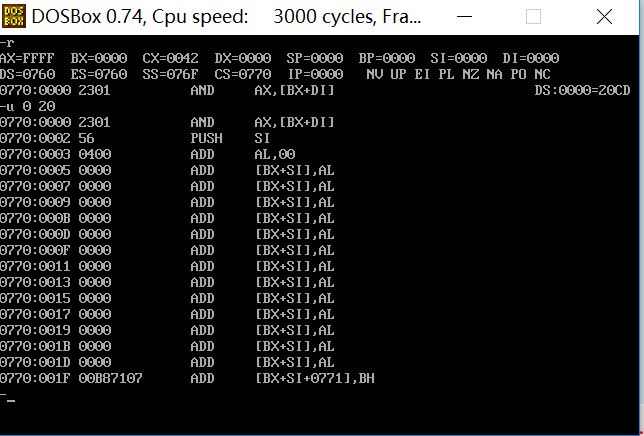
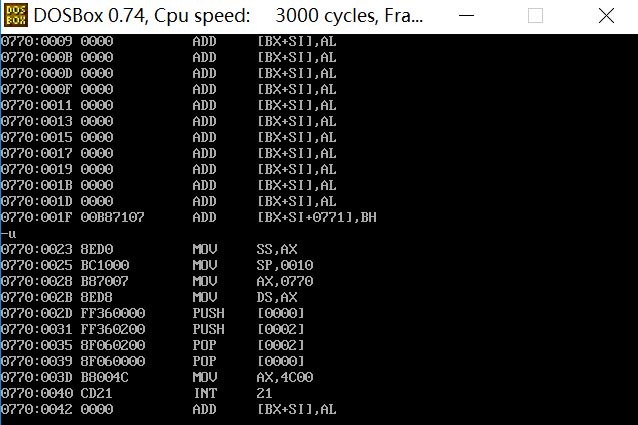
(3)

前两个程序不能正确执行,最后一个可以正确执行
因为如果不指明程序的入口,CPU就会默认从头执行,我们从调试的结果就可以看出前两个开始执行的不是我们指定的代码段
实验5
源代码
assume cs:code a segment db 1,2,3,4,5,6,7,8 a ends b segment db 1,2,3,4,5,6,7,8 b ends c1 segment db 8 dup(0) c1 ends code segment start: mov ax,a mov ds,ax mov ax,c1 mov es,ax mov bx,0 mov cx,8 s:mov al,[bx] mov es:[bx],al inc bx loop s mov ax,b mov ds,ax mov bx,0 mov cx,8 s:mov al,[bx] add es:[bx],al inc bx loop s code ends end start
调试
在实现数据相加前,逻辑段c 的8 个字节
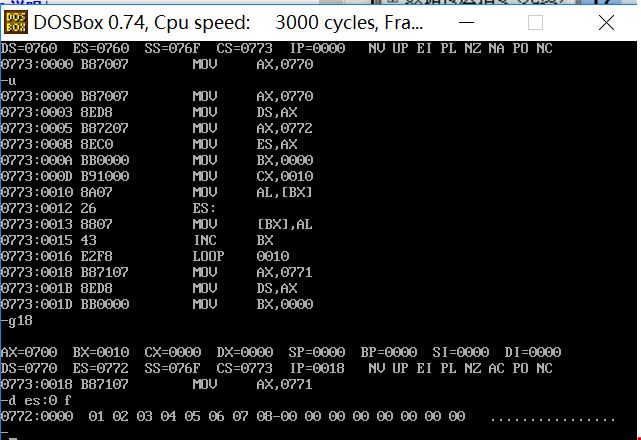
执行完实现加运算的代码后,逻辑段c 的8 个字节
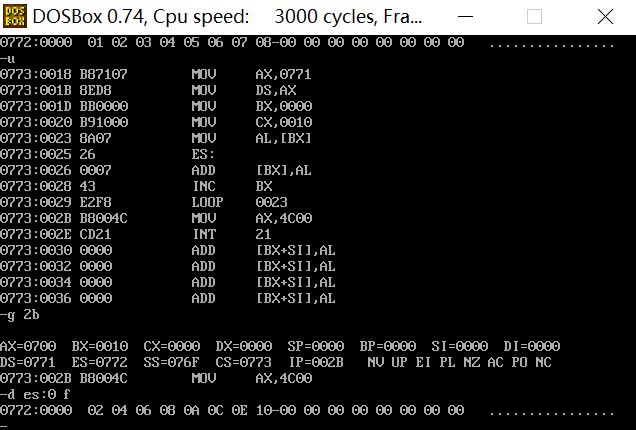
正确实现数据相加
实验6
源代码
assume cs:code a segment dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh a ends b segment dw 8 dup(0) b ends code segment start: mov ax,a mov ds,ax mov ax,b mov ss,ax mov sp,16 mov cx,8 mov bx,0 s:mov ax,[bx] push ax add bx,2 loop s mov ax,4c00h int 21h code ends end start
调试
在push 操作执行前,查看逻辑段b 的8 个字单元信息截图
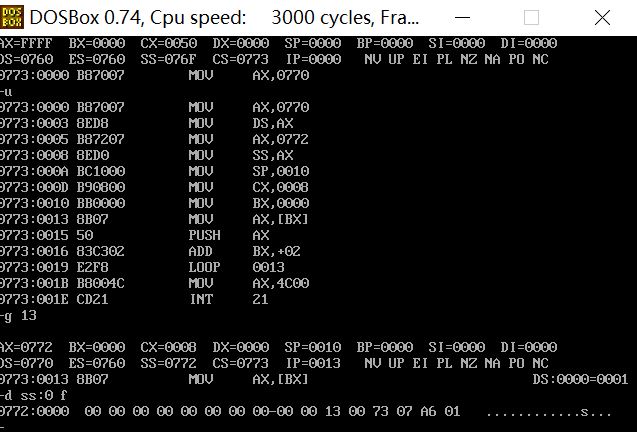
执行push 操作,然后再次查看逻辑段b 的8 个子单元信息截图
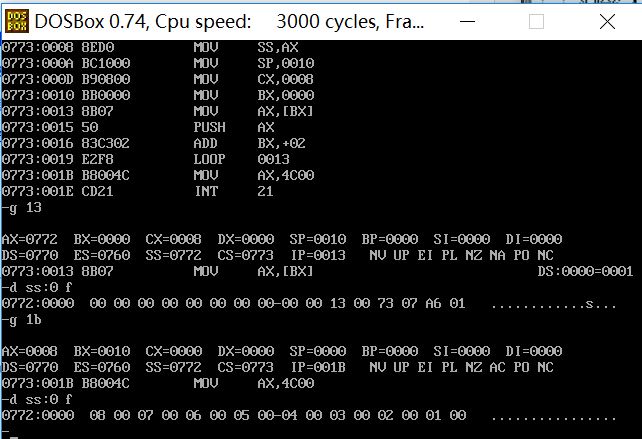
成功实现将a段中前8个字型数据逆序存储到b段中
总结与体会
1.前三个实验在寻找代码段,数据段,堆栈段之间的关系和联系,他们可以共用一段内存空间,并且有一定的关系,但是并没有找到确切的代数关系,在网上找到了下面这个图
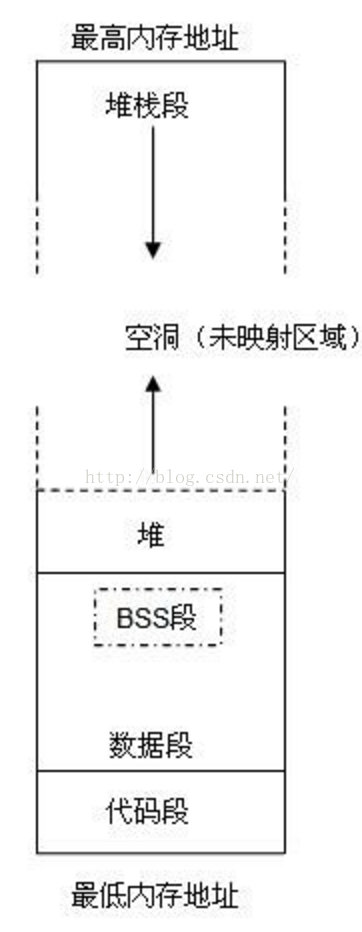
(摘自https://blog.csdn.net/ywcpig/article/details/52303745)
2.段中实际数据占用大小的分析
在8086CPU架构上,段是以paragraph(16-byte)对齐的。程序默认以16字节为边界对齐,所以不足16字节的部分数据也要填够16字节。“对齐”是alignment,这种填充叫做padding。16字节成一小段,称为节
详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号